Imagine you’re building a system where users can perform transactions such as selling and buying tokens. For each token, every user has a dedicated wallet.
Our database consists of four entities: User, Wallet, Token, and Transaction.

The transaction has a field delta that is either a positive or negative number. When positive, that is the number of tokens purchased. When negative, it is how many tokens were sold.
A balance is a sum of all deltas from all transactions within a given wallet.
How do you calculate the balance?
You’re building a query to retrieve all wallets that belong to a given user. You want to show how many tokens of each type the user has.
How would you approach such a query? Before reading further, think for a few seconds, then compare your initial thoughts with my research. If there’s something I haven’t covered, share it with me on Twitter!
Use an aggregate function to compute the balance by summarising all transactions.
This is probably the most popular and a solution you should start with… unless you’re using Prisma! Postgres (and other relational databases) were designed to work with large datasets, and with enough resources on a machine (typically, they scale vertically), it shouldn’t be a problem for them to handle hundreds of thousands of records relatively fast.
However, if you’re like me, you probably think it’s better to save that computational power for queries we can’t optimize further.
If that doesn’t convince you yet, here’s another thing. While Prisma supports aggregation via aggregate API, selecting fields, joining related tables, and aggregating in a single query is impossible.
That means we’re back writing good old SQL. I’d rather look for alternatives and enjoy TypeScript-type safety at the early stage of my product lifecycle as long as possible.
Select all transactions and then reduce them into balance for each wallet
users.map((user) => ({
...user,
balance: user.wallet.transactions.reduce((acc, t) => acc + t.delta, 0),
}));
This is probably the least performant solution with O(n^2) complexity, which is typical when dealing with nested loops (you should be able to speed that up to O(n) if you have recently done any coding challenges). Performing such an operation with hundreds of thousands of records doesn’t sound right, regardless of time complexity.
Store a computed balance of each wallet after every transaction
While this option sounds intuitive at first, it is dangerous. We duplicate the data in two places and increase the likelihood of data corruption. As soon as transactions start flowing throughout the system, you’re never sure if the value you’re reading is accurate.
That’s unfortunate because having direct access to a balance field on a Wallet would be the most intuitive and performant way of accessing that data.
What if I told you that creating such a computed field was possible without risking your data integrity?
Say hello to database functions! 👋
Trigger functions
If this is your first time working with Postgres, let me tell you one thing:
That was a great choice!
It’s an amazing open-source relational database packed with many features that will come in handy as your application grows. Trigger functions are one of them.
If you’re interested in other advanced Postgres features, make sure to subscribe to my blog. I will definitely be exploring them as I advance in my development.
On a high level, Postgres lets you register a callback that will run before or after a specified operation happens in the database, such as INSERT, UPDATE or DELETE.
You can do many great things with database functions, such as performing checks on the data that can’t be expressed as constraints or updating records in related tables.
Does that sound familiar to you? It is exactly what we’ll be doing today!
Creating a Postgres function to update the balance on every transaction
There are two ways to create a database function - programmatically, by running a query, or by using the Supabase dashboard.
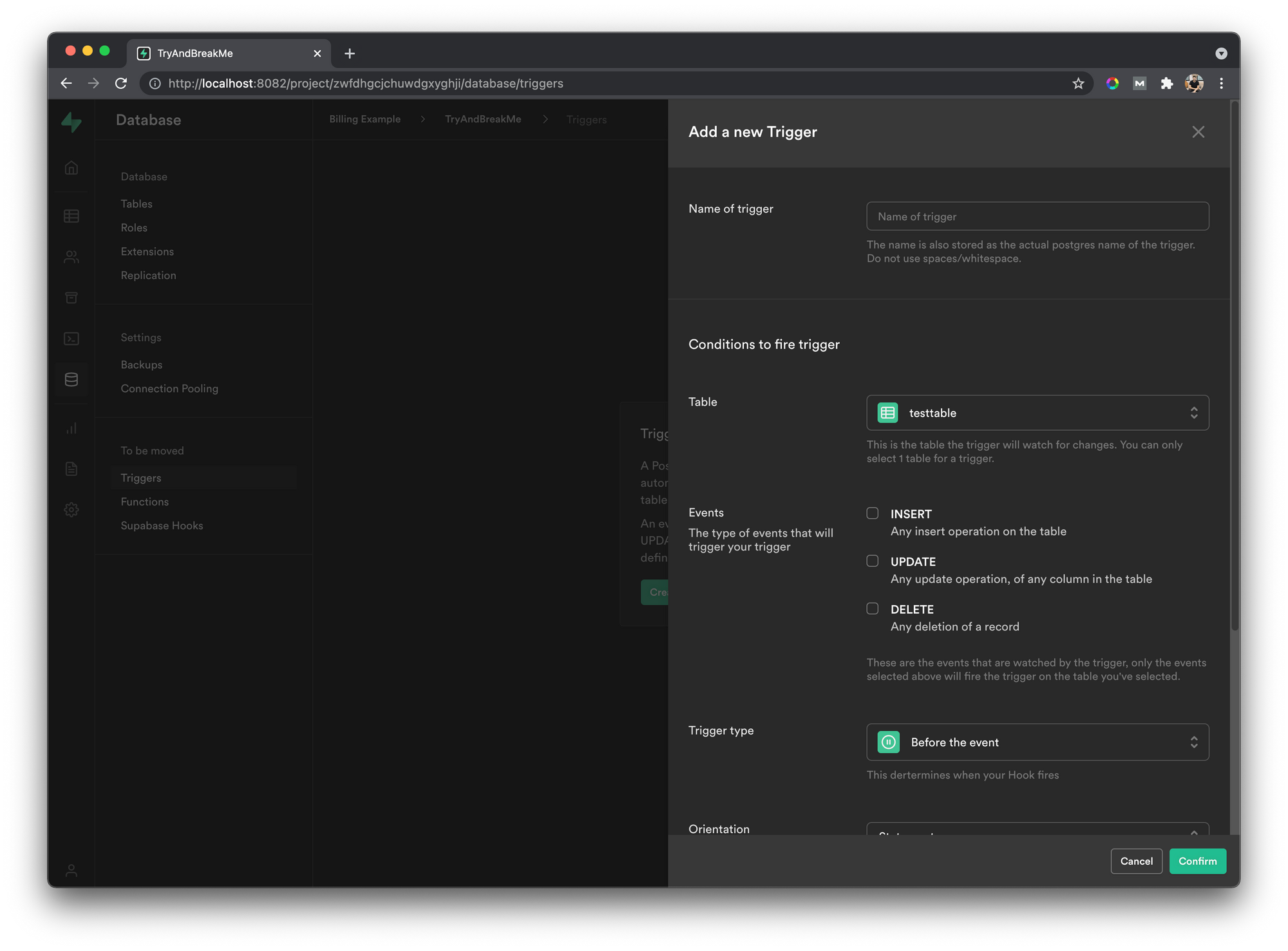
Either way, you will need to write a bit of PL/pgSQL. It’s a procedural programming language supported by Postgres.
Sounds scary? Don’t worry.
You should feel at home if you have worked with SQL before. If you look at the function below, without going into many details, you will notice that there is a fair amount of good old SQL in it.
CREATE FUNCTION calculate_balance() RETURNS trigger AS $$
BEGIN
UPDATE public."Wallet" w
SET balance = sub.balance
FROM (
SELECT SUM(delta) AS balance
FROM public."Transaction" t
WHERE t."walletId" = new."walletId"
GROUP BY t."walletId"
) sub
WHERE w.id = new."walletId";
return null;
END;
$$ LANGUAGE plpgsql;
Now we are ready to break that down into pieces!
CREATE FUNCTION calculate_balance() RETURNS trigger AS $$
/* your function goes here */
$$ LANGUAGE plpgsql;
This statement creates a function and saves it under calculate_balance in the global namespace.
If you’re wondering what’s that $$ about, it’s an alternative symbol for enclosing string literals. The body of your function is a string literal. If we used single or double quotes, we would have to escape any nested occurrences of these characters.
UPDATE public."Wallet" w
SET balance = sub.balance
FROM (
SELECT SUM(delta) AS balance
FROM public."Transaction" t
WHERE t."walletId" = new."walletId"
GROUP BY t."walletId"
) sub
WHERE w.id = new."walletId";
This is our function body. It’s an update statement. What is worth noting is that there’s a new variable that includes a row that results from the operation that triggered our function. If our function was triggered by an INSERT operation, this would be a newly added record. If it was an UPDATE, it would hold the latest data.
If we’re dealing with DELETE operation,
newwill naturally be null and we should read fromold. We’re not handling that case in our function yet. It will most likely require an IF condition somewhere inside function body to check whetherTG_OPvariable isdeleteand if yes, chooseoldinstead.
Creating a trigger to run our function
Now that we have created a function, it is time to define what will trigger it. Like before, what we will be writing is going to be a SQL-like query that describes the conditions under which our function should execute.
CREATE TRIGGER on_new_transaction
AFTER INSERT OR UPDATE ON public."Transaction"
FOR EACH ROW EXECUTE PROCEDURE calculate_balance();
Here, we create on_new_transaction trigger that we want to run after either insert or update operation is performed on the Transaction table. We want our function calculate_balance() to run for every added record.
An alternative to running for every added record would be to run for every statement. There are use cases where that makes sense. However, in our scenario, we want to recalculate balance after every transaction, as they may concern different wallets.
Registering a function in the database
Now that our entire trigger is ready, it is time to register it within our database.
The easiest way to register a function would be to execute that query. I personally use Supabase SQL Editor and occasionally save queries for future reuse.

After we copy the query into SQL Editor, we hit RUN. The operation should complete successfully.
To verify that our function and trigger were added, we can go to the Database tab and select Triggers from the left menu.

If everything worked well, we should see the trigger right in the middle of the page and the conditions that will make it run.
Now, going to Functions:

We should see our newly created function at the top of the screen.
That’s it!
We just created a Postgres function that computes a field each time underlying data changes. It’s almost like a cache, but built-in. And because it’s running on a database level, we don’t have to worry about data integrity, which would be quite a challenge if done manually.
Thanks for reading,
Mike