Initialement publié en anglais par StarkWare le 11 août, 2022.

Les toutes premières preuves récursives de calcul général, sont désormais live sur Ethereum Mainnet
TL;DR
- Recursive Proving est en direct sur Mainnet, permettant de scale les applications StarkEx et StarkNet avec une seule preuve
- Boost le scaling, offre des avantages en termes de coût et de latence (une occurrence rare et passionnante de scaling et de latence se déplaçant en tandem sans être un compromis)
- Prépare le terrain pour L3 et d’autres avantages
- Allez lire l’article sur Recursive Proving. C’est un sujet cool 😉.
Augmenter Scaling
Preuves récursives – alimentées par le calcul général* de Cairo – sont actuellement en production. Ceci marque un coup de pouce majeur à la puissance de L2 scaling avec STARKs. Il fournira rapidement une augmentation multiple du nombre de transactions qui peuvent être écrites à Ethereum par l’intermédiaire d’une seule preuve.
Jusqu’à présent, STARK scaling fonctionnait en «rolling up» pour des dizaines ou même des centaines de milliers de transactions dans une seule preuve, qui était écrite à Ethereum. Avec la récursion, beaucoup de ces preuves peuvent être «rolled» en une seule preuve.
Cette méthode est maintenant en production pour une multitude d’applications basées sur Cairo : des applications fonctionnant sur StarkEx, le moteur SaaS de StarkWare et StarkNet, le rollup permissionless.
L’histoire Jusqu’à présent
Depuis la première preuve sur Mainnet, en mars 2020, les développements suivants ont façonné l’utilisation des STARKs.
Scaling basée sur les STARKs
En juin 2020, la première solution de scaling basé sur les STARKs – StarkEx – a été déployé sur Ethereum Mainnet. StarkEx dispose d’un Prover qui effectue de gros calculs off-chain et produit une STARK-proof pour leur exactitude, et d’un Verifier qui vérifie cette preuve on-chain. Les contraintes de ce premier déploiement ont été «écrites à la main» par les ingénieurs de StarkWare, limitant ainsi considérablement la vitesse des fonctionnalités de StarkEx. Nous avons conclu qu’un langage de programmation pour soutenir le calcul général était nécessaire – Cairo.
Cairo
Au cours de l’été 2020 Cairo a fait sa première apparition sur Ethereum Mainnet. Cairo signifie CPU Algebraic Intermediate Representation (AIR), et inclut un AIR unique qui vérifie le jeu d’instructions de ce « CPU .» Il a ouvert la porte au codage de preuves pour une business logic plus complexe, pour des énoncés de calcul arbitraires et pour le faire d’une manière plus rapide et plus sûre. Un programme Cairo peut prouver l’exécution de la logique d’une seule application. Mais un programme Cairo peut aussi être un enchaînement de plusieurs de ces applications – SHARP.
SHARP
SHARP – un SHARed Prover – prend les transactions de plusieurs applications distinctes, et les prouve toutes en une seule STARK-proof. Les applications combinent leurs lots de transactions, remplissant la capacité d’un STARK-proof plus rapidement. Les transactions sont traitées à un rythme et une latence améliorée. La prochaine frontière : les preuves récursives, mais pas seulement pour une hard-coded logic, mais plutôt pour le calcul général (general computation).
Pour comprendre tous les avantages de Recursive Proving, il est utile de comprendre un peu plus comment le proving (non récursif) a été réalisé par SHARP jusqu’à présent. Le dessin 1 représente un flux non-récursif typique :
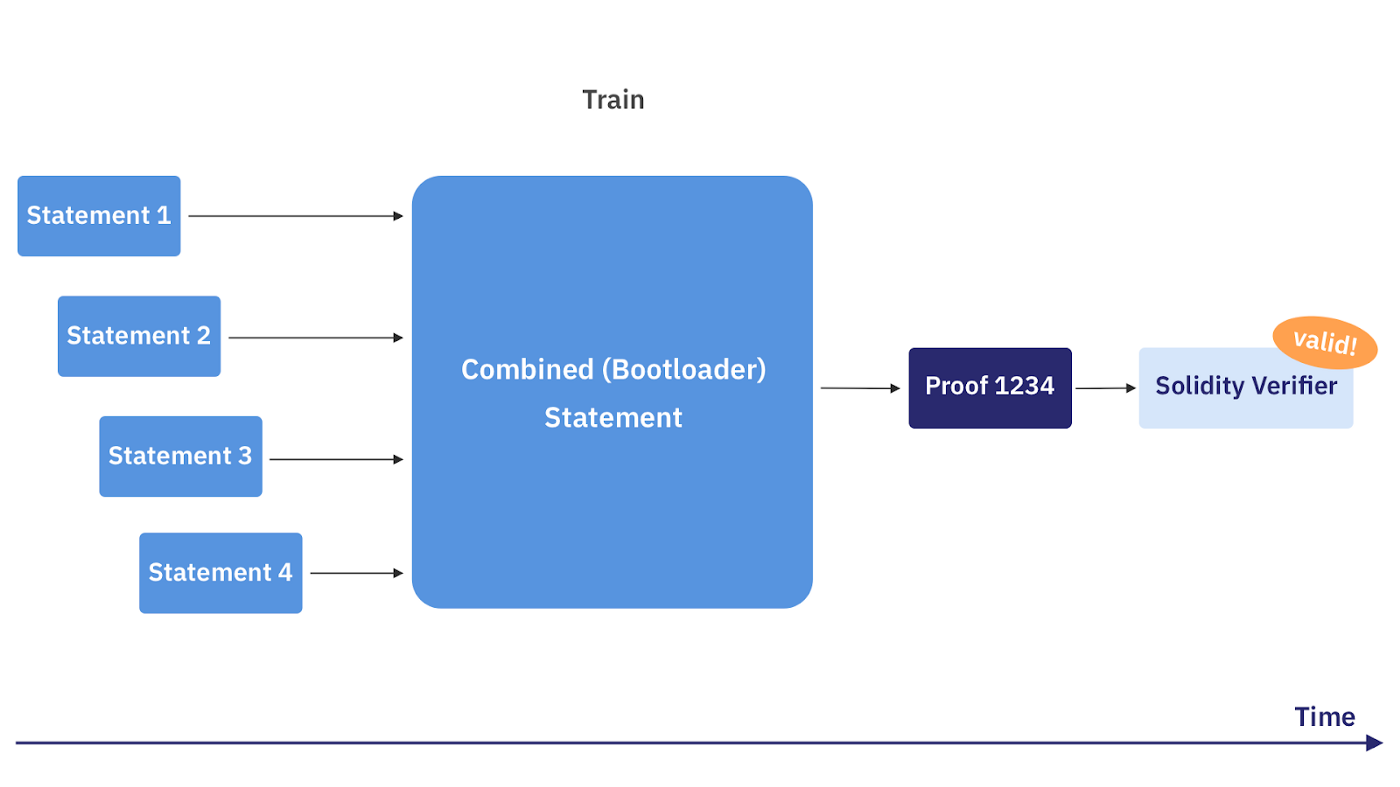
Ici, les déclarations (statements)¹ arrivent au fil du temps. Lorsqu’un certain seuil de capacité (ou de temps) est atteint, un large énoncé de déclarations combiné (aka Train) est généré. Cette déclaration combinée n’est prouvée qu’une fois que toutes les déclarations individuelles ont été reçu. Cette preuve prend beaucoup de temps à être prouver (à peu près la somme de temps qu’il faut pour prouver chaque affirmation individuellement).
La preuve d’énoncés extrêmement volumineuses est éventuellement limitée par les ressources de calcul disponibles telles que la mémoire. Avant la récursion, c’était effectivement la barrière limitant la scalabilité de STARK-proving.
Qu’est-ce qu’une preuve récursive ?
Avec les STARKs proofs, le temps qu’il faut pour prouver une instruction est à peu près linéaire avec le temps qu’il faut pour exécuter une déclaration. De plus, si la démonstration d’une déclaration prend un temps T, alors la vérification de la preuve prend approximativement log(T) temps, ce qui est généralement appelé « compression logarithmique .» En d’autres termes, avec STARKs, vous passez beaucoup moins de temps à vérifier la déclaration qu’à la calculer.
Cairo permet d’exprimer des déclarations de calcul générales qui peuvent être prouvées par des STARK-proof et vérifiées par les verifiers STARK correspondants.
C’est là qu’intervient l’opportunité d’effectuer une récursion : de la même manière que nous écrivons un programme en Cairo qui prouve l’exactitude de milliers de transactions, nous pouvons également écrire un programme en Cairo qui vérifie plusieurs STARK-proofs. Nous pouvons générer une seule preuve attestant la validité de plusieurs preuves «amont.» C’est ce que nous appelons une preuve récursive (Recursive Proving).
En raison de la compression logarithmique et du temps de test approximativement linéaire, la vérification d’une STARK-proof prend relativement peu de temps (on s’attend à quelques minutes dans un futur proche).
Lors de l’implémentation de Recursion, SHARP peut prouver les instructions à leur arrivée. Les preuves peuvent être fusionnées en preuves récursives de différents modèles jusqu’à ce que, à un moment donné, la preuve résultante soit soumise à un contrat de vérifier on-chain. Un schéma typique est représenté sur le dessin 2 :
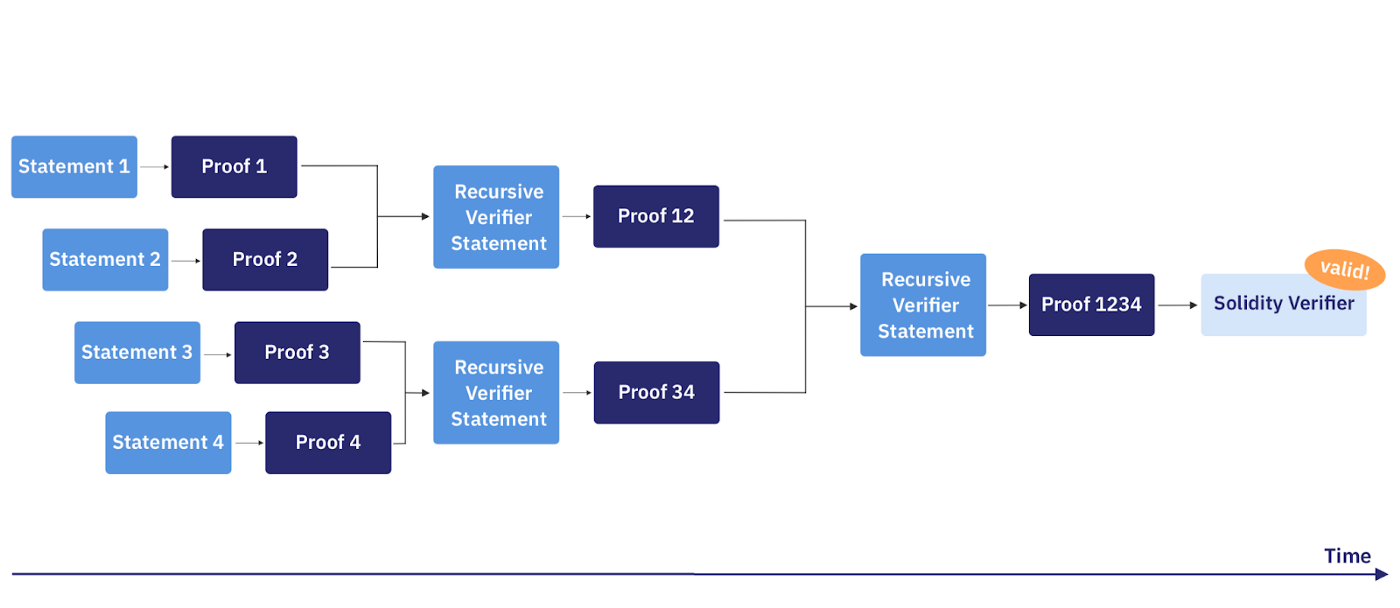
Dans cet exemple, quatre déclarations sont envoyés vers SHARP (provenant peut-être de quatre sources différentes). Ces déclarations sont prouvées en parallèle. Ensuite, chaque paire de preuves est validée par Recursive Verifier – un programme Cairo qui vérifie les STARK-proofs – pour laquelle une preuve est générée. Cette déclaration affirme que l’exactitude de deux preuves a été vérifiée. Ensuite, les deux preuves sont à nouveau fusionnées (merged) par une instruction Recursive Verifier. Il en résulte une seule preuve attestant les quatre déclarations originales. Cette preuve peut ensuite être transmise on-chain, pour être vérifiée par un smart contract de Solidity verifier.
Avantages immédiats des preuves récursives
Réduction des coûts on-chain
D’emblée, nous parvenons à «compresser» plusieurs preuve en une seule, ce qui implique un coût de vérification on-chain inférieur par transaction (où chaque déclaration peut inclure de nombreuses transactions).
Avec la récursion, la barrière des ressources de calcul (p.ex la mémoire) qui limitait la taille des preuves jusqu’à présent, est éliminée, puisque chaque déclaration de taille limitée peut être vérifiée séparément. Par conséquent, lors de l’utilisation de la récursion, la taille effective du Train de la récursion est presque illimitée, et le coût par transaction peut être réduit d’un ordre de grandeur.
Concrètement, la réduction dépend de la latence acceptable (et du rythme auquel les transactions arrivent). En outre, comme chaque preuve est généralement accompagnée d’une output (sortie) tel que des données on-chain, il y a des limites à la quantité de données qui peuvent être écrites on-chain avec une preuve unique. Néanmoins, une réduction des coûts d’un ordre de grandeur, voire mieux, est trivialement réalisable.
Réduction de la latence
Le modèle de preuve récursive réduit la latence de la preuves de grands Trains d’une déclaration. Ceci est le résultat de deux facteurs:
- Les déclarations entrantes peuvent être vérifiées en parallèle (par opposition à la preuve d’une très grande déclaration combinée).
- Il n’est pas nécessaire d’attendre la dernière déclaration dans le Train pour commencer à prouver. Plutôt, les preuves peuvent être combinées avec de nouvelles déclarations au fur et à mesure qu’elles arrivent. Cela signifie que la latence de la dernière instruction joignant un Train, est approximativement le temps nécessaire pour prouver cette dernière instruction plus le temps nécessaire pour prouver une instruction de Recursive Verifier (qui atteste de toutes les instructions qui ont déjà «embarqué» sur ce Train particulier).
Nous développons et optimisons activement la latence de la démonstration de l’instruction Recursive Verifier. Nous nous attendons à ce que cela atteigne l’ordre de quelques minutes d’ici quelques mois. Ainsi, un SHARP très efficace peut offrir des temps de latence allant de quelques minutes à quelques heures, selon le compromis par rapport au coût on-chain par transaction. Ceci représente une amélioration significative de la latence de SHARP.
Faciliter L3
Le développement de déclaration Recursive Verifier en Cairo ouvre également la possibilité de soumettre des preuves à StarkNet, puisque cette déclaration peut être inclu dans un smart contrat StarkNet. Cela permet de construire des déploiements L3 au-dessus de StarkNet public (le réseau L2).
Le modèle récursif s’applique également à l’agrégation des preuves de L3, à vérifier par une seule preuve sur L2. Par conséquent, l’hyper-scaling est atteint là aussi.
Plus d’avantages subtils
Récursion d’application
Récursion ouvre encore plus d’opportunités pour les plateformes et les applications qui souhaitent augmenter leurs coûts et leurs performances.
Chaque STARK proof atteste de la validité d’une instruction appliquée à une input (entrée) connue sous le nom “public input” (ou “program output” en Cairo). Conceptuellement, la récursion STARK compresse deux preuves avec deux inputs en une preuve avec deux inputs. En d’autres termes, alors que le nombre de preuves est réduit, le nombre d’inputs reste constant. Ces inputs sont ensuite généralement utilisées par une application pour mettre à jour un state (état) sur L1 (par exemple pour mettre à jour une state root ou effectuer un retrait on-chain).
Si la déclaration récursive est autorisée à tenir compte de l’application, c’est-à-dire qu’elle reconnaît la sémantique de l’application elle-même, elle peut à la fois compresser deux preuves en une seule et combiner les deux inputs en une seule. La déclaration résultante atteste de la validité de la combinaison d’inputs basée sur la sémantique de l’application, d’où le nom de Récursion Applicative (voir le dessin 3, par exemple).
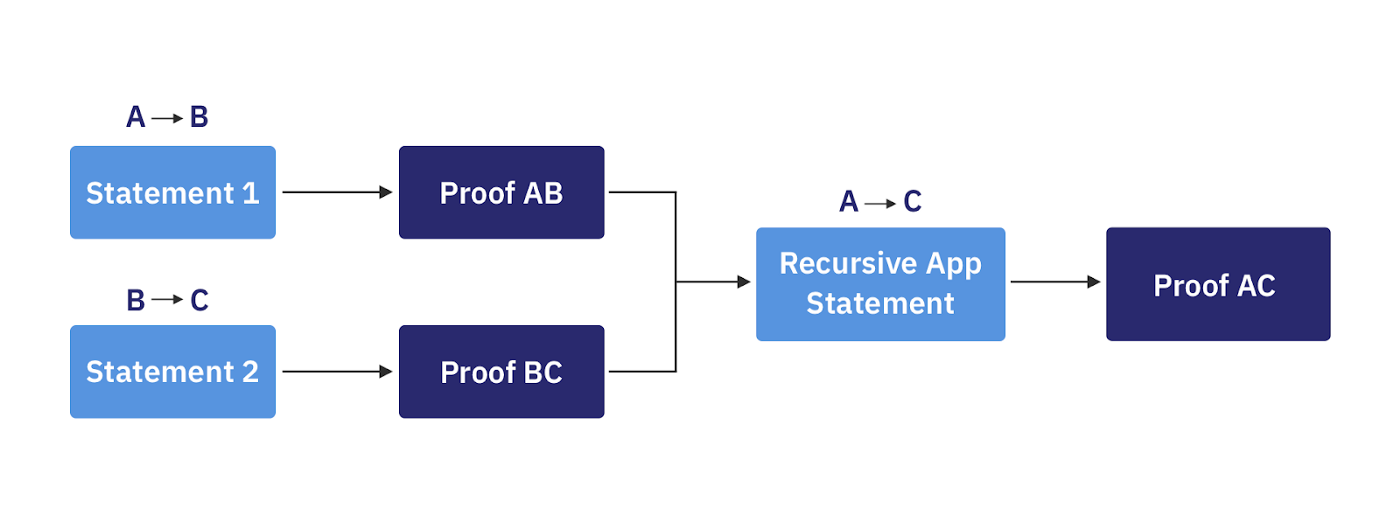
Ici, Statement 1 atteste un update state de A à B et Statement 2 atteste d’un update state ultérieure de B à C. Les preuves de Statement 1 et de Statement 2 peuvent être combinées dans un troisième state, attestant la mise à jour directe de A à C. En appliquant une logique similaire récursivement, on peut réduire considérablement le coût de la mise à jour de l’état jusqu’à l’exigence de latence de finalité.
Un autre exemple important de Applicative Recursion est de compresser les données du rollup en plusieurs preuves. Par exemple, pour un validity Rollup tel que StarkNet, chaque mise à jour de stockage sur L2 est également incluse comme données de transmission sur L1, afin de garantir la disponibilité des données. Toutefois, il n’est pas nécessaire d’envoyer plusieurs mises à jour pour le même élément de stockage, car seule la valeur finale des transactions attestées par la preuve vérifiée est requise pour la disponibilité des données. Cette optimisation est déjà réalisée au sein d’un seul bloc StarkNet. Cependant, en générant une preuve par bloc, Applicative Recursion peut compresser ces données de rollup sur plusieurs blocs L2. Cela peut entraîner une réduction significative des coûts, permettant des intervalles de block plus courts sur L2, sans sacrifier la scalabilité des mises à jour L1.
À noter : La récursion applicative peut être combinée avec la récursion applicative-agnostique comme décrit plus haut. Ces deux optimisations sont indépendantes.
Réduction de la complexité du verifier on-chain
La complexité du STARK verifier dépend du type de déclarations qu’il est conçu pour vérifier. En particulier, pour les déclarations Cairo, la complexité du verifier dépend des éléments spécifiques autorisés dans le langage Cairo, et plus particulièrement des modules intégrés pris en charge (si nous utilisons la métaphore CPU pour Cairo, alors les modules intégrés sont l’équivalent de micro-circuits dans un CPU : des calculs effectués si fréquemment qu’ils nécessitent leur propre calcul optimisé).
Le langue Cairo continue d’évoluer et offre de plus en plus d’intégrations utiles. D’un autre côté, le Recursive Verifier nécessite seulement l’utilisation d’un petit sous-ensemble de ces éléments intégrés. Ainsi, un SHARP récursif peut supporter avec succès n’importe quelle déclaration de Cairo en supportant le langage complet dans les recursive verifiers. Spécifiquement, le verifier de Solidity L1 n’a besoin que de vérifier les preuves récursives, et peut donc se limiter à un sous-ensemble plus stable du langage Cairo : Le verifier L1 n’a pas besoin de suivre les dernières et les plus grandes fonctionnalités intégrées. En d’autres termes, la vérification des déclarations complexes en constante évolution est reléguée à L2, laissant au verifier L1 le soin de vérifier des déclarations plus simples et plus stables.
Réduction des Footprints de calcul
Avant la récursion, la possibilité d’agréger plusieurs instructions en une seule preuve était limitée par la taille maximale de l’instruction pouvant être testée sur les instances de calcul disponibles (et le temps nécessaire pour produire de telles preuves).
Avec la récursion, il n’est plus nécessaire de prouver des affirmations aussi volumineuses. Par conséquent, il est possible d’utiliser des instances de calcul plus petites, moins coûteuses et plus accessibles (bien qu’un plus grand nombre d’entre elles puissent être nécessaires qu’avec des provers monolithiques de grande taille). Cela permet le déploiement d’instances de prover dans des environnements plus physiques et virtuels qu’auparavant.
Résumé
Les Recursive proofs de calcul général servent désormais de nombreux systèmes de production, y compris StarkNet, sur Mainnet Ethereum.
Les avantages de la récursion se concrétiseront graduellement, à mesure qu’elle continue de permettre de nouvelles améliorations et elle permettra bientôt de réduire les frais de gaz à grande échelle et d’améliorer la latence en libérant le potentiel de la parallélisation.
Elle apportera des avantages significatifs en termes de coûts et de latence, ainsi que de nouvelles opportunités telles que L3 et applicative-récursion. L’optimisation du Recursive Verifier est en cours et l’on s’attend à ce que le rendement et les coûts soient encore améliorés au fil du temps.
Gidi Kaempfer, Head of Core Engineering, StarkWare
¹ Déclaration = Statement
*Général Computation : https://en.wikipedia.org/wiki/Computation
Turing Machine : https://en.wikipedia.org/wiki/Turing_machine
Traduction faite par @cleminso