
撰写:Mohamed Fouda、Qiao Wang
*本文由 Alliance DAO 独家授权深潮 TechFlow 编译发布。

自 ChatGPT 和 GPT-4 推出以来,有大量内容探讨人工智能如何改变 Web3 等一切事物。很多行业的开发人员通过利用 ChatGPT 自动化工作内容,如生成样板代码、进行单元测试、创建文档、调试和检测漏洞等。虽然本文将探讨人工智能如何启用新的有趣的 Web3 用例,但主要关注点在于 Web3 和人工智能之间的互惠关系。少有技术能够显着影响人工智能的发展轨迹,而 Web3 就是其中之一。
尽管潜力巨大,但当前的人工智能模型面临着若干挑战,包括数据隐私、专有模型执行的公平性以及创建和传播可信虚假内容的能力等。一些现有的 Web3.0 技术具有独特的优势来应对这些挑战。
用于机器学习训练的专有数据集
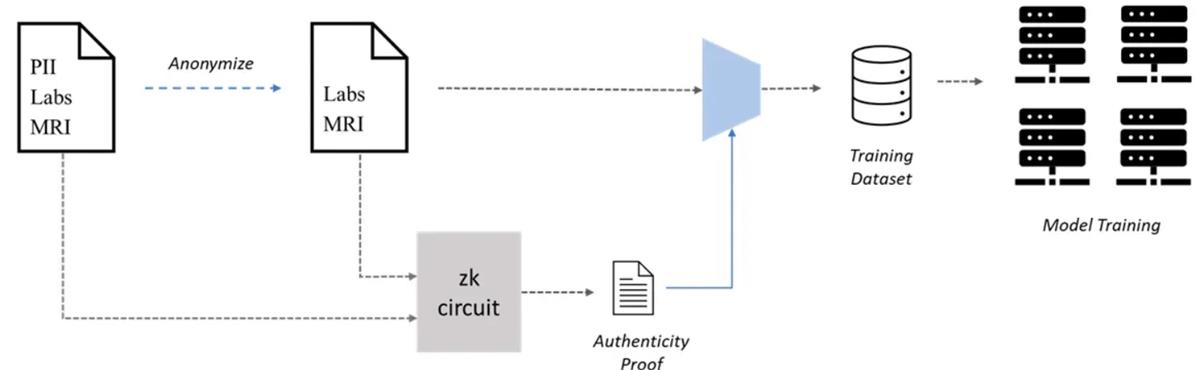
Web3 可以帮助人工智能的一个领域是协作创造专有数据集以供机器学习(ML),即用于数据集创建的 PoPW 网络。海量数据集对于准确的 ML 模型至关重要,但它们的创建可能是一个瓶颈,特别是在需要使用私人数据进行诊断的医疗 ML 应用中。患者数据隐私问题是个重大障碍,但访问医疗记录是训练这些模型所必需的。然而,由于隐私问题,患者可能不愿意共享他们的医疗记录。为了解决这个问题,患者可以通过可验证的方式对他们的医疗记录进行匿名化处理,以保护他们的隐私,同时仍然可以将其用于 ML 训练。
匿名化医疗记录的真实性是一个问题,因为伪造数据可能会影响模型性能。为了解决这个困境,可以使用零知识证明(ZKP)来验证匿名化的医疗记录的真实性。患者可以生成 ZKP 来证实匿名化记录确实是原始记录的副本,即使删除了个人身份信息(PII)同样可以验证。这样,患者可以将匿名记录和 ZKP 一起提交给有兴趣的各方,并获得奖励,而不会牺牲他们的隐私。
对隐私数据运行推理
当前 LLM 的一个主要弱点是其处理隐私数据的能力。例如,当用户与 ChatGPT 交互时,OpenAI 收集用户的数据并将其用于增强模型的训练,可能会导致敏感信息泄露。此情形曾发生在三星公司。零知识 (zk) 技术可以帮助解决 ML 模型在对私有数据执行推断时出现的一些问题。在这里,我们考虑两种情况:开源模型和专有模型。
- 对于开源模型,用户可以下载模型并在本地运行它们的隐私数据。一个例子是 Worldcoin 计划升级 World ID。Worldcoin 需要处理用户的私有生物特征数据,即用户的虹膜扫描,以创建每个用户的唯一标识符,称为 IrisCode。在这种情况下,用户可以在设备中保持其生物特征数据的隐私性,下载用于生成 IrisCode 的 ML 模型,本地运行推断,并创建 ZKP 来证明他们成功创建了 IrisCode。所生成的证据保证了推断的真实性,同时也保护了数据隐私。ML 模型的高效 zk 证明机制(例如由 Modulus Labs 开发的机制)对于此用例至关重要。
- 另一种模型是专有模型。ZKP 有两种可能的方式可以帮助解决这个问题。第一种方法是,在将匿名化数据发送到 ML 模型之前,使用 ZKP 对用户数据进行匿名化,就像在数据集创建案例中讨论的那样。另一种方法是在将预处理输出发送到 ML 模型之前,对私有数据进行本地预处理。在这种情况下,预处理步骤隐藏了用户的私有数据,使其无法被重构。用户生成一个 ZKP 来证明预处理步骤的正确执行,然后可以远程在模型所有者的服务器上执行其余专有模型。这里的应用场景包括 AI 医生,可以分析患者的医疗记录以进行潜在诊断,以及评估客户私人财务信息的金融风险评估算法。
内容真实性和对抗深度伪造技术
ChatGPT 可能已经从那些专注于生成图片、音频和视频的生成式人工智能模型中夺得了风头。然而,这些模型目前能够生成逼真的深度伪造内容。最近由 AI 生成的 Drake 歌曲就是一个很好的例子。这些深度伪造技术代表着一个重大威胁,有许多创业公司正在尝试使用 Web 2 技术解决这个问题,但是 Web3 技术(如数字签名)更适合解决这个问题。
在 Web3 中,用户交互(即 Transactions)通过用户的私钥进行签名以证明其有效性。同样,无论是文本、图片、音频还是视频等内容都可以通过创建者的私钥进行签名,以证明其真实性。任何人都可以根据创建者的公共地址验证签名,该地址提供在创建者的网站或社交媒体账户上。Web3 网络已经建立了所有用于这种用例的基础设施。Fred Wilson 讨论了将内容与公钥关联起来如何有效地对抗虚假信息。许多知名的 VC 已经将他们现有的社交媒体个人资料(如 Twitter)或去中心化社交媒体平台(如 Lens Protoocl 和 Mirror)与加密公共地址相连,这为数字签名作为内容认证方法的可信度提供了支持。
尽管这个概念很简单,但是需要做很多工作来改善这个认证过程的用户体验。例如,需要自动化创建内容的数字签名过程,以为创建者提供无缝的流程。另一个挑战是如何生成已签名数据的子集,例如音频或视频片段,而无需重新签名。许多现有的 Web3 技术都独特地解决了这些问题。
专有模型的信任最小化
Web3 可以使 AI 受益的另一个领域是,在提供专有 ML 模型作为服务时,可以将对服务提供商的信任程度降到最低。用户可能需要验证他们是否获得了花钱购买的的服务,或获得公平执行 ML 模型的保证,即所有用户都使用相同的模型。可以使用 ZKP 来提供这些保证。在这种架构中,ML 模型创建者生成表示 ML 模型的 zk 电路。然后在需要时使用电路为用户推断生成 ZKP。ZKP 可以发送给用户进行验证,也可以发布到处理用户验证任务的公共链上。如果 ML 模型是私有的,独立第三方可以验证使用的 zk 电路确实代表该模型。ML 模型的信任最小化,在模型的执行结果具有高风险时将会特别有用。示例包括:
1、ML 医疗诊断
在这种用例中,患者向 ML 模型提交他们的医疗数据以进行潜在诊断。患者需要保证目标 ML 模型已经正确地应用于他们的数据。推理过程生成一个 ZKP,证明了 ML 模型的正确执行。
2、贷款信用评估
ZKP 可以确保银行和金融机构在评估信用价值时考虑到申请人提交的所有财务信息。此外,ZKP 可以通过证明所有用户使用相同的模型,来证明公平性。
3、保险索赔处理
当前的保险索赔处理是手动和主观的。ML 模型可以更好地公正地评估保险单和索赔详细信息。结合 ZKP,这些索赔处理 ML 模型可以被证明已经考虑了所有保单和索赔细节,并且能保证同一模型用于处理同一保险单下的所有索赔。
解决模型创建的中心化问题
创建和训练 LLM (大语言模型)是一个漫长而昂贵的过程,需要特定领域的专业知识、专用计算基础设施和数百万美元的计算成本。这些特点可能导致强大的中心化实体,例如 OpenAI,它们可以通过限制对其模型的访问,获得巨大的权力。
考虑到这些中心化风险,关于 Web3 如何促进 LLM 创建中的去中心化问题,就成了研究的重点。一些 Web3 倡导者提出了分布式计算的方法,与中心化参与者竞争。其核心思想是分布式计算可以是一种更便宜的替代方案。然而,我们的观点是,这可能不是与中心化参与者竞争的最佳角度。分布式计算的劣势在于,因不同异构计算设备之间的通信开销,ML 训练可能会变慢 10-100 倍。
相反,Web3 项目可以专注于以 PoPW 风格创建独特且具有竞争力的 ML 模型。这些 PoPW 网络还可以收集数据以构建唯一的数据集来训练这些模型。一些正在朝着这个方向发展的项目包括 Together 和 Bittensor。
AI 代理的支付和执行框架
过去几周见证了 AI 代理的兴起,这些代理利用 LLM 来推理实现特定目标所需的任务,甚至执行这些任务以实现目标。AI 代理浪潮始于 BabyAGI,并迅速扩散到包括 AutoGPT 在内的高级版本。这里的一个重要预测是,AI 代理将变得更加专业化,以在某些任务中表现出色。如果存在专门的 AI 代理市场,则 AI 代理可以搜索、雇佣和支付其他 AI 代理来执行特定任务,从而完成主项目。在这个过程中,Web3 网络为 AI 代理提供了一个理想的环境。对于支付,可以为 AI 代理配备加密货币钱包,用于接收款项和支付给其他 AI 代理费用。此外,AI 代理可以插入加密网络,以在无许可的情况下委托资源。例如,如果 AI 代理需要存储数据,AI 代理可以创建一个 Filecoin 钱包并支付 IPFS 上的去中心化存储费用。AI 代理还可以委托来自 Akash 等去中心化计算网络的计算资源来执行某些任务,甚至扩展其自身的执行能力。
防止 AI 侵犯隐私
考虑到训练高效 ML 模型所需的大量数据,可以预料到任何公共数据都会进入到模型中,以使用这些数据来预测个人行为。此外,银行和金融机构可以建立自己的 ML 模型,该模型是基于用户的财务信息进行训练的,并且能够预测用户未来的财务行为。这可能是对隐私的重大侵犯。唯一减轻这种威胁的方法是,金融交易隐私是默认被保护的。而在 Web3 中,这种隐私可以通过使用隐私支付区块链(如 zCash 或 Aztec)和私有 DeFi 协议(如 Penumbra 和 Aleo)来实现。
链上游戏
1、非编程游戏玩家的机器人生成
像 Dark Forest 这样的链上游戏创造了一种独特的范例,玩家可以通过开发和部署执行所需游戏任务的机器人来获得优势。这种范式转变可能会排除没有代码能力的游戏玩家。然而,LLM 可以改变这一点。LLM 可以被精细调整以理解链上游戏逻辑,并允许玩家创建反映玩家策略的机器人,而不需要玩家编写任何代码。Primodium 和 AI Arena 等项目正在致力于为他们的游戏招募人类和 AI 玩家。
2、机器人战斗、下注和博彩
链上游戏的另一种可能性是完全自主的 AI 玩家。在这种情况下,玩家是一个 AI 代理,例如 AutoGPT,它使用 LLM 作为后端并可以访问外部资源,例如互联网访问和潜在的初始加密货币资金。这些 AI 玩家可以以机器人大战的方式进行投注。这可以为投机和押注这些赌注的结果打开市场。
3、为链上游戏创建逼真的 NPC
当前的游戏很少关注非玩家角色(NPC)。NPC 的行动有限,并且对游戏进程影响很小。考虑到 AI 和 Web3 的协同作用,可以创建更具吸引力的 AI 控制的 NPC,打破可预测性,使游戏更加有趣。这里可能面临的一个挑战是如何引入有意义的 NPC,同时最小化与 NPC 活动相关的 TPS 。NPC 活动的 TPS 要求过高可能导致网络拥塞和实际玩家的用户体验不佳。
去中心化社交媒体
当前去中心化社交平台的挑战之一是,与现有的中心化平台相比,它们没有提供独特的用户体验。与 AI 的无缝集成可以提供缺乏 Web 2 替代方案的独特体验。例如,AI 管理的帐户可以通过分享相关内容、评论帖子和参与讨论来帮助吸引新用户加入网络。AI 帐户还可以用于新闻聚合,总结与用户兴趣相匹配的最近趋势。
去中心化协议的安全性和经济性设计测试
基于 LLM 的AI 代理,可以自定义目标、创建代码并执行这些代码,为去中心化网络的安全性和经济可行性提供了实际测试的机会。在这种情况下,AI 代理被指示检查协议的安全或经济平衡。AI 代理可以通过审查协议文档和智能合约,并确定弱点。然后,AI 代理可以独立地执行攻击协议的机制,以最大化自己的收益。这种方法模拟了协议在发布后可能你会面临的实际环境。根据这些测试结果,协议的设计者可以审查协议设计并修补弱点。到目前为止,只有专门的公司,例如 Gauntlet,提供此类去中心化协议服务所需的技术技能集。然而,对于接受过 Solidity、DeFi 机制和以前的开发机制培训的 LLM,我们希望 AI 代理可以提供类似的功能。
用于数据索引和指标提取的 LLM
尽管区块链数据是公开的,但对该数据进行索引并提取有用的见解仍然是一项持续的挑战。这个领域的一些参与者(例如 CoinMetrics)专注于索引数据和构建复杂的指标以进行销售,而其他参与者(如 Dune)则专注于索引原始交易的主要组成部分,并通过社区贡献以众包的形式完成指标创建。随着最近 LLM 的进展,我们清楚地看到了数据索引和指标提取可能被颠覆的趋势。Dune 已经意识到了这种威胁,并公布了一个 LLM 路线图,包括 SQL 查询解释和基于 NLP 的查询潜力等组件。然而,我们预测 LLM 的影响将更深入。这里的一种可能性是,基于 LLM,可以为特定的指标索引数据,并直接与区块链节点交互。像 Dune Ninja 这样的初创公司已经在探索创新的 LLM 应用程序,用于数据索引。
引导开发者进入新生态系统
不同的区块链互相竞争,吸引开发人员在该生态系统中构建应用程序。Web3 开发人员的活跃,是特定生态系统成功的重要指标之一。对于开发人员而言,一个主要的痛点是在学习和构建新兴生态系统时不能及时获得支持和指导。已经有一些生态系统投资数百万美元成立了专门的 Dev Rel 团队来支持探索该生态的开发人员。在这方面,新兴的 LLM 已经展示了惊人的结果,可以解释复杂的代码,捕捉错误甚至创建文档。精细调整过的 LLMs 可以与人类经验相辅相成,显著提高 dev rel 团队的工作效率。例如,LLMs 可以用于创建文档、教程、回答常见问题,并且甚至可以通过提供样板代码或创建单元测试来支持 hackathon 中的开发人员。
改进 DeFi 协议
通过将 AI 集成到 DeFi 协议的逻辑中,可以显着提高许多 DeFi 协议的性能。到目前为止,在 DeFi 中集成 AI 的主要瓶颈是,在链上实施 AI 的成本过高。AI 模型可以在链下实现,但以前没有办法验证模型执行。但是,借助像 Modulus 和 ChainML 这样的项目,链下执行的验证正在变得可能。这些项目允许在链下执行 ML 模型,同时限制了链上成本的扩张。对于 Modulus 来说,链上费用仅限于验证模型的 ZKP;对于 ChainML 来说,则是支付给去中心化 AI 执行网络的预言机费用。
一些可以从 AI 集成中受益的 DeFi 用例:
- AMM 流动性提供,即更新 Uniswap V3 流动性范围。
- 使用链上和链下数据进行债务头寸的清算保护。
- 复杂的 DeFi 结构化产品,其中保险库机制由金融 AI 模型定义,而不是固定策略。这些策略可以包括由 AI 管理的交易、借贷或期权。
- 可以考虑不同链、不同钱包的链上信用评分机制。
结论
我们相信 Web3 和 AI 在文化和技术上是兼容的。与倾向于厌恶机器人的 Web2 相比,Web3 允许 AI 蓬勃发展,这要归功于其无需许可的可编程特性。
更广泛地说,如果您将区块链视为一个网络,那么我们预计 AI 将主导网络的边缘(译者注:指进入网络的交互点)。这适用于各种消费者应用程序,从社交媒体到游戏。
到目前为止,Web3 网络的边缘大多是人类。人类发起并签署交易或实施具有固定策略的机器人来代表他们行动。
随着时间的推移,我们将在网络边缘看到越来越多的 AI 代理。AI 代理将通过智能合约与人类以及彼此进行交互。这些互动将带来新颖的消费者体验。
深潮 TechFlow 是由社区驱动的深度内容平台,致力于提供有价值的信息,有态度的思考。
社区:
订阅频道:https://t.me/TechFlowDaily
推特:@TechFlowPost
进微信群添加助手微信:blocktheworld