
-
Machine learning is undergoing a renaissance
-
Machine learning compute is the most important market in the world and could surpass 1% of all US GDP in < 7 years
-
This market is controlled by a few players who limit access and extract rent
-
A Machine Learning Compute Protocol provides an accessible and cost-effective alternative: securing the right to build AI and computational liberty for everyone.
-
To be successful the protocol must meet the GHOSTLY criteria
-
If AI is going to reach its full potential we must establish the right to build
Machine learning models are driving our cars, testing our eyesight, detecting our cancer, giving sight to the blind, giving speech to the mute, and dictating what we consume and enjoy. These models are a part of the human experience now and the way we create and govern them is going to shape our future as a species. Our belief is that an open system of computational resources, accessible by everyone, is the best way to ensure that we are all represented by the artificially intelligent systems that we create.
Soon, we will be able to conjure entertainment on a whim, moulded to our exact preferences and desires and shaped by every sentence we utter and every reaction we exhibit. We’ll be able to tune in to never-ending TV series that feature ourselves and our loved ones, watch action films where our favourite heroes save any world we choose, watch C-beams glitter in the dark near the Tannhäuser gate, and live in digital worlds that constantly change and evolve around us.
Beyond entertainment, our lives will be enriched by constant, probabilistic feedback. We’ll have personalised foundation models that act as external memory, consuming the information that we consume and learning to approximate and augment our inner thoughts through RLHF. We’ll adapt to new methods of storing information—much like we adapted to search engines—storing the keys for retrieval rather than the information itself. Historical figures will be re-awoken by the imprints they’ve left behind, our loved ones will live on through chat systems that know what they knew, and the lines between human and machine interaction will begin to blur without us even noticing. Biological evolution can be slow but social and intellectual evolution is fast, and through it we’ll become indistinguishable from the intelligent systems that we create.
This future requires massive computational power, an always-on network of raw processing resources, the electricity of a new age. Harnessing this power and providing it to every home, every device, and every person should be done through networks that we all govern. Owned by no one but accessible by everyone - with value streams that incentivise us all to provision the resources to them. Forever.
0. Machine learning, compute, & AGI
-
Machine Learning (ML) is the branch of AI that deals with systems that learn from data
-
Compute is the the number of calculations a device can achieve per second
-
AGI is the concept of a generalised intelligence (i.e. able to make sense of – and exist within – the wider world) made from artificial means
Before continuing, it’s best to describe what we mean by ‘machine learning’, ‘compute’, and ‘AGI’.
Machine learning (ML) is a subfield of Artificial Intelligence (AI). Where AI broadly represents any computer program that makes decisions autonomously, ML typically refers to computer programs that can learn how to make those decisions from data they ingest. We call the programs that make these decisions models and the process of instilling knowledge within them as training.
AI has always been a mercurial concept as our shared definition of intelligence can vary significantly over time. For example, the AI models which made (relatively poor) weather predictions in the mid 1950s are unlikely to seem intelligent when contrasted with the AI models that can hold a fluid conversation with you today.


Computational power, or ‘compute’, is electricity transformed by a machine to perform a calculation; the most basic example of this is a FLOP (FLoating point OPeration), e.g. 1.0 + 1.0 = 2.0, which is usually measured in FLOPS (FLOPs per Second). For historical context, the two Apollo Guidance Computers that flew the Apollo 11 mission to the moon in 1969 both achieved 14,245 FLOPS, and today’s iPhone 14 achieves ~2 trillion FLOPS.
FLOPs are the building blocks of computation and are particularly valuable for understanding the computational complexity (or ‘amount’) of compute a model requires to learn. However, the amount of compute used to train a model is also a liquid concept; partly because FLOPs are executed faster/more efficiently on state of the art devices (meaning the electrical ‘cost’ of a FLOP 10 years ago was more expensive than it is now), but also because a FLOP isn’t always the best measure of compute power. For example, the rate at which data can be transferred from memory to the processor might be the main bottleneck in a computational task. Notwithstanding these two issues, FLOPS are a convenient way to quantify the performance of computational hardware.
As AI has developed as a field, we’ve seen a progression of models from expert knowledge systems like template matching, which required human knowledge to be manually hardcoded into the model, to ML models like Viola-Jones in 2001 that automatically discovered visual features in an image. Today, we typically use deep learning (DL) models when performing advanced ML tasks. These models are a special class of Artificial Neural Network (ANN or just NN) that (very loosely) resemble human neural networks and gained prominence in the 2010s when they showed an incredible ability to understand images. DL models are simply NNs that contain a large number of intermediate (or hidden) layers of processing between the input data and the final output. These layers allow the model to reason about the input and build its own understanding of the world by building up a ‘memory’ (known as parameters) of things that it has seen before.


The rapid advances we see in AI are now almost entirely from the field of deep learning, and mostly as a consequence of the ever-increasing size (depth) of the models and the data used to train them. Put simply, more of everything generally results in models that 1. make fewer mistakes, and 2. can be applied to ever more complex use cases.
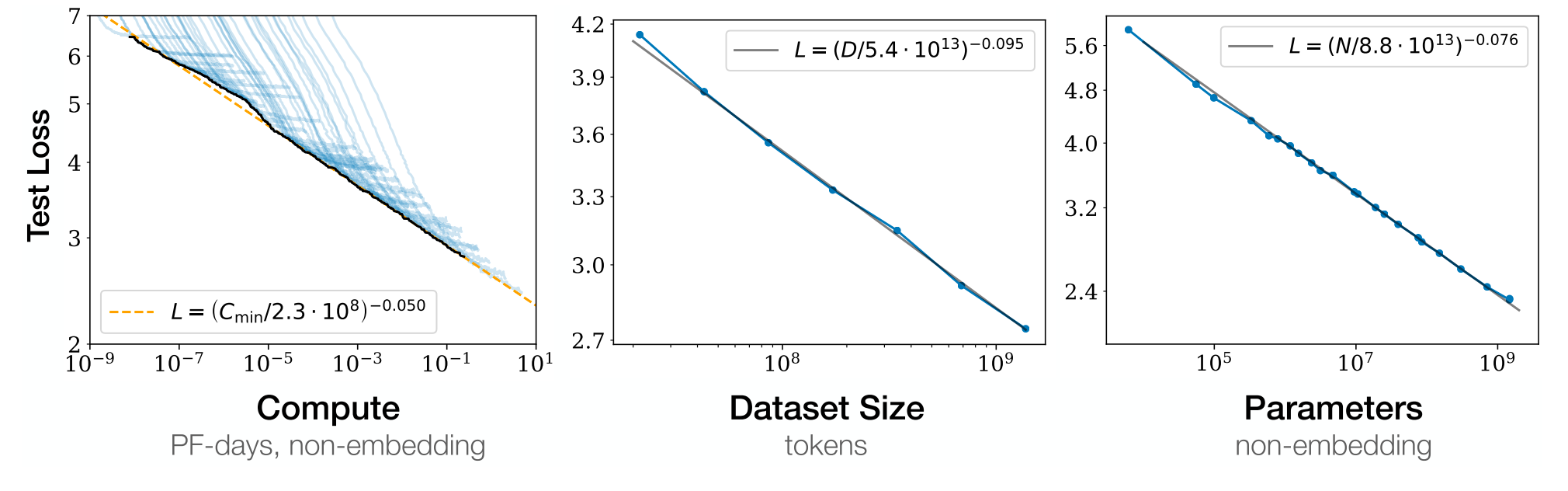
As DL models have rapidly grown in size (roughly doubling every 6 months), their impressive ability to generalise (i.e. use their learning on tasks other than the one they originally undertook) has led to the creation of foundation models. These models take the concept of transfer learning (using a pre-trained model to quickly start training on a new task) and expand it into the idea of creating a model that can perform a large number of tasks through either multiple interfaces or a single general interface, often chat-based. Foundation models and shared interfaces give AI a way to interact with the world that goes beyond the efficient performance of a single task, leading many to consider them the seeds of Artificial General Intelligence (AGI).
AGI could be a single, large model that is able to generalise incredibly well about the world, but it could also be a rich ecosystem of different models, all continuously learning and interacting with each other autonomously. The former represents a quick path towards impressive outcomes plagued by fragile biases and difficulty aligning objectives. The latter allows for meta-optimisation through a free market of models, voted on by all of us through our usage. If you don’t think a model represents your way of thinking - create a new one!
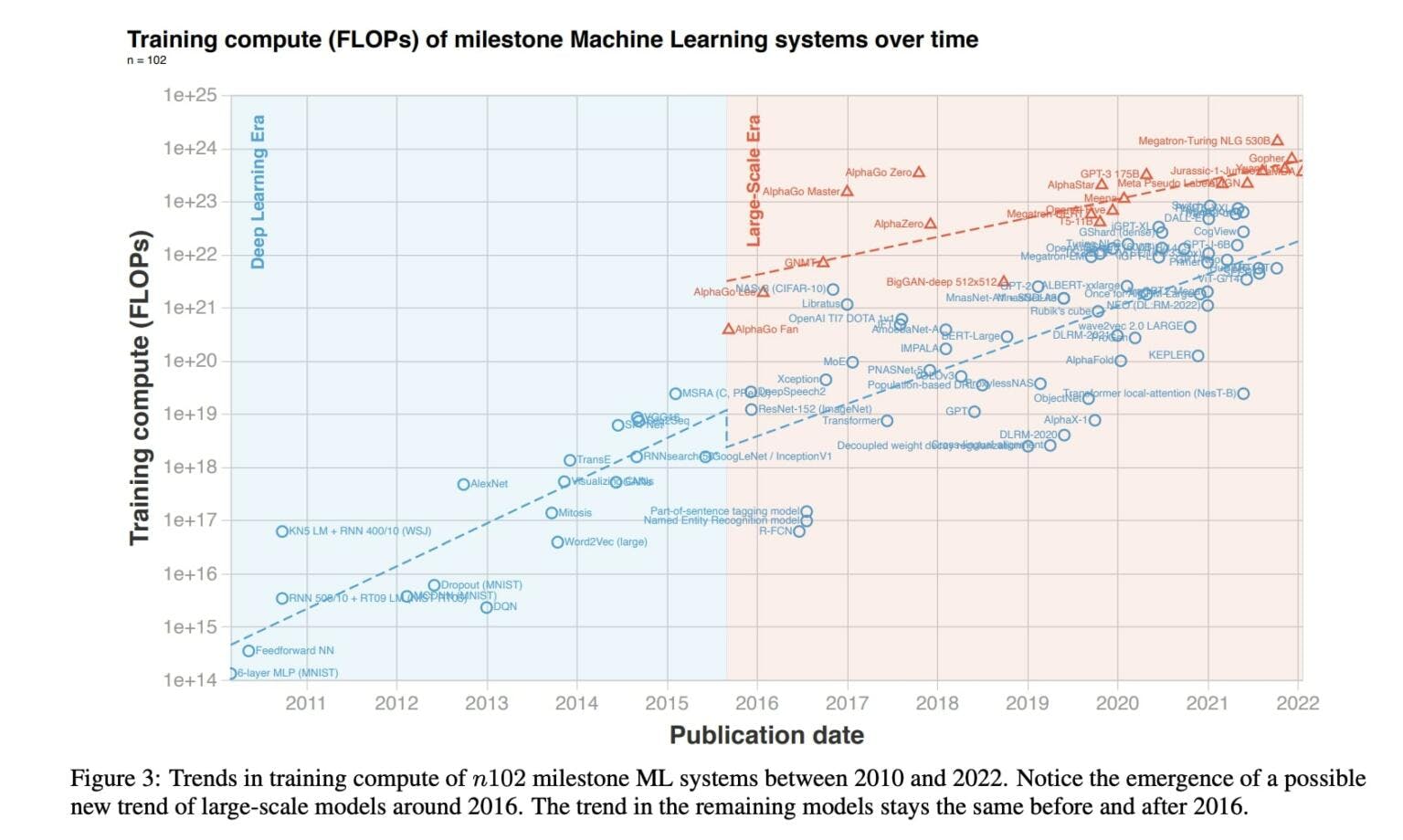
1. The most important market in the world
-
Compute is powering a new industrial revolution in intelligence
-
ML training compute costs alone could reach 1% of US GDP in 8 years
-
Hardware is hugely concentrated and price gouged by incumbents
We’ve undergone roughly three industrial revolutions since the 1760s: starting with steam, then electricity, and most recently the information revolution powered by the internet. It’s clear we’re on the cusp of something else - an intelligence revolution - and even clearer what the accelerant for it will be: compute.
Recall that we previously noted the main drivers of AI system performance are architecture, data, and compute. Both architectural advancements and data are (relatively) easy to procure. Academic publishing disseminates the knowledge required to build complex models, ensuring that new breakthroughs are understandable and useable by everyone soon after discovery. Data is now ubiquitous, and the requirement for complex human labelling is slipping away, replaced with unsupervised and semi-supervised training methods that can create rich embedding spaces simply by processing huge amounts of unlabelled open data.
So, what about compute? It is used during the training phase of models (when they ‘learn’) and also during inference (when they make predictions). However, the former is significantly more compute-intensive than the latter. As early as 2012, it became clear that training on Graphical Processing Units (GPUs) was vastly preferential to training on CPUs. This is because individual NN operations are highly parallelisable; for example a matrix multiplication can be split into many concurrent operations under the paradigm of Single Instruction Multiple Data (SIMD). The most common hardware used for training NNs is still GPUs but they now come with specialised cores for computing NN layers called Tensor Cores. Additionally, several companies have developed their own specialised Deep Learning ASICs that accelerate matrix multiplication and convolution operators under the terminology of [Intelligence/Neural/Tensor] Processing Units (IPU/NPU/TPU).

This hardware is expensive: Meta’s 2023 LLaMA model, a large language model (LLM), was trained on $30m of GPU hardware. Indeed, training models, and re-training them (‘fine-tuning’) for certain tasks, is the most capital-intensive part of the revolution. The cost to train models has been rising exponentially since 2009, as advances in compute capacity unlocked new model use-cases which, in turn, increased demand. Extrapolating growth trends, model training alone could hit 1% of US GDP in the next 8 years. This year the revolution was reflected in the share price of NVIDIA - the world’s most eminent GPU manufacturer: their market capitalization eclipsed $1 trillion for the first time in history.
However, it is the cloud giants who currently stand to truly benefit from this. As demand for HPC ballooned in 2010, AWS (Amazon Web Services) introduced their first GPU instance (the Cluster GPU instance - which had Nvidia M2050s). Consider AWS’s current p4d.24xlarge compute instance - a server you can rent by the hour which contains eight Nvidia A100 40GB GPUs. The cost for an Ohio instance is $4.10/hour/gpu. Per Amazon’s balance sheet and external research, the marginal Cost of Goods Sold for delivering the instance is $1.60 (equating to a 61% gross margin) and the marginal operating expense amounts to $1.50 (equating to a 24.3% operating margin in Q4 2023). Microsoft has an even higher gross margin for its cloud services: 72%.
Other cloud giants have followed suit, leading to a “cloud war” over computation and a race to secure hardware. This is illustrated by ARK Invest’s projected compute-related hardware spend: $1.7T by 2030.
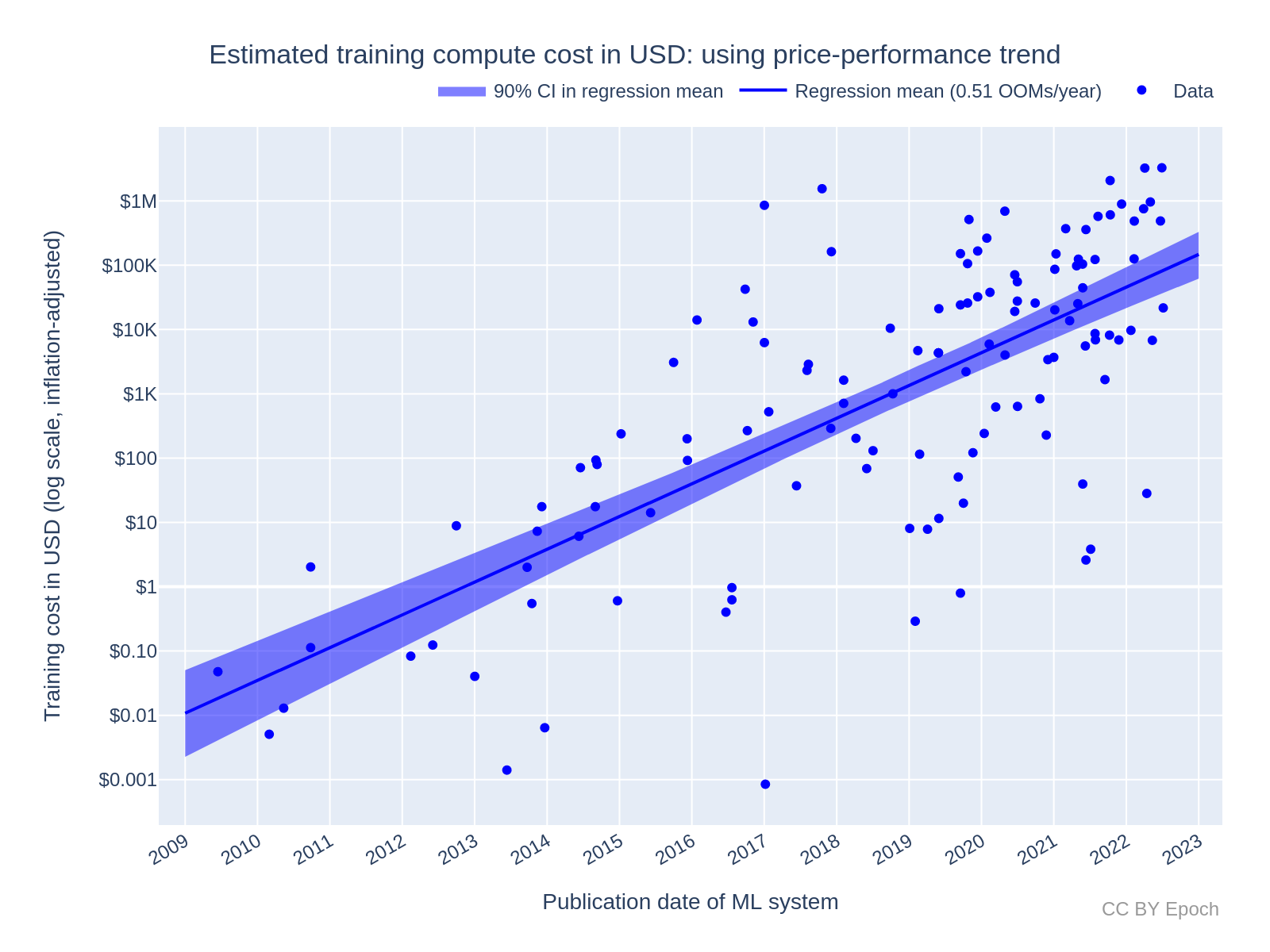
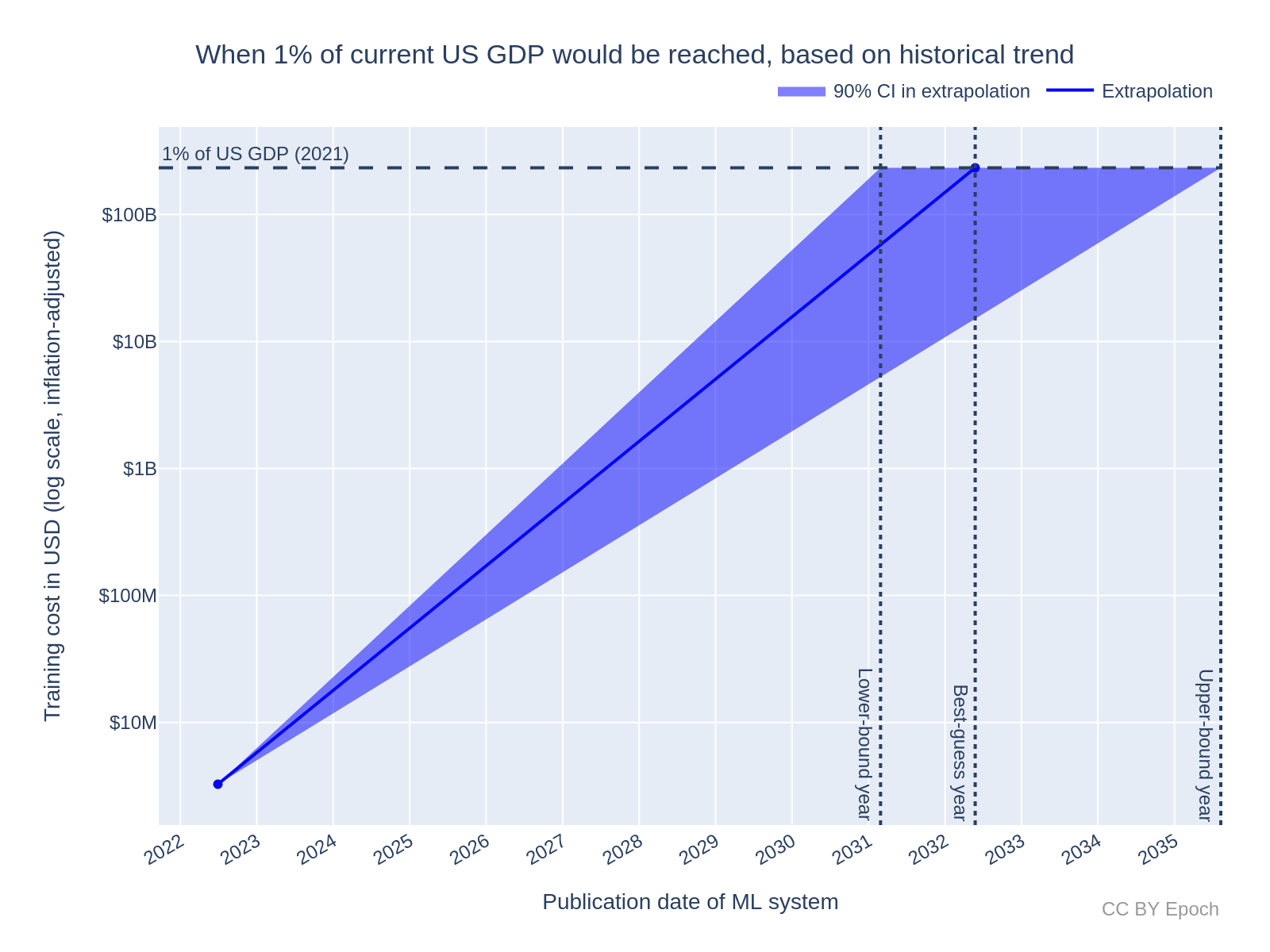
This scramble to amass hardware is true even outside of cloud giants. Consider the aforementioned Nvidia A100 GPU and the newer H100 - the uranium in the arms race to amass computational power. Ownership and concentration of these GPUs into High Performance Compute (HPC) clusters has a strong pareto relationship, and skews heavily to very well financed incumbent organisations. The benefit (& consequences) of owning this compute cannot be understated. It’s why the US, EU, and Japan have repeatedly applied ‘Chip’ (semiconductor) sanctions to China - to slow down their ability to build AGI. It’s also why large AI companies are frantically lobbying to maintain their edge over new market entrants: controlling compute is like having a monopoly on steam power, the electrical grid, or the internet (people have tried).
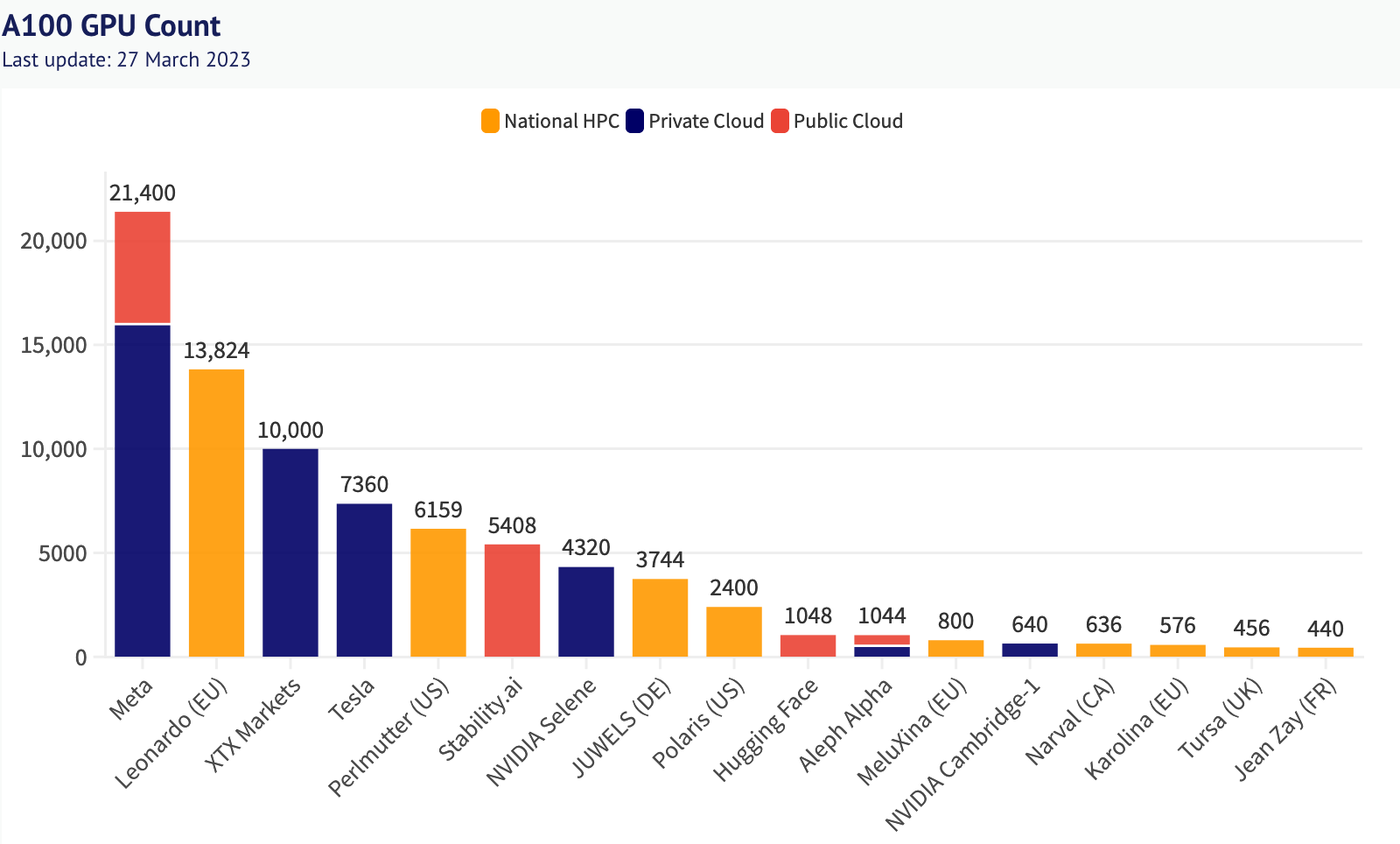
2. The protocol for machine learning compute
-
Previous decentralised compute and file sharing networks present an alternative perspective on the compute issue
-
Hardware access can be increased, and price decreased, by using a P2P network secured by a blockchain
-
For such a protocol to work it must address the GHOSTLY criteria
What can be done? The year is 2023, costs are spiralling out of control, there is a ground war by incumbent countries and companies to lock in (and expand) control via legislation, and some developers are struggling to even access a single GPU.
If we were to pause and ask ‘how would we approach this differently’, what questions might we ask? Perhaps:
-
Why are we paying cloud oligopolists 72 cents of every dollar we spend on compute?
-
Given the exaFLOPs of underutilised compute in the world (see below) - why are we only training models in centralised server farms?
-
If we’re willing to pay more for it, why can’t we access the state-of-the-art GPUs that cloud giants give to their preferred clients?
-
Why does OpenAI tell us that we won't be able to train an LLM from scratch?
The answer to all of these questions, obviously, is because of the economic model under which they operate (closed source, rentier capitalism). Further, any attempt to solve these problems that use the same economic model are destined to only result in different companies with identical outcomes and a repeating cycle.
However, when we look at the history of HPC, we see the seeds of another path: there are teraFLOP or even exaFLOP projects (exa means 1018, or a 1 followed by 18 zeros) which operate over crowdsourced compute. As we’ve noted before, well before Google was stockpiling TPUs, projects like SETI@home attempted to discover alien life by using decentralised compute power provided on a voluntary basis. By the year 2000, SETI@home had a processing rate of17 teraflops, which is more than double the performance of the best supercomputer at the time, the IBM ASCI White. SETI@home was sunsetted in 2020; however, in its place, Folding@home rose to prominence - crowdsourcing 2 exaFLOPS of volunteer compute to run protein-folding programs (used to better understand and treat diseases).
The crowdsourced compute approach seems to address some of our questions above: there is no access limit (any computer can join the network, increasing supply); there is no margin charged here; money doesn’t even change hands. Indeed, mutual relationships like this have occurred elsewhere in the internet revolution. Sites like PirateBay and BitTorrent, which came to prominence in the early 2000s as a peer-to-peer (P2P) method to exchange (often copyrighted) media. Despite the legal issues, they demonstrated that P2P could exist at a large scale (in the past 65-70% of internet traffic was estimated to be P2P) - as long as the users were properly incentivized.
The issue is what would happen if money were to change hands? People would have a strong incentive to cheat. Indeed, some users even cheated on SETI@home to get to the top of the volunteer leaderboard. To solve this we require a core system that can secure the economic incentives of the network and verify that the resource provisioned at the lowest layer is provided correctly. We need a new protocol.
This is similar to the issue that Bitcoin author(s) Satoshi Nakamoto had to overcome in 2008 when attempting to create a protocol that would enable virtual money to be securely transacted with no intermediaries. In this case, the core resource being provided is consensus itself - that is, agreement on the outcome of a state transition within the network. Irrespective of one’s views on Bitcoin, one thing is clear: it successfully incentivizes crowdsourced hardware to join a network and behave in a certain way. Indeed, approximately $13bn of hardware currently contributes to the network (at today’s Hashrate, assuming Antminer S19 Hydro devices) and has ultimately been lauded for its security and verification of transactions.
After Bitcoin proved that the protocol concept could create and secure an open financial system, Ethereum expanded the concept to arbitrary computational tasks with the inclusion of the Ethereum Virtual Machine (EVM), which is (technically quasi) Turing-complete. This demonstrated that, through those same dynamics, we can build a trustless network of computing parties to perform any computation.
A downstream benefit of this protocol approach is that cryptonetworks like Bitcoin and Ethereum - which uses a more financialised and less energy-intensive consensus mechanism - do not charge margins. Instead, a small tax from every payment is returned to the network, destined to be used to maintain the network itself as directed by community governance.
An additional advantage of P2P for hardware networking is that the devices don’t need to be located in traditional data centres. Indeed, beyond the data centre GPUs like the A100, the following devices become available:
-
Custom ASICs: Like Graphcore’s IPUs - custom-built for machine learning - which could be combined into small clusters similar to Bitcoin mining operations.
-
Consumer GPUs: Like the Nvidia RTX series- mainly used for gaming but a mainstay of ML researchers in academia.
-
Consumer SoCs: Like Apple M2 - general-purpose chips with neural processing abilities. Even M1 processors can be used for training with performance comparable to a mid-range Nvidia RTX.

The greater supply and superior unit economics of such a protocol could reduce the price of compute by up to an order of magnitude. For example, the Nvidia A100 mentioned above can be purchased in bulk at $7,800/unit (US-customs cleared, December 2022). Hardware miners in the Bitcoin network typically rate opportunities on their ability to return the value of the hardware (note: the price of hardware can change in this time) over a certain time period, commonly 18 months. With a total power draw of 250w/h and assuming a constant price of electricity and maintenance of $0.10/Kwh in the United States, for a miner to be incentivised to provide deep learning computation they require a yield of $0.59/h to cover the machine and $0.025/h to cover electricity. This means they could provide compute for as little as ~$0.62/h → ~85% cheaper than AWS.
However, so far we’ve only considered protocols like Ethereum which work for small-scale computation - where every peer in the network performs the work (putting an upper cap on the computational complexity). If we wanted to perform large-scale computation using trustlessly-provisioned hardware to train a machine learning model, we would need to achieve one of two things:
-
Make the computations more efficient so that they can feasibly be performed by the chain; or
-
Prove that large-scale computations, performed off-chain, were performed as-specified to the satisfaction of the chain.
The former point is possible but results in heavy constraints on the model, owing to the scaling laws mentioned earlier; the latter is a compelling concept. In this setting, a blockchain secured by a trustless consensus mechanism and able to do arbitrary small computations would be able to take the place of a trusted third party in a verification dispute - as long as the final disputed portion of the computation can be reduced to a size that is reasonable for a chain to perform. This makes the verification system, and particularly the additional cost of verifying the work, core to the protocol’s success.
Indeed, such a protocol would need to satisfy six defining principles, GHOSTLY:
-
Generalisability - Specifically, can you submit a custom architecture, optimiser, and dataset and receive a trained model? This is a core user requirement for ML developers; constraining a protocol to a single type of model training would only work if that mode of training became the default form of training (fragile/very unlikely).
-
Heterogeneity (over supply) - Core to achieving maximum scale of supply is ensuring the ability to use different processor architectures and different operating systems. If the protocol requires hashing (as is highly common in decentralised protocols) then the computation performed on the different devices must result in identical outputs, i.e. it must be deterministic (or reproducible). Despite the fact that differences in output are often tiny, it is surprisingly hard to achieve reproducibility for deep learning because:
-
Different processor architectures add together numbers differently and at varying levels of precision
-
Many parts of the training process involve random seeds that are often hard to control
-
The physical hardware is susceptible to cosmic ray radiation causing bit-flips - but this is widely solved by Error Correcting Codes
-
Stochasticity has actually proven beneficial for deep learning in avoiding overfitting, leaving little reason to address it in the face of greater throughput
-
-
Overheads (low) - Ethereum blockspace could be theoretically used to train a model; however, this would incur a ~7850x computational overhead vs an AWS instance using a Nvidia V100 GPU as a reference. Similarly, even a Truebit-style game-theoretic replication approach fails at achieving suitably low overhead (still ~7x). Any approach to verification must have a minor overhead lest it offset the unit economic gains achieved through decentralisation. Further, Fat protocols typically incur higher overheads as they attempt to allow every possible computation.
-
Scalability - Protocols relying on specialised hardware that are distinct from those used by normal machine learning researchers invariably cannot scale to State-of-The-Art (SoTA) LLMs. For example, use of Trusted Execution Environments (TEEs) partially solve the trust problem at the expense of huge speed reductions.
-
Trustlessness - If the network requires trust, then:
-
it incurs scaling limits as a trusted party is required to verify work; and/or
-
the network cannot scale above a certain point before trust is broken and the dominant economic outcome becomes cheating; and/or
-
an operational labour cost is borne by the network that puts upward pressure on price (e.g. KYC checks).
-
-
LatencY - Inference is highly sensitive to latency (training systems less so). Core to this problem is the notion of model parallelism; that is, if you are compute-rich and latency-poor, instead of sending a 1GB model to one device, could you send 1024 1 MB models to 1024 devices? Could you split it up even more? The short answer for most NN architectures is no. NN training requires context (state dependency) about what is happening elsewhere in the model (unlike SETI which is embarrassingly parallel) and therefore requires a system which can: a) optimally trade off compute capacity for network bandwidth; and b) somehow chunk a model into smaller components without violating point 3) above.
In satisfying the GHOSTLY principles, a machine learning compute protocol would combine the crowdsourced grid computing of SETI@Home with the P2P verification and security of Ethereum to perform machine learning tasks over the entire world’s hardware.
3. The right to build
-
Computational liberty is best achieved via technological means, not legal means
-
The decentralised machine learning compute protocol is core to building AI systems that are aligned with society
-
Such a protocol also increases the rate of technological change by preventing oligopolies
For machine learning models to proliferate throughout our world in a fair and equitable manner, it is crucial that we establish the right to build. Not as a legal right enforced by governments, but as a technological right enabled by building with a new perspective - decentralisation. This right is very simple - we should all be able to access the resources required to build new machine learning models. We’re in a race against competitors aiming to dominate our future by controlling an enabling technology that will radically alter our society.
Regulating this technology will create new monopolies, and those monopolies will do everything they can to maintain their position and increase their capture of value. Without the feedback loop of competition, we lose the direct representation of the voices of consumers and must rely on those same regulating institutions to uphold their positions. Why hand this task to a chain of organisations, each with their own incentives, when we can rely directly on the market to perform it?
Decentralised networks give us the ability to change the incentive structure itself, to choose a new set of guiding principles for the powerful optimising force of capitalism. By building protocols instead of companies we can counteract the behaviours that inevitably turn innovation into rent-seeking oligopolies.
We see this trend with storage protocols like IPFS, networking layers like Helium, and niche computational networks like Render Token. Crucially, unlike storage, which is incredibly cheap to scale in a centralised way; networking, which suffers from Metcalfe’s Law; and rendering, which is a relatively niche market, machine learning hardware has clear economic value at any scale. The first GPU on the network is just as valuable as the last.
Through protocol economics, we can ensure that the value flows are governed by a network of participants, with no barrier to entry other than owning a valuable resource. These networks do not isolate distribution or empower existing royalty, they manage a pool of participants as a shared resource to be optimised. Distributing value over the core resources in this way, the protocol incentivises improving the provision of the resource itself, not capturing more of the distribution.
Decentralised networks don’t merely improve economic incentives, they also free us from authoritarian control over the content that we consume and even our personal communications themselves. As per Chris Dixon, ‘But the benefits of such a shift will be immense. Instead of placing our trust in corporations, we can place our trust in community-owned and -operated software, transforming the internet’s governing principle from “don’t be evil” back to “can’t be evil”.’
4. The future
- The world will be unrecognisable in 5 years
In 5 years time, a developer won’t think about where their model will be trained, how the server is configured, how many GPUs they can access, or any other system administration details. They’ll simply define their model architecture and hyperparameters and send it out to a protocol - where it could be trained on a single GPU, a cluster of TPUs, a billion iPhones, or any combination thereof.
We’ll look back on human-guided training of AI models like we look back on ancestral hand-tools; a necessary, yet almost incomprehensibly expensive (in terms of human effort) step towards an automated future.
By building the decentralised rails to carry computation to the hardware and payments to the participants, a machine learning compute protocol would be an invisible network, supplying the compute revolution with the base resources it needs to move to the next level of scale. Right now we’re all relying on a small number of companies to drip-feed access to computation to the partners they choose. Through decentralisation we could create a free market over all compute, allowing anyone to pay a fair price to access as much of it as they’d like. Such a network would enable currently gatekept developers to try out new architectures, datasets, and even modalities - ultimately creating things that would otherwise never exist.
Conversely, we could all contribute resources to the network, getting paid for the compute power that we have when we’re not using it. When our MacBooks or iPhones are charging, when our gaming PCs are idle, when we’re sleeping but the other side of the earth is awake, our devices could earn us money. By spreading the load in this way we’d take advantage of idle efficiencies, greener sources of electricity, geographical downtimes, and make the most out of the resources we’ve already manufactured. As Bitcoin began to proxy the global energy markets—this would do the same—all underpinned by real-economic-valued work, requested and paid for by others.
Ultimately, those others will be machine learning models themselves. Living on a self-organising substrate over the core resources required to sustain them, they’ll trigger training, inference, and even the creation of new models. Artificial General Intelligence won’t be a single large model that can answer questions, it will be a living ecosystem of models that can think for themselves, replicate, and one day surpass our understanding. It’s important that we build this in the open and for everyone - we can’t allow the future of AI to be in the hands of a small minority who think they know what’s best - we should all have a part in this future.