
Table of Contents
-
The beginning of it all: The Privacy-preserving era
-
Diving Into Personalization
-
A New Wave for Internet Data Ownership
-
Pitfalls on Adaptation
-
-
Web2 & Content
-
Signal In The Noise
-
The Rise of Interest Graphs
-
-
FirstBatch: Decentralized Personalization
-
Building The Universal Interest Graph
-
Availability of Meta’s and Spotifys’ Similarity Search Engines on Arweave
-
Why are we building on Arweave?
-
FirstBatch’s Contributions to Arweave
-
-
Conclusion
The beginning of it all: The Privacy-preserving era
In the past few years, users have become increasingly concerned about their privacy and companies have taken steps to address these concerns. This is a positive development that portends a new era.
We all know that many companies collect our data to use on their products and thus perform advertising, personalization, and third-party data sharing. Although cookies are used less frequently as a result of the latest interventions, personalization is still an important part of the user experience. This way, the end-to-end flow of users aligning with products is determined by user behavior. With the rise of communities and digital interactions driven by social alignment, personalization is on the verge of a fundamental change.
Personalization has traditionally been centered around the behavior of individuals. Companies are using data to tailor their products and services to individual customers’ specific needs and desires. However, with the increasing importance of social alignment, personalization is shifting to become more community-focused, nuanced, and complex. Rather than just considering the preferences of individual users, personalization mechanisms must now also consider the values and beliefs of communities to which those users belong. This shift is partly driven by the increasing importance of social media and other online platforms that allow people to connect easily with like-minded individuals and form communities based on shared interests.
The emergence of new data necessitates better privacy-oriented approaches, this can be achieved by implementing certain innovative approaches.
Privacy-preserving methods, such as zero-knowledge proofs and privacy-preserving data vectorization, are essential for users. These methods allow users to share information or prove the authenticity of their data without actually revealing the data itself. Zero-knowledge proofs allow users to prove that they possess certain information without revealing the information itself. zero-knowledge proofs are very useful in situations where users want to prove the authenticity of their digital identity but want to keep the actual identity private.
Privacy-preserving data vectorization can help users share information without revealing the specific values of the data. The data is first transformed into a vector of values that can be used for ML analysis. The specific values of the data remain hidden, but due to vectorization, users can share their data for research or analysis without revealing the specific values.
In addition to being important for individual users, privacy-preserving methods are also crucial for businesses. By using these methods, businesses can protect the personal information of their customers and employees and their proprietary data.
Privacy-preserving methods can also help businesses to create a tech stack that is manipulation resistant. By using these methods, companies can ensure that their data is secure and cannot be accessed or manipulated by unauthorized parties. This can help businesses establish trust with their user base who are made aware that their data is being protected.
In the coming years, businesses will likely be required to implement more robust privacy measures to protect the personal information of their users. By using privacy-preserving methods, businesses can ensure that they are fully aligned with these upcoming regulations.
Diving Into Personalization
What is the main issue regarding customization? What should we develop? How can we provide a better experience?
With more and more focus on a smoother user experience, personalization has become an inseparable part of basically every application. Even though there are clear benefits to both platforms and users, there are still crucial vulnerabilities in privacy and interoperability.
To examine personalization in more detail, it is useful to separate it into layers.

Data collecting often involves collecting and analyzing data about individuals to tailor content or recommendations to their interests and preferences. This can happen through on-platform methods such as collecting data related to likes, reposts, clicks, time spent, followers, etc. or using external data such as cookies. Online data collection usually invades the privacy of users today because they do not control their data transparently. There is no restriction on what data organizations may choose to take. The flow of data has been provided through first-party experiences in recent years, even though it is mandatory to provide options for data collection.
Censorship can be shown as the penalty layer of personalization. Although the data received from the user is processed, some perspectives and topics are ‘filtered’ at this stage. This is the stage where an organization other than the user first intervenes in the data, and it gives the right to interfere with another agent, regardless of what you are dealing with. Censorship is not something that one chooses to do or not. We can only choose where to draw the line. Content policies and local laws largely determine what will be allowed on the platform, but there is also ‘shadow ban’ policies that are sometimes implemented for spamming users or repetitive content even if they don’t violate any platform rules or laws.
The Manipulation layer is the stage where new data or logic is added to the personalization, in contrast to the censorship layer where there is only removal. In this layer, users can be manipulated by targeting them with content or recommendations that are designed to influence their beliefs or behavior. Manipulation can be used for directing users to an ad or making them sympathize with a certain topic/idea. It can also be used for increasing the quality of users’ experience on the platform by ranking content they see based on the relevant interests they have. While manipulating data in some way is necessary for targeted ads and prioritizing the content users are more interested in, using this to favor certain political or cultural agendas over others may cause problems. Either way, the platforms must be completely transparent in everything they do in this layer.
This framework offers an efficient way of showing relevant posts to users and making the most out of advertisement budgets, but it does not consider self-sovereignty as a core principle and has a low bar for privacy. The resulting personalization not only lacks privacy, but it’s also not interoperable which means that users’ experience gets reset every time they sign up to a new platform.
A New Wave for Internet Data Ownership
Data ownership is defined as an individual or organization’s ability to control its data and how it is used. Web3’s initial ideologies toward data ownership — users’ full custodial control and monetization of their data — seemed utopian in nature compared to the traditional centralized model of data ownership where data is often controlled and monetized by a small number of large companies.
While the relationship between web2 and web3 is often portrayed in an adversarial way, we can expect that users will continue to have experiences in both web2 and web3 simultaneously. The reality is that a user’s web experience is decentralized in nature — one ecosystem, platform, or experience cannot fulfill all the needs of a modern web user. Most users will gain exposure to web3 primitives through web2, and to understand users in a holistic way across ecosystems, interoperable data will be a necessity.
Over time, many technological advances have evolved the ideals of web3 data ownership into more achievable goals. Blockchain and decentralized storage systems enable a more decentralized model of ownership, where individuals and organizations are the custodians of their data — rather than relying on centralized servers or platforms. This can give them more control over their data and how it is used and help to protect their privacy and security. Additionally, self-sovereign data allows for much more efficient development that is not bottlenecked through 3–4 mega web2 corporations.
Furthermore, Web3 technologies enable new forms of data monetization, such as the use of tokens or other digital assets. The purpose of this is to enable individuals and organizations to directly monetize their data, rather than having to rely on third parties for this purpose. Web3’s main objective is all about decentralizing and democratizing data management, where individuals and organizations have more control over their data.

Pitfalls on Adaptation
Data ownership on web3 has the potential to offer many benefits, but it is important for individuals and organizations to carefully consider the risks and challenges associated with these technologies before implementing them.
Privacy concerns are one of them. Previously, Web2 data ownership was given to the user to solve the privacy problem. However, this also meant that the data is more susceptible to unauthorized access by third parties. In addition to the laws of official organizations, centralized structures ensure the security of this data. As an alternative, blockchain technology is generally safe, but it is not foolproof. Data stored on the blockchain can potentially be accessed by hackers or other malicious actors.
There is also the issue of data breaches. It’s possible to have a data breach if your data isn’t properly secured or if your systems aren’t configured correctly. Web3 is particularly vulnerable to this risk, as data stored on a blockchain is typically more difficult to delete or alter once it has been added. People or organizations that are responsible for providing the flow of data over the blockchain need to be vigilant about data breaches.
In light of these considerations, it should not be forgotten that while web3 gives ownership to the user, it also provides the user with control over the entire system. They are difficult to design for users, so another organization steps in between the user and data ownership, ensuring the security of the system. These organizations, whose main advantage is decentralized companies when compared to Web2 companies, provide data ownership and management to the user while making the system more useful and more functional in terms of user experience.
With a well-designed data ownership structure, users can easily manage their data while not allowing them to be used without their permission, but data flow may have to walk through the organization since experiences such as personalization are subject to multi-layered technical interventions. While our goal is not to share our data with the organization as in web2, we fall into the same situation, on top of which a more difficult UX welcomes us.
The entire web is undergoing a transformation and technologies are advancing day by day. So how can today’s personalization experience be realized on web3?
While the personalization experience is one of the main functions for mass adaptation, which will be one of the most fundamental breakthroughs of Web3, how do we carry this technology to the present day?
Personalization is carried out through many methods, but the most popular of them are graph-based ones. Graphs, in particular, represent the behavior models of social media platforms, ensuring the maximum level of personalization. Let’s talk a little bit about social graphs.
Signal In The Noise
What enabled Web2 was our ability to share, comment, and react to content. The exponential growth of users on socials fundamentally changed how and what we monetize, access new information, make friends, and form communities. Like the Cambrian explosion, we have started appearing on digital internet records since then.
As socials and feeds that provide generated or collected data to overpopulated networks, we started creating noise, a powerful stream of data that can reach billions that contain mostly** useless information.
We were once overwhelmed by signals; now, finding the signal in the noise is the challenge.
This is one of the many reasons socials are starting to lose their functionality as content providers. As the content types vary and the number of people creating content increases, the quality of the content decreases, and the curation process gets more complex, a solid example of the Negative Network Effect.
The Rise of Interest Graphs
Interest graphs are like social graphs but focus on connecting users based on shared interests and activities. By design, interest graphs aid the discovery and connection of users who share similar passions and interests and facilitate the exchange of ideas around these interests.
Interest graphs have recently gained popularity as an alternative to traditional social media platforms. They offer a more targeted and specialized approach to social networking, allowing users to connect with others who share their specific interests rather than just their social connections.
Negative network effects are caused by contamination between graph relationships, which degrades quality significantly. Interest graphs produce results based on people’s interests rather than the social affinities between users. So you can make a user-specific recommendation without being biased by the network. Another benefit of the situation is that communities are created more healthily if you look at it from a macro perspective. Matching users with the right communities in social graphs is sometimes inefficient due to bias of social relations and negative network effect.
Building The Universal Interest Graph
FirstBatch’s objective is simple: building a universal interest graph accessible to everyone.
Universal Interest Graph (UIG) is an interest graph built on top of blockchain that is fed by interoperable data and wrapped with a privacy layer to provide complete ownership and privacy to its users. UIG represents contents, products, and users as nodes and their interactions as edges. These representations are multi-dimensional vectors that relate contents, users, and products to contexts and specific topics of interest.
UIG offers decentralized personalization with interoperable data while preserving user privacy. This means better content delivery and privacy at the same time.
UIG features:
-
Accessible by everyone, anytime; UIG operates on blockchain to be available for everyone without needing a centralized authority for access and guaranteed uptime.
-
Similarity Search; UIG is capable of matching any content, product, and identities with each other meanwhile providing modularity, data & computation validity, and web2-like response times.
-
Privacy; User IDs stored on-chain are ZK-IDs that are not linked to the user but can only be accessed and updated by the user.
-
Interoperability; Users generate their persona using multiple public data sources and attach a single vector to their ZK-IDs. This ensures the validity and richness of a persona with interoperable data while preserving privacy.
Developing UIG in a decentralized environment brings many bottlenecks;
Trustless and Shared Source; Similarity search should operate on a contract level, making it fully decentralized.
Capability for Storage Large Data; Similarity search models use large amounts of data while training; hence, the blockchain should be able to store this model.
Scaling to Millions; UIG may be subject to many requests by users and organizations.
Cost Efficiency; Transactions on the blockchain have a cost. Although the experience delivered for users should be free, it should be cost-effective for organizations that use UIG to provide better experiences.
Distributed computation, community; People should be able to contribute to UIG by running nodes to increase scalability. Also, the community should be able to contribute to UIG features.
The availability of Meta’s Similarity Search Engine on Arweave marks the beginning of a new era of decentralized recommendation engines, Interest Graphs, and the path forward for Web2 giants into Web3
Similarity search allows searching for similar vectors to a given input vector. It is widely used in various applications, including recommendation systems, image and video retrieval, and natural language processing.
As FirstBatch, we are implementing popular, state-of-art similarity search to the decentralized domain, making them available on the blockchain. All models operate entirely on smart contracts.
We are currently working on the following:
-
FAISS (Facebook Artificial Intelligence Similarity Search) is an open-source library developed by Meta that allows users to perform efficient similarity searches on large datasets. It is particularly useful for tasks such as nearest neighbor search and large-scale search on high-dimensional data.
-
Annoy (Approximate Nearest Neighbors Oh Yeah) is another open-source library that is widely used for similarity searches. Developed by Spotify, Annoy is optimized for fast and efficient nearest-neighbor searches on large datasets. It works by constructing a tree-based index that allows for an efficient search of approximate nearest neighbors.
-
HNSW(Hierarchical Navigable Small Worlds) based search is a graph-based solution to approximate K-nearest neighbor search based on NSW graphs developed by Yu. A. Malkov and D. A. Yashunin. It provides high-quality results with good speed and low memory.
When Similarity Search operates on smart contracts, it leverages the power of the shared state. With decentralization, a fully transparent, immutable model that everyone can query is possible. We can also call this an upgrade to integrity. In a decentralized system, data is validated and agreed upon by multiple parties rather than controlled by a single entity, ensuring the integrity of the data and reducing the risk of manipulation. This also allows on-chain model updates and access control mechanics.
Decentralized similarity search engines have several benefits over their centralized counterparts. One key advantage is ownership. In a decentralized system, data is stored on a blockchain, therefore, not subject to the same level of surveillance and control as in a centralized system.
Decentralized similarity search engines also enable the interoperability of data. In a centralized system, data is typically siloed and not easily accessible to other parties. In a decentralized system, data can be easily shared and accessed by multiple parties, enabling greater collaboration and innovation.

Why are we building on Arweave?
Before explaining why we build on Arweave, it is fruitful to mention bottlenecks that we encounter on EVM.
Why not EVM?
EVM is a state machine that runs on thousands of computers distributed worldwide. EVM is capable of executing machine code, therefore, providing computation and storage via smart contracts. Unfortunately, everything that changes the state of EVM is costing us dollars.
Storing a large model (up to 10s of GB) on Ethereum is pricy. Since models are updated frequently, gas price plays a significant role in the feasibility of the model. A user querying a model shouldn’t pay anything if we aim for a feasible UX. Also, it is nearly impossible to provide a Web2-like experience in response times if we store large models and update them frequently. The cost of gas can vary significantly depending on the demand for computation and storage, which can make it expensive to use the EVM for certain types of applications.
In our case, it seems impossible to set up an EVM-based structure due to data storage costs and computation problems.
Solution for Bottlenecks: Arweave
Considering all our bottlenecks and EVM’s disadvantages, Arweave is what we need. Arweave is a decentralized protocol and network that enables the creation of a permanent, censor-resistant archive of data. It is designed to be scalable, low-cost, and energy-efficient, using a proof of access consensus mechanism.
SmartWeave contracts, built on Arweave offers:
Lazy Evaluation: SmartWeave contracts move the computation to the caller’s computer, unlike EVM. Since computation is done locally and queries to UIG do not change state, there are no gas costs for users. This provides unlimited scalability to UIG contracts.
Low cost: Because the Arweave network relies on a distributed network of users to store data, storage cost is drastically lower than EVM and generally cheaper than traditional centralized storage solutions.
High scalability: The Arweave protocol is designed to be highly scalable, with the ability to handle a large volume of transactions and data storage without experiencing performance degradation.
Web2 Performance on Web3: Since Arweave utilizes lazy evaluation, the computation can be distributed among computers of your choice while using the shared state, ensuring the validity of results and faster response times like in Web2. The same property allows people to contribute to the scalability of UIG by running a node that queries the smart contract and connecting through an API
JS, TS, and WASM: SmartWeave contracts support Javascript, Typescript, and WebAssembly modules. This significantly reduces the need to develop tailored libraries by making existing libraries available for computation. It also enables computation-heavy mathematical operations like vector operations on smart contracts.
FirstBatchs’ Contributions to Arweave
We plan to share our code with the community as open source to contribute to the Arweave ecosystem and help the development of ambitious technologies operating on Arweave.
DANNY (Decentralized Approximate Nearest Neighbor Yummy!)
DANNY is a Decentralized Similarity Search engine that operates fully on SmartWeave contracts. The library contains source code for contracts, workers, and utilities that allow training, deployment, and inference of Similarity Search models.
Training:
-
Training of similarity search model with multithread support. It can be trained locally or using WASM on the browser.
-
Sharding & deployment of the model to Arweave
Inference:
-
Loading model to contract
-
Querying for similarity search
-
Sharded multi-contract structure for large models
-
On-chain updates to the model
We’ve implemented a Rust version with multithreading compatibility in the first version of DANNY. We also plan to release FAISS and HNSW soon after.
Together with Danny, we are adding functionality where all users can converge at a vector level in a trustless environment. This way, many tasks, including our case, the Recommendation Engine, will run in a decentralized environment.

HollowDB: Key-Value Database for Arweave
HollowDB, a key-value database that we can define as Redis for Arweave, will be a new open-source contribution developed to represent non-complex data in a decentralized environment easily.
We encountered some problems when we stored data on different blockchain
- Many of the solutions remain overkill in our case;
Our difficulties were primarily due to schemes, rules, complicated queries, and undetected runtime slowdowns.
- As data got larger, query times increased drastically; As the data transfer took place, the state swelled, making it impossible to use.
So what makes HollowDB different
-
Query experience is effortless as it works with a key-value structure.
-
It has a bucketing mechanism. The bucketing mechanism prevents swelling by positioning the states in the contracts in a distributed structure. Query times remain constant
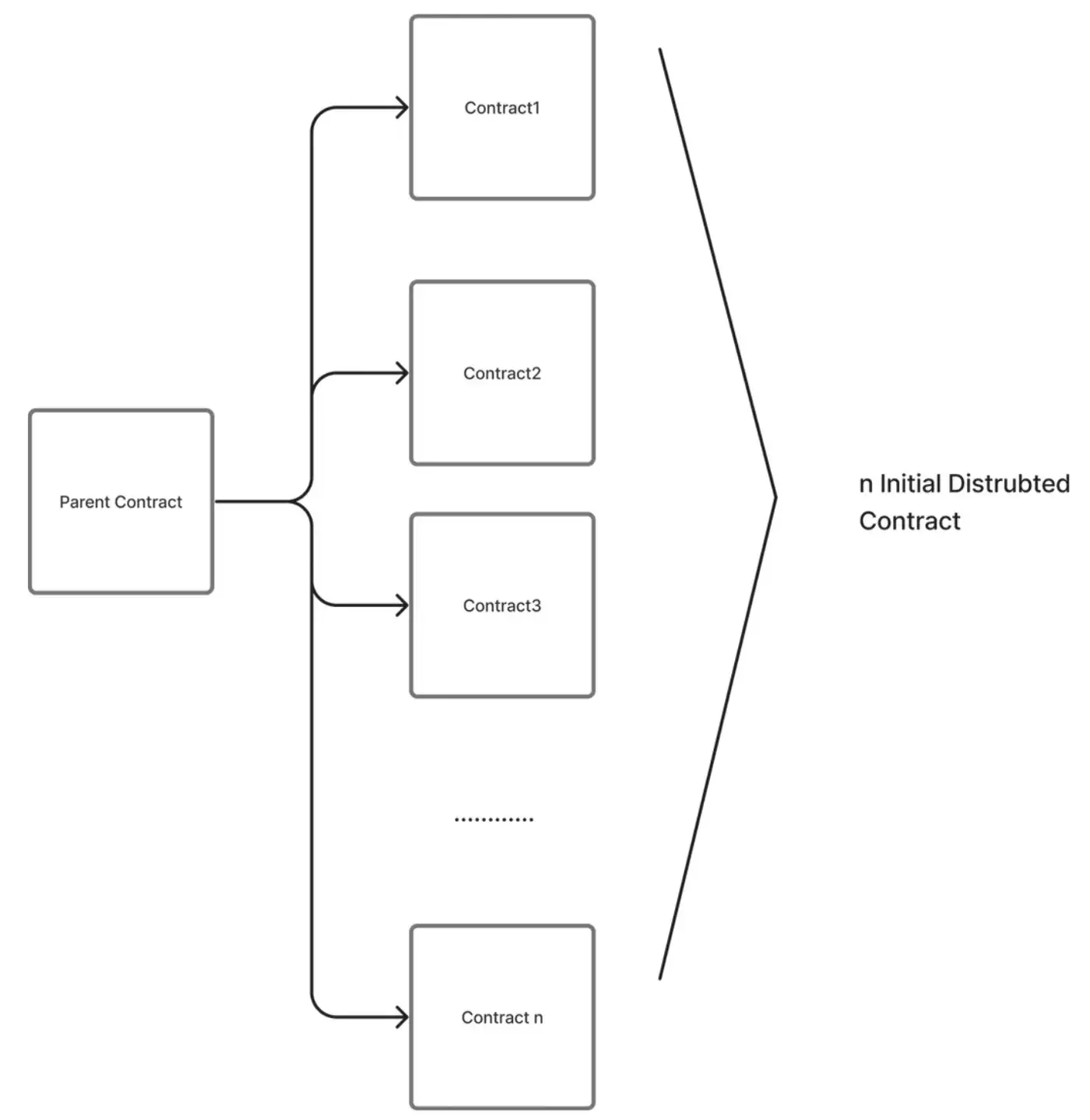
The re-Hashing mechanism works when the initially distributed contracts presented in HollowDB exceed a specific size. With Re-Hashing, users in existing contracts are re-distributed to more contracts. In this way, the system can update itself with constantly evolving contracts.
Semaphore on SmartWeave
We will also release :
- Warp Contract wrapper for Semaphore, an EVM-based open-source ZK library that enables fully anonymous group memberships.
Conclusion
The very feature that made the Internet such a success — personalization — became its greatest liability when privacy and lack of data availability issues arose. Although data management has always been a challenge for organizations, the pressure has recently been magnified by Web3’s ability to give users more control over their data.
As Web3 technologies have not yet been fully developed, applications and users have been left wanting in the area of personalization. As FirstBatch, we are developing a technology called the Universal Interest Graph to bring this critical feature to the blockchain using Artificial Intelligence & Zero Knowledge Proofs. Thanks to the structure offered by Arweave, we can have both a cost-effective and a powerful computation.
Even though the current generation of Web3 technologies have not reached their ultimate state, the progression of these technologies will lead to mass adoption and fascinating solutions.