
Welcome to Footprint Analytics API
Footprint has a unique and very flexible API that allows you to build full-fledged data pipelines for data analysis, as well as machine learning applications. This is achieved by providing two types of interfaces: the first is for uploading data to the platform (Upload API); the latter is for obtaining data from the platform (Data API). The implementation of the first one is quite trivial and requires only one endpoint. To use the Upload API please proceed to the following link:
Data API is a more complex interface, involving more ways to interact and allowing blockchain and DApp developers to gain insight from the distributed ledger covering the scenarios like track whales, NFT collections, GameFi data, and more, from 20 chains.
We have developed two types of API and two sub-types within one of them in order to cover most of the cases.
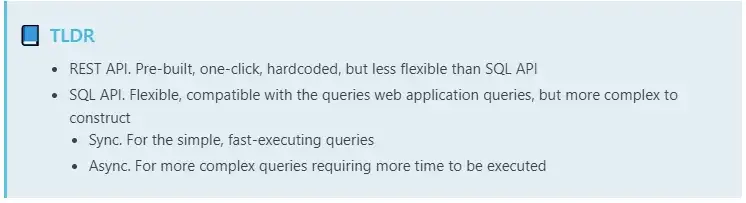
REST API allows to quickly integrate an application, since each endpoint is a pre-built, hard-coded script that we have identified ourselves as one of the most popular. All endpoints come with easy-to-use tools for filtering, sorting, and pagination.
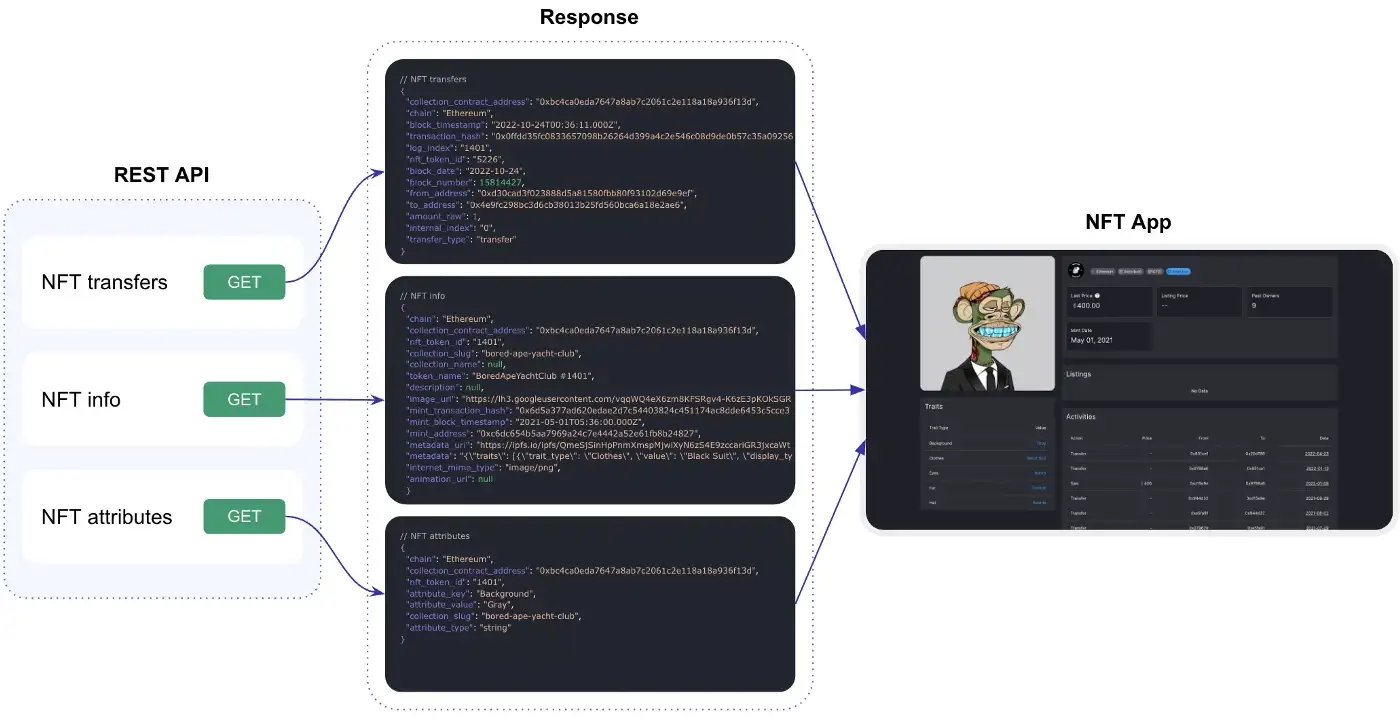
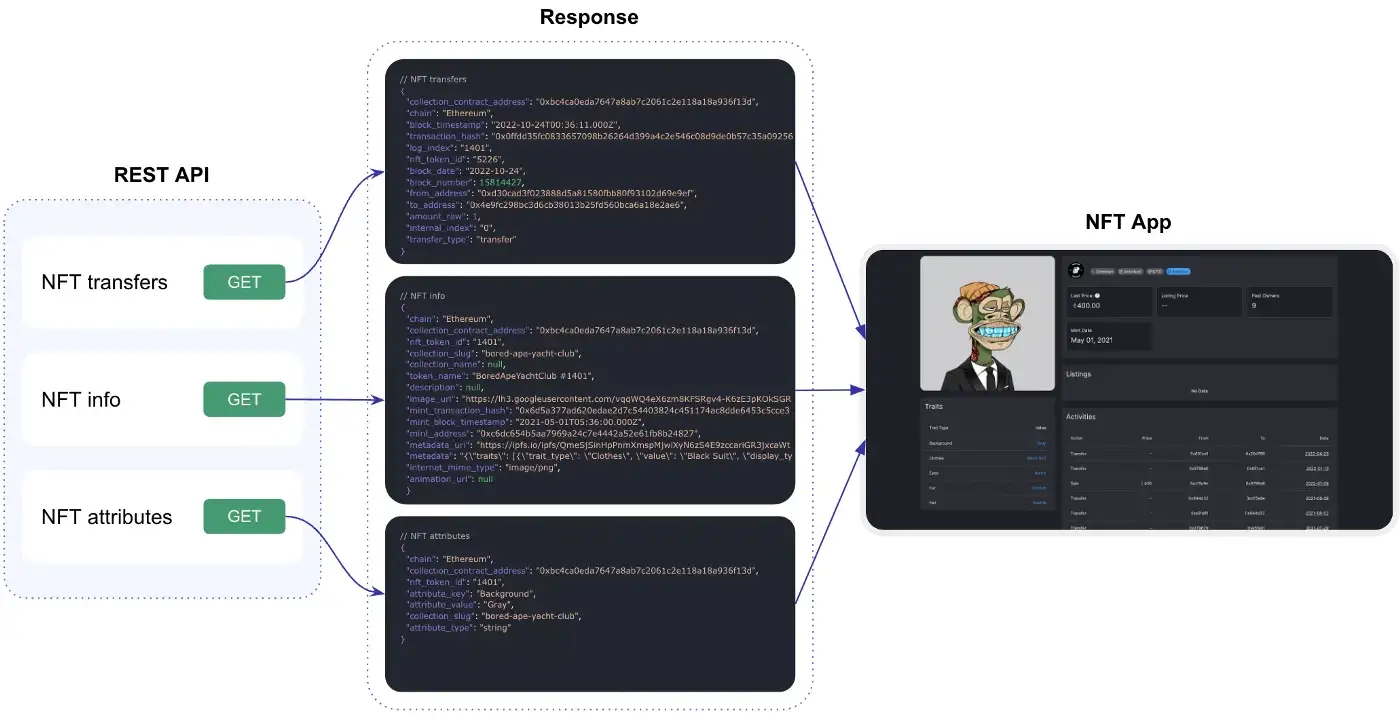
REST API
The SQL API is a more flexible interface and allows you to get this for more narrow scenarios. The SQL API was designed in such a way that before its immediate use, it was possible to get a visualization within the web application, and then copy and paste the SQL code into the SQL API so that the same data is received. More details about this process are described on the following page:
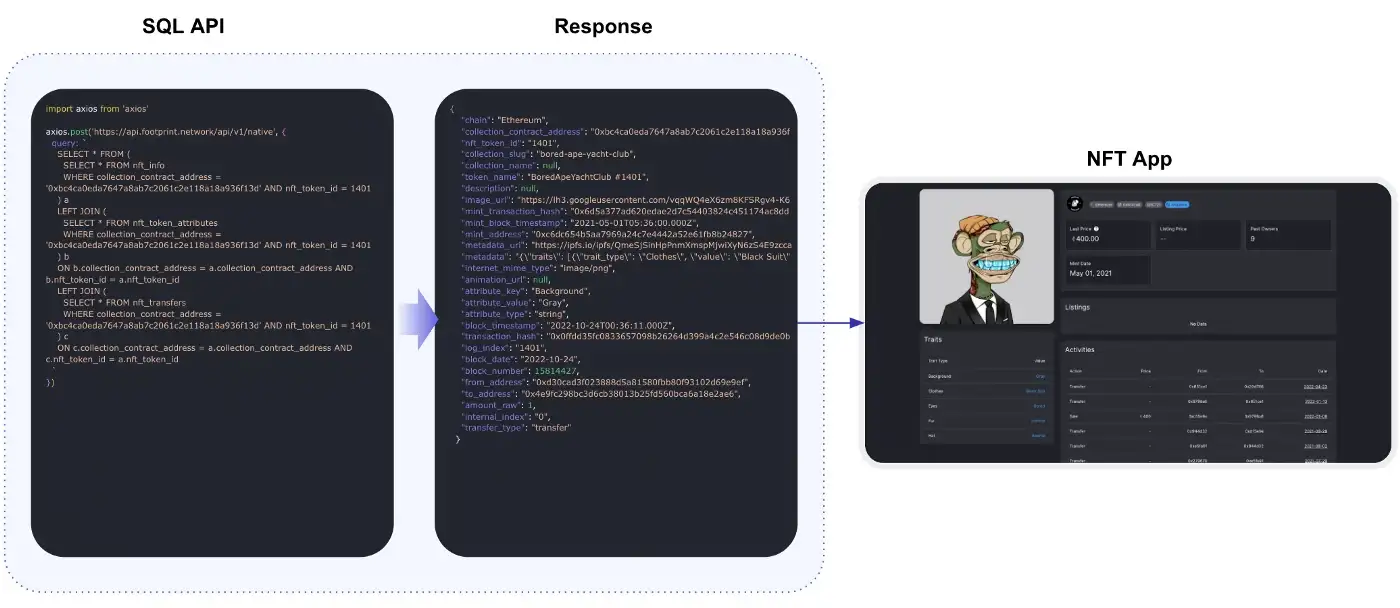
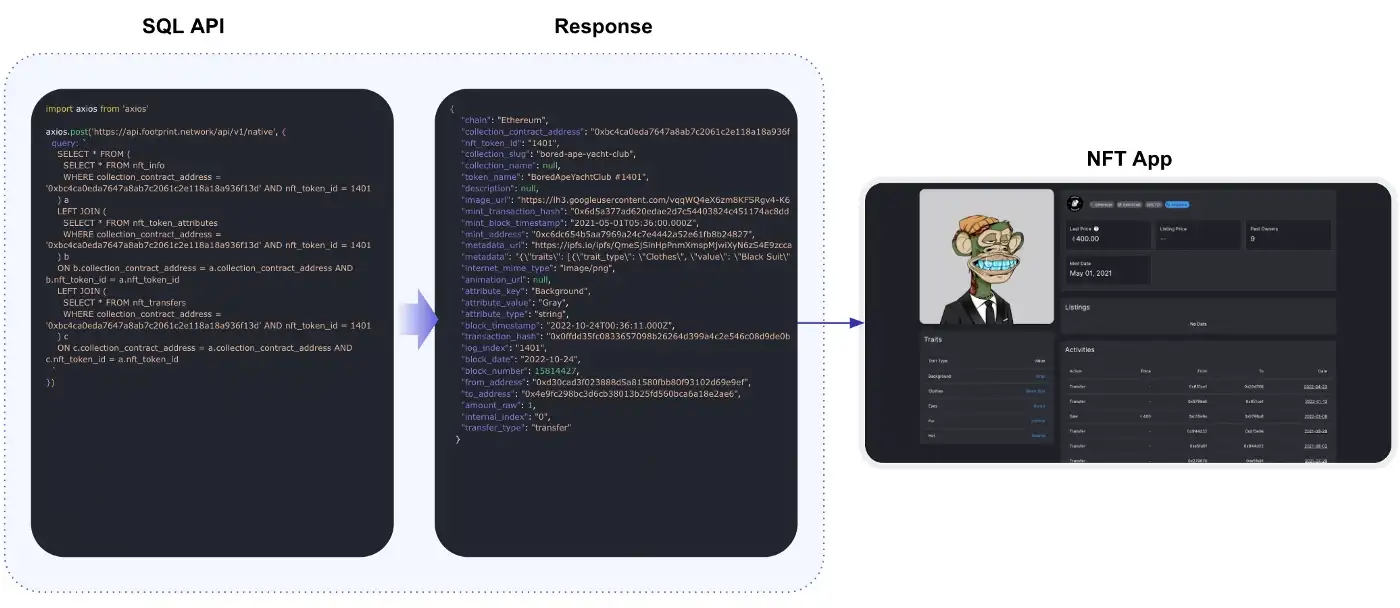
SQL API
Within the Footprint, there are two modes for executing queries to the SQL API — synchronous and asynchronous. API call to the synchronous endpoint implies the SQL query will be executed by the Footprint servers as soon as an HTTP request is received from the application, thereby maintaining the connection. This makes sense when using lightweight requests, as in this case the application does not have to wait long for execution. The details could be found on the following page:
For heavy requests, it is recommended to use an asynchronous request. Unlike a synchronous one, the client application does not have to maintain a connection with the server during execution, but instead can simply get the request id immediately, according to which, after some time, separately get the execution results. As part of the asynchronous API, two step should be covered to fetch the data — the following endpoint will be used to send an “order” for SQL execution:
The second step is to send a request to receive results by the identifier obtained when accessing the previous endpoint. The endpoint for this second step is described on the following page:
Overview of Footprint’s API Offerings
- NFT data endpoints
Fetch NFT ownership, transfer, price, order book, metadata, and more, making it easy to build NFT applications instantly. - GameFi data endpoints
All-in-one API allows access to all blockchain data from the GameFi industry to single game. - Chain data endpoints
Covering most chains and support from raw data to analytic metrics. - Address data endpoints
Enabled developers to easily query any wallet address for interaction history, token balance of each asset and other metrics. - Token data endpoints (Coming soon)
Enabled developers to easily query a list of tokens, 5-minute prices, minting and burning of tokens and other metrics like market cap, trading volume. - DeFi data endpoints (Coming soon)
Enables developers to easily query a list of DeFi pools, TVL, liquidity of each DEX pools, transactions of options and more.
Use cases
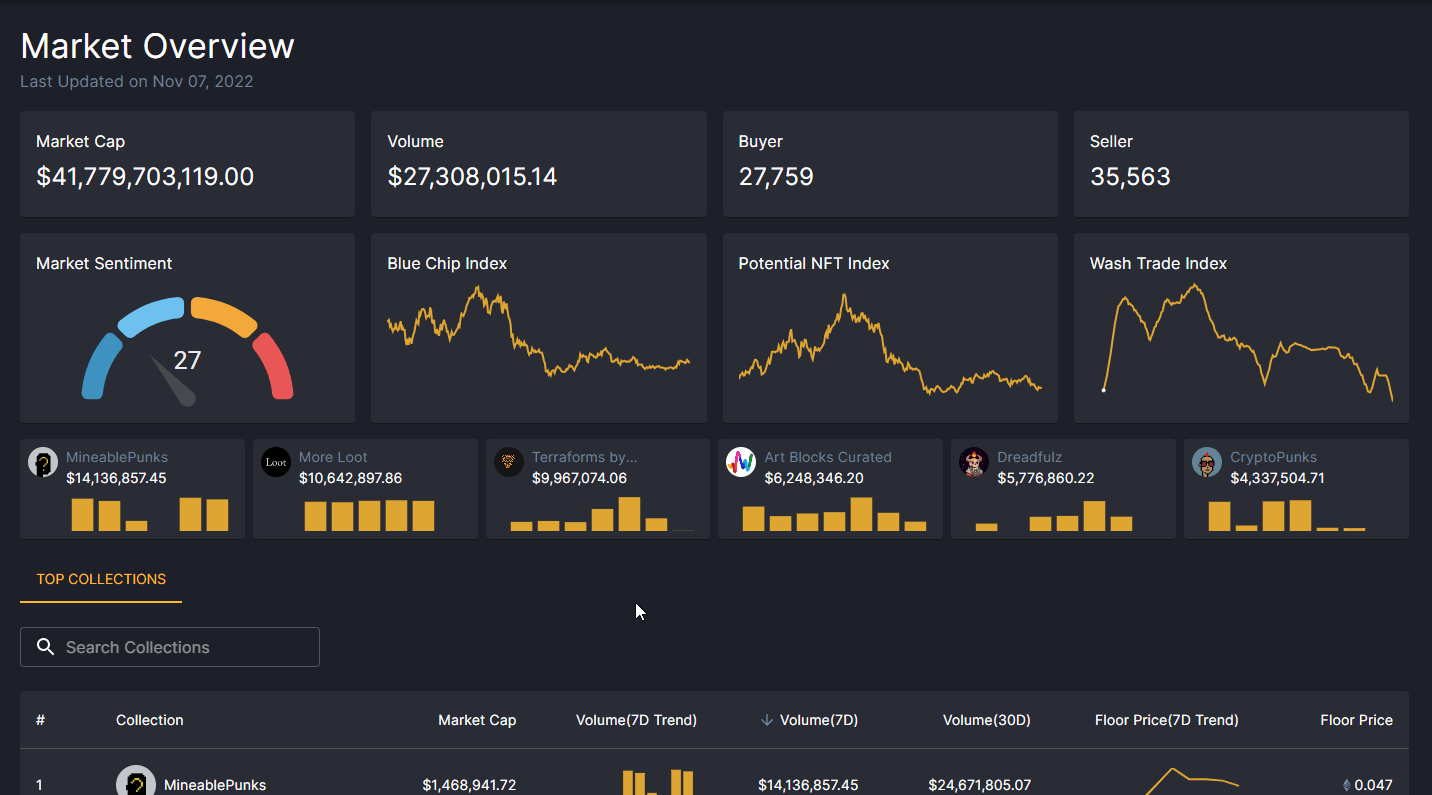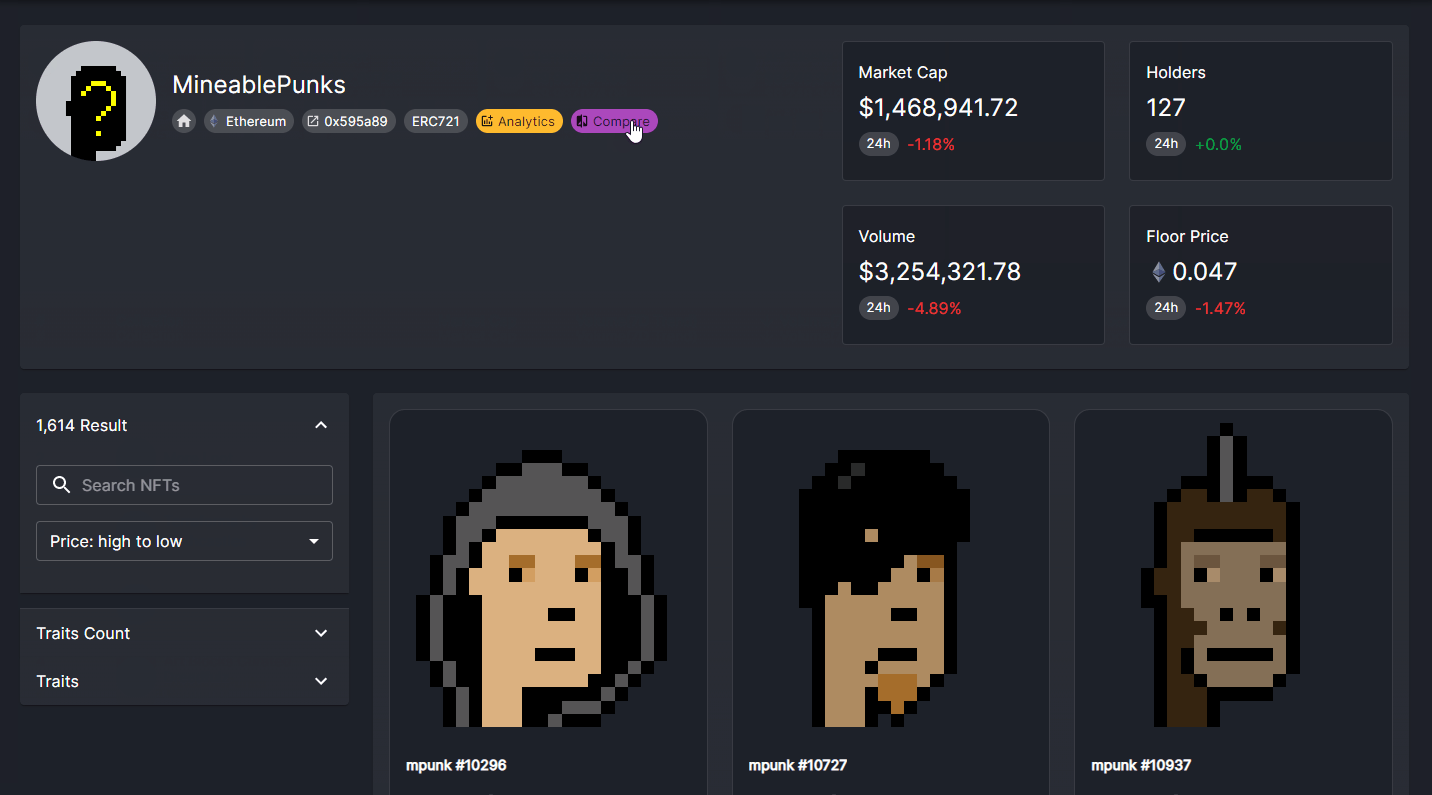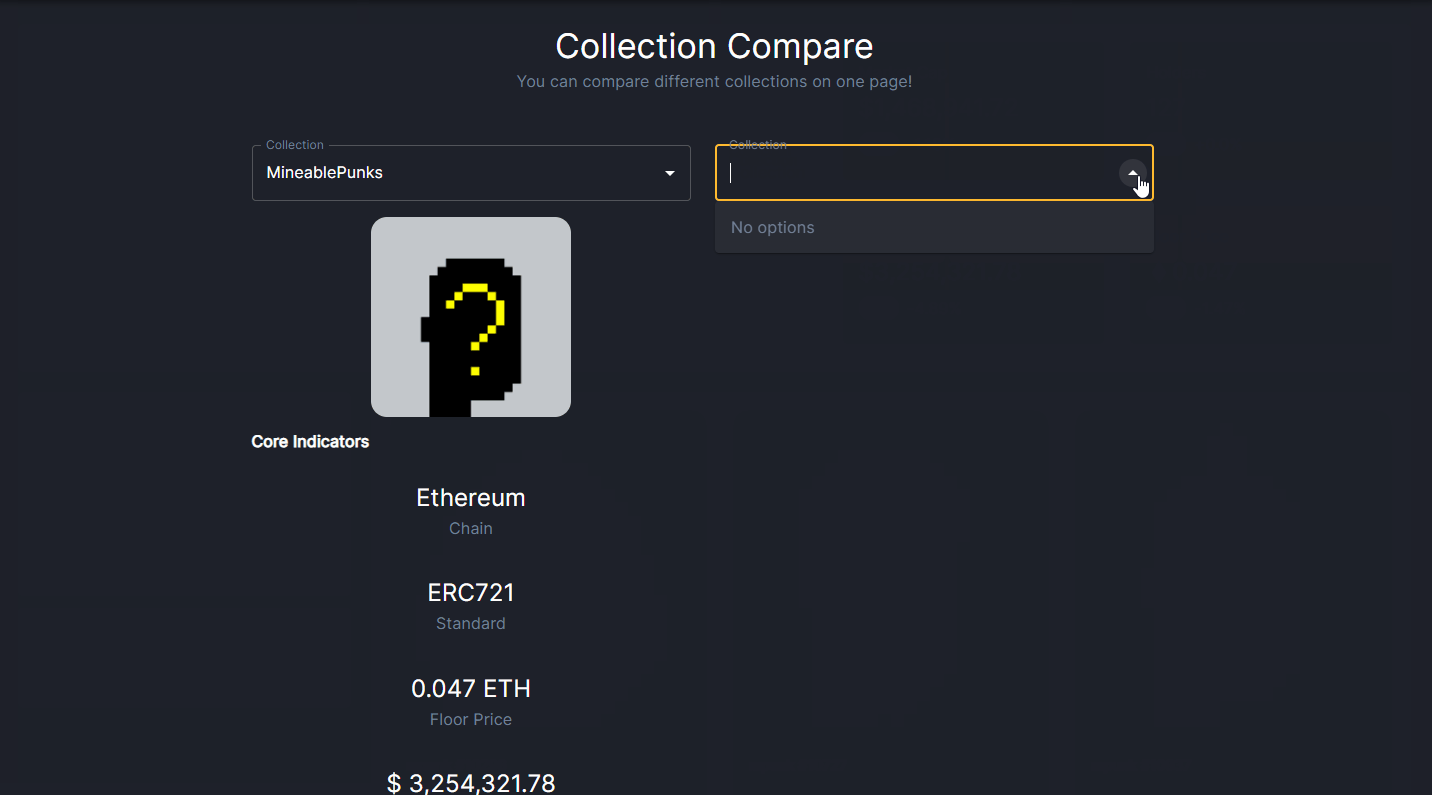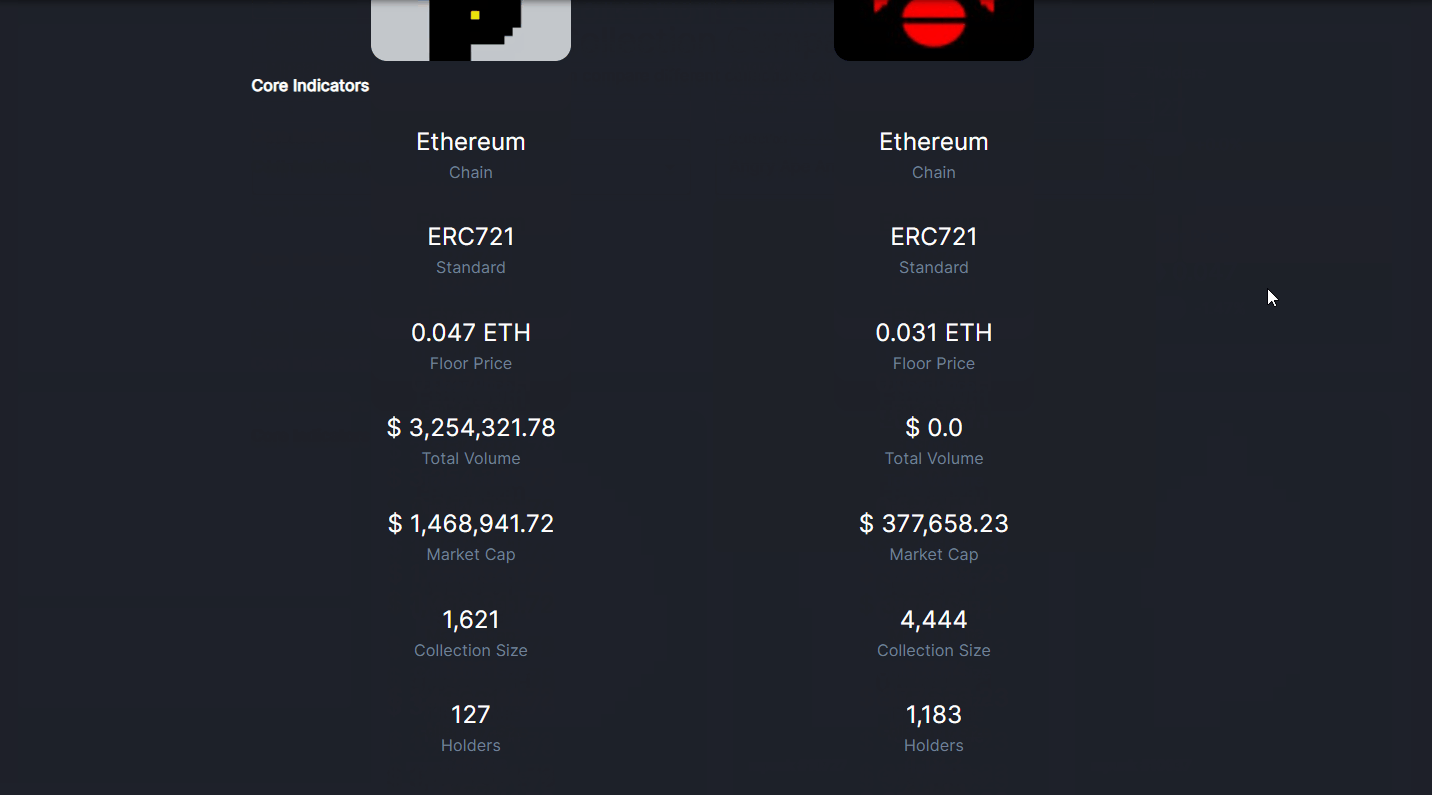

NFT collection comparison use-case


NFT market overview application use-case
Why use Footprint API
Footprint provides enterprise-grade Web3 APIs that connect any tech stack to blockchain networks.
Our 24/7 worldwide support ensures your project’s easy launch, priority maintenance, and sustainable growth, with custom SLAs to support your demands.
- Unified API
One call to retrieve all data across any supported blockchain - Full dataset
Covering full dataset from raw data to statistics metrics - Stability and Reliability
Highest quality data with top protocols being manually verified - Customized
Supports both REST API and SQL API for open and flexible data access methods
API key
To start exploring the Footprint Data API, you would need to sign up for an API key here.
Deployments
The core team runs a production-ready instance of the Footprint Analytics API with the following endpoints:
- Stable
https://api.footprint.network/ - Beta
https://api-test.footprint.network/
Versioning
In order to ensure backwards compatibility, any changes to API endpoints are deployed as new versions. We will strive to keep old versions available for as long as possible, while also working closely with you to help upgrade.