
I:总览
新兴的AI帝国及其他们对数据的渴求
“请把你的数据集给我们,如果你们给我们数据集,我们会非常高兴。”
– Sam Altman,在 "印尼人可以为 OpenAI 做什么 "活动现场中的一段有趣回答,雅加达,2023 年
打造最大、最强的大模型竞赛已经开始。科技巨头们正疯狂地互相竞争,争夺能够垄断行业的“力量”。
在AI领域,巨头总是拥有绝对的优势。由于,巨头企业拥有更多算力,所以也能训练出更大的模型。然而,一个大型语言模型的参数越多,它需要的数据量也就越大。
在过去的几个月里,模型开发者不仅达到了公开网络爬虫数据的极限(比如非营利性组织,定期抓取互联网公开网页的Common Crawl),也达到了由盗版材料构成的数据集的极限(如 Books3,它是 The Pile 的一个组成部分,而 The Pile 是用于训练 Llama 等模型的关键数据集)。
尝试根据自己的输出来训练模型,只会取得部分成功。研究表明,随着每次迭代,原始数据分布会逐渐退化,最终导致“模型崩溃”。我们目前面临这样一个处境:由于下一代模型过于庞大,以至于无法高效地基于生产商提供的合法数据进行有效训练。
为了获得更多数据,这些公司正在鼓励用户上传自己和他人的私人信息,有些公司甚至公开宣称,他们不仅打算继续窃取有版权保护的数据来训练模型,还会鼓励用户这样做,甚至会承担由此引发的任何纠纷的法律费用。
这种从“仅仅”个人不端行为发展到煽动他人做同样的事情,显然具有欺凌性质。甚至按照过去大科技公司不当的行为标准来看也是前所未有的。但这清楚地证明了大科技公司为喂养模型对数据和知识的极度渴望,以及小玩家在AI市场上的弱势地位。
当科技巨头们开始争夺未来AI的主导权:
许多人早已预见那些巨头公司之间会为获得专有数据的控制权而进行新的“龙争虎斗”。事实上,这场竞赛已经开始了。这场竞赛的目的是为拥有AI价值创造的所有关键因素的控制权与主导权。
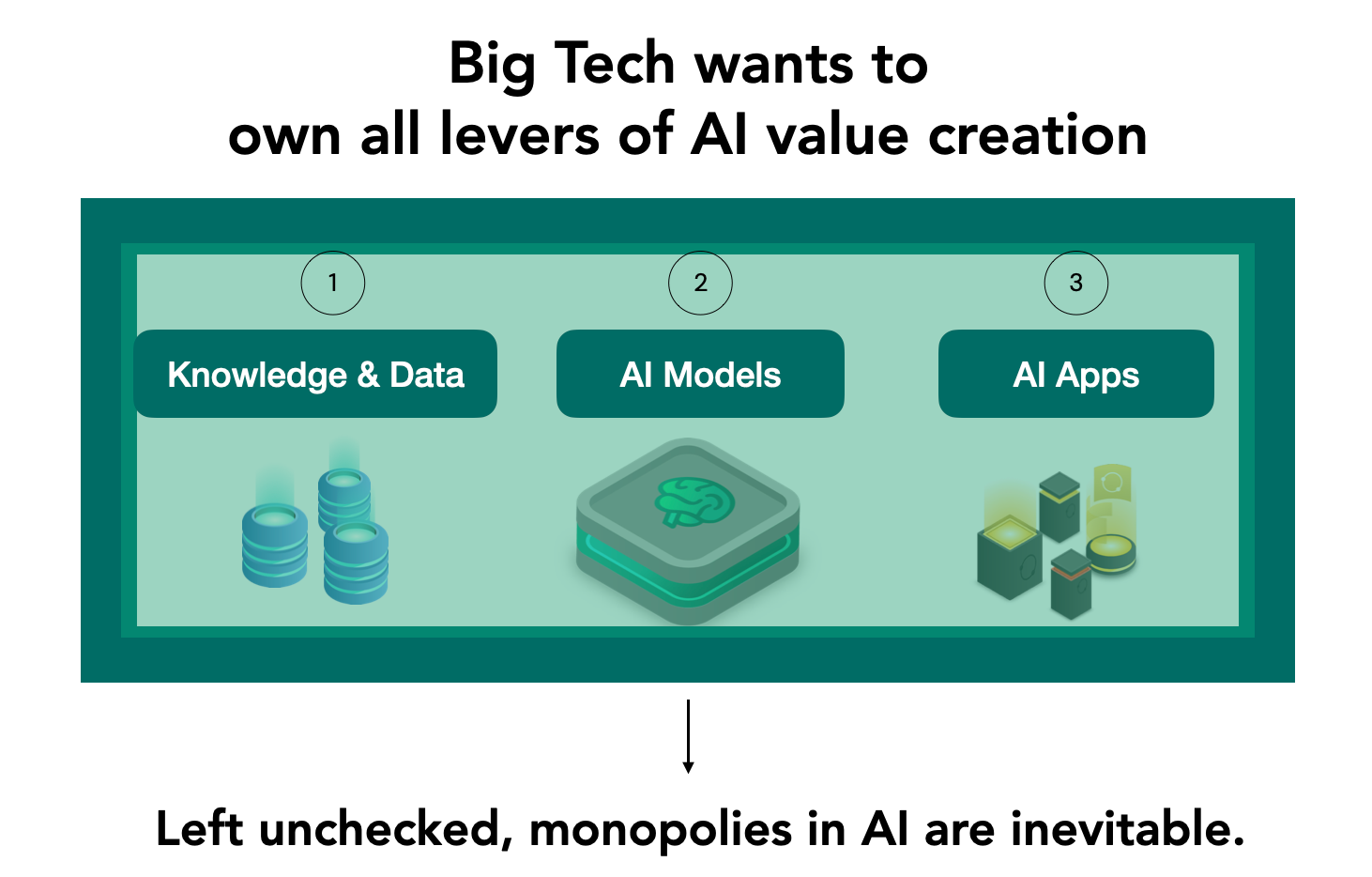
但正如上文所述,这些公司对知识和数据的高度依赖,为我们提供了扭转局面的最好机会。
对大型科技公司来说,他们可以毫不费力地支付所需的计算资源来训练规模更大的模型。通过拉拢立法者使竞争对手更难获取和使用高性能GPU,而且必要时还能够使用他人的知识产权进行训练。这些优势不断积累,有利于这些大公司,但对他们的供应商、竞争对手甚至用户都是十分不利的。
知识产权持有者的数据通常单独价值不高且分散在多个平台,缺乏保护自己权利的议价能力,只能受制于由二级持有者(发布平台)制定的数据安全政策。这在一定程度上解释了为什么最近许多AI公司转向检索增强生成(RAG)以及更小的定制模型和APP的原因:其目的是推迟训练下一代模型,直到从当前用户那里收集到更多数据。
每个曾经为互联网公共知识做出过贡献的人,他们的知识很可能已经被至少一个大语言模型吸收并成为其核心语料库的一部分。
目前还没有办法对AI模型或AI app使用的数据和知识的所有权进行归属追溯,因此也无法对交互进行记录核算。
然而,受到冲击的不仅仅是个人数据所有者。对于大多数用户而言,AI由三个要素组成:执行计算的模型、为其提供数据的数据库以及向用户展示结果的的app。在每种情况下,小型供应商都难以抗衡那些大型科技公司所拥有的垄断力量。
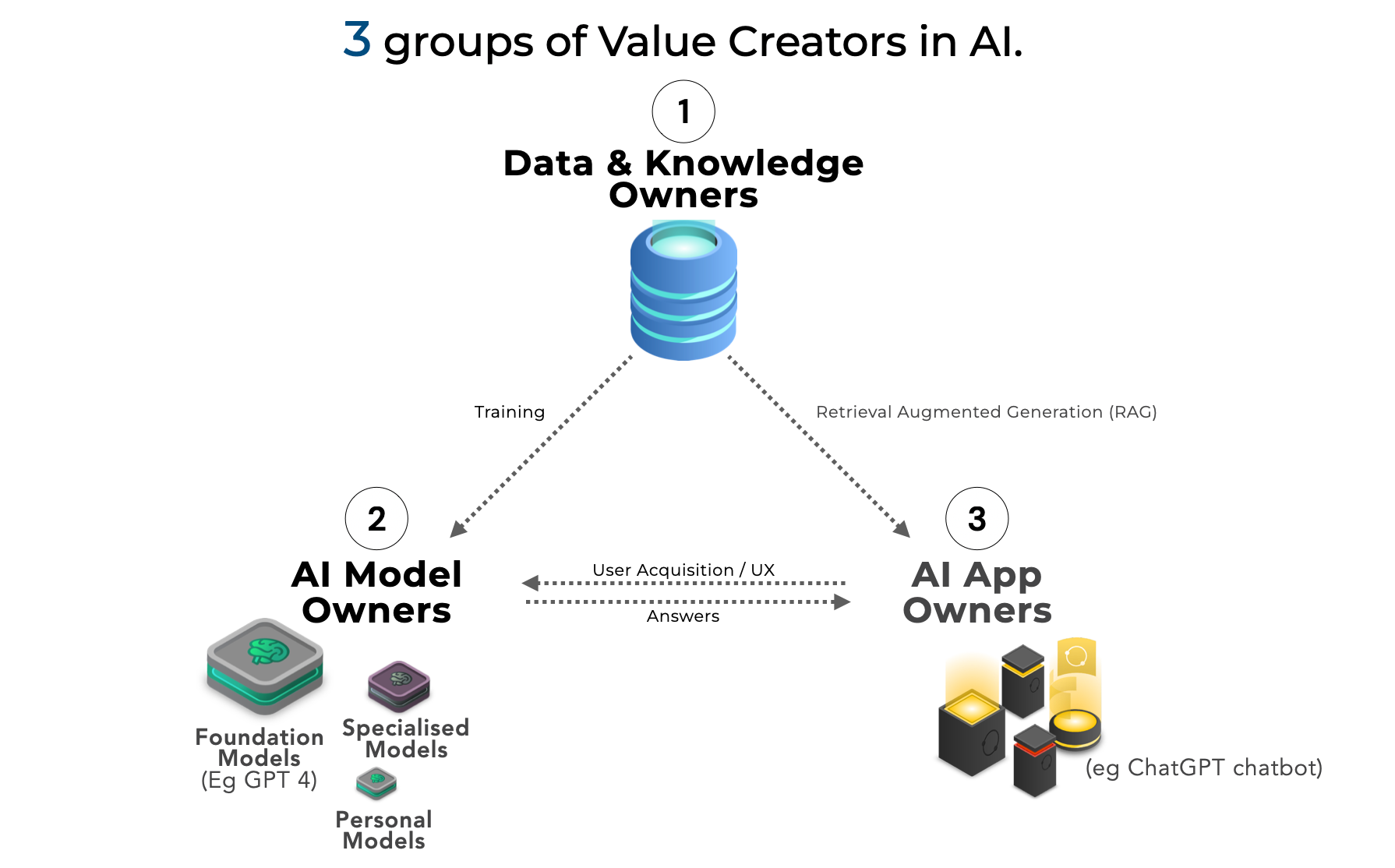
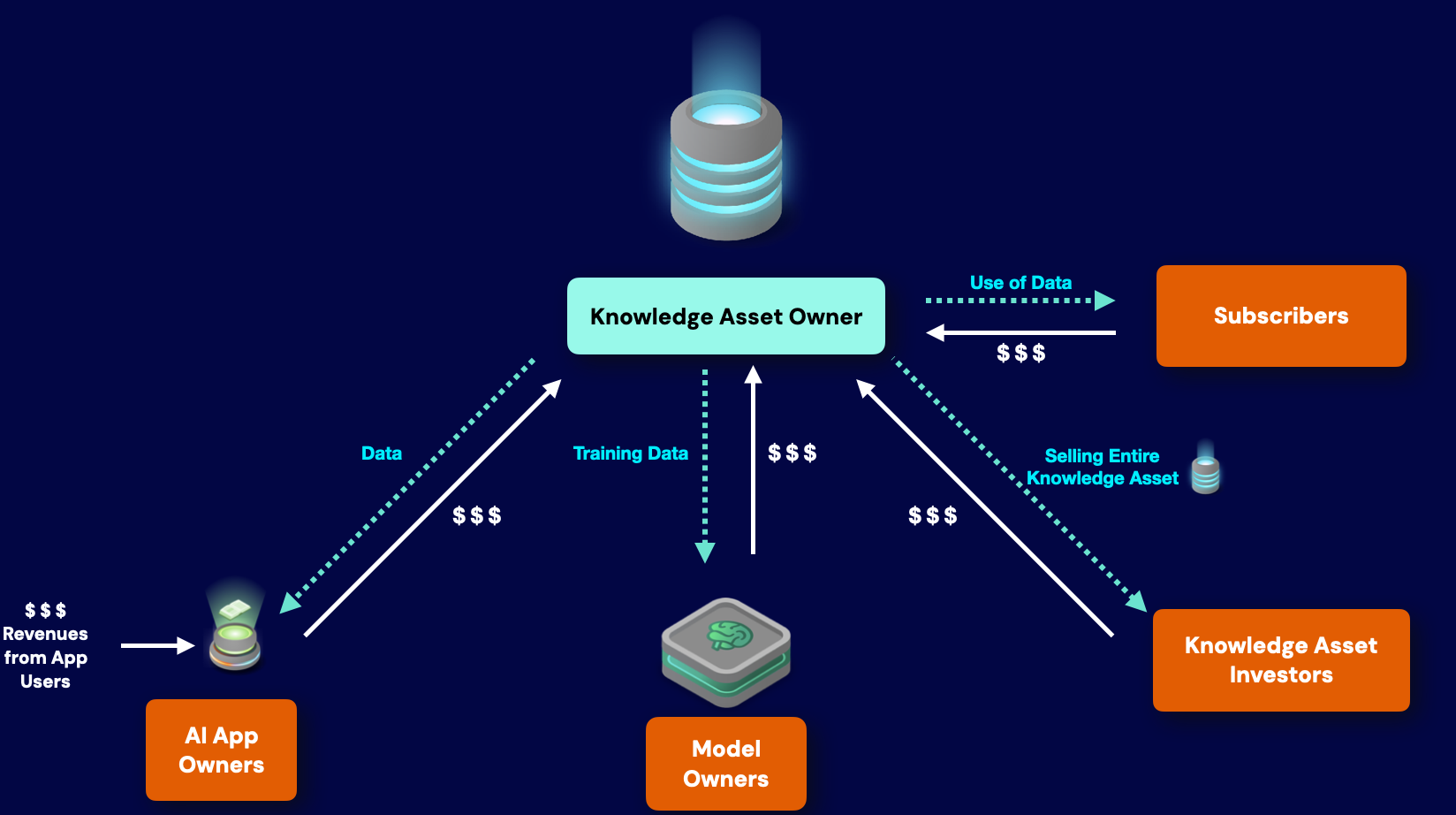
数据提供者往往被排除在AI的经济效益之外:
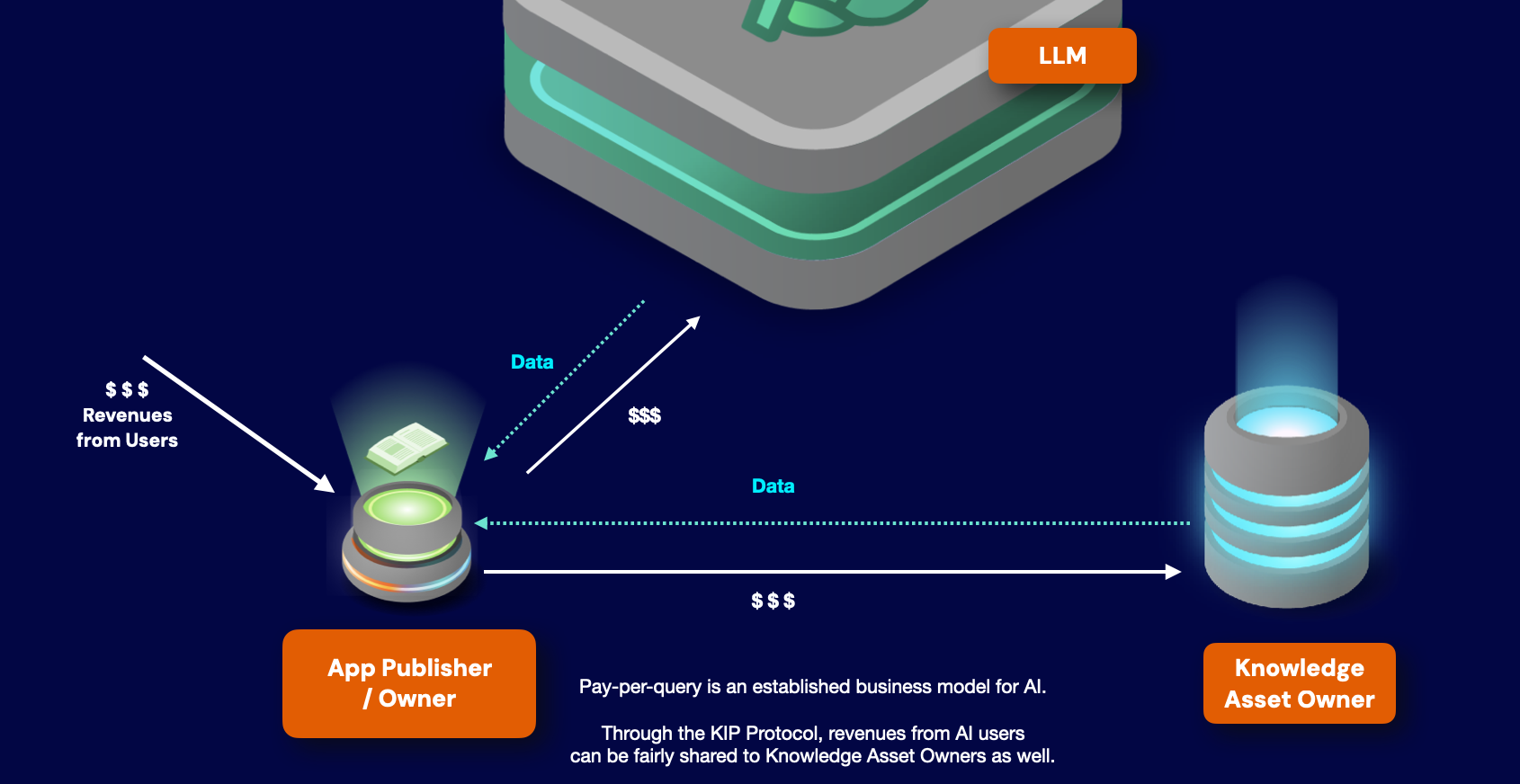
不管AI app界面是否有明确说明,AI实际上都是按查询次数计费的,月订阅费反映了用户平均月查询次数(通常API订阅会清楚说明这一点,而网页客户端用户一般是按月付费)。
当用户向AI app发出查询后,积分会被消耗以推进app与AI模型以及知识资产进行交互,来完成查询工作。这些积分在经济上代表了所使用的GPU计算能力,以及模型开发者/提供者的其他成本和利润。计算服务方、模型设计者和股东都能从这些收入中获益,但是协助构建整个框架的数据提供者却得不到分成。
参考:
Shumailov, Ilia, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. "Model Dementia: Generated Data Makes Models Forget." arXiv preprint arXiv:2305.17493 (2023). Growcoot, Matt, "Midjourney Founder Admits to Using a ‘Hundred Million’ Images Without Consent", Petapixel, 21 December 2022. Retrieved 15 November 2023: https://petapixel.com/2022/12/21/midjourny-founder-admits-to-using-a-hundred-million-images-without-consent/ Novak, Matt. "OpenAI To Pay Legal Fees Of Business Users Hit With Copyright Lawsuits", Forbes, 6 November 2023. Retrieved 15 November 2023: https://www.forbes.com/sites/mattnovak/2023/11/06/openai-to-pay-legal-fees-of-business-users-hit-with-copyright-lawsuits/?sh=1d98e71d51cd Song, Congzheng, and Ananth Raghunathan. "Information leakage in embedding models." In Proceedings of the 2020 ACM SIGSAC conference on computer and communications security, pp. 377-390. 2020.
AI联邦:一项提案
我们并不反对发展更大更好的模型。实际上,正因为我们想看到AI技术继续蓬勃发展,我们才想努力避免AI技术被科技巨头所垄断的尴尬局面。
基于上文提到的原因,我们相信一个能够包容多种参与角色的多样化生态系统,包括AI模型设计者、app开发者和知识/数据提供者,将更有效地为人类利益服务。
已经有几个项目在使用Web3技术和理念来实现AI的去中心化。
-
Bittensor:去中心化机器学习
-
Akash Network:去中心化的云计算资源市场
-
SingularityNET:去中心化AI服务市场
-
fetch.ai:针对AI代理的开放网络
-
Ocean Protocol:保护隐私的AI数据共享协议
-
Render Network:去中心化GPU云渲染
我们采取了不同但互补的方法:
KIP Protocol:专注于AI的去中心化Web3底层协议,是为 AI app开发者、模型制作者和数据所有者构建的去中心化底层协议,可在 Web3 中安全地进行交易和收益变现。这是通过在Web3中创建知识资产来完成的,为所有AI价值创造者赋予真正的数字所有权。
我们认为,在所有AI价值创造者之间公平透明地进行分成,是鼓励各种AI参与者来共同建造一个充满活力的生态系统的关键。
我们相信,实现这一目标的首要步骤是通过区块链创建知识和数据的数字所有权。
我们的逻辑很简单:
-
AI价值领域的每个组成部分都依赖于其他部分。目前,拥有最大市场力量的人往往也会控制重新分配价值的渠道,从而迫使其他人接受其条件。
-
通过创建一个开放的框架来确认知识的所有权——无论是数据、模型还是app的形式——一个公平交易的系统将从技术和商业层面,让每个人更容易参与到模型改进所带来的经济效益;
-
经济利益的分享将鼓励更多人贡献他们的知识,从而进一步推动AI的进步;
-
为规模较小的AI模型开发者和AI app制作者提供机会,参与新的生态系统,进一步激励AI领域的所有创新,并为用户提供更广泛的产品选择。
公平透明分享经济利益是摆脱AI垄断的关键第一步。
通过实施基于区块链技术的Web3框架来确立数字所有权,我们旨在实现几个关键目标:
-
确保数据来源和完整性:通过基于区块链技术的记账系统来安全透明地追踪数据的来源和使用情况,确保其真实性、可靠性和可追溯性。
-
增强隐私和控制:数据所有者将更好地管控他们的信息,包括设置使用权限和条件,以确保AI训练时也能尊重隐私偏好——尤其是对于敏感数据。同样,小型模型开发者将有选择以闭源格式出售其作品,而不仅仅是自由分享或完全私有,虽然这是目前的常态。
-
促进公平补偿和归属:如果确保了数据来源和控制,就可以通过ERC-3525来标准代币分配的框架,确保模型制作者、app开发者和数据所有者可以自动获得公平补偿。这将为AI开发创造一个更公平的数据共享生态系统,并鼓励更多的创造者贡献其数据用于AI开发。
-
提高透明度和信任:去中心化账本的透明性允许监测和审计数据使用情况、模型和app,在数据提供者之间建立信任,并使供应商能够检查开发者和用户。这对于所有这种系统的正确运行至关重要,特别是诸如医疗保健和金融等敏感领域。
-
促进协作式AI开发:一个公平安全的去中心化数据共享平台将为AI的开发建立一种协作但竞争激烈的环境,以此激发出更多更具创新性和多样性的AI解决方案:理想化的情况是在线社区由小部分人群连接组成。
知识资产及其繁荣所需的基础设施
试想一下,如果我们的知识能够为我们带来收益...

在解决去中心化AI服务问题时,我们做了三个关键假设:
-
一个去中心化的AI系统在技术上必须具有竞争力——提供的模型和app必须与行业领先水平相当。
-
一个去中心化的AI系统必须具有用户友好性——OpenAI用其简洁的产品界面革新了市场,用户现在期望至少具备这种可用性水平。
-
一个去中心化的AI系统必须允许参与者从他们的贡献中获利——这是一个更难达到的标准,但如果系统想享有任何长久的生命周期,就必须满足这一标准。
简而言之,为了说服现有中心化系统的用户转化并获得新用户,一个去中心化的AI系统不能仅仅寄希望于其去中心化的理念就能蓬勃发展。它还必须至少与中心化系统的性能相当,并激励贡献者的参与(因为这些贡献者不是像大型AI公司那样领薪水的员工)。
此外,这三个组成部分高度集成。为了成为最新和最好模型的核心分发平台,有必要为设计者提供足够的经济激励,以使他们通过我们的平台提供这些模型(特别是考虑到涉及的高计算成本),但前提是整个平台必须易于使用,并回到第一点——结合最先进的技术,否则这种激励将无法实现。
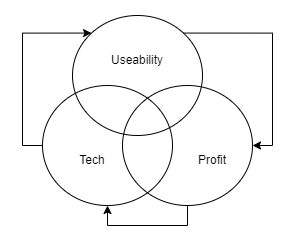
换句话说,无论你的去中心化AI解决方案多么先进,如果它不可访问或没有为参与其中的贡献者提供经济激励,它最终都会失败。
为了找到解决办法,我们需要先考虑三个关键问题:
-
安全问题:如果没有简单的方法,来允许仅向支付过费用的人有选择地访问某项资产(这往往是信息领域的情况),那么就很难将其变成大众市场产品。它要么完全私有,要么完全开源。自互联网出现以来,传统出版商已经尝试了许多方法来保护他们的营收,并防止盗版,但情况依然不容乐观。对于没有法律保护和经济实力的个人来说,同样的反抗都是徒劳。
-
连接问题。目前没有一个可访问的市场,允许专门从事特定AI知识资产(无论是模型、数据还是应用程序)的创造者之间进行连接并可向他人出售自己的作品。
这两个因素共同催化出了:
- 变现问题:创作者无法轻松变现,这降低或削弱了其经济价值。如果没有办法将产品推向市场,那么产品就没有价格。当产品进入市场时,就存在很大机会被广泛盗版,某种程度上会降低其继续开发的动力。
我们的解决方案是一个相应的三层架构:
-
所有权层:每个资产都在web2中运行,但被“包装”在ERC-3525半同质化代币中,作为所有权的证明,也作为一个访问控制的机制。
-
应用层:资产在web2中集成并交互,为创造者和用户提供了完全自由的选择权利,他们可以自行选择模型、数据和app,同时通过一组透明且匿名的web3智能合约来记录交互。换句话说,我们可以精确知道有多少人使用了某个app,以及使用了哪些AI模型和数据来制作它。
前两层的实现也为第三层铺平了道路。
- 结算层:通过该层,用户可以在中央池购买app积分。这些积分使他们可以与AI app、模型和数据进行交互。因为每个交互都会被记录在链上,所以可以准确计算每个app的收入中的多少应该归给哪些为其作出贡献的创造者,并在池里按比例重新分配这些收入。
KnowledgeFi
KnowledgeFi的兴起!
提要:KnowledgeFi描述了一种概念,即所有AI价值创造者,首先是知识资产所有者,都能参与到AI驱动的未来,并公平分享它带来的经济效益。KIP Protocol就是为了实现这种理念而设计的。
不管AI app界面是否有明确说明,AI实际上都是按查询次数计费的,月订阅费反映了用户平均月查询次数(通常API订阅会清楚说明这一点,而网页客户端用户一般支付标准月费)。
当用户向AI app发出查询后,积分会被消耗以推进app与AI模型以及知识资产进行交互,来完成查询工作。这些积分在经济上代表了所使用的GPU计算能力,以及模型开发者/提供者的其他成本和利润。计算服务方、模型设计者和股东都能从这些收入中获益,但是协助构建整个框架的数据提供者却得不到分成。
我们正在构建一个Web3协议。在这个协议中,所有AI利益相关者和价值创造者(如知识资产的所有者)都可以在为AI用户提供服务时进行交互和获得公平的经济收益。
我们将其称为KnowledgeFi。
KnowledgeFi:AI时代的自由&公平的知识经济。
我们的目标是通过系统性地建立真正的数字产权,让每个人都能充分释放其知识资产的经济价值。

一旦知识资产的所有权能够得到确保,围绕知识和数据交易的全新商业模式就变得可能。
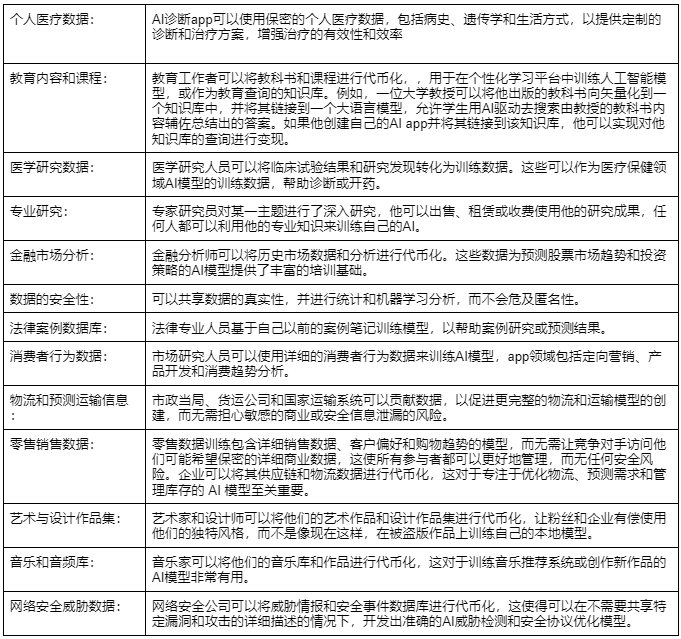
为了让用户更好地理解,以下是一些场景用例:
这就是我们想要的AI未来。一个越来越多人受到鼓励为AI发展做出贡献的未来,知识不再因担心大型科技公司大语言模型的爬取而被囤积,而是通过公平共享以产生更多经济价值。
这就是KnowledgeFi。
关于 KIP Protocol
KIP Protocol 为 AI App 开发者、模型制作者和数据所有者构建 Web3 底层协议,使 AI 资产能够轻松部署和实现货币化,同时保留完整的数字产权。
KIP 将搭建全新的 AI 商业生态系统,以解决去中心化 AI 部署中面临的问题与挑战,并确保所有人都能享受 AI 带来的经济利益。
KIP 团队汇集了自 2019 年以来致力于 AI 研究的资深博士和技术专家,他们同时在 Web3 领域拥有深厚的专业背景和丰富经验,致力于推动 AI 去中心化,成为去中心化 AI 浪潮的加速催化剂。
要了解更多信息,请关注我们的官方账号:
官网 | X |Discord| 白皮书 |Mirror中文