
摘要:
RAG 是生成式AI中使用的一种创新技术,涉及AI中的 3 个关键价值创造者(App开发者、模型制作者和数据所有者)。
KIP Protocol是世界上第一个支持去中心化RAG的协议,实质上是提供了一种将所有AI去中心化的基础框架,这是帮助摆脱AI巨头垄断的第一步。
1)RAG简述
AI模型是通过大量投喂数据从而进行训练。它们从数据中学习,调整内部权重以识别模式,从而能够根据新数据做出预测或决策。然后,模型就能根据新获得的 "原始"知识回答用户的问题。
但是,这种训练过程需要将整个数据集暴露给模型,基本上会导致数据会被 "吸收"到模型中。如果数据中包含机密信息或版权信息,那么模型就有可能在未来的某个时刻逐字逐句地吐露这些信息。
那么,如果你不想让你的数据面临风险呢?
这就是RAG(检索增强生成)出现的原因。
RAG 是一种复杂的技术,它能让AI模型通过检索外部知识库和数据库中的数据和信息,生成它原本不知道的答案。
它就像一个智能助手,虽然不知道你问题的答案,但却能专业地从外部数据中找到你想要的答案。
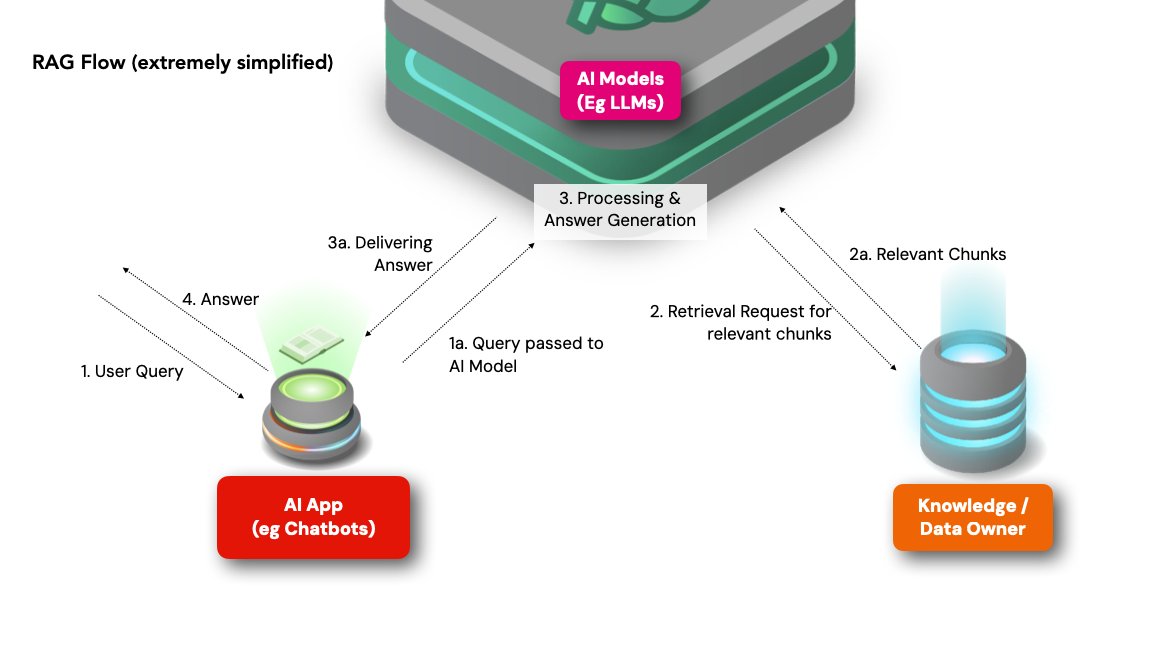
-
用户查询输入:
首先,用户向运行 RAG 系统的聊天机器人提出问题。
例如,“COVID-19 的症状是什么?”
-
从外部数据库检索:
该模型搜索已连接的外部知识库和数据库,如医学期刊、健康网站和临床数据库,来启动检索阶段,只检索与用户查询相关的数据和信息。
-
数据处理、过滤和生成:
对检索到的数据进行处理和过滤,以提取关键信息并消除不相关的数据。AI模型将检索到的数据与用户查询的上下文进行整合并生成答案。
在 COVID-19 症状查询的案例中,RAG 可能会生成一个列出发烧、咳嗽和呼吸急促等常见症状的响应,但也可能包括模型训练时没有的最新医学研究论文信息--一个更高质量的答案。
-
发送回复:
生成的回复会通过聊天机器人界面呈现给用户。
因此,RAG 允许使用外部数据来回答AI查询,而无需通过训练过程让模型先 "吸收 "这些数据。
RAG 技术日趋成熟,在我们的研究文件中,我们展示了RAG给出答案的质量可以超越那些训练有素的模型。https://arxiv.org/pdf/2311.05903.pdf
2)RAG的重要性
RAG 将变得越来越重要,因为:
-
训练模型是一项技术性和专业性很强的事情,通常成本很高--不是每个人都具备训练模型所需的技能或资源。
-
很多数据(机密数据、专有数据等)的所有者可能不放心让数据暴露给那些他们不完全拥有或不受他们掌控的模型。
你可能还注意到一个重要问题:
在 RAG 框架下,App开发者、模型制作者和数据所有者能够一起合作,各自为回答用户的查询做出贡献。
因此,在公平的情况下,各方都应为其贡献获得公平的补偿。
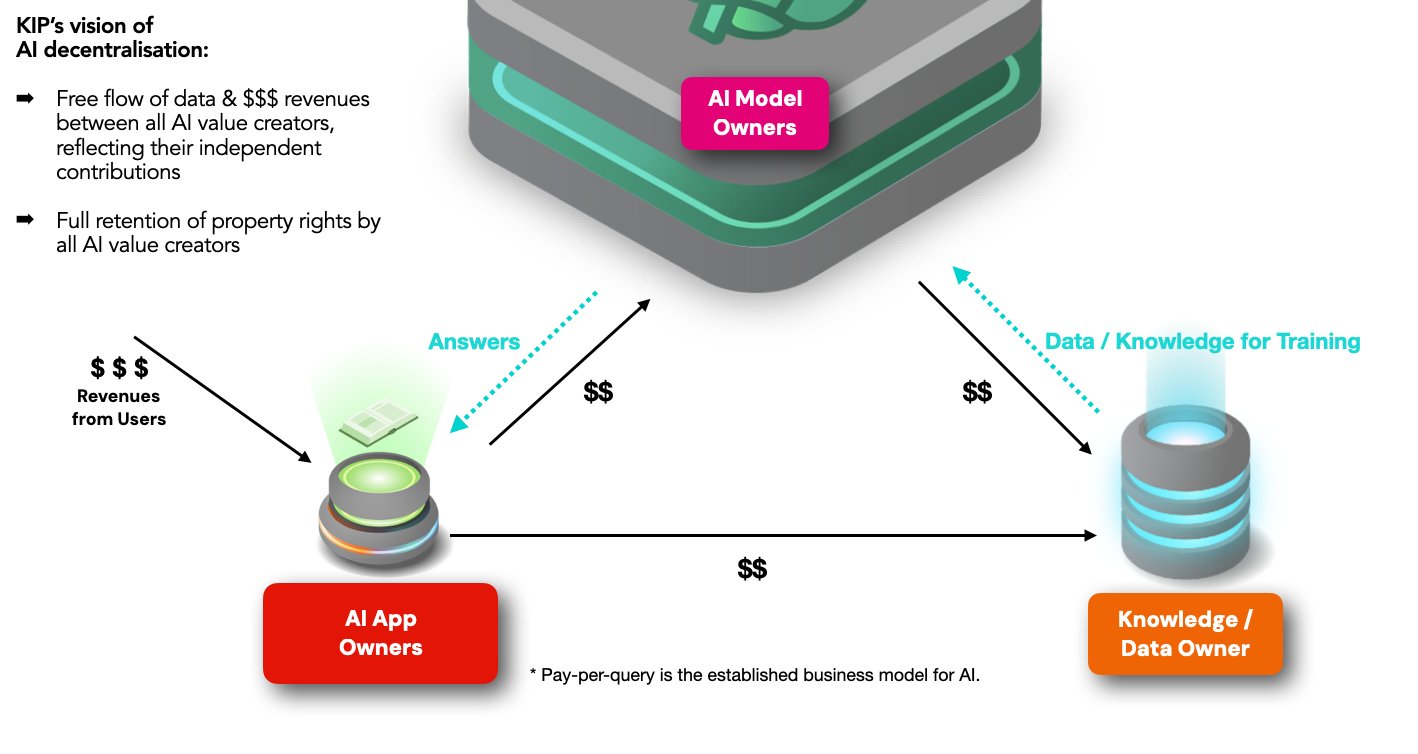
但目前还没有一种简单的方法,可以在不损害各方独立性或所有权的情况下做到这一点。 (顺便提一下,这个问题正是促使我们在一年多前开始建设 KIP 的原因)。
这就是“收益问题”。
3)RAG与中心化AI的“收益问题”
让我们想象一种情境,其中一个实体拥有人工智能价值创造的所有三个要素:无需在各方之间重新分配从用户那里收集的支付,因为可以直接内部进行核算。
但反过来说,如果我们不能接受一个实体拥有AI的价值创造的所有三个要素,(app开发者、模型制作者和数据所有者),我们就必须解决如何在不同行业的AI价值创造角色之间的收益问题。
不解决“收益问题”,App开发者、模型制作者和数据所有者就无法保持各自的独立性和交易自由。
然而AI行业的垄断现在已经开始了。
以下是我们对 OpenAI 垄断的看法:
-
OpenAI 显然拥有一些最强大的模型--像 GPT-4 这样的闭源模型,这些模型是收集我们多年来从互联网上发布的知识和内容训练而成的。这为他们App(如 ChatGPT)和用户自制的 GPT 提供了燃料。
-
通过他们的版权保护措施(即承诺为任何被发现在其平台上上传受版权保护数据的人支付法律费用),他们鼓励用户大胆地将数据上传到他们的封闭平台,而不必担心法律后果。
-
鉴于 OpenAI 是一个中心化、闭源 web2 平台,我们应该扪心自问:用户上传的数据(无论是 ChatGPT 还是 GPT App)是否仍属于上传者?
-
因此,根据他们现有的模型、以及对所有数据毫无保留的“搜刮”、版权保护措施和庞大的资金储备,你可能会发现OpenAI是有史以来最贪婪的“数据吸尘器”,不断地吸入数据和资源来满足他们的模型需求。
将上述所有因素(以及他们为硬件筹集的70亿美元)总结在一起,我们就不难看出,除非采 取一些措施,否则由一家或几家公司完全垄断AI行业的事实将不可避免。
基于我们已经分享过的原因,我们坚信AI行业的垄断对人类不利,并我们也会接下来积极想出摆脱被垄断的解决办法。
4)去中心化RAG的意义
RAG 涉及AI价值创造的所有 3 个核心因素(App开发者、模型制作者和数据所有者)。
因此,通过建立一个去中心化 RAG 的框架,KIP 本质上其实是建立了一个去中心化控制AI价值创造的框架,从而为所有价值创造者提供一个公平竞争的环境,从而摆脱AI垄断。
我们允许AI以高效的方式发挥作用,成为数百万小规模和大规模创作者共同努力的结晶,而无需任何一个大型公司来一手掌控每个核心功能。
为此,我们将首先解决阻碍 RAG 去中心化的 3 个基础问题:
-
所有权:
保证(App开发者、模型制作者和数据所有者)可以轻松、安全地向 web3 发布内容,通过创建以ERC 3525半同质令牌(Semi-Fungible Tokens)的形式构建他们的Web3“交易实体”,从而使他们能够在链上证明其数字产权。
-
链上/链下连接:
确保链下和链上互动的丝滑度,为App开发者、模型制作者和数据所有者 提供一个开放的环境,使其能够轻松自由地相互连接。
-
货币化:
提供一个通用的框架,用于记录和核算每个AI价值创造者的贡献,以及自动收入分成和提款。
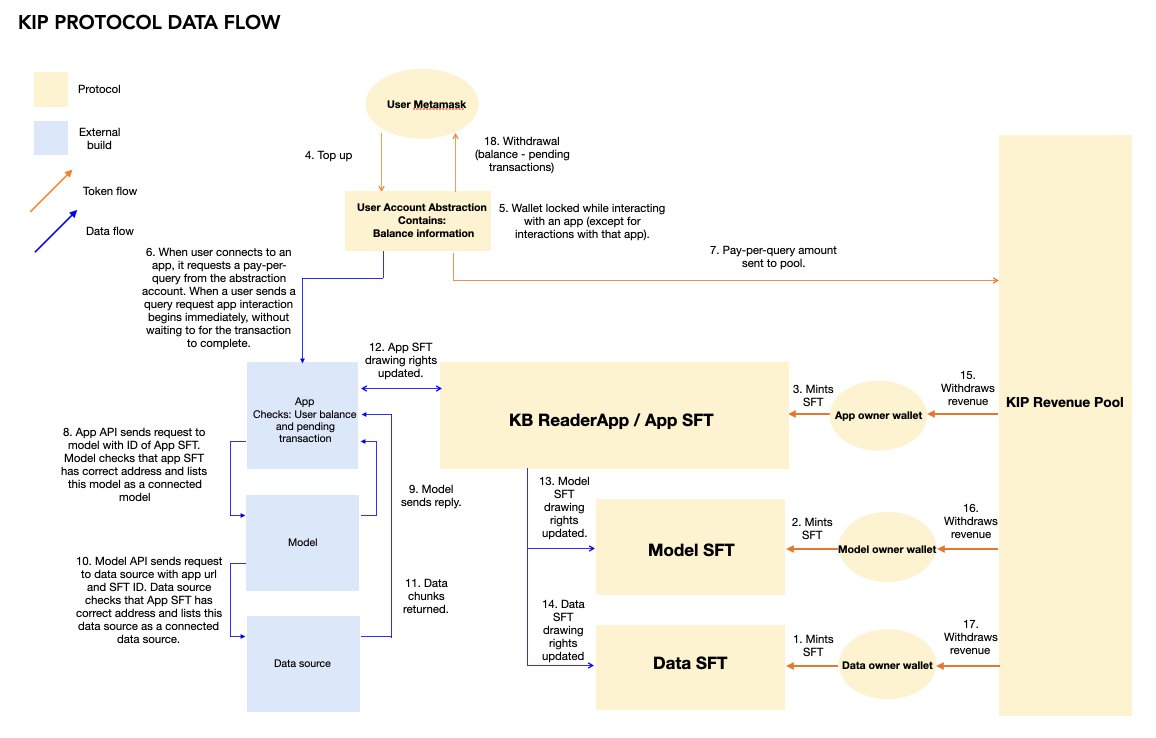
通过实现 RAG(d/RAG)去中心化,KIP 正在绘制第一张摆脱AI垄断的重要蓝图。
为每个AI价值创造者解锁数字产权,让每个人都能在保持独立的同时进行交易,这也与web2的大型科技公司试图实现的目标恰恰相反。
KIP 协议会为AI价值创造者提供摆脱AI垄断所必需的工具。
关于 KIP Protocol
KIP Protocol 为 AI App 开发者、模型制作者和数据所有者构建 Web3 底层协议,使 AI 资产能够轻松部署和实现货币化,同时保留完整的数字产权。
KIP 将搭建全新的 AI 商业生态系统,以解决去中心化 AI 部署中面临的问题与挑战,并确保所有人都能享受 AI 带来的经济利益。
KIP 团队汇集了自 2019 年以来致力于 AI 研究的资深博士和技术专家,他们同时在 Web3 领域拥有深厚的专业背景和丰富经验,致力于推动 AI 去中心化,成为去中心化 AI 浪潮的加速催化剂。
要了解更多信息,请关注我们的官方账号:
官网 | X |Discord| 白皮书 |Mirror中文