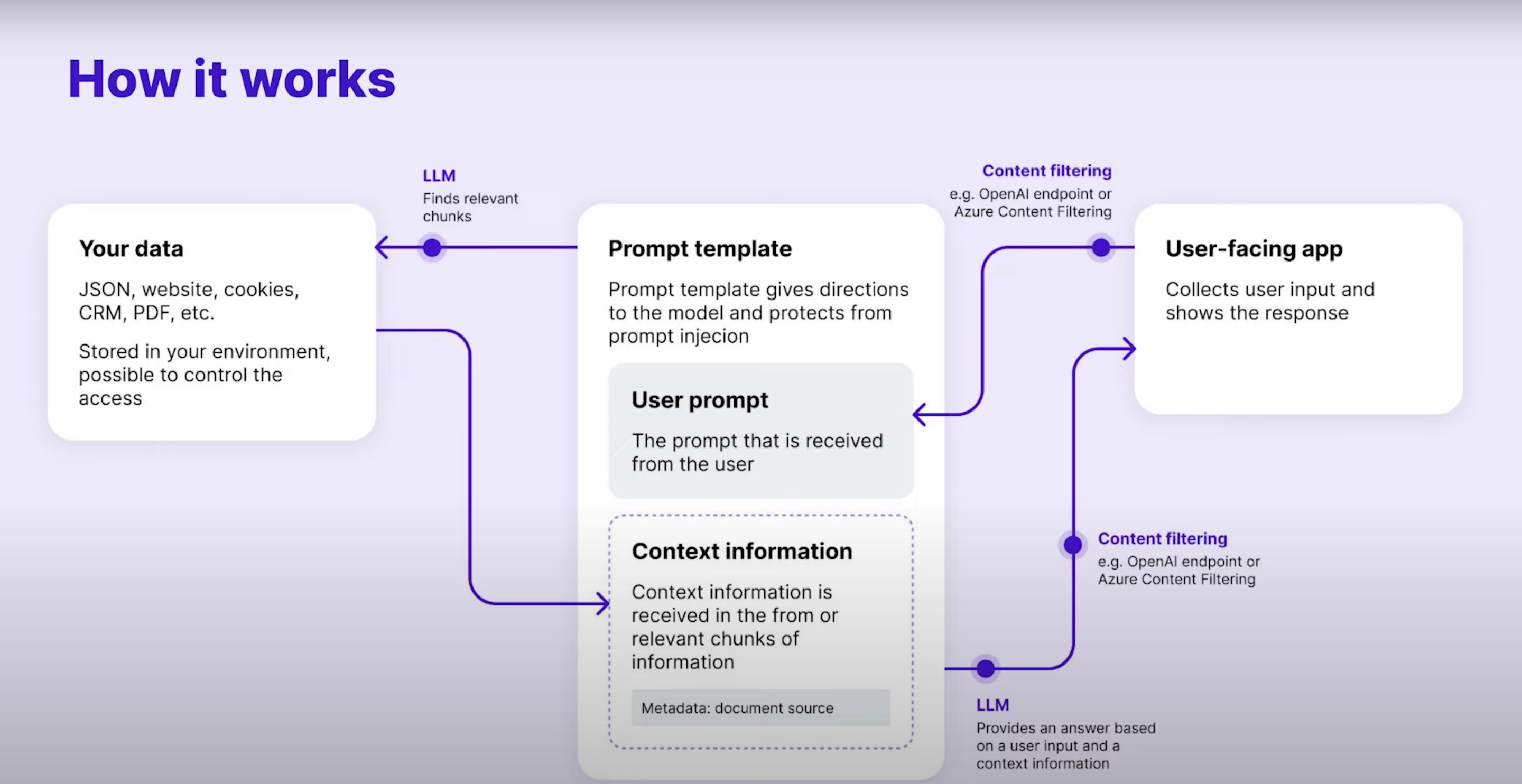
Creating a personalized chatbot has become relatively straightforward using libraries like LangChain. In fact you can develop your own full-stack javascript/typescript application in a few hours using the LangChain library. In the text below I will explain the steps I took. In this case I used service that also does the predictions. If you have a GPU with enough RAM you can run the model of your choice directly on the GPU
Prepare Vector Store
We will be using the langchain conversational retrieval chain, to use a conversational retrieval chain we need to create a vector store. To do this I used pinecone as the index for the vectors.
Create a PineCone account then create an index with the dimensions of the embeddings you will be using. In this case the dimensions are 768
First initialize pinecone make sure to do the necessary python installs to get the pinecone module
!pip install langchain==0.0.189
!pip install pinecone-client
!pip install openai
!pip install tiktoken
!pip install nest_asyncio
import pinecone
# initialize pinecone
pinecone.init(
api_key="PINECONE_API_KEY", # find at app.pinecone.io
environment="ENVIRONMENT_NAME" # next to api key in console
)
Load the data to be used in the vector store, this example uses a pdf loader
import nest_asyncio
nest_asyncio.apply()
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("/Path/To/PDF")
pages = loader.load_and_split()
Split the loaded text into smaller chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
import json
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1000,
chunk_overlap = 200,
)
docs_chunks = text_splitter.split_documents(pages)
Create the embeddings
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(model_name='gpt2')
Create the vectors in your pinecone index
from langchain.vectorstores import Pinecone
index_name = "name of index created on pinecone"
docsearch = Pinecone.from_texts(split_text, embeddings, index_name=index_name)
Create javascript app to use the vector store
The frontend is a simple ui written in react that a user can type questions and see responses from the model. When the user types a question and then clicks on the senf button. A POST request to an endpoint within the application with the user’s question and the chat history for additional context. The backend is written in typescript.
The backend has two parts.
First, The API endpoint that calls the conversational QA chain
import { NextResponse } from 'next/server';
import {chain} from "@/utils/chain";
import {Message} from "@/types/message";
//endpoint to call the conversational qa chain
export async function POST(request: Request) {
const body = await request.json();
const question: string = body.query;
const history: Message[] = body.history ?? []
const res = await chain.call({
question: question,
chat_history: history.map(h => h.content).join("\n"),
});
return NextResponse.json({role: "assistant", content: res.text, links: ""})
}
Second, the conversational QA chain also written in typescript; it utilizes the LangChain.js package. In this example I will be using the AI21 jurassic model as the llm for the conversational retrieval chain, here are some other options.
import {pinecone} from "@/utils/pinecone-client";
import {PineconeStore} from "langchain/vectorstores/pinecone";
import {ConversationalRetrievalQAChain} from "langchain/chains";
import{AI21} from "langchain/llms/ai21"
import { HuggingFaceInferenceEmbeddings } from "langchain/embeddings/hf";
async function initChain() {
const model = new AI21({
model:"j2-ultra"
})
//initialize pinecone index
const pineconeIndex = pinecone.Index(process.env.PINECONE_INDEX ?? '');
/* call vectorstore*/
const vectorStore = await PineconeStore.fromExistingIndex(
new HuggingFaceInferenceEmbeddings({}),
{
pineconeIndex: pineconeIndex,
textKey: 'text',
},
);
return ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever(),
{returnSourceDocuments: true}
);
}
export const chain = await initChain()
Run your application and you have an llm that can answer questions from the documents in your vector store.