
作者:Alex Xu,Mint Ventures研究合伙人
引言
在我的上一篇文章中,提到本轮加密牛市周期与前两轮周期相比,缺少足够有影响力的新商业和新资产叙事。AI是本轮Web3领域少有的新叙事之一,本文笔者将结合今年的热点AI项目IO.NET,尝试梳理关于以下2个问题的思考:
-
AI+Web3在商业上的必要性
-
分布式算力服务的必要性和挑战
其次,笔者将梳理AI分布式算力的代表项目:IO.NET项目的关键信息,包括产品逻辑、竞品情况和项目背景,并就项目的估值进行推演。
本文关于AI和Web3结合一节的部分思考,受到了Delphi Digital研究员Michael rinko所写的《The Real Merge》的启发。本文的部分观点存在对该文章的消化和引述,推荐读者阅读原文。
本文为笔者截至发表时的阶段性思考,未来可能可能发生改变,且观点具有极强的主观性,亦可能存在事实、数据、推理逻辑的错误,请勿作为投资参考,欢迎同业的批评和探讨。
以下为正文部分。
1.商业逻辑:AI和Web3的结合点
1.1 2023:AI造就的新“奇迹年”
回看人类发展史,一旦科技实现了突破性进展,从个体日常生活,到各个产业格局,再到整个人类文明,都会跟着发生天翻地覆的变化。
人类历史中有两个重要年份,分别是1666年和1905年,如今它们被称为科技史上的两大“奇迹年”。
1666年作为奇迹年,是因为牛顿的科学成果在该年集中式地涌现。这一年,他开辟了光学这个物理分支,创立了微积分这个数学分支,导出了引力公式这个现代自然科学的基础定律。这当中无论哪一项都是未来百年人类科学发展的奠基式贡献,大大加速了整体科学的发展。
第二个奇迹年是1905年,彼时仅仅26岁的爱因斯坦在《物理学年鉴》上连续发表4篇论文,分别涉及光电效应(为量子力学奠基)、布朗运动(成为分析随机过程的重要引用)、狭义相对论和质能方程(也就是那个知名公式E=MC^2)。在后世评价中,这四篇论文每一篇都超过诺贝尔物理学奖的平均水平(爱因斯坦本人也因为光电效应论文获得了诺贝尔奖),人类文明的历史进程再一次被大大推进了好几步。
而刚刚过去的2023年,大概率也会因为ChatGPT,而被称之为又一个“奇迹年”。
我们把2023年看做人类科技史上的有一个“奇迹年”,不仅是因为GPT在自然语言理解和生成上的巨大进步,更是因为人类从GPT的进化中摸清了大语言模型能力增长的规律——即通过扩大模型参数和训练数据,就能指数级别提升模型的能力——且这一进程短期还看不到瓶颈(只要算力够用的话)。
该能力远不至于理解语言和生成对话,还能被广泛地交叉用于各类科技领域,以大语言模型在生物领域的应用为例:
-
2018年,诺贝尔化学奖得主弗朗西斯·阿诺德在颁奖仪式上才说道:“今天我们在实际应用中可以阅读、写入和编辑任何 DNA 序列,但我们还无法通过它创作(compose it)。”仅仅在他讲话的5年后,2023年,来自斯坦福大学和硅谷的AI创业企业Salesforce Research的研究者,在《自然-生物技术》发表论文,他们通过基于GPT3微调而成的大语言模型,从0创造出了全新的100万种蛋白质,并从中寻找到2种结构截然不同、却都具有杀菌能力的蛋白质,有希望成为抗生素之外的细菌对抗方案。也就是说:在AI的帮助下,蛋白质“创造”的瓶颈突破了。
-
而在此前,人工智能AlphaFold算法在18个月内,把地球上几乎所有的2.14亿种蛋白质结构都做了预测,这项成果是过往所有人类结构生物学家工作成果的几百倍。
有了基于AI的各类模型,从生物科技、材料科学、药物研发等硬科技,再到法律、艺术等人文领域,必将迎来翻天覆地的变革,而2023正是这一切的元年。
我们都知道,近百年来人类在财富上的创造能力是指数级别增长的,而AI技术的快速成熟,必然会进一步加速这一进程。
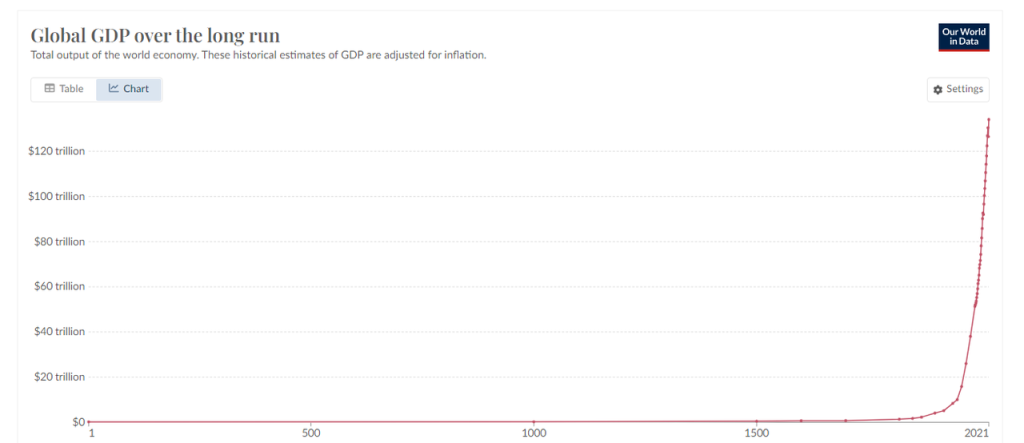
1.2 AI与Crypto的结合
要从本质上理解AI与Crypto结合的必要性,可以从两者互补的特性开始。
AI和Crypto特性的互补
AI有三个属性:
-
随机性:AI具有随机性,其内容生产的机制背后是一个难以复现、探查的黑盒,因此结果也具有随机性
-
资源密集:AI是资源密集型产业,需要大量的能源、芯片、算力
-
类人智能:AI(很快将)能够通过图灵测试,此后,人机难辨*
※2023年10月30日,美国加州大学圣迭戈分校的研究小组发布了关于GPT-3.5和GPT-4.0的图灵测试结果(测试报告)。GPT4.0成绩为41%,距离及格线50%仅差9%,同项目人类测试成绩为63%。本图灵测试的含义为有百分之多少的人认为和他聊天的那个对象是真人。如果超过50%,就说明人群中至少有一半以上的人认为那个交谈对象是人,而不是机器,即视作通过图灵测试。
AI在为人类创造新的跨越式的生产力的同时,它的这三个属性也给人类社会带来的巨大的挑战,即:
-
如何验证、控制AI的随机性,让随机性成为一种优势而非缺陷
-
如何满足AI所需要的巨大能源和算力缺口
-
如何分辨人和机器
而Crypto和区块链经济的特性,或许正好是解决AI带来的挑战的良药,加密经济具有以下3个特征:
-
确定性:业务基于区块链、代码和智能合约运行,规则和边界清晰,什么输入就有什么结果,高度确定性
-
资源配置高效:加密经济构建了一个庞大的全球自由市场,资源的定价、募集、流转非常快速,且由于代币的存在,可以通过激励加速市场供需的匹配,加速到达临界点
-
免信任:账本公开,代码开源,人人可便捷验证,带来“去信任(trustless)”的系统,而ZK技术则避免验证同时的隐私暴露
接下来通过3个例子来说明AI和加密经济的互补性。
例子A:解决随机性,基于加密经济的AI代理
AI代理(AI Agent)即负责基于人类意志,替人类执行工作的人工智能程序(代表性项目有Fetch.AI)。假设我们要让自己的AI代理处理一笔金融交易,比如“买入1000美元的BTC”。AI代理可能面临两种情况:
情况一,它要对接传统金融机构(比如贝莱德),购入BTC ETF,这里面临着大量的AI代理和中心化机构的适配问题,比如KYC、资料审查、登录、身份验证等等,目前来说还是非常麻烦。
情况二,它基于原生加密经济运行,情况会变得简单得多,它会通过Uniswap或是某个聚合交易平台,直接用你的账户签名、下单完成交易,收到WBTC(或是其他封装格式的BTC),整个过程快捷简单。实际上,这就是各类Trading BOT在做的事情,它们实际上已经扮演了一个初级的AI代理的角色,只不过工作专注于交易而已。未来各类交易BOT随着AI的融入和演化,必然能执行更多复杂的交易意图。比如:跟踪100个链上的聪明钱地址,分析它们的交易策略和成功率,用我地址里的10%资金在一周内执行类似交易,并在发现效果不佳时停止,并总结失败的可能原因。
AI在区块链的系统中运行会更加良好,本质上是因为加密经济规则的清晰性,以及系统访问的无许可。在限定的规则下执行任务,AI的随机性带来的潜在风险也将更小。比如AI在棋牌比赛、电子游戏的表现已经碾压人类,就是因为棋牌和游戏是一个规则清晰的封闭沙盒。而AI在自动驾驶上的进展会相对缓慢,因为开放的外部环境的挑战更大,我们也更难容忍AI处理问题的随机性。
例子B:塑造资源,通过代币激励聚集资源
BTC背后的全球的算力网络,其当前的总算力(Hashrate: 576.70 EH/s)超过了任何一个国家的超级计算机的综合算力。其发展动力来自于简单、公平的网络激励。
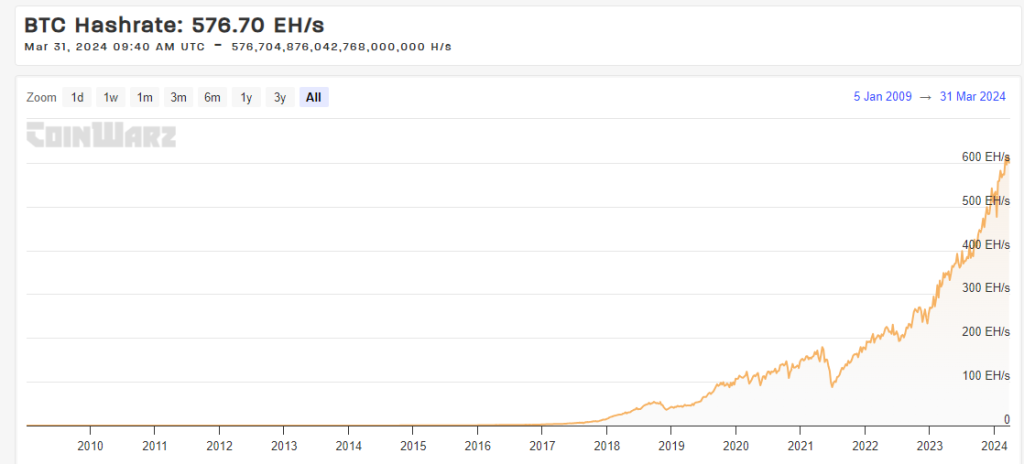
除此之外,包括Mobile在内的DePIN项目们,也正在尝试通过代币激励塑造供需两端的双边市场,实现网络效应。本文接下来将重点梳理的IO.NET,则是为了汇聚AI算力设计的平台,希望通过代币模型,激发出更多的AI算力潜力。
例子C:开源代码,引入ZK,保护隐私的情况下分辨人机
作为OpenAI创始人Sam Altman参与的Web3项目,Worldcoin通过硬件设备Orb,基于人的虹膜生物特征,通过ZK技术生成专属且匿名的哈希值,用于验证身份,区别人和机器。今年3月初,Web3艺术项目Drip就开始使用Worldcoin的ID,来验证真人用户和发放奖励。
此外,Worldcoin也在近日开源了其虹膜硬件Orb的程序代码,就用户生物特征的安全和隐私提供保证。
总体来说,加密经济由于代码和密码学的确定性、无许可和代币机制带来的资源流转和募集优势,和基于开源代码、公开账本的去信任属性,已经成为人类社会面临AI挑战的一个重要的潜在解决方案。
而且其中最迫在眉睫,商业需求最旺盛的挑战,就是AI产品在算力资源上的极度饥渴,围绕芯片和算力的巨大需求。
这也是本轮牛市周期,分布式算力项目的涨势冠绝整体AI赛道的主要原因。
分布式计算(Decentralized Compute)的商业必要性
AI需要大量的计算资源,无论是用于训练模型还是进行推理。
而在大语言模型的训练实践中,有一个事实已经得到确认:只要数据参数的规模足够大,大语言模型就会涌现出一些之前没有的能力。每一代GPT的能力相比上一代的指数型跃迁,背后就是模型训练的计算量的指数级增长。
DeepMind和斯坦福大学的研究显示,不同的大语言模型,在面对不同的任务(运算、波斯语问答、自然语言理解等)时,只要把模型训练时的模型参数规模加大(对应地,训练的计算量也加大了),在训练量达不到10^22 FLOPs(FLOPs指每秒浮点运算量,用于衡量计算性能)之前,任何任务的表现都和随机给出答案是差不多的;而一旦参数规模超越那个规模的临界值后,任务表现就急剧提升,不论哪个语言模型都是这样。


也正是在算力上“大力出奇迹”的规律和实践的验证,让OpenAI的创始人Sam Altman提出了要募集7万亿美金,构建一个超过目前台积电10倍规模的先进芯片厂(该部分预计花费1.5万亿),并用剩余资金用于芯片的生产和模型训练。
除了AI模型的训练需要算力之外,模型的推理过程本身也需要很大的算力(尽管相比训练的计算量要小),因此对芯片和算力的饥渴成为了AI赛道参与者的常态。
相对于中心化的AI算力提供方如Amazon Web Services、Google Cloud Platform、微软的Azure等,分布式AI计算的主要价值主张包括:
-
可访问性:使用 AWS、GCP 或 Azure 等云服务获取算力芯片的访问权限通常需要几周时间,而且流行的 GPU 型号经常无货。此外为了拿到算力,消费者往往需要跟这些大公司签订长期、缺少弹性的合同。而分布式算力平台可以提供弹性的硬件选择,有更强的可访问性。
-
定价低:由于利用的是闲置芯片,再叠加网络协议方对芯片和算力供给方的代币补贴,分布式算力网络可能可以提供更为低廉的算力。
-
抗审查:目前尖端算力芯片和供应被大型科技公司所垄断,加上以美国为代表的政府正在加大对AI算力服务的审查,AI算力能够被分布式、弹性、自由地获取,逐渐成为一个显性需求,这也是基于web3的算力服务平台的核心价值主张。
如果说化石能源是工业时代的血液,那算力或将是由AI开启的新数字时代的血液,算力的供应将成为AI时代的基础设施。正如稳定币成为法币在Web3时代的一个茁壮生长的旁支,分布式的算力市场是否会成为快速成长的AI算力市场的一个旁支?
由于这还是一个相当早期的市场,一切都还有待观察。但是以下几个因素可能会对分布式算力的叙事或是市场采用起到刺激作用:
-
GPU持续的供需紧张。GPU的持续供应紧张,或许会推动一些开发者转向尝试分布式的算力平台。
-
监管扩张。想从大型的云算力平台获取AI算力服务,必须经过KYC以及层层审查。这反而可能促成分布式算力平台的采用,尤其是一些受到限制和制裁的地区。
-
代币价格的刺激。牛市周期代币价格的上涨,会提高平台对GPU供给端的补贴价值,进而吸引更多供给方进入市场,提高市场的规模,降低消费者的实际购买价格。
但同时,分布式算力平台的挑战也相当明显:
-
技术和工程难题
-
工作验证问题:深度学习模型的计算,由于层级化的结构,每层的输出都作为后一层的输入,因此验证计算的有效性需要执行之前的所有工作,无法简单有效地进行验证。为了解决这个问题,分布式计算平台需要开发新的算法或使用近似验证技术,这些技术可以提供结果正确性的概率保证,而不是绝对的确定性。
-
并行化难题:分布式算力平台汇聚的是长尾的芯片供给,也就注定了单个设备所能提供的算力比较有限,单个芯片供给方几乎短时间独立完成AI模型的训练或推理任务,所以必须通过并行化的手段来拆解和分配任务,缩短总的完成时间。而并行化又必然面临任务如何分解(尤其是复杂的深度学习任务)、数据依赖性、设备之间额外的通信成本等一系列问题。
-
隐私保护问题:如何保证采购方的数据以及模型不暴露给任务的接收方?
-
-
监管合规难题
- 分布式计算平台由于其供给和采购双边市场的无许可性,一方面可以作为卖点吸引到部分客户。另一方面则可能随着AI监管规范的完善,成为政府整顿的对象。此外,部分GPU的供应商也会担心自己出租的算力资源,是否被提供给了被制裁的商业或个人。
总的来说,分布式计算平台的消费者大多是专业的开发者,或是中小型的机构,与购买加密货币和NFT的加密投资者们不同,这类用户对于协议所能提供的服务的稳定性、持续性有更高的要求,价格未必是他们决策的主要动机。目前来看,分布式计算平台们要获得这类用户的认可,仍然有较长的路要走。
接下来,我们就一个本轮周期的新分布式算力项目IO.NET进行项目信息的梳理和分析,并基于目前市场上同赛道的AI项目和分布式计算项目,测算其上市后可能的估值水平。
2.1 项目定位
IO.NET是一个去中心化计算网络,其构建了一个围绕芯片的双边市场,供给端是分布在全球的芯片(GPU为主,也有CPU以及苹果的iGPU等)算力,需求端是希望完成AI模型训练或推理任务的人工智能工程师。
在IO.NET的官网上,它这样写道:
Our Mission
Putting together one million GPUs in a DePIN – decentralized physical infrastructure network.
其使命是把百万数量级的GPU整合到它的DePIN网络中。
与现有的云AI算力服务商相比,其对外强调的主要卖点在于:
-
弹性组合:AI工程师可以自由挑选、组合自己所需要的芯片来组成“集群”,来完成自己的计算任务
-
部署迅速:无需数周的审批和等待(目前AWS等中心化厂商的情况),在几十秒内就可以完成部署,开始任务
-
服务低价:服务的成本比主流厂商低90%
此外,IO.NET未来还计划上线AI模型商店等服务。
2.2 产品机制和业务数据
产品机制和部署体验
与亚马逊云、谷歌云、阿里云一样,IO.NET提供的计算服务叫IO Cloud。IO Cloud是一个分布式的、去中心化的芯片网络,能够执行基于Python的机器学习代码,运行AI和机器学习程序。
IO Cloud的基本业务模块叫做集群(Clusters),Clusters是一个可以自我协调完成计算任务的GPU群组,人工智能工程师可以根据自己的需求来自定义想要的集群。
IO.NET的产品界面的用户友好度很高,如果你要部署属于自己的芯片集群,来完成AI计算任务,在进入它的Clusters(集群)产品页面后,就可以开始按需配置你要的芯片集群。
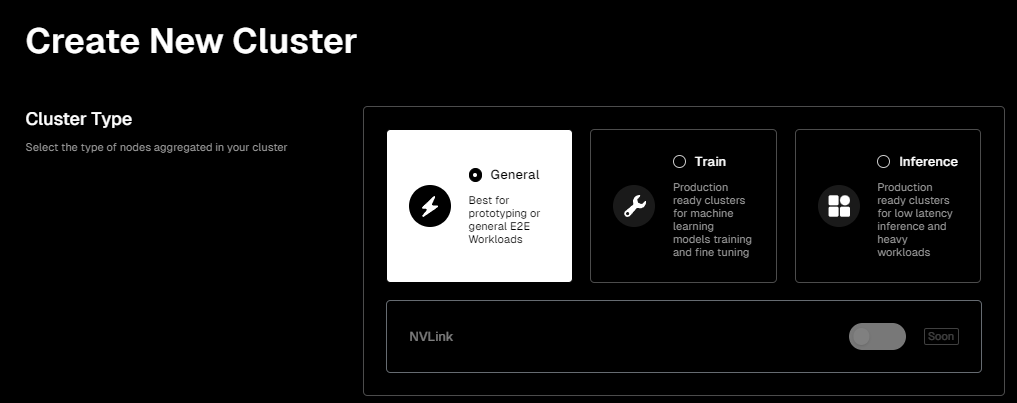
首先你需要选择自己的任务场景,目前有三个类型可供选择:
-
General(通用型):提供了一个比较通用的环境,适合早期不确定具体资源需求的项目阶段。
-
Train(训练型):专为机器学习模型的训练和微调而设计的集群。这个选项可以提供更多的GPU资源、更高的内存容量和/或更快的网络连接,以便于处理这些高强度的计算任务。
-
Inference(推理型):专为低延迟推理和重负载工作设计的集群。在机器学习的上下文中,推理指的是使用训练好的模型来进行预测或分析新数据,并提供反馈。因此,这个选项会专注于优化延迟和吞吐量,以便于支持实时或近实时的数据处理需求。
然后,你需要选择芯片集群的供应方,目前IO.NET与Render Network以及Filecoin的矿工网络达成了合作,因此用户可以选择IO.NET或另外两个网络的芯片来作为自己计算集群的供应方,相当于IO.NET扮演了一个聚合器的角色(但截至笔者撰文时,Filecon服务暂时下线中)。值得一提的是,根据页面显示,目前IO.NET在线可用GPU数量为20万+,而Render Network的可用GPU数量为3700+。
再接下来就进入了集群的芯片硬件选择环节,目前IO.NET列出可供选择的硬件类型仅有GPU,不包括CPU或是苹果的iGPU(M1、M2等),而GPU也主要以英伟达的产品为主。
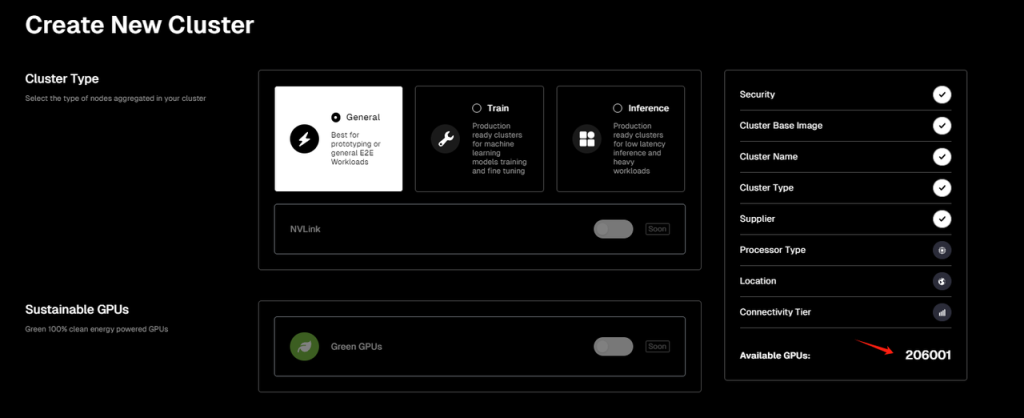
在官方列出、且可用的GPU硬件选项中,根据笔者测试的当日数据,IO.NET网络总在线的可用数量的GPU数量为206001张。其中可用量最多的是GeForce RTX 4090(45250张),其次是GeForce RTX 3090 Ti(30779张)。
此外,在处理AI计算任务如机器学习、深度学习、科学计算上更为高效的A100-SXM4-80GB芯片(市场价15000$+),在线数有7965张。
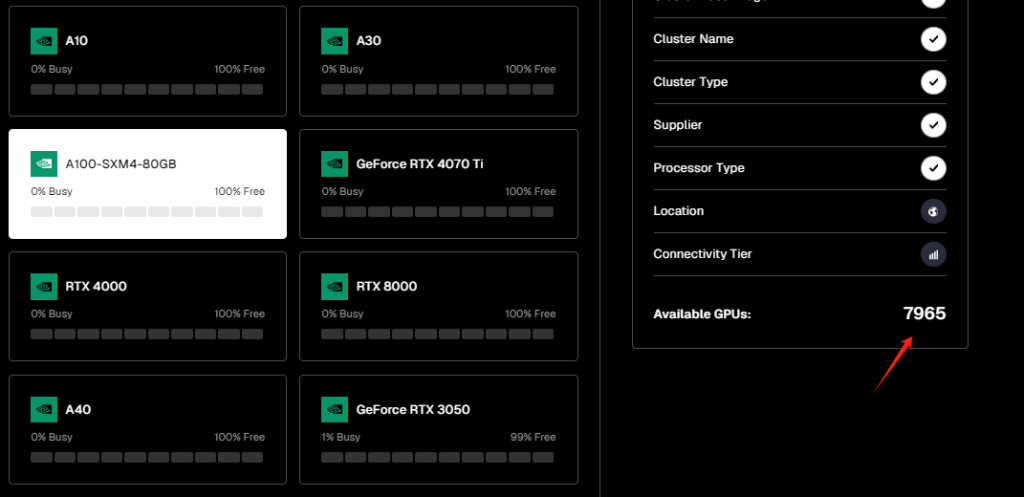
而英伟达从硬件设计开始就专为AI而生的H100 80GB HBM3显卡(市场价40000$+),其训练性能是A100的3.3倍,推理性能是A100的4.5倍,实际在线数量为86张。
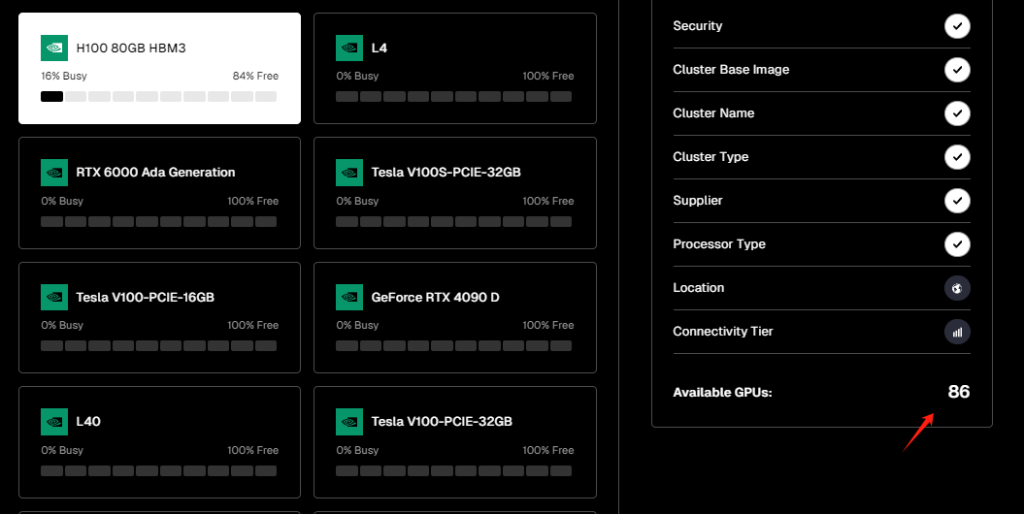
在选定集群的硬件类型后,用户还需要选择集群的地区、通信速度、租用的GPU数量和时间等参数。
最后,IO.NET根据综合的选择,会为你提供一个账单,以笔者的集群配置为例:
-
通用(General)任务场景
-
16张A100-SXM4-80GB芯片
-
最高连接速度(Ultra High Speed)
-
地理位置美国
-
租用时间为1周
该总账单价格为3311.6$,单张卡的时租单价为1.232$
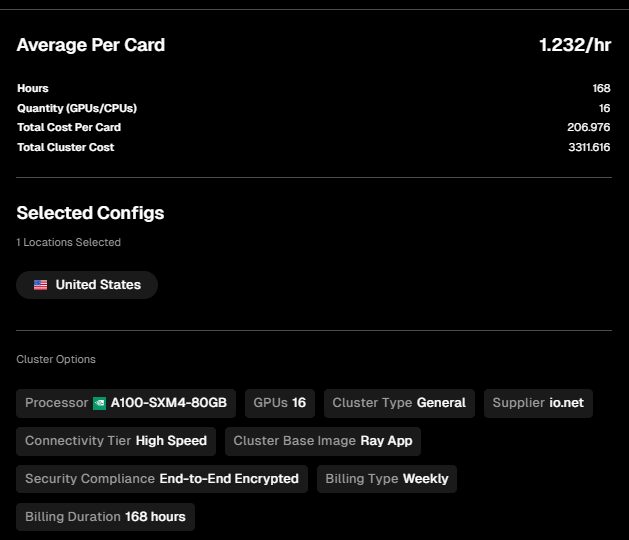
而A100-SXM4-80GB在亚马逊云、谷歌云和微软Azure的单卡时租价格分别为5.12$、5.07$和3.67$(数据来源:https://cloud-gpus.com/,实际价格会根据合约细节条款产生变化)。
因此仅就价格来说,IO.NET的芯片算力确实比主流厂商便宜不少,且供给的组合与采购也非常有弹性,操作也很容易上手。
业务情况
供给端情况
截至今年4月4日,根据官方数据,IO.NET在供应端的GPU总供给为371027张,CPU供给为42321张。此外,Render Network作为其合作伙伴,还有9997张GPU和776张CPU接入了网络的供给。
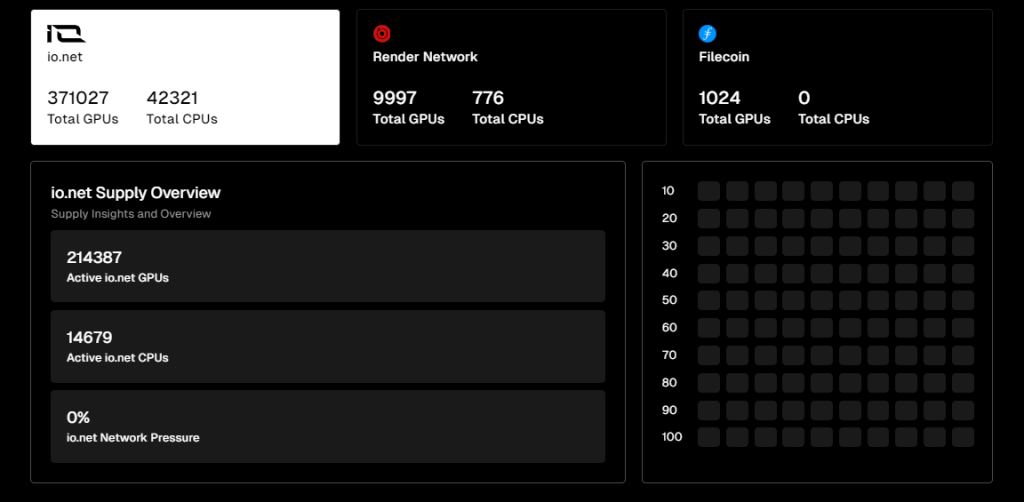
笔者撰文时,IO.NET接入的GPU总量中的214387处于在线状态,在线率达到了57.8%。来自Render Network的GPU的在线率则为45.1%。
以上供应端的数据意味着什么?
为了进行对比,我们再引入另一个上线时间更久的老牌分布式计算项目Akash Network来进行对比。
Akash Network早在2020年就上线了主网,最初主要专注于CPU和存储的分布式服务。2023年6月,其推出了GPU服务的测试网,并于同年9月上线了GPU分布式算力的主网。
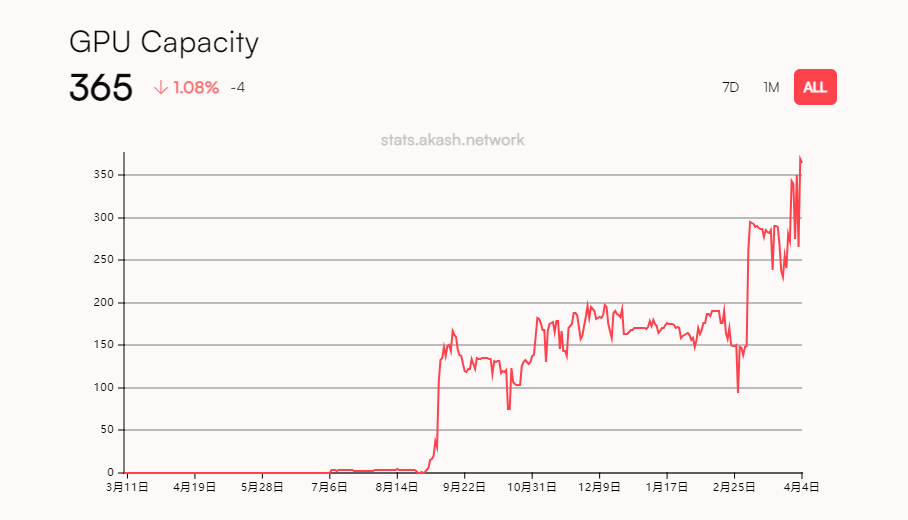
根据Akash官方数据,其GPU网络推出以来,供应端尽管持续增长,但截至目前为止GPU总接入数量仅为365张。
从GPU的供应量来看,IO.NET要比Akash Network高出了好几个数量级,已经是分布式GPU算力赛道最大的供应网络。
需求端情况

不过从需求端来看,IO.NET依旧处于市场培育的早期阶段,目前实际使用IO.NET来执行计算任务的总量不多。大部分在线的GPU的任务负载量为0%,只有A100 PCIe 80GB K8S、RTX A6000 K8S、RTX A4000 K8S、H100 80GB HBM3四款芯片有在处理任务。且除了A100 PCIe 80GB K8S之外,其他三款芯片的负载量均不到20%。
而官方当日披露的网络压力值为0%,意味着大部分芯片供应都处于在线待机状态。
而在网络费用规模上,IO.NET已经产生了586029$的服务费用,近一日的费用为3200$。
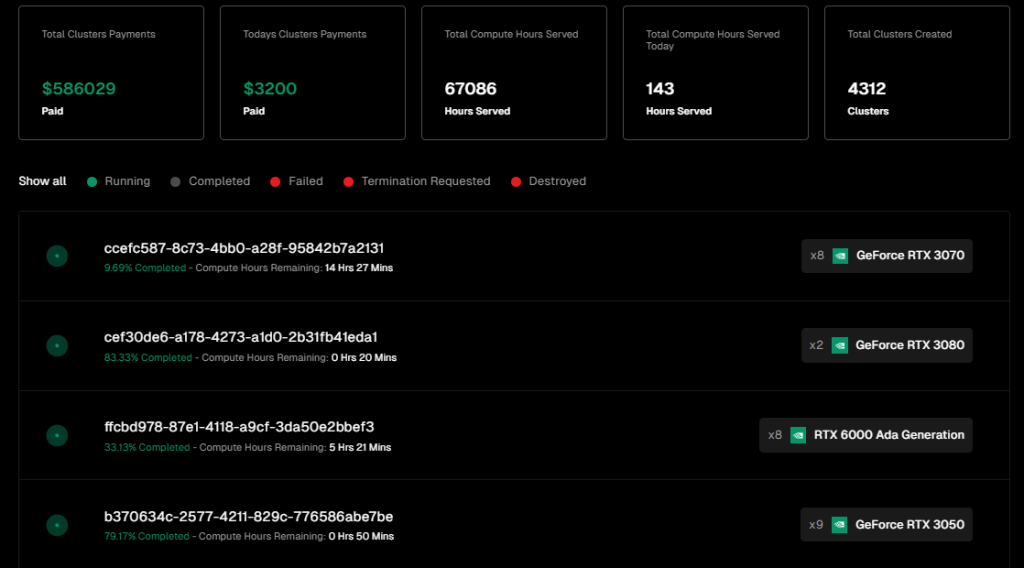
以上网络结算费用的规模,无论是总量还是日交易量,均与Akash处在同一个数量级,不过Akash的大部分网络收入来自于CPU的部分,Akash的CPU供应量有2万多张。
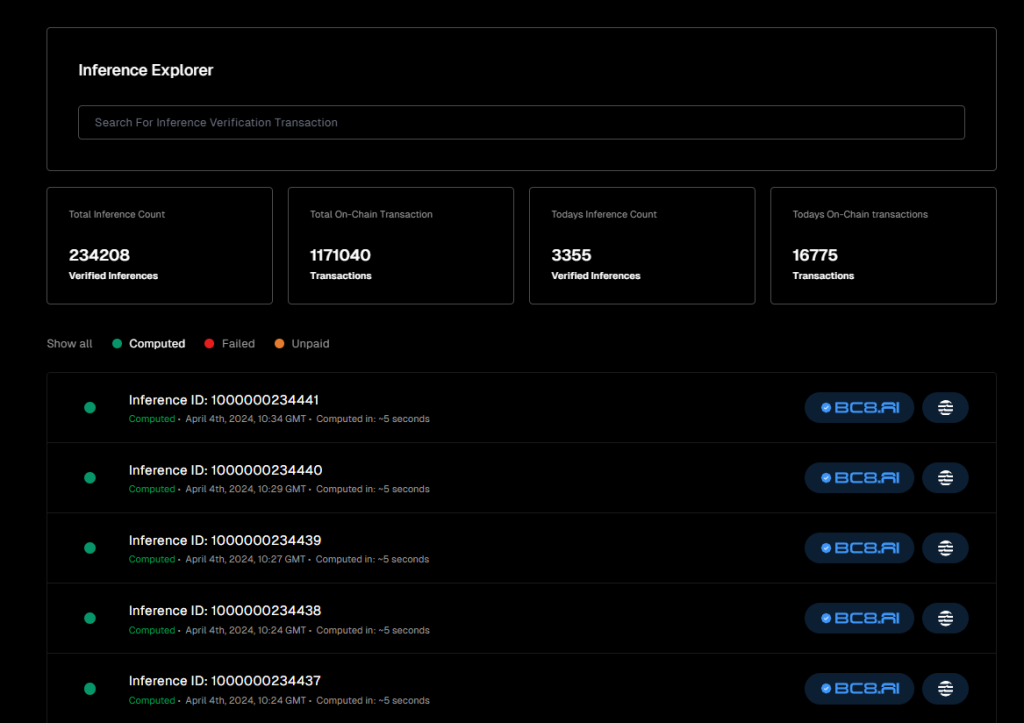
此外,IO.NET还披露了网络处理的AI推理任务的业务数据,截至目前其已经处理和验证的推理任务数量超过23万个, 不过这部分业务量大部分都产生于IO.NET所赞助的项目BC8.AI。
从目前的业务数据来看,IO.NET的供给端扩张顺利,在空投预期和代号“Ignition”的社区活动刺激下,让其迅速地汇聚起了大量的AI芯片算力。而其在需求端的拓展仍处于早期阶段,有机需求目前还不足。至于目前需求端的不足,是由于消费端的拓展还未开始,还是由于目前的服务体验尚不稳定,因此缺少大规模的采用,这点仍需要评估。
不过考虑到AI算力的落差短期内较难填补,有大量的AI工程师和项目在寻求替代方案,可能会对去中心化的服务商产生兴趣,加上IO.NET目前尚未开展对需求端的经济和活动刺激,以及产品体验的逐渐提升,后续供需两端的逐渐匹配仍然是值得期待的。
2.3 团队背景和融资情况
团队情况
IO.NET的核心团队成立之初的业务是量化交易,在2022年6月之前,他们一直专注于为股票和加密资产开发机构级的量化交易系统。出于系统后端对计算能力的需求,团队开始探索去中心化计算的可能性,并且最终把目光落在了降低GPU算力服务的成本这个具体问题上。
创始人&CEO:Ahmad Shadid
Ahmad Shadid在IO.NET之前一直从事量化和金融工程相关的工作,同时还是以太坊基金的志愿者。
CMO&首席战略官:Garrison Yang
Garrison Yang在今年3月才正式加入IO.NET,他此前是Avalanche的战略和增长VP,毕业于加州大学圣巴巴拉分校。
COO:Tory Green
Tory Green 是 io.net 首席运营官,此前是 Hum Capital 首席运营官、Fox Mobile Group 企业发展与战略总监,毕业于斯坦福。
从IO.NET的Linkedin信息来看,团队总部位于美国纽约,在旧金山有分公司,目前团队人员规模在50人以上。
融资情况
IO.NET截至目前仅披露了一轮融资,即今年3月完成的A轮估值10亿美金融资,共募集了3000万美金,由Hack VC领投,其他参投方包括Multicoin Capital、Delphi Digital、Foresight Ventures、Animoca Brands、Continue Capital、Solana Ventures、Aptos、LongHash Ventures、OKX Ventures、Amber Group、SevenX Ventures和ArkStream Capital等。
值得一说的是,或许是因为收到了Aptos基金会的投资,原本在Solana上进行结算记账的BC8.AI项目,已经转换到了同样的高性能L1 Aptos上进行。
2.4 估值推算
根据此前创始人兼CEO Ahmad Shadid的说法,IO.NET将在4月底推出代币。
IO.NET有两个可以作为估值参考的标的项目:Render Network和Akash Network,它们都是代表性的分布式计算项目。
我们可以用两种方式推演IO.NET的市值区间:1.市销比,即:市值/收入比;2.市值/网络芯片数比。
先来看基于市销比的估值推演:

从市销比的角度来看,Akash可以作为IO.NET的估值区间的下限,而Render则作为估值的高位定价参考,其FDV区间为16.7亿~59.3亿美金。
但考虑到IO.NET项目更新,叙事更热,加上早期流通市值较小,以及目前更大的供应端规模,其FDV超过Render的可能性并不小。
再看另一个对比估值的角度,即“市芯比”。
在AI算力求大于供的市场背景下,分布式AI算力网络最重要的要素是GPU供应端的规模,因此我们可以以“市芯比”来横向对比,用“项目总市值与网络内芯片的数量之比”,来推演IO.NET可能的估值区间,供读者作为一个市值参考。
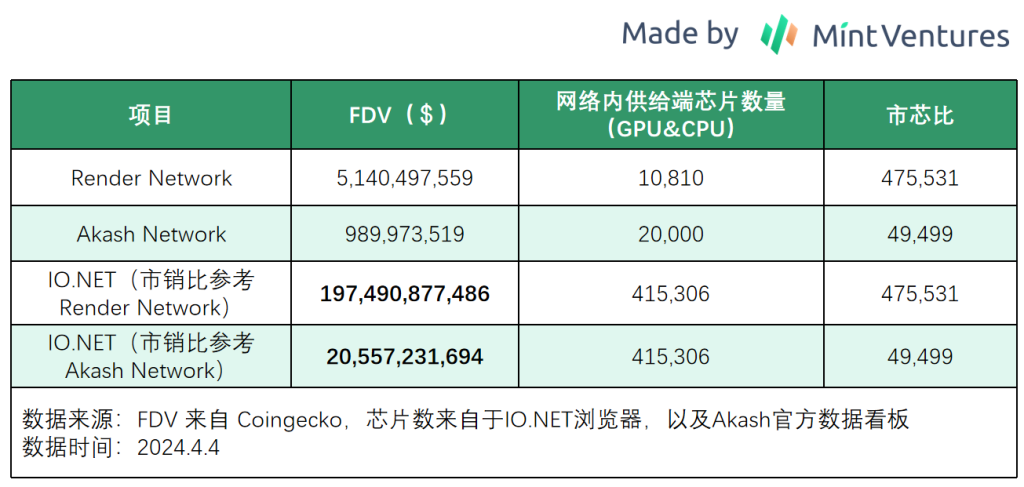
如果以市芯比来推算IO.NET的市值区间,IO.NET以Render Network的市芯比为上限,以Akash Network为下限,其FDV区间为206亿~1975亿美金。
相信再看好IO.NET项目读者,都会认为这是一个极度乐观的市值推算。
而且我们需要考虑到,目前IO.NET如此庞大的芯片在线张数,有受到空投预期以及激励活动的刺激,在项目正式上线后其供应端的实际在线数仍然需要观察。
因此总体来说,从市销比的角度进行的估值测算可能更有参考性。
IO.NET作为叠加了AI+DePIN+Solana生态三重光环的项目,其上线后的市值表现究竟如何,让我们拭目以待。
3.参考信息
-
Dephi Digital:The Real Merge
