บทความต้นฉบับ:

Data Availability (DA) หมายถึงการมีอยู่ของ data ของธุรกรรมที่เกี่ยวข้องและจำเป็นในการตรวจสอบความถูกต้องของ block และเนื่องด้วยการที่มันมีความเกี่ยวข้องโดยตรงกับความสามารถในประสิทธิภาพ, การใช้งานที่เป็นไปได้, และการขยายของ Ethereum network ทำให้ DA จึงกลายเป็นหนึ่งในความท้าทายด้านโครงสร้างพื้นฐานที่สำคัญที่สุดของ Web3
บทความนี้ที่พูดถึงการทำความเข้าใจวิวัฒนาการของ DA เป็นข้อมูลเชิงลึกขั้นสูงซึ่งจะทำให้ผู้อ่านเกี่ยวกับเทคโนโลยีนี้และทิศทางการพัฒนา รวมถึงกรณีการใช้งานหลักๆ เช่น AI on-chain อย่างแท้จริง ซึ่งกำลังใกล้เคียงความจริงขึ้นเรื่อยๆในขณะนี้
ในบทความนี้ เราจะครอบคลุมเรื่อง:
-
Data Availability และความสำคัญของมัน
-
การเกิดขึ้นของ DA Layer
-
ข้อจำกัดสำคัญที่ส่งผลต่อความก้าวหน้าของอุตสาหกรรม
-
สถาปัตยกรรมใหม่สำหรับงานที่ต้องการประสิทธิภาพสูง
ยุคแรกเริ่ม: 2017-2021
เพียงในช่วงแรกเริ่มของ Ethereum เราก็เห็นได้ชัดแล่วว่าความสามารถในการขยายขนาดเป็นปัญหาสำคัญ เยื่องจากเครือข่ายมีธุรกรรมประมาณ 1 ล้านรายการต่อวันในปี 2017 เพียงปีเดียว โดยมีวิธีแก้ปัญหาต่างๆที่ถูกเสนอไว้ ได้แก่:
-
Plasma: กรอบการทำงานการใช้ child chain ที่ส่ง data เป็นระยะไปยัง chain หลักของ Ethereum
-
Sharding: การประมวลผลธุรกรรม Horizontal processing สำหรับ Ethereum
-
State channels: ช่องทางธุรกรรม off-chain ที่ชำระ on-chain เมื่อผู้เข้าร่วมตกลงที่จะปิดธุรกรรม Layer 2 networks ถูกเลือกเป็นวิธีแก้ปัญหาหลัก โดยจัดการธุรกรรม off-chain แล้วส่งหลักฐานสรุปไปยัง Ethereum เพื่อพิสูจน์การดำเนินการที่ซื่อสัตย์ โดย Optimism และ Arbitrum เป็นสองตัวอย่างที่เปิดตัวในปี 2021 และรักษา data availability โดยเปิด data ธุรกรรม off-chain ที่ node เต็มรูปแบบใดๆ สามารถตรวจสอบได้
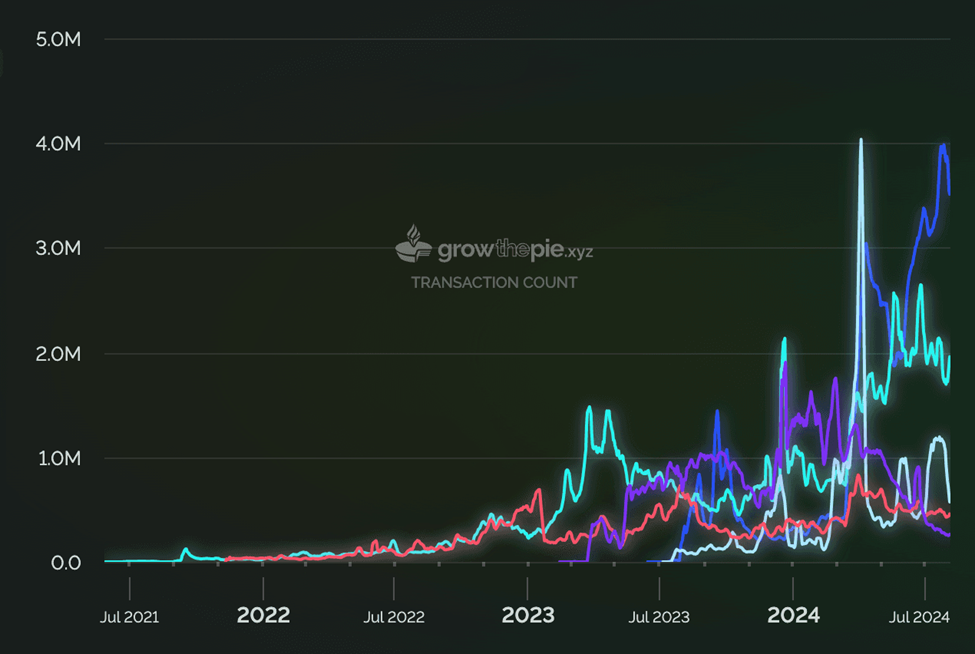
อย่างไรก็ตาม จำนวนธุรกรรมรายวันบน Layer 2 ได้เติบโตขึ้นอย่างมากตั้งแต่นั้นมา (ดูด้านบน) full node ของ Ethereum ซึ่งรับผิดชอบในการเก็บประวัติธุรกรรมทั้งหมดของ Ethereum จึงได้รับ data มากขึ้นเรื่อยๆ
ในขณะนั้น การอัปเกรด EIP-4844 ของ Ethereum ยังไม่เกิดขึ้น ซึ่งหมายความว่าการลง data ธุรกรรมของ Layer 2 ไปยัง Ethereum มีค่าใช้จ่ายสูงมาก จึงจำเป็นต้องมีโซลูชันที่สามารถพิสูจน์ความพร้อมใช้งานของ data ได้อย่างมีประสิทธิภาพ ซึ่งเป็นที่รู้จักกันในชื่อ data availability layer
การเกิดขึ้นของ Data Availability Layer: 2021-2023
ระหว่างปี 2021 ถึง 2023 โครงการต่างๆ เริ่มพัฒนา data availability layer (DAL) เหล่านี้ ซึ่งช่วยลดค่าใช้จ่ายในการทำให้ data พร้อมใช้งานอย่างมีนัยสำคัญ
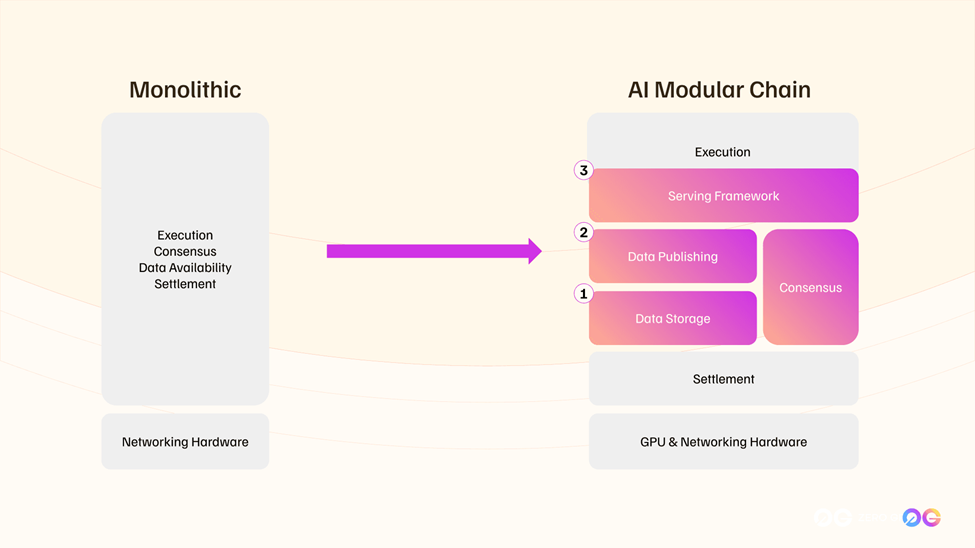
เพื่อทำความเข้าใจ DAL เราควรเริ่มจากโครงสร้างเครือข่ายที่มีสี่ layer ที่แตกต่างกัน:
-
Execution Layer: ตัวดำเนินการธุรกรรมที่มีความถูกต้องและ smart contract operations
-
Settlement Layer: สรุปและบันทึกธุรกรรมเพื่อให้แน่ใจว่าไม่สามารถเปลี่ยนแปลงได้
-
Data Layer: จัดเก็บและให้การเข้าถึง data ธุรกรรมและสถานะของ blockchain
-
Consensus Layer: ทำให้แน่ใจว่า node ทั้งหมดในเครือข่ายเห็นพ้องกันเกี่ยวกับสถานะปัจจุบันของ blockchain และลำดับของธุรกรรม
blockchain แบบ monolithic คือ blockchain ที่ full node ในเครือข่ายจัดการทั้ง 4 งาน โดย Ethereum จะเป็นตัวอย่างหนึ่งในกลุ่มนี้
ในทางตรงกันข้าม blockchain แบบ modular แยก Data และ Consensus ออกจาก Execution และ Settlement Layers ทำให้มีวิธีการจัดเก็บและตรวจสอบ data ที่ค่าใช้จ่ายถูกกว่า Celestia เปิดตัวในช่วงปลายปี 2023 ในฐานะผู้บุกเบิกรายแรกๆ โดยใช้การสุ่มตัวอย่างความพร้อมใช้งานของ data สำหรับการตรวจสอบ data อย่างมีประสิทธิภาพในด้านค่าใช้จ่าย ซึ่งทุกคนสามารถมีส่วนร่วมได้โดยไม่จำเป็นต้องมี full node
โดยสรุป วิธีนี้ทำงานโดยให้ light client (เวอร์ชันที่เบากว่าของ full node) แต่ละตัวเก็บ data เล็กๆ น้อยๆ และใช้การสุ่มตัวอย่างทางคณิตศาสตร์เพื่อพิสูจน์ว่า data ทั้งหมดมีอยู่จริงและถูกต้อง
โซลูชัน DAL อื่นๆ เช่น NEAR, EigenDA และ Avail ก็ได้เข้ามาในตลาดแล้ว โดยแต่ละ DAL มีแนวทางที่เป็นเอกลักษณ์ เช่น NEAR ที่พึ่งพาการแบ่ง shard และ EigenDA ที่ใช้คณะกรรมการตรวจสอบความพร้อมใช้งานของ data
ดังที่เราจะเห็น แต่ละโซลูชันมีข้อจำกัดที่ส่งผลกระทบอย่างมากต่อทั้งประสิทธิภาพและการใช้งานที่เป็นไปได้
ข้อจำกัดของ DAL: ตั้งแต่ปี 2566 เป็นต้นไป
ตอนนี้เราอยู่ในจุดที่น่าสนใจ ที่ DAL หลายตัวได้เปิดตัวและมีผู้ใช้มันเป็นโครงสร้างพื้นฐานมากมาย แต่เทคโนโลยีนี้ก็ยังไม่สามารถรองรับการใช้งานในอนาคตได้
เมื่อพิจารณาปัญหาคอขวดด้านประสิทธิภาพของ Celestia ซึ่งรวมถึงความเร็ว block ที่ 12 วินาที (ซึ่งหมายถึงยังค่อนข้างจะล่าช้า) ในขณะที่ปริมาณการทำธุรกรรมจำกัดอยู่ที่ 6.67 เมกะไบต์ต่อวินาที และแม้ว่าปริมาณการทำธุรกรรมของ NEAR จะมากกว่าสองเท่าของ Celestia แต่ความเร็วของทั้งสองโซลูชั่นยังไม่เพียงพอและเหมาะสมที่สุดเพียงสำหรับ Layer 2 ที่มีความต้องการด้านประสิทธิภาพไม่มากนัก
เมื่อการใช้งาน Web3 เติบโต ความต้องการในการประมวลผล on-chain อย่างทันท่วงที ปลอดภัย และคุ้มค่าก็เพิ่มขึ้นด้วย ความเป็นจริงคือโซลูชัน DA ที่มีอยู่ยังไม่เพียงพอสำหรับสิ่งนี้ และไม่สามารถรองรับการใช้งานต่างๆ เช่น:
-
AI on-chain: โมเดล AI ต้องเข้าถึง data จำนวนมากอย่างรวดเร็วและด้วยต้นทุนที่ต่ำสำหรับการ train โมเดล การอนุมานข้อมูล (data inferences) และอื่นๆ
-
การเทรดความถี่สูง (High-Frequency Trading): ต้องการการสืบค้นราคาในสมุดคำสั่งซื้อขายอย่างรวดเร็ว และการชำระเงินที่รวดเร็ว
-
เกม: ต้องการการเข้าถึง data เช่น สถานะเกม สินทรัพย์ การโต้ตอบของผู้เล่น และอื่นๆ อย่างรวดเร็ว
-
ความสามารถในการทำงานร่วมกัน (Interoperability): การแบ่งปัน data ระหว่างเครือข่าย blockchain ต่างๆ อย่างรวดเร็ว
-
ตลาด data: ที่ผู้ใช้สามารถจัดเก็บ อัปเดต และสืบค้น data on-chain ได้อย่างมีประสิทธิภาพ เปิดโอกาสทางธุรกิจใหม่ๆ เกี่ยวกับการแบ่งปันและการสร้างรายได้จาก data
โชคดีที่ด้วยความสำคัญของ DA ทำให้ DA ได้รับความสนใจอย่างกว้างขวางมากขึ้น และหลายคนกำลังแข่งขันกันสร้างโซลูชันที่มีประสิทธิภาพอย่างแท้จริงตามที่ต้องการ
นอกจากนี้ DA ยังเป็นตลาดขนาดใหญ่ ซึ่งหมายความว่าจะมีความต้องการด้านความพร้อมใช้งานของ data อย่างไม่มีที่สิ้นสุดและมีพื้นที่สำหรับโซลูชันมากมาย
Infinitely Scalable DA: ตั้งแต่ปี 2567 เป็นต้นไป
ในตลาด DA ผู้เล่นมากมายกำลังแข่งขันกันเพื่อตอบสนองการใช้งานข้างต้นและการใช้งานใหม่อื่นๆ โดยผู้ที่จะชนะในที่นี่จะต้องนำเสนอโซลูชันที่:
-
รวดเร็ว: ควรสามารถสืบค้นหรือตรวจสอบ data ได้ภายในเสี้ยววินาที คล้ายกับโซลูชันโครงสร้างพื้นฐาน data ของ Web2 เช่น AWS
-
ทำงานร่วมกันได้: สามารถรองรับเครือข่าย EVM และ non-EVM
-
ขยายได้มาก: สามารถทำงานร่วมกันในระดับโลกด้วยธุรกรรมนับพันล้าน (หรือมากกว่า) ในเวลาใดก็ได้ โดยเฉพาะอย่างยิ่งสำหรับ AI หรือการเทรดความถี่สูง
แม้ยังไม่มีโซลูชัน DA รุ่นแรกที่มีสามารถรองรับสิ่งนี้ในปัจจุบัน แต่มีทีมที่เก่งกาจมากมายที่กำลังทำงานกันอย่างหนัก
ในขณะเดียวกัน 0G ได้ระดมทุนรอบ pre-seed มูลค่า 35 ล้านดอลลาร์สำหรับสถาปัตยกรรม DA ใหม่ที่คาดว่าจะแก้ไขปัญหาข้างต้น
เราได้กล่าวถึงเรื่องนี้อย่างละเอียดในบล็อกโพสต์อื่นๆของเรา แต่โดยรวมแล้ว 0G มีระบบจัดเก็บ data ในตัวที่สามารถสืบค้นได้อย่างรวดเร็วเพื่อความพร้อมใช้งานของ data ที่ประมาณ 10-30 เมกะไบต์ต่อวินาที (เร็วกว่า Celestia 24 เท่า) นอกจากนี้ยังสามารถขยายได้ไม่จำกัด เนื่องจากสามารถเพิ่มเครือข่ายฉันทามติได้อย่างต่อเนื่อง โดยแต่ละเครือข่ายจัดจะการธุรกรรมแบบขนานกัน โดยมีจุดประสงค์ที่สำคัญเป็นอันดับแรกคือการตอบโจทย์ของโครงการ AI ที่ต้องการโซลูชัน DA เช่น 0G โดยเฉพาะ เพราะเรามุ่งเน้นที่จะทำให้ AI เป็นสาธารณประโยชน์
เทคโนโลยีนี้มีแนวโน้มที่น่าสนใจเป็นอย่างยิ่ง และนั่นคือเหตุผลที่นักลงทุนสนใจโครงการนี้มากเช่นกัน อย่างไรก็ตาม ทีมงานตระหนักดีว่านี่เป็นตลาดขนาดใหญ่ที่มีพื้นที่สำหรับหลายโซลูชัน และหวังว่าจะได้เห็นโซลูชันที่น่าสนใจอื่นๆ ที่นำเสนอเพื่อให้เราสามารถพัฒนาพื้นที่ตรงนี้ไปด้วยกัน
สุดท้ายนี้ เราหวังว่าบทความนี้ได้ครอบคลุมบริบทที่เป็นประโยชน์เกี่ยวกับสภาวะตลาดและประวัติการพัฒนา DA solution สำหรับผู้อ่านทุกคน
*หากคุณต้องการมีส่วนร่วมในการพัฒนา ecosystem กับเรา กรุณาส่งข้อความหาเราที่ https://0g.ai/contact!
*และอย่าลืมติดตามเราบน Twitter เพื่อติดตามข่าวสารล่าสุดของเราที่ https://x.com/0G_labs
