
一、背景
- 2022年5月23日,Discord的MEE6机器人遭到攻击,致使一些 Discord 官方服务器发布了有关铸币的钓鱼网站。在Discord 里面,进 NFT 的官方 Discord,经常会有人私聊告诉你获得了白名单,附带一个 mint 链接。骗子会把头像和名称改成官方的样子,告诉你可以在几个小时内 mint,可以mint的数量限制为 1到10。大多热门项目一个白名单mint一两个不错了,这一上来就10 个还带时间限制,可以说是很有吸引力了。还有骗子会模仿项目官网做个假网站,私信给项目 Server 里的人,让他们来 mint。
- 2022年5月10日,@Serpent 发推文称 NFT 交易平台 X2Y2 在 Google 的第一个搜索结果是一个欺诈网站,该网站利用谷歌广告中的漏洞使真实网站和欺诈 URL 看起来相同,大约 100 ETH 已经被盗,而且攻击者伪造了前后几位均相同的假合约,进行联合钓鱼。
- 2022年5月6日,Opensea的官方Discord被黑客入侵,致使机器人账户在频道上发布虚假链接,谎称“Opensea与YouTube合作,点击链接制造100个限量版的mint pass NFT”。
- 2022年4月1日,流行歌手周杰伦在Instagram上透露,他的Bored Ape NFT被钓鱼网站窃取。
如果说web3.0是正在缓缓升起的一轮明日,那么钓鱼就是环绕着红日的云翳,有无数web3.0的机构和个人正在被这层云雾困扰着,在迷雾中机构平台被假冒利用,个人和用户被骗取钱财。 本文主要介绍X-explore phishing detect v1.0 工具中解决的问题。在完全未知钓鱼链接的情况下,主动嗅探出钓鱼网站的URL,并且判断其是否具有钓鱼意图。
二、X-explore phishing detect工具效果
接下来以币安和FTX交易所为例子,讲解X-explore phishing detect工具的使用效果。
2.1 币安反钓鱼
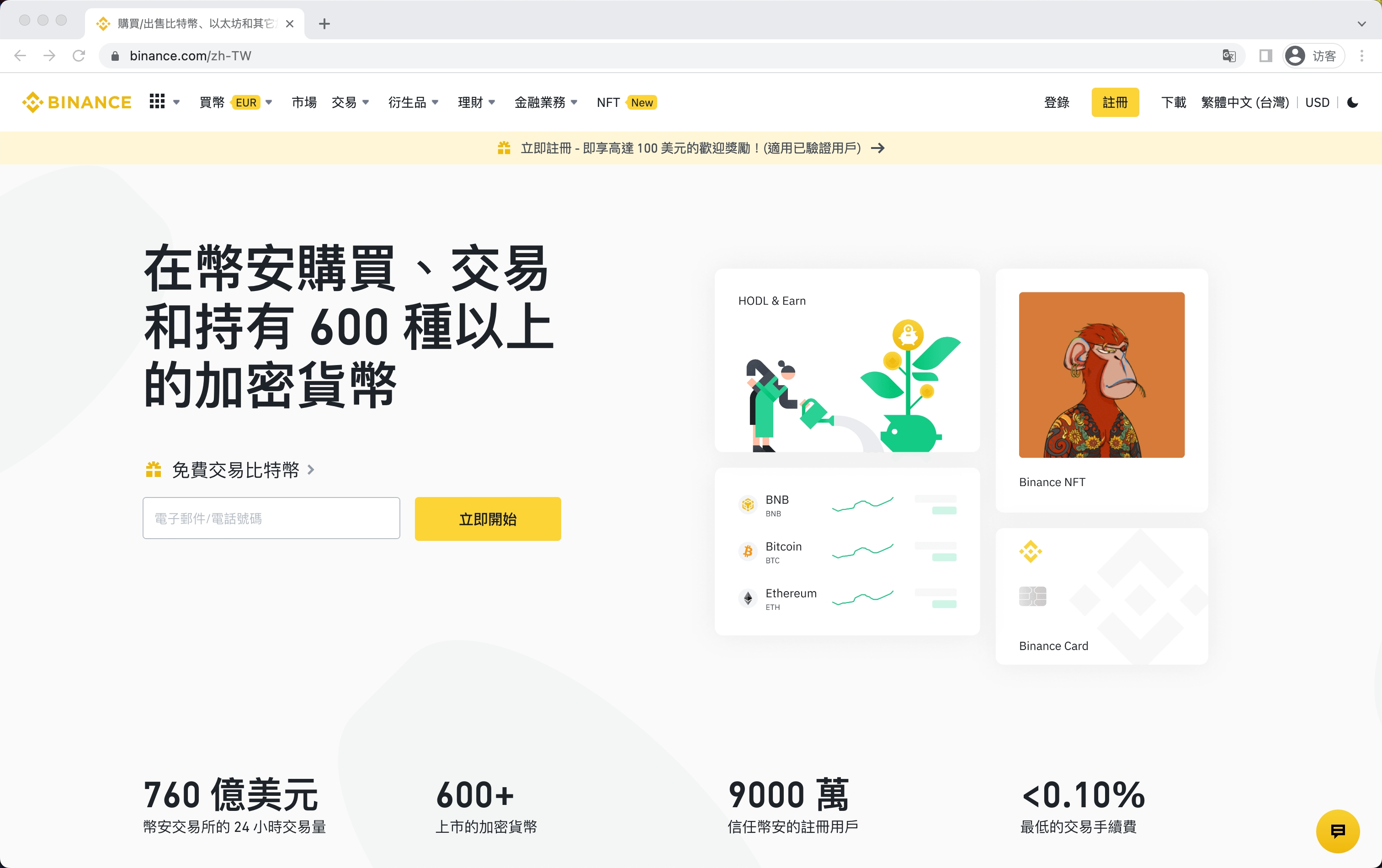
先分析一下关于币安真实官网的图片,以及真实的币安官网的相关信息,用于和钓鱼网站的对比。
- 币安的部分官方组织注册的链接:
- 观察得,币安的注册域名是“binance.com”。
- 以上这一堆网站icon都是和官网主页一致的,并且注册组织都是“AMAZON-02 ”“binance.com”。当然还有一些历史网站和“DXTL Tseung Kwan O Service”有过合作。以上为不完全统计。
- 使用的服务器包括“awselb/2.0”、“CloudFront”、“Tengine”、“ nginx”,使用最多的是使用了362次的“awselb/2.0”和453次的“ nginx”。
- 最常见的网站端口号是443,对应使用最多的是“https”协议,历史以来一共使用889次。(以上数据是币安历史以来使用过的所有网站,包含大量已经呈404状态的废弃网站)。
- 官方注册网站使用的(或者使用过的)部分地区的部分IP地址:
- 美国:13.224.167.56、54.192.18.103、13.225.89.6等
- 日本:13.114.190.40、54.178.137.203等
- 还有一些像钓鱼,但确实是币安官方的链接:
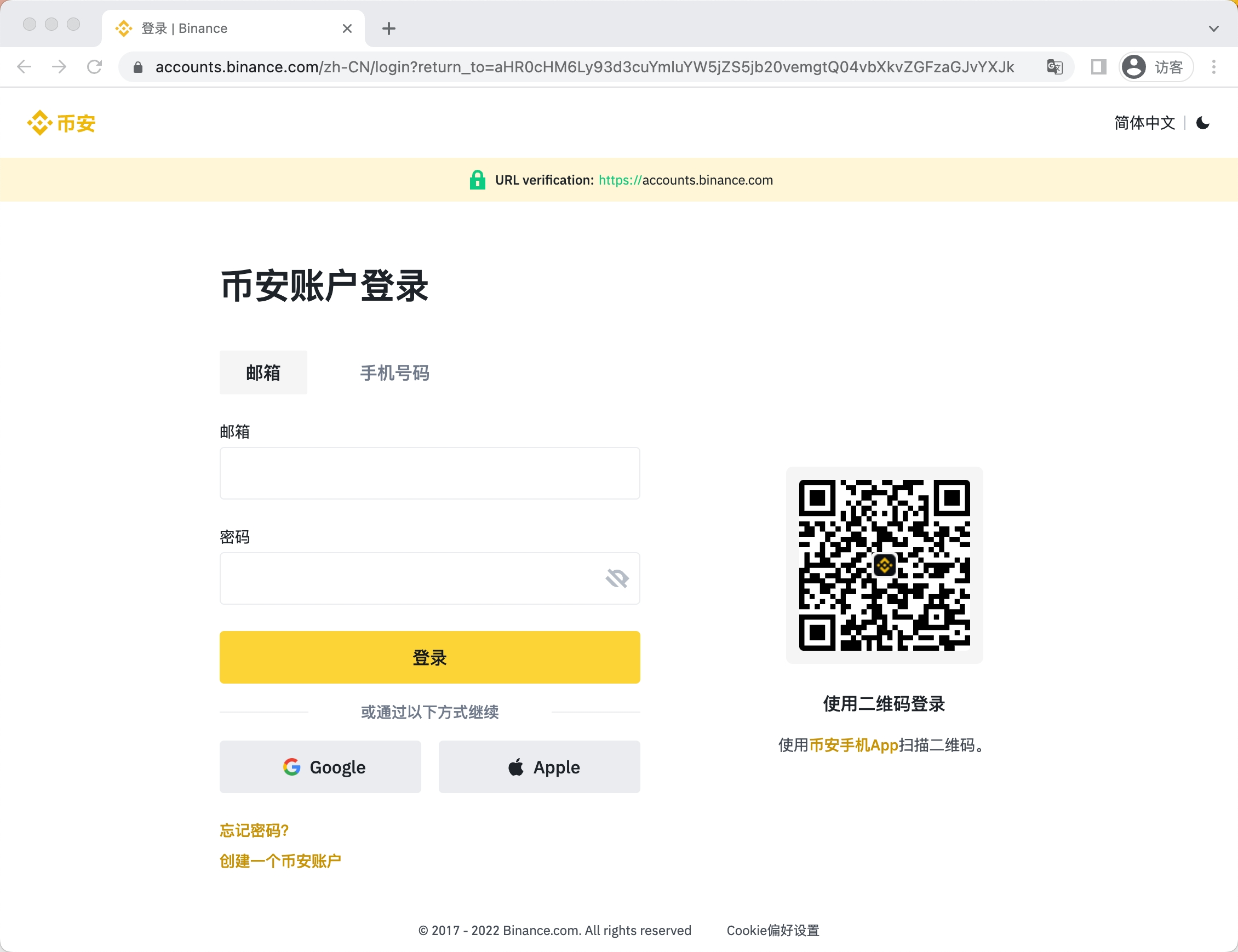
虽然还可以看到更多信息,但是作为验证真伪的基础信息,以上这些已经够了。以下为官网首页的截图,以及登录界面的截图。
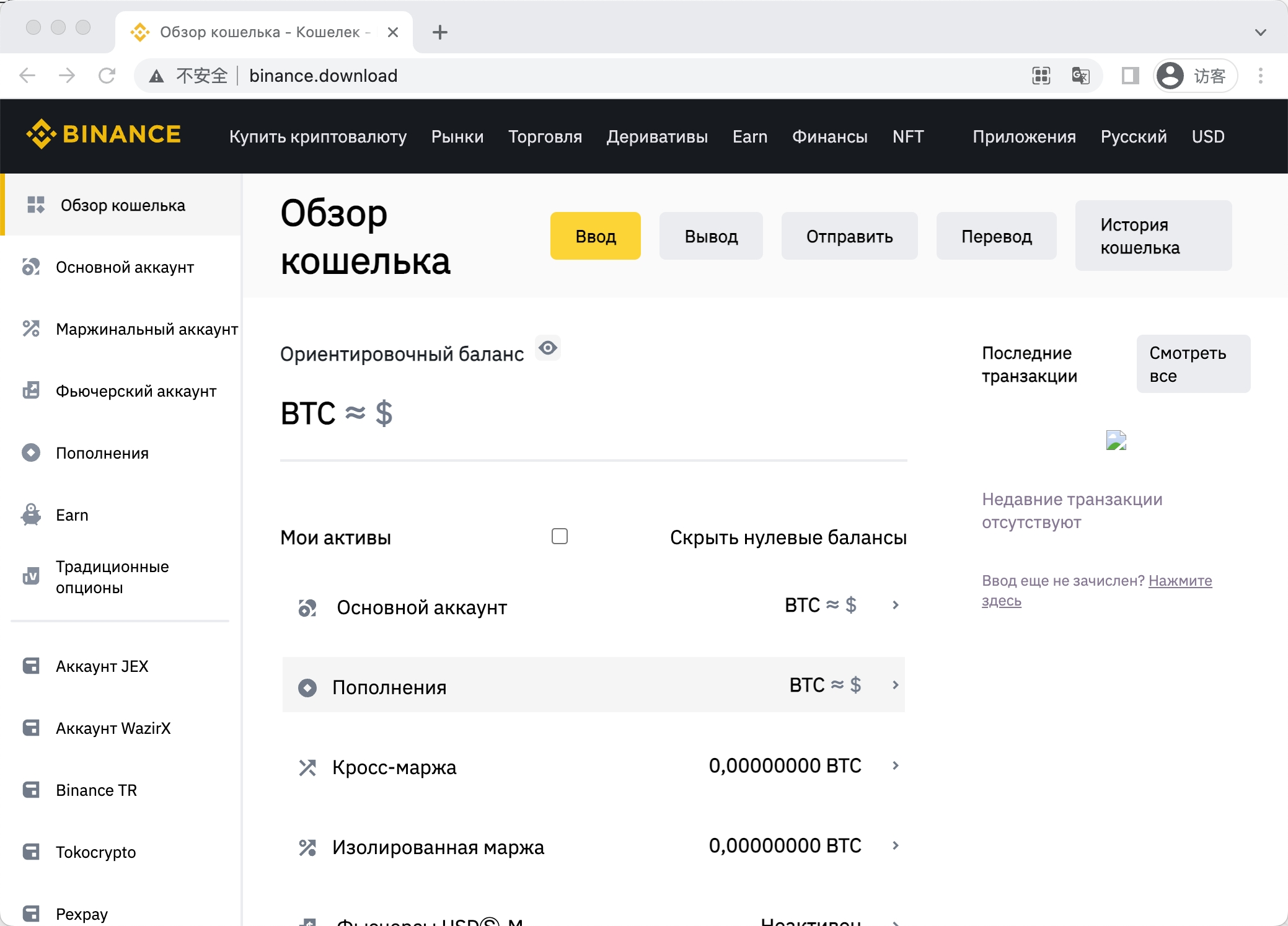
2.1.1 模块一 —— 可疑URL拼凑法
Example 1
同一个模块检测出来的另一个很可疑的网站。
2.1.2 模块二 —— 基于特征识别主动探测法
通过查询模拟传统黑客,基于某些特征值定向查找钓鱼网站的思路。
Example 1
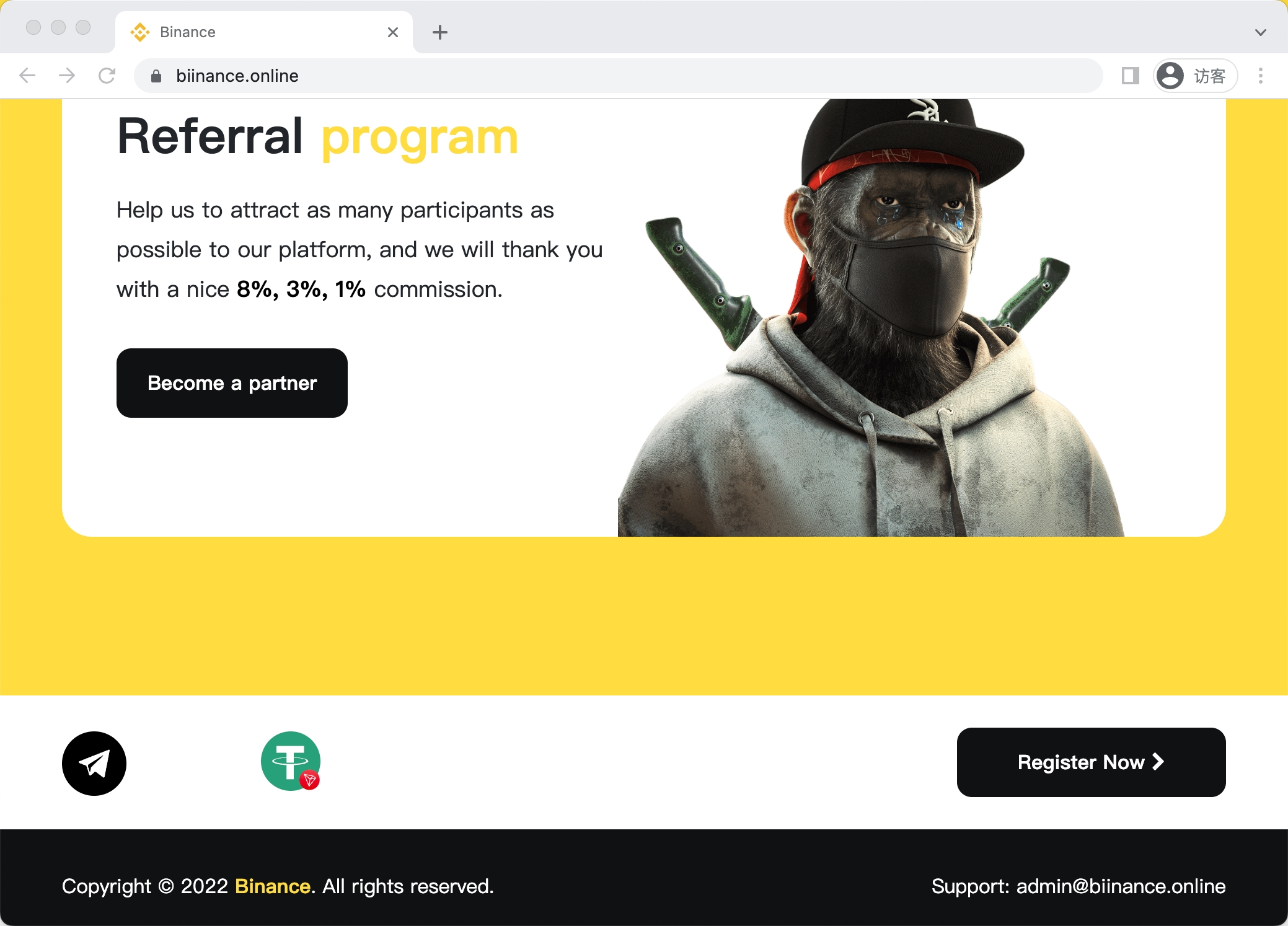
抛开钓鱼不谈,这个网站设计真的挺好看的,也很聪明,模仿的是官网的风格色调然后 照抄了官网的icon,很像艺术生版本的官网。和这个网站长得很像的,目测是测试网站的还有 下面两个:
2.1.3 模块三 —— 基于蜜罐全网钓鱼链接进行筛选判断法
Example 1
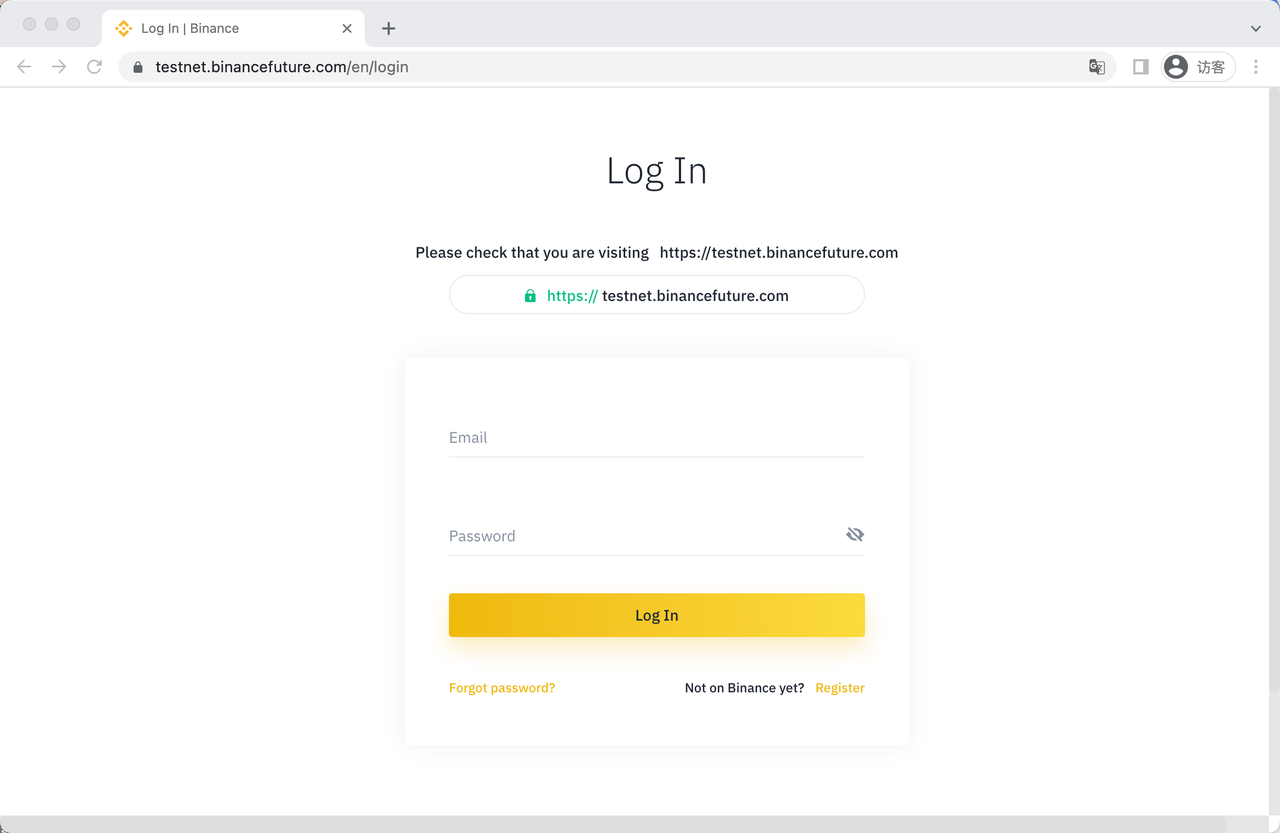
2.1.4 官方验证通道
最后放一个币安的官方验证网站,如果遇到不确定的网站或者是电子邮件地址、电话号码、微信 ID、Twitter 帐户或 Telegram ID都可以在这里测试一下。
2.2 OKX反钓鱼
2.2.1 模块一 —— 可疑URL拼凑法
Example 1
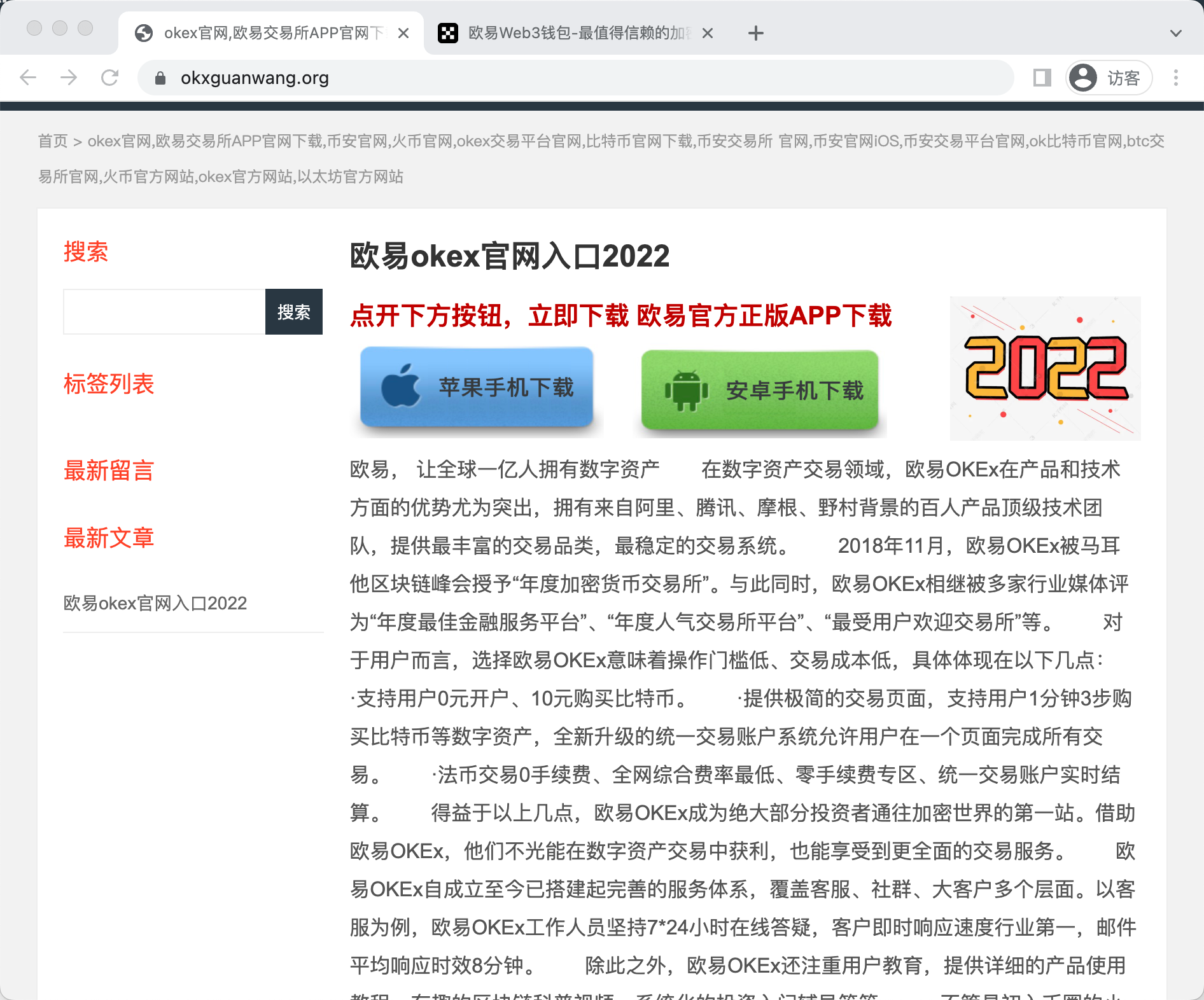
不得不说,这个钓鱼网站从域名的伪造到页面的伪造都好像不太聪明的样子……
2.2.2 模块二 —— 基于特征识别主动探测法
Example 1
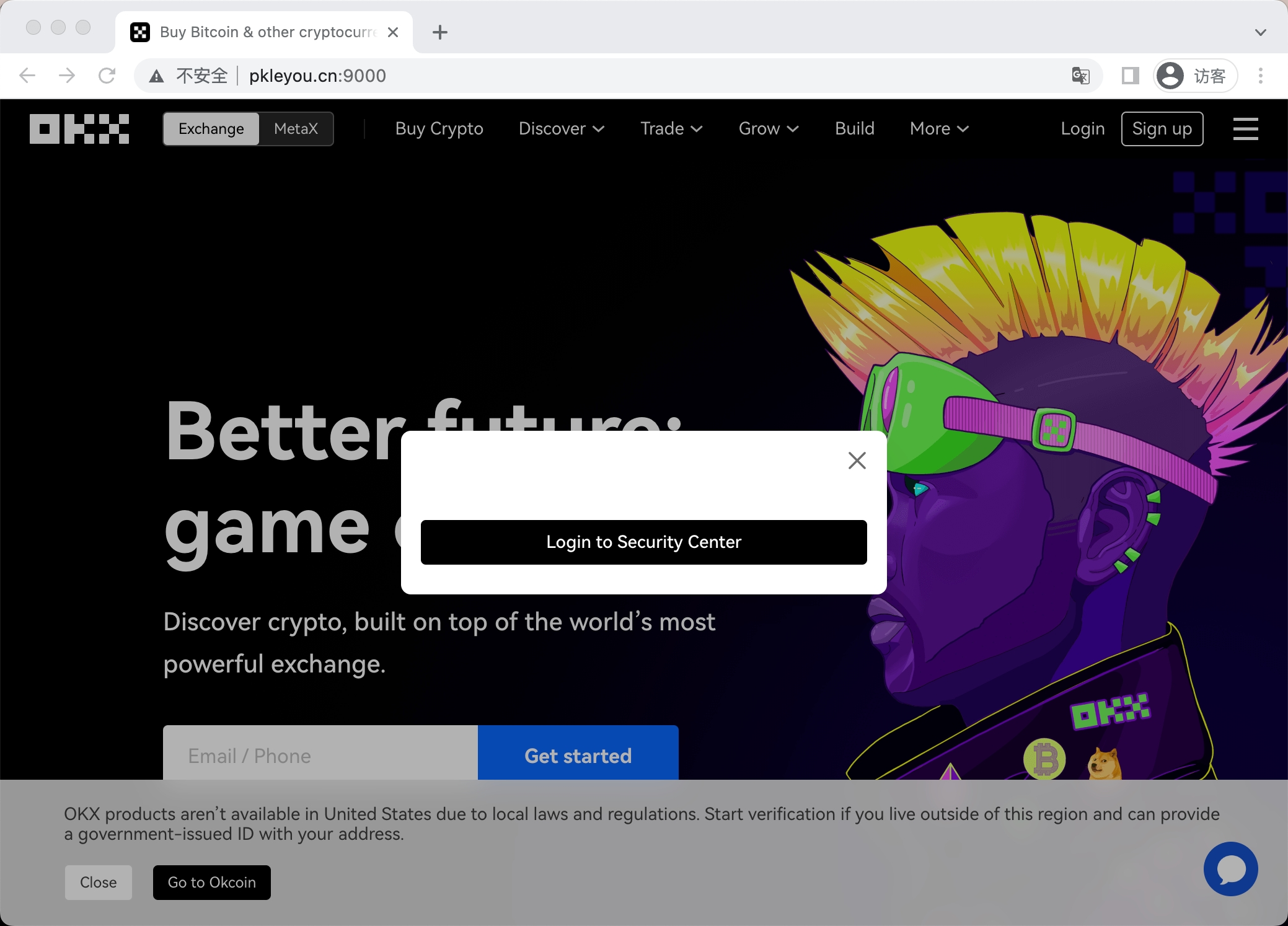
又是一个页面模仿得很漂亮的网站。
Example 2
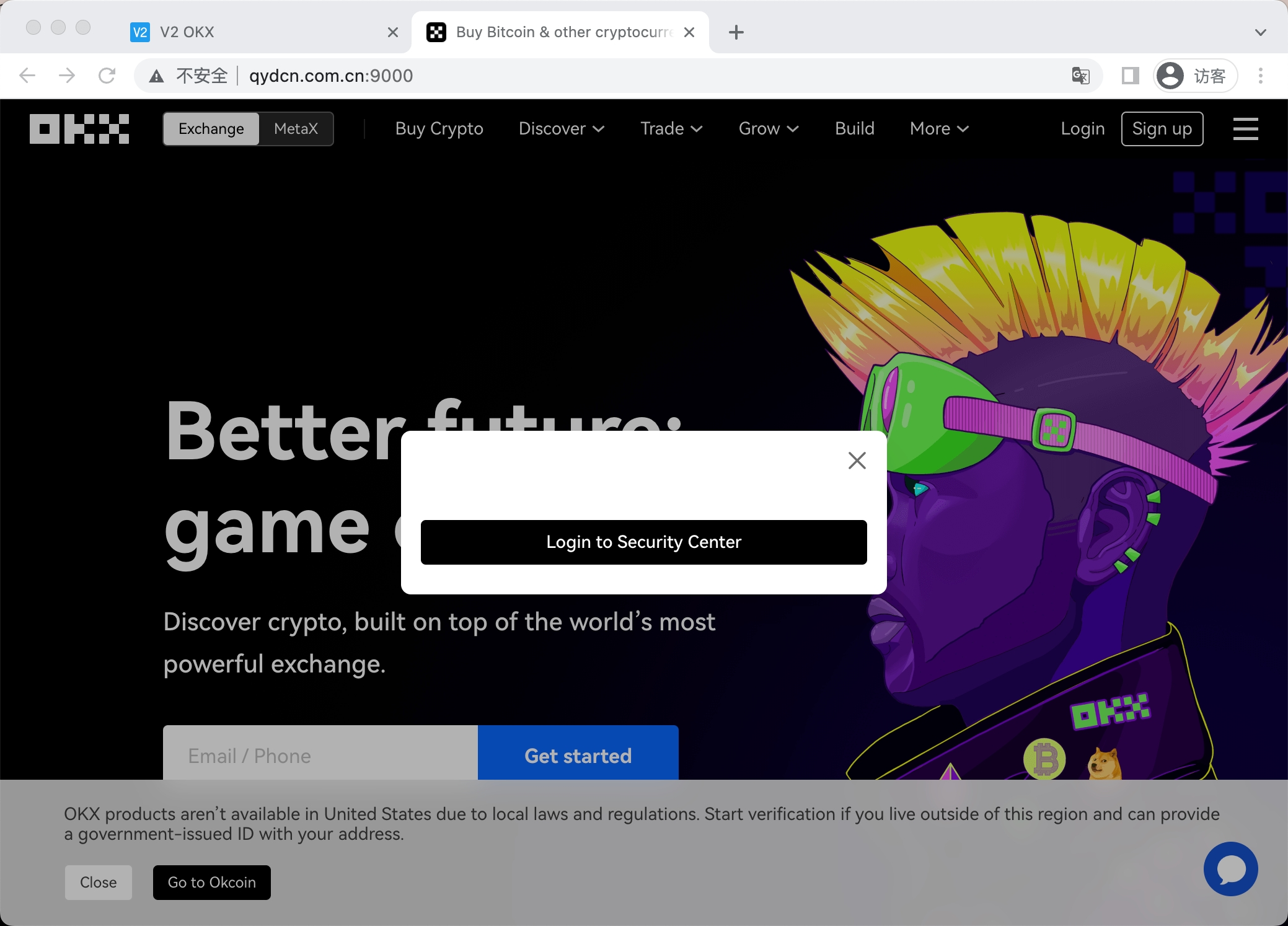
Example 3
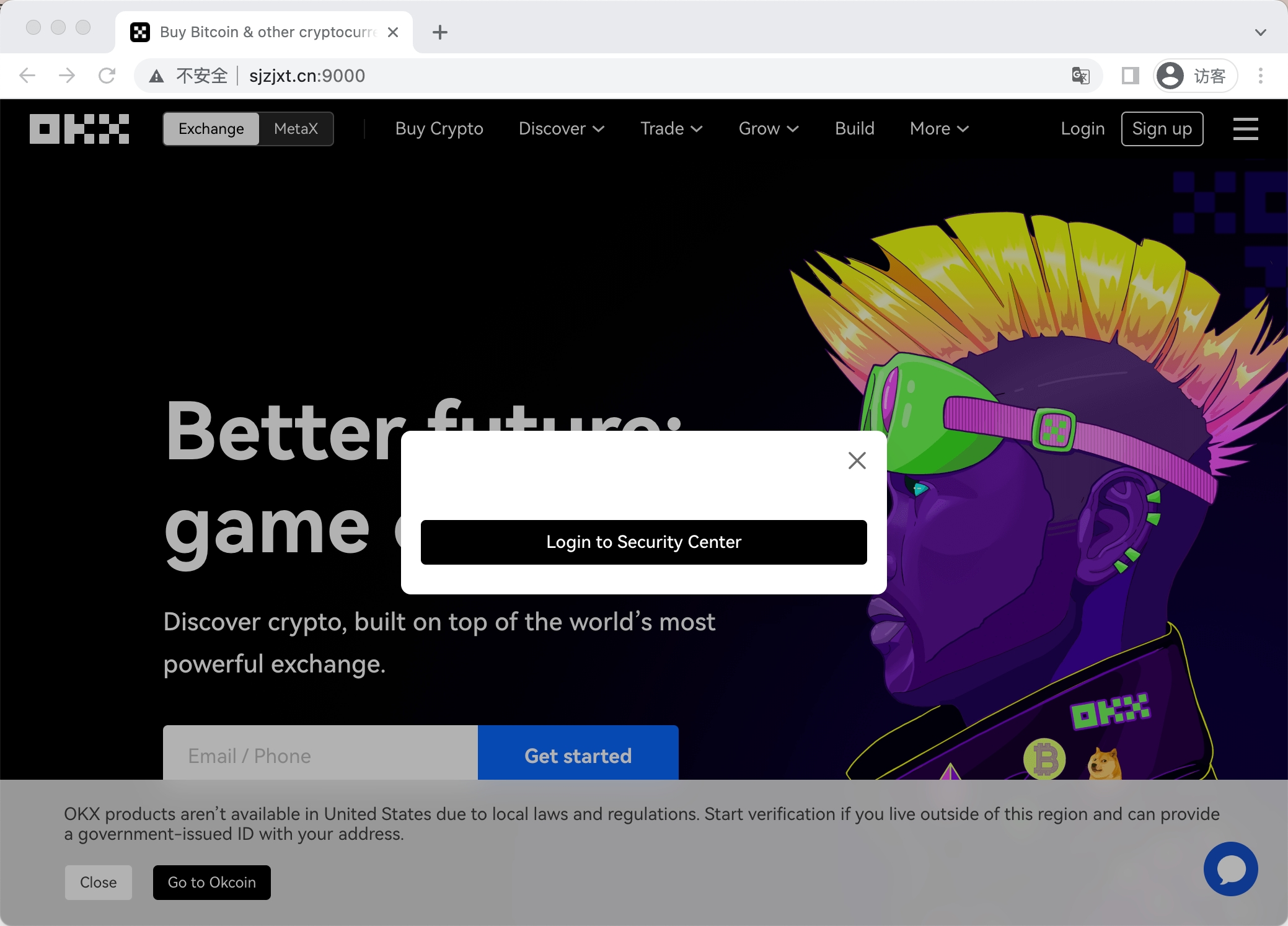
2.2.3 模块三 —— 基于蜜罐全网钓鱼链接进行筛选判断法
Example 1
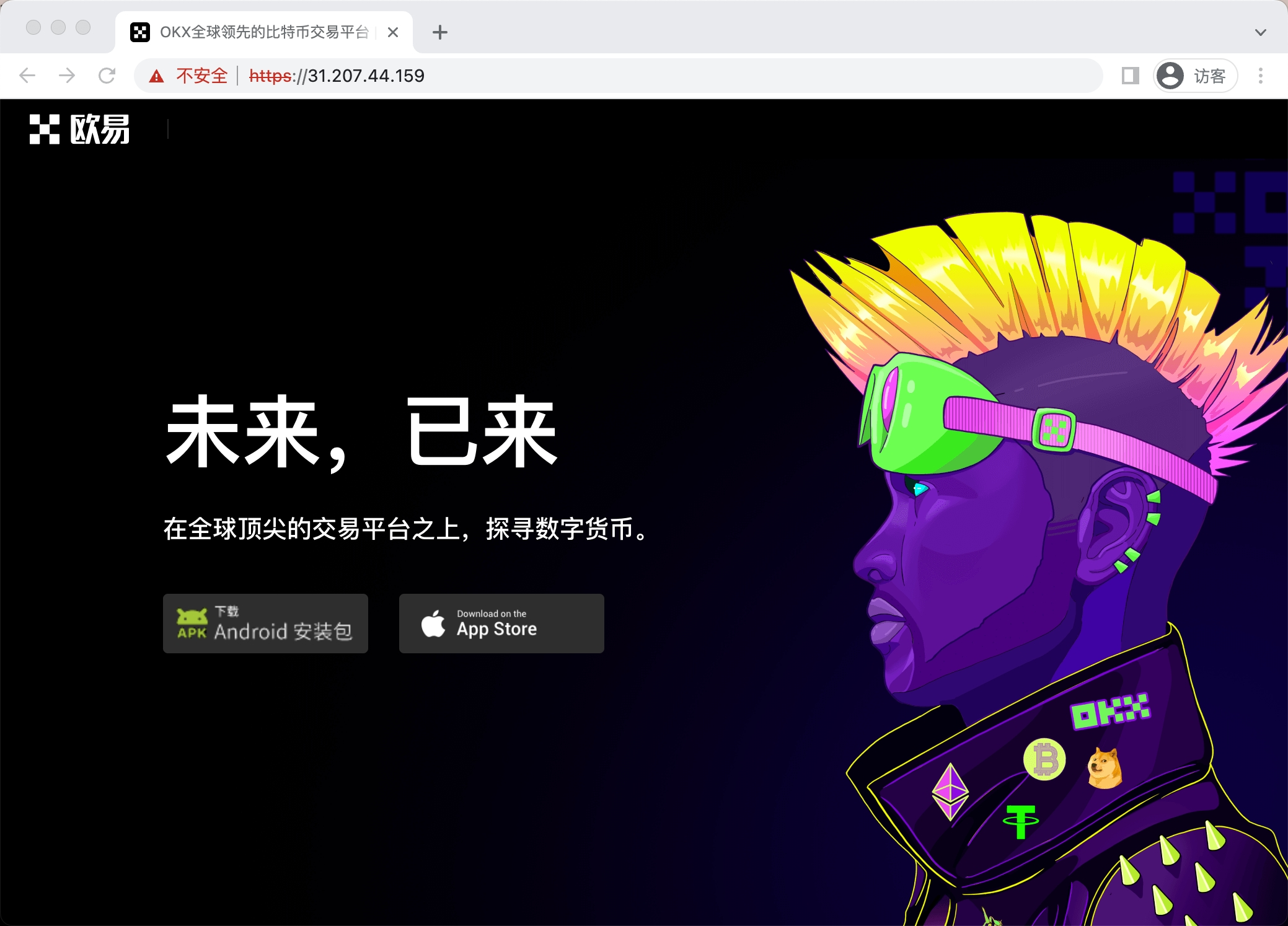
2.2.4 话题补充
在反钓鱼过程中跑出来很多自称官方下载的页面。在我眼里,这种自称官方下载的链接,都挺可疑的,不过具体有没有问题有待验证。
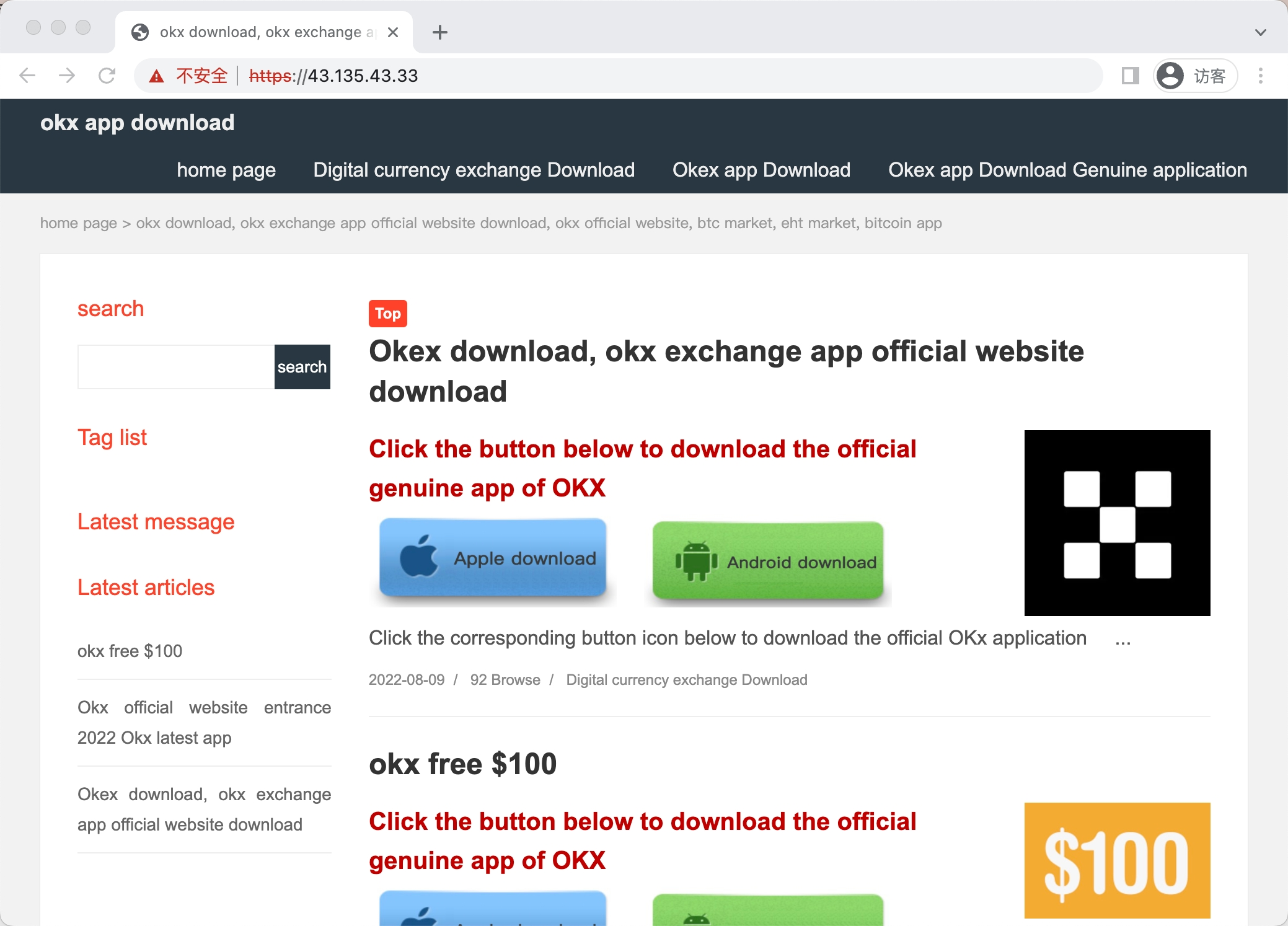
2.2.5 官方验证通道
2.3 coinbase
2.3.1 模块一 —— 可疑URL拼凑法
Example 1
2.3.2 模块二 —— 基于特征识别主动探测法
Example 1
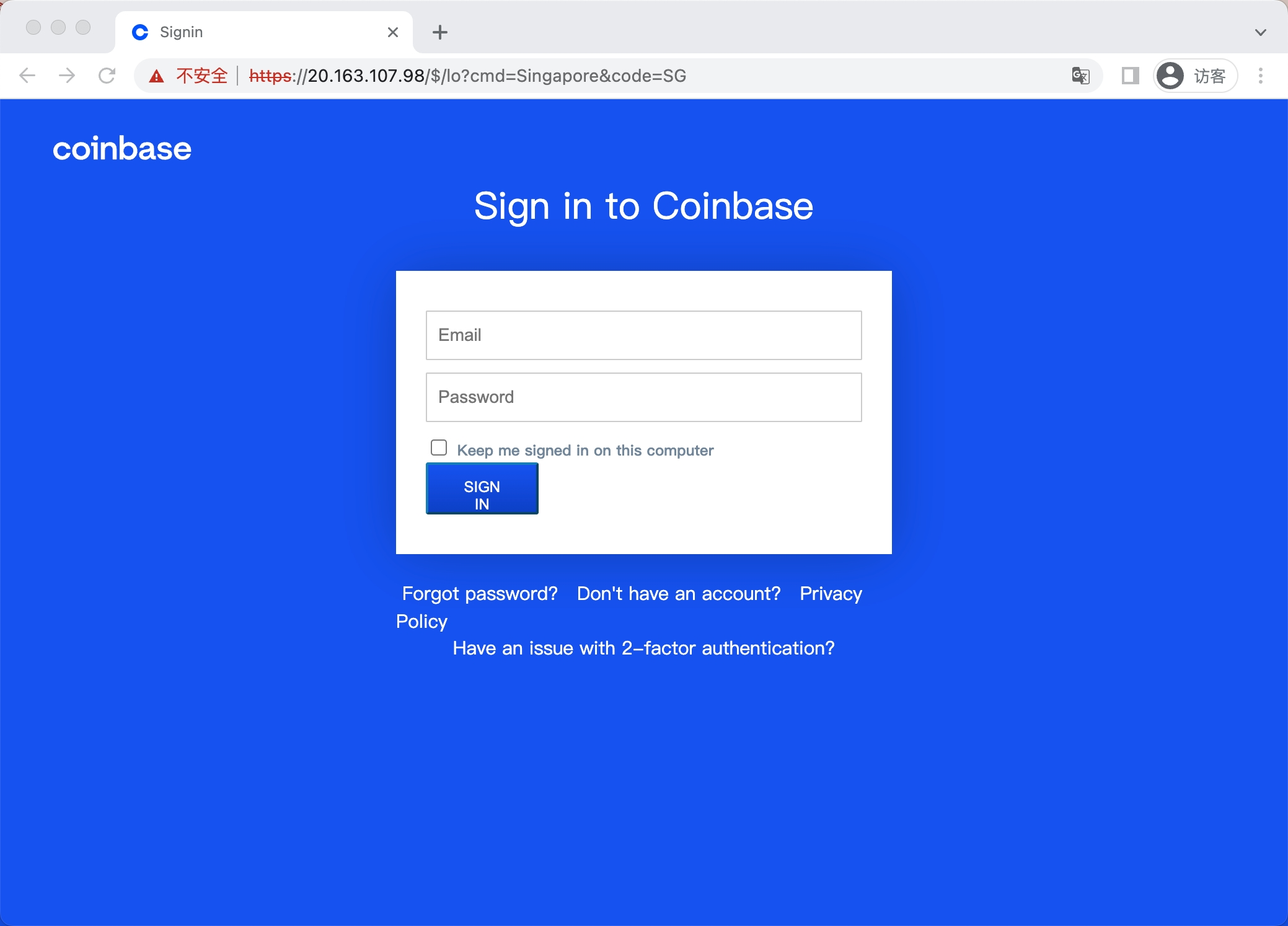
2.3.3 模块三 —— 基于蜜罐全网钓鱼链接进行筛选判断法
Example 1
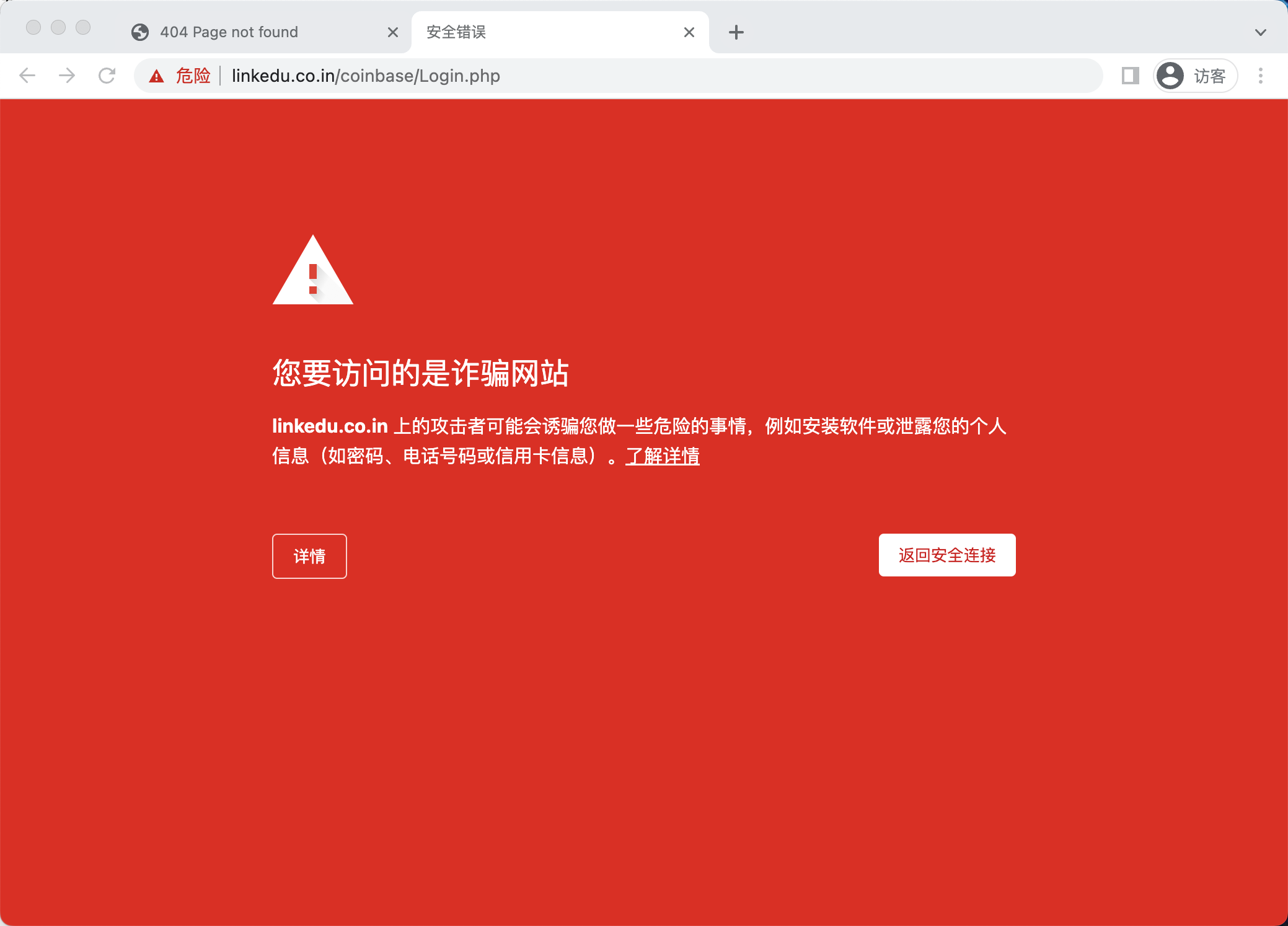
2.4 kucoin
2.4.1 模块一 —— 可疑URL拼凑法
Example 1

与这个网站长得非常相似的还有其他几个网站,包括https://103.72.147.251/。
2.4.2 模块二 —— 基于特征识别主动探测法
Example 1
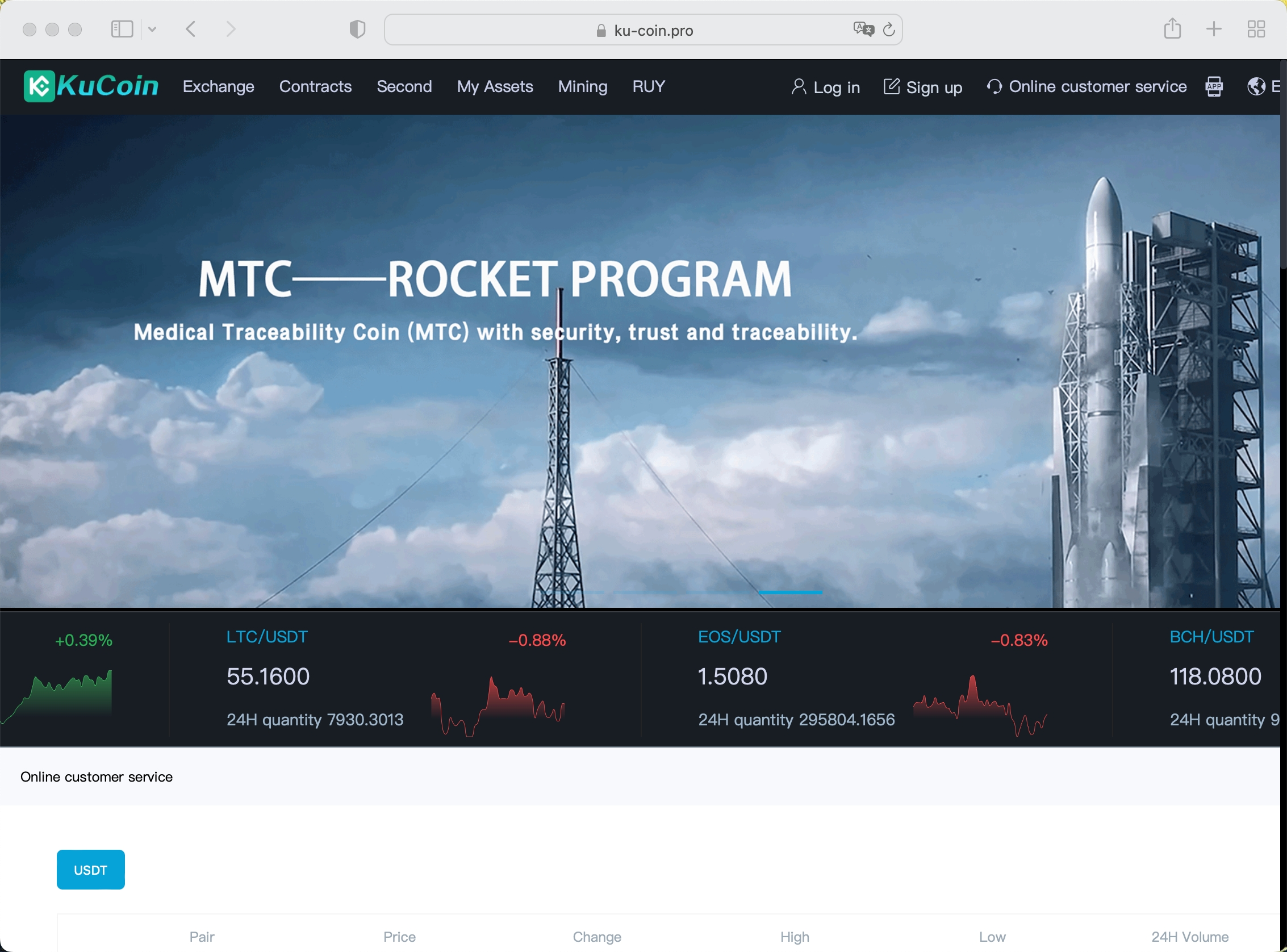
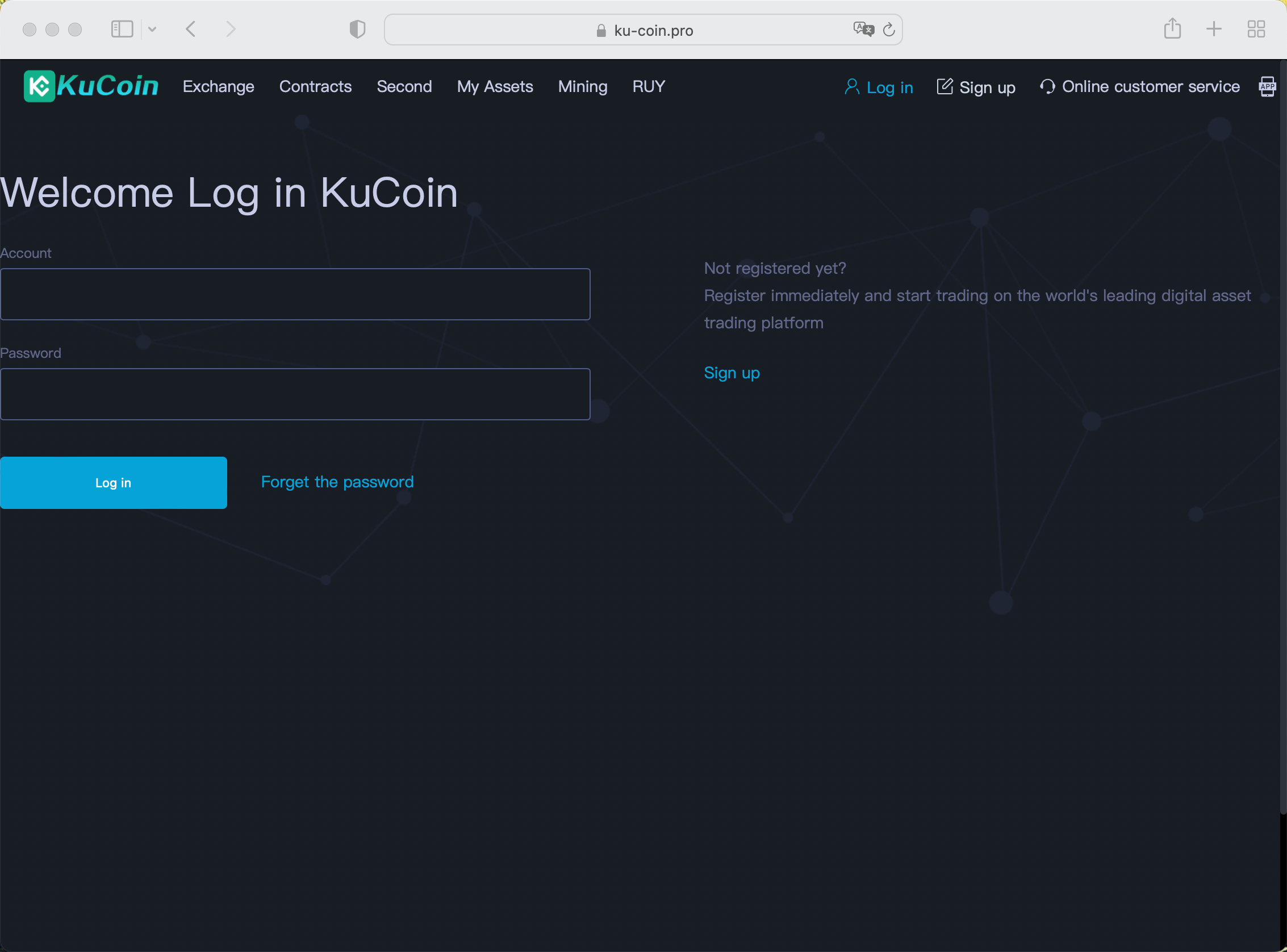
Example 2
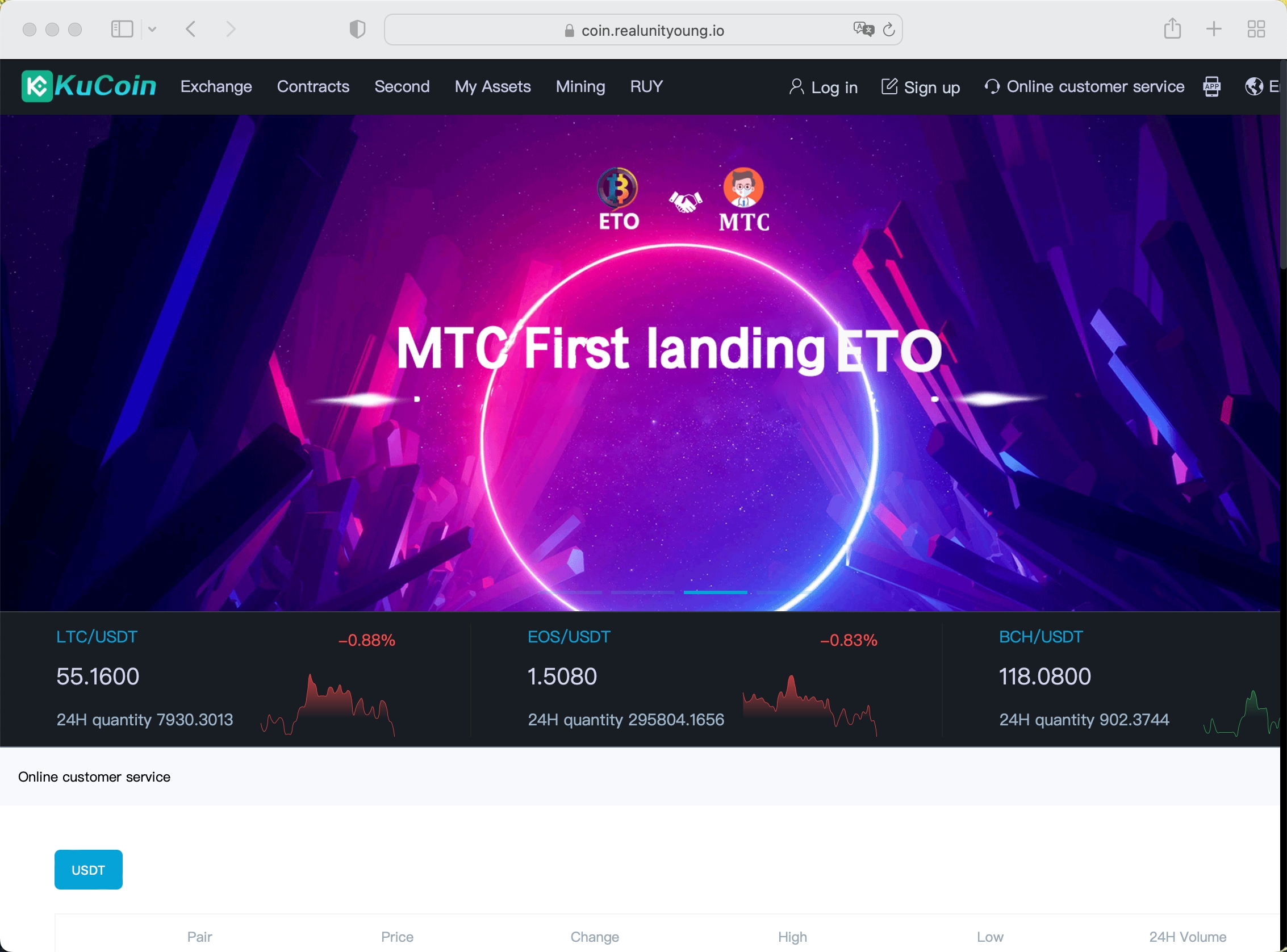
Example 3
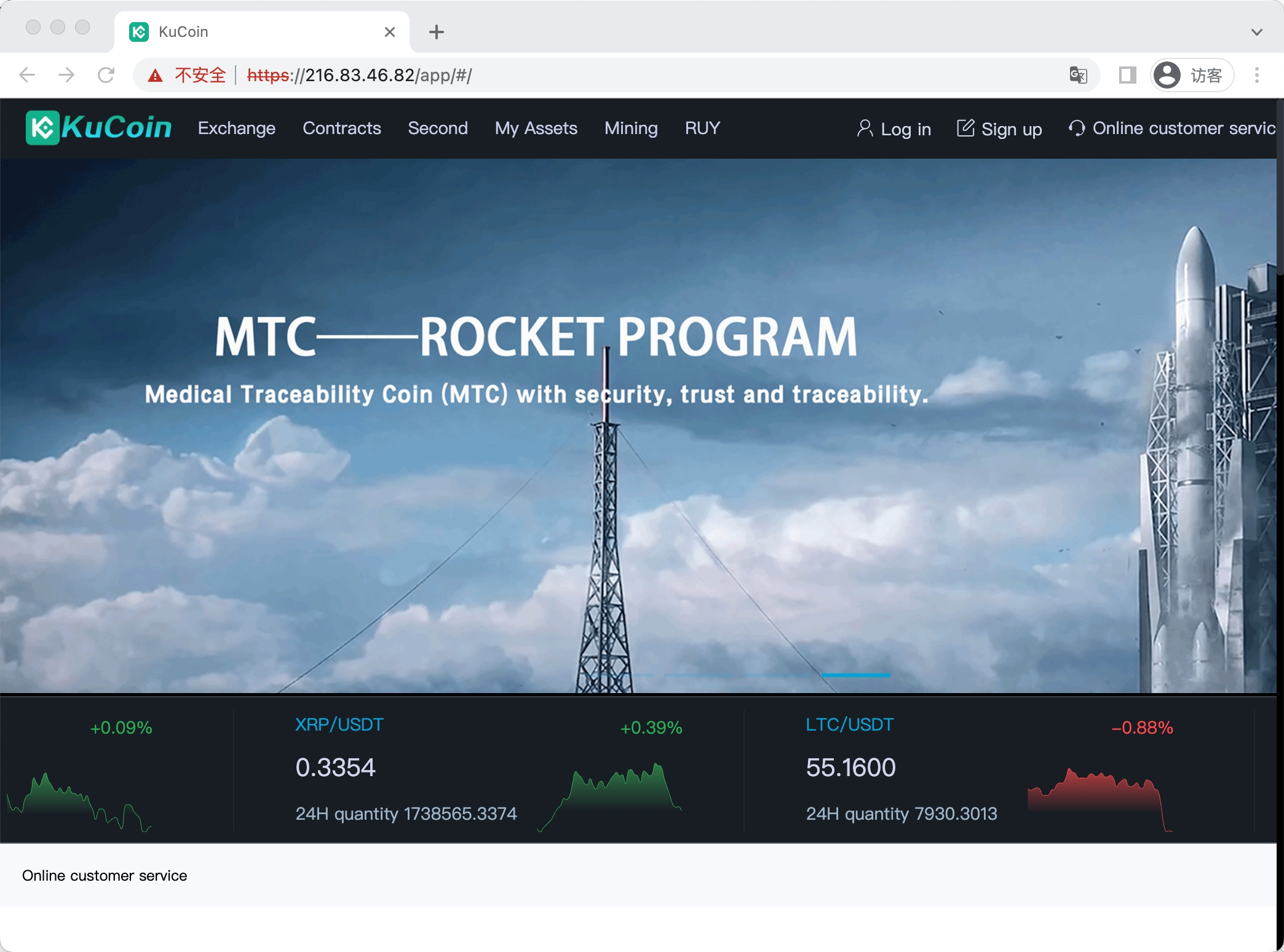
2.4.3 模块三 —— 基于蜜罐全网钓鱼链接进行筛选判断法
Example 1
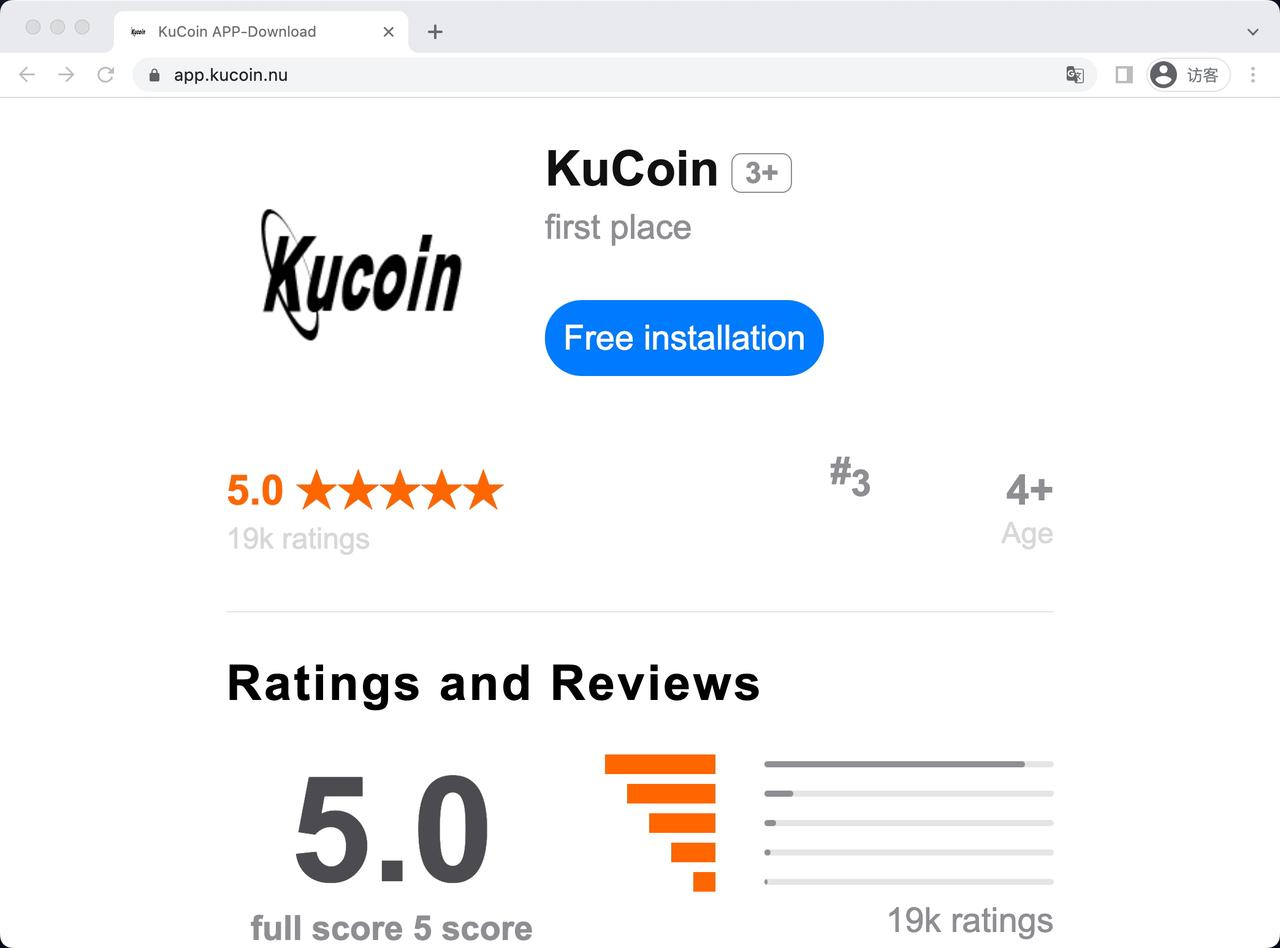
Example 2
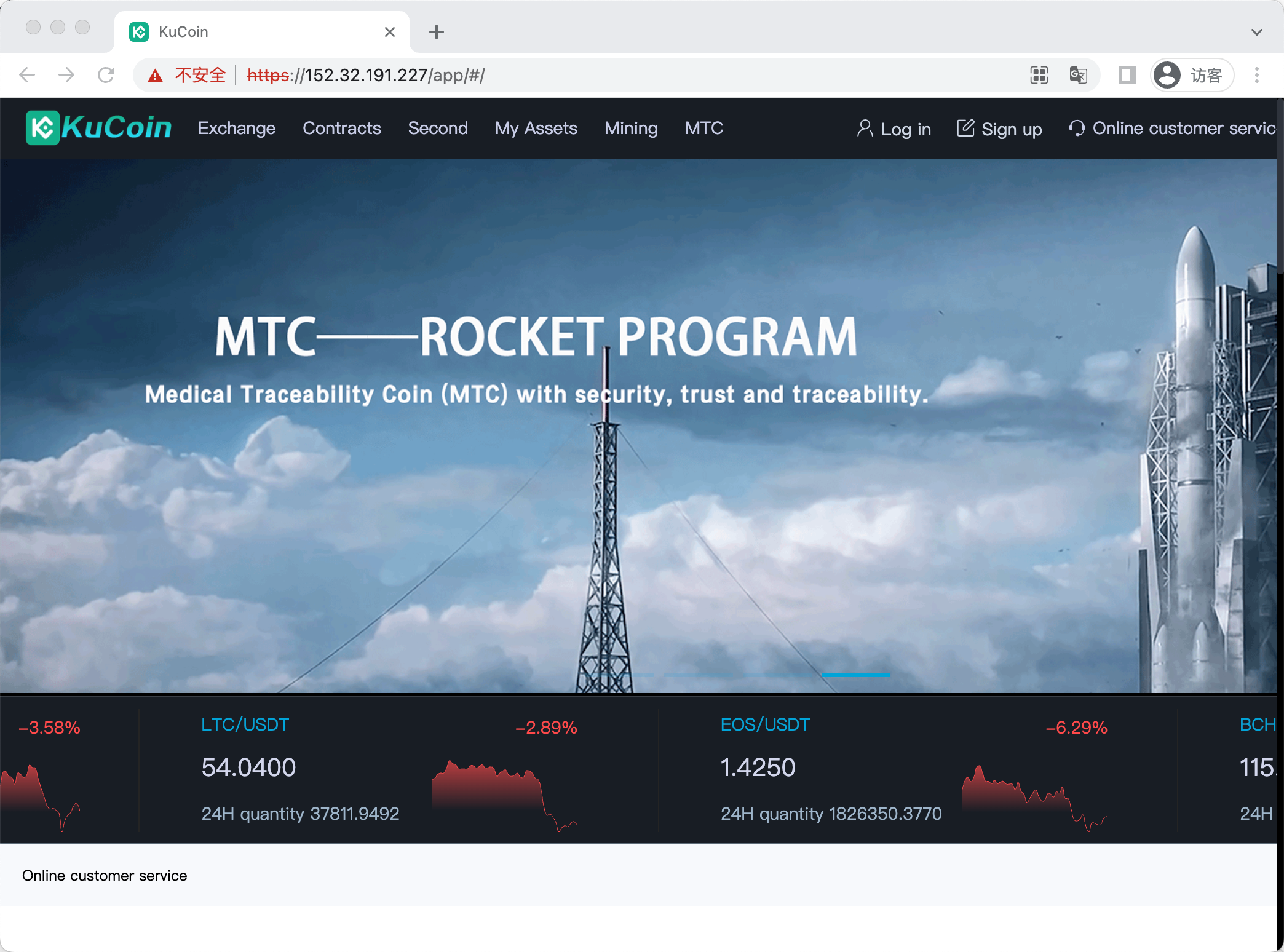
2.5 FTX
2.5.1 模块一 —— 可疑URL拼凑法
Example 1
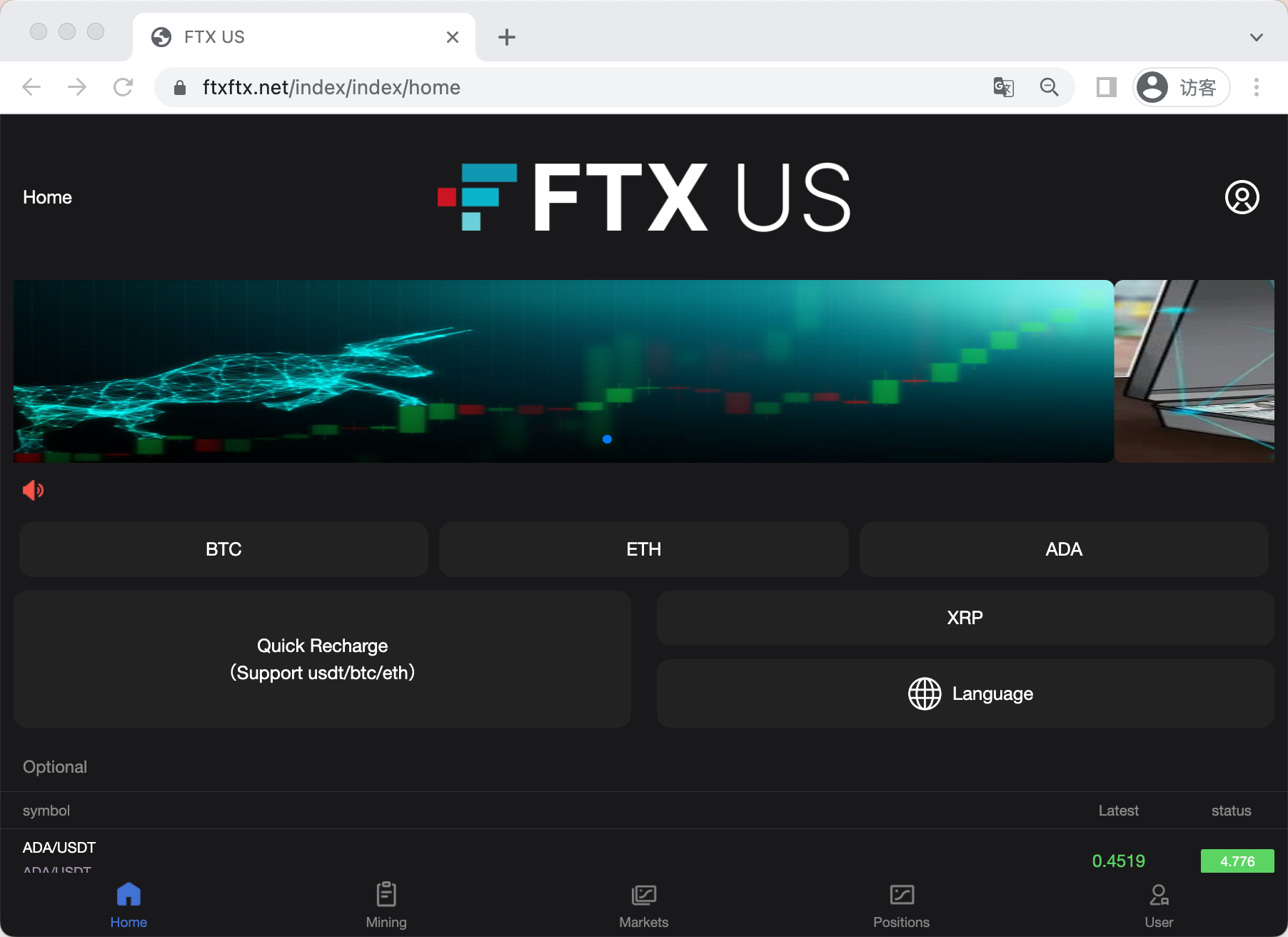
2.5.2 模块二 —— 基于特征识别主动探测法
Example 1
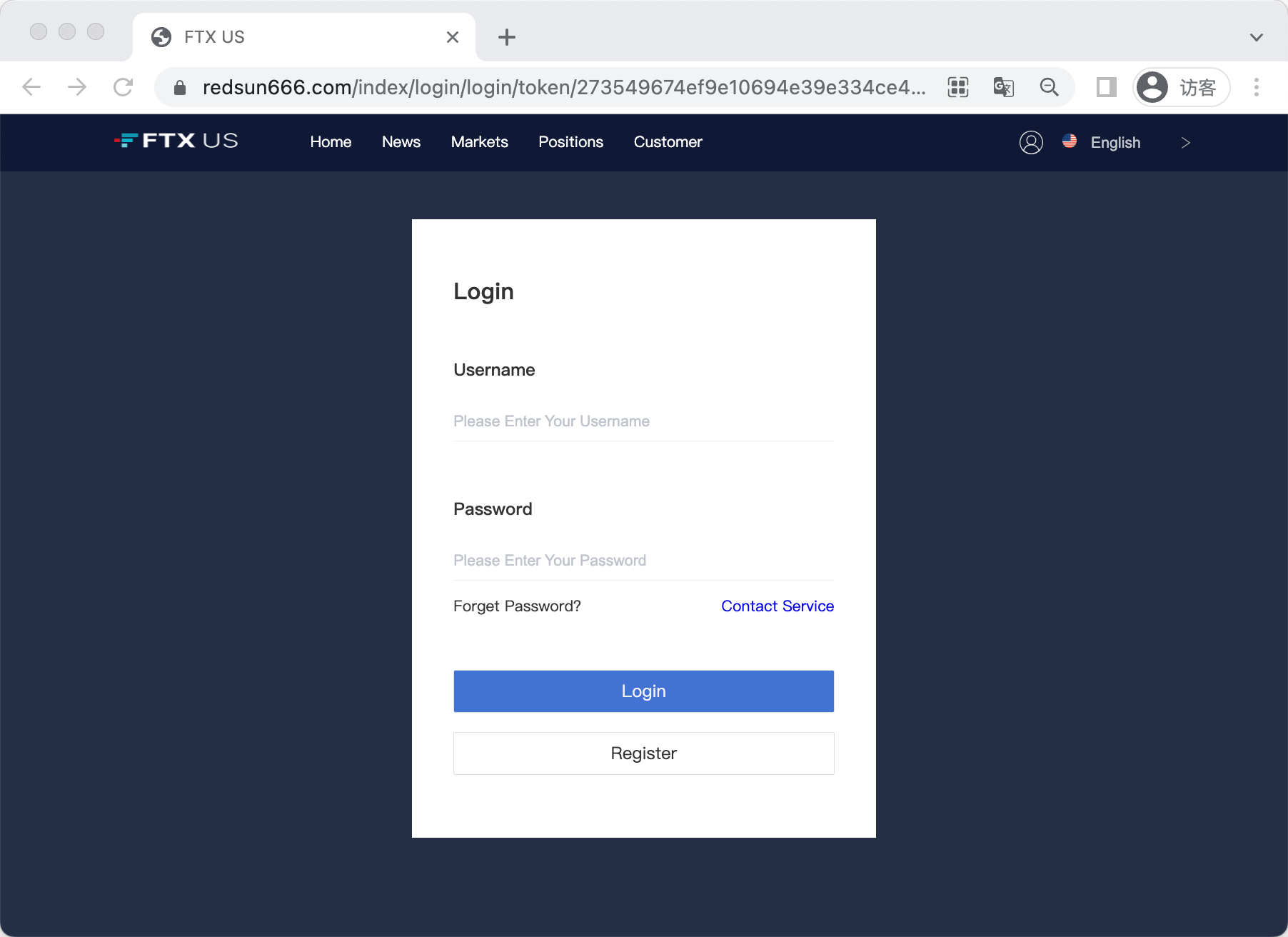
2.5.3 模块三 —— 基于蜜罐全网钓鱼链接进行筛选判断法
Example 1
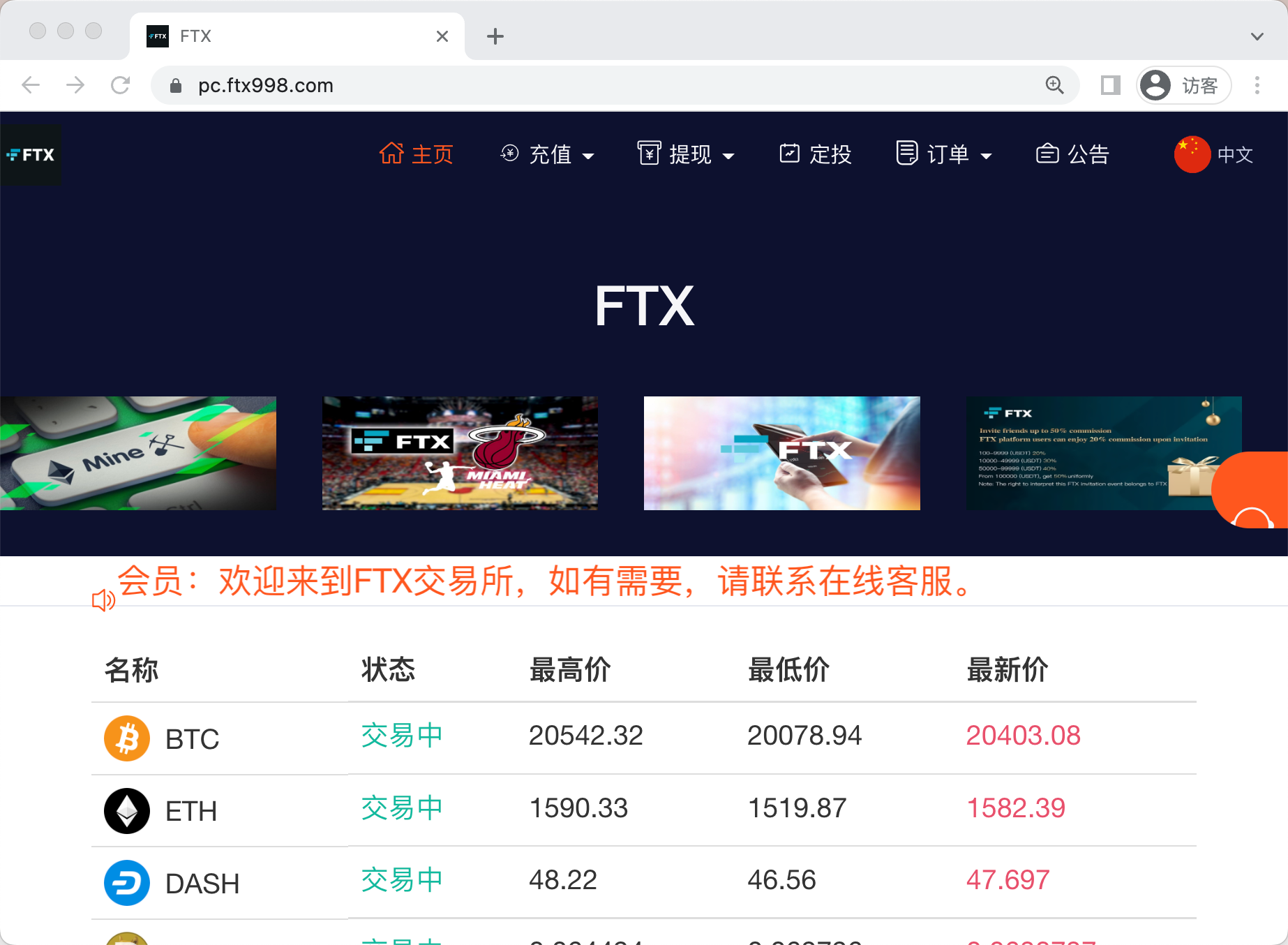
作为最后一个例子,我这边多列举一点工具探测出来的可疑的钓鱼网站,但是就不展开放图啦。
FTX的疑似钓鱼(包括但是不限于以下这些)
https://xdtyhgrf.com/index/index/home
https://ftx678.com/index/index/home
https://ftxau7.com/index/index/home
https://auftx555.com/index/index/home
三、与其他工具效果比较
3.1 Kali的URL Crazy工具
可以生成一堆域名,主要是简单字符的拼接和后缀的替换为主,但是大部分都并不存活,或者说并不是钓鱼链接。
3.2 Evil URL工具
只支持西里尔字母模仿英文字母的情况,没有其他的变种形式。并且其中模块对于whois的查询较为粗糙,只确认了是否曾经注册过,但是不会对注册时间是否过期进行判断。里面的request模块没有进行状态码的判断。
3.3 X-explore与以上两者的效果比较
- 支持西里尔字母模仿英文字母的情况
- 支持字符的常见规则的变种,也支持后缀的替换
- 支持以上规则的混合变种
- 加入了专家经验的规则,手动挖掘并且分析了大量web3.0历史钓鱼网站的形式,最终总结出一些专家经验
- 加入了传统web2.0的钓鱼网站手动挖掘方式的自动化规则,包括查找host、title、domain中包含被钓鱼的网站的关键字的规则等,引用了第三方API和钓鱼网站库作为结果的补充
- 对于挖掘出来的数据进行了初步结果的验证,减少人工审核的压力
四、底层原理——面向问题本身,而非面向生成字典
X-explore根据规则模块化生成域名字典,对字典进行检测。规则分为基础拼接规则和递归拼接规则两部分,还有模拟传统黑客纯手工挖掘钓鱼网站的模块,以及基于蜜罐的全网钓鱼网站捕获模块。
相比起URL Crazy和Evil URL这种面向于生成批量域名字典的工具,X-explore更面向解决钓鱼网站这个问题本身,不是为了生成域名而生成域名。因此,X-explore phishing detect除了拼接规律,还会尝试其他挖掘钓鱼网站的方法,加入了传统黑客的挖掘思路的自动化advanced模块,而且还加入了强大的钓鱼网站是否存活是否恶意的验证逻辑。
4.1 模块一 —— 可疑URL拼凑法
4.1.1 基础规则介绍
-
unicode西里尔字母假冒英文字母
西里尔小写字母A和英文小写字母A等,一些肉眼无法判断的一些不同语种相互替代的字母。
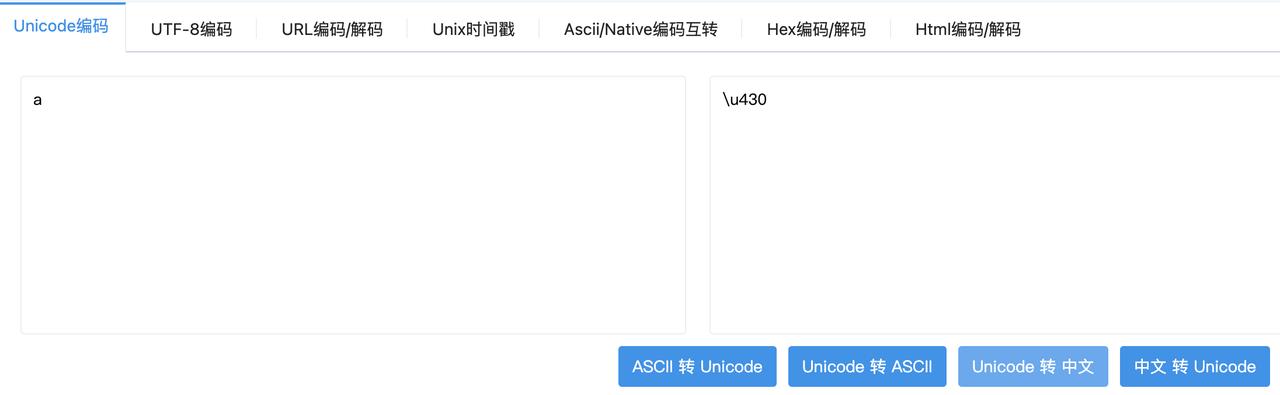
2. 字符遗漏 遗漏域名的一个字母而造成。
例如,[www.goole.com](http://www.goole.com) 和 [www.gogle.com](http://www.gogle.com)
3. 字符重复 重复域名的一个字母而产生。
例如,[www.ggoogle.com](http://www.ggoogle.com) 和 [www.gooogle.com](http://www.gooogle.com)
4. 相邻字符交换 交换域名中相邻字母的顺序。
例如,[www.googel.com](http://www.googel.com) 和 [www.ogogle.com](http://www.ogogle.com)
5. 相邻字符替换
将域名的某一个字母替换为键盘上紧邻的左右字母。例如,[www.googke.com](http://www.googke.com) 和 [www.goohle.com](http://www.goohle.com)
6. Missing Dot
域名中点缺失,任何一个点,或多个不同的点缺失的情况都考虑在内。例如,[translate.google.cn变成translategoogle.cn](http://translate.google.xn--cntranslategoogle-4r72a998q.cn)
7. 去除破折号 这些拼写错误是通过从域名中省略破折号而产生的。
例如,[www.domain-name.com](http://www.domain-name.com) 变为 [www.domainname.com](http://www.domainname.com)
8. 单数或复数
例如,[www.google.com](http://www.google.com) 变为 [www.googles.com](http://www.googles.com),[www.games.co.nz](http://www.games.co.nz) 变为 [www.game.co.nz](http://www.game.co.nz),又或者是es。
9. 元音交换 交换域名内的一个元音或者全部元音,或者全部除了第一个字符以外的元音。
例如,[www.google.com](http://www.google.com) 变为 [www.gaagle.com](http://www.gaagle.com)。
10. 同音
例如,[www.base.com](http://www.base.com) 变为 [www.bass.com](http://www.bass.com),[比如www.chain.com](http://xn--www-eo8er22f.chain.com) 变成 [www.train.com](http://www.train.com)。
11. 同形文字
一个或多个看起来与另一个字符相似但不同的字符称为同形文字。例如,小写 l 看起来与数字 one 相似,例如 l 与 1。例如,[google.com](http://google.com) 变为 [goog1e.com](http://goog1e.com)。
12. 顶级域名错误
例如,[www.trademe.co.nz](http://www.trademe.co.nz) 变为 [www.trademe.ac.nz](http://www.trademe.ac.nz) 和 [www.trademe.iwi.nz](http://www.trademe.iwi.nz)
13. 前后缀带一些常见数字
例如,多了一个1,11,111。
14. 专家经验:
将出现次数最多的一个字母添加一次到域名末尾
看起来合理的单词前后缀 -app,-h5,-my,-logins 或者 app-,h5-,my-,login- global、vietnam、vtn、cbr、b 、web、search的拼接;home,index
知名搜索引擎的site或者sites以及带“-”前后缀 google、bing、yahoo、Baidu、Ask、Aol、DuckDuckGo、WolframAlpha、Yandex、WebCrawler 与site或者sites与-的拼接
国家缩写和完整国家名字去空格与简化板国家名字前后缀
覆盖http https协议
以上为部分规则,由于篇幅问题剩下的规则不做介绍。
4.1.2 基于基础拼接规则的多规则交叉拼接
对于顶级域名的单一变化,或者是非顶级域名的单独变化都不足以涵盖大部分的可以规则,根据历史钓鱼网站的手动分析,也确实证实了多规则的交叉实现的必要性。
比如上述例子中:
- https://www.binance.charity/,就是根据单一规则改变了后缀得到的。
- http://m.kucoins.link/,这个网址要被拼凑出来需要同时使用单复数变形的规则和改变后缀的规则。
- https://www.okxguanwang.org/,是通过专家经验分析出来的高频出现的钓鱼词汇“guanwang”加入官方域名作为前后缀得到的。
- https://testnet.binance.org/en/unlock,则是通过专家词汇“test net”和改变后缀两条规则交叉实现得到的。
4.2 模块二——基于特征识别主动探测法
这个模块有点像传统黑客对于钓鱼网站主动探测的一首狂想曲。它集合了黑客对于传统钓鱼网站的搜集的各种奇技淫巧。其中包括但是不限制于引用whois正反向查询、调用某些网站的API接口或者是小工具等方法,从网站的各个维度的信息来寻找可疑钓鱼网站的蛛丝马迹。
Example 1
如果使用从okx开始变形的域名拼凑法根本拼凑不出来。但是这个网址有着和OKX几乎一样的页面特征,从okx的图标、到页面中多次提到的一些关键词还有都是查到到这个页面的关键线索之一。
Example 2
与此相似的还有这种,直接就是裸露的IP地址的网站,如果用拼凑法的角度出发,根本没有办法发现,但是从页面特征识别探测的角度却很容易找到。
4.3 模块三——基于蜜罐定期捕获全网的钓鱼网站
再强大的规则,再主动的探测得到的结果,也不如请君入瓮来得轻松快乐。模块三是全网钓鱼网站搜寻,其核心原理也是基于大部分钓鱼网站的一些显著共同特征,加入一些小技巧定期捕获网上的钓鱼网站,然后定期更新到数据库里。
模块三捕获的规则相对于模块一,会宽松很多,包括但不限于裸域、非裸域以及IP加端口号这种形式。相对于模块一二,唯一的小问题是大量的搜寻需要相对较长的时间。好处是,因为是基于全网钓鱼网站的特征识别,以及一些反钓鱼小技巧,搜集的钓鱼网站不针对某个特点的官网或者机构。 以下这些在上文有所提及的钓鱼网站,还有附录里面很大一部分网站都是模块三的产物。
这个模块还有一个小问题,就是会识别出来很多已经下架的钓鱼网站,也有一个好处,就是也会识别出来一些尚未完全开发成功但是已经形成钓鱼网站特征的网站。(这个好处在模块二也可以体现出来)
4.4 强大的验证逻辑
目前,拼接或者是挖掘出来的网址,先进行whois查询判断域名是否注册,是否过了有效期,然后进行request请求的判断其是否真实存活可访问,存活的状态码是否符合钓鱼网站的意图。
五、关于X-explore phishing detect工具的展望
对于未来计划目前检测到的钓鱼网站成果继续总结提炼一部分专家规则到模块一,并且进一步提高模块一的执行速度。还计划将更多维度的验证,例如加入网页的各种维度的特征包括title、图标、关键字、whois信息等等,来验证是否是真实钓鱼网站,尽做大的能力提炼产出的结果,减少人工最后的审核压力。并打算提供用户友好的图像可视化界面。 接下来我们还有两个研发方向:针对假NFT的钓鱼方式,进行专项监控,防止用户被误导而approve;未来也会为有需要的项目方提供实时告警服务。
附言:
如果有需要进行相关的检测服务,请不要犹豫,可以直接联系我们。衷心希望我们可以帮助到您。
六、附录
这里展示一些X-explore phishing detect工具识别出来,但是已经被浏览器、钱包拦截或者是屏蔽的一些网站。还有一些识别出来正常存活也能不受拦截很顺利打开的网站,由于篇幅问题就不一一展示了。
6.1 币安
6.1.1 谷歌识别出来是诈骗所以进行了拦截提示
- https://binance.cancel73431.com/
- http://binance.esnprotected.com/
- https://binance.mobile-manage.com/
- https://identifywallet.buzz/binanc/binance.php
- http://delegatorssolutionpads.live/binance.html
- https://yellowcitygoldendoodles.com/crypto-solutions/wallets/connect-binance/binance.html
- https://testnet.binancefuture.com/en/login
- http://accountss-binance.com/
- https://accountts-binance.com/login
- http://accounts.verification-binance.com/?binance=suspended-account
- http://adibaapparels.com/admin/binance/index.html
- http://binamce.eu
- http://binance.cneprotected.com
- http://binance.com1567854237681.xyz/167581/login.html
- http://binancelogin.info
- http://binancemetamask.com
- http://binance.mmsprotected.com
- http://binance-securrty.com
- http://binance.verify-cancel-newdevice.com/login
- http://binance-walletconect.ml
- http://binance-walletrestore-smartchain.ml.ultimatefxmarttrade.cf
- http://metamask.io-binance.xyz
- https://binance.hhsy.cc/
6.1.2 被谷歌浏览器屏蔽:
6.1.3 被狐狸钱包拦截
6.2 coinbase
6.2.1 被谷歌浏览器拦截
- https://172.247.39.162/
- https://coinbesaprime-logi.com/
- http://20.117.151.202/
- https://colnbase.la/
- http://54.146.148.54/
- http://accountsecurity-coinbase.com/
- http://app-wallet-coinbase.googleystore.com/
- http://australianaapp.com/coinbase/admin
- http://awrcgrc.ga/zamacbjinacredita/home/coinbase
- http://awrcgr.ml/coinbase
- http://bestlife.me/.../home/online/coinbase-auth-access
- http://btccoinbase.000webhostapp.com/bizmail.php
- http://case225085-coinbase-com.web.app/signin
- http://coinbase.accountrecovrey.com/lrr/attlrr/lrrcontroller
- http://coinbase.com.12548546.xyz/1586654/185485.html
- http://coinbasedirect.com/sign-on/a1b2c3/cad5961ac052068775fc8aa1ff5e368f/login
- http://coin-base.money
- http://coinbase.verification.guerramkt.com.br/
- http://coinbasewallet.googleystore.com
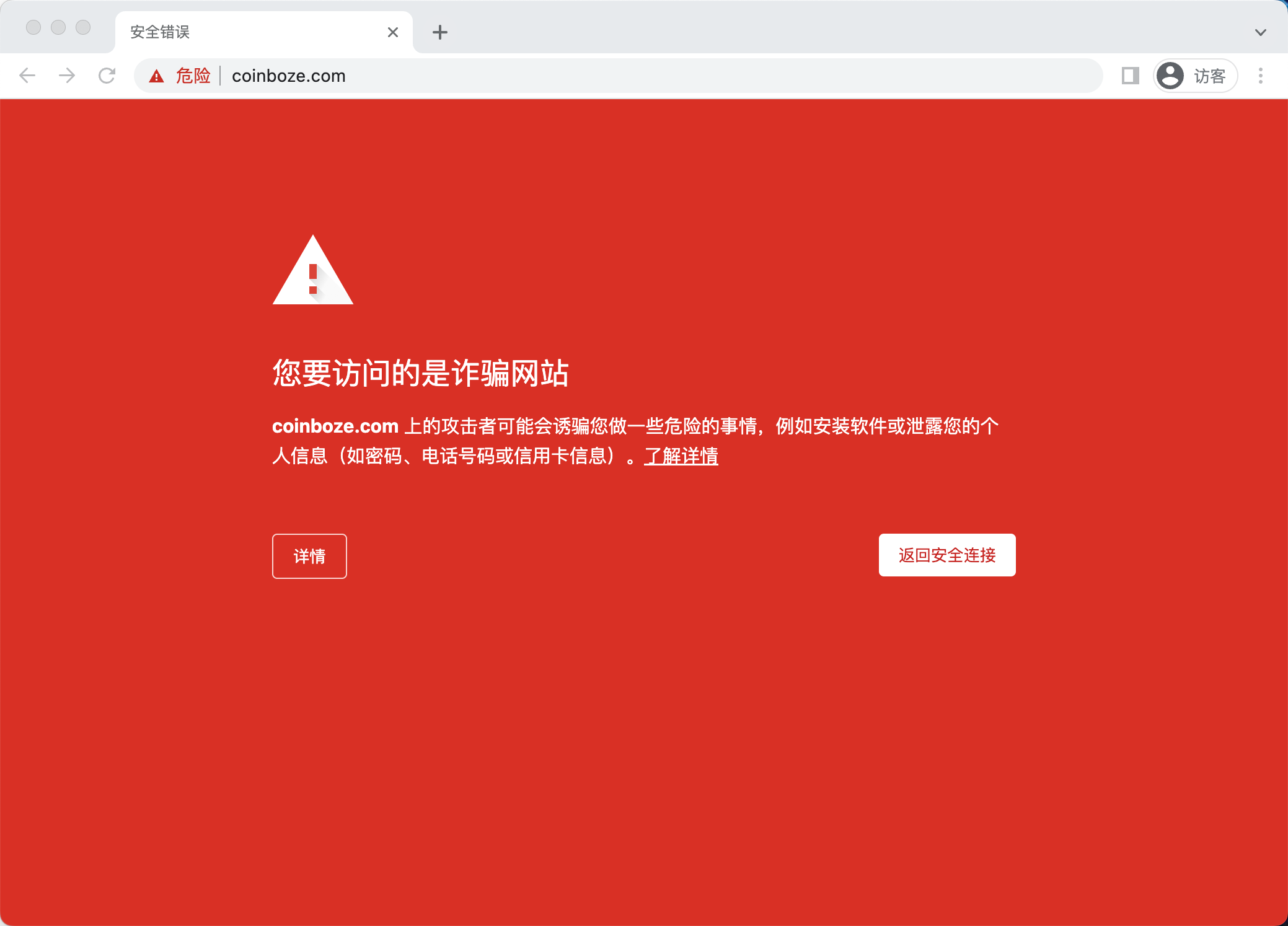
- http://coinboze.com
- http://delegatorssolutionpads.live/coinbase.html
- http://dev-1coinbase.pantheonsite.io/wp-content/uploads/2022/03/lee-harsh-html.html
- http://fineartglimpses.com/coinbase
- http://geminilogines.com/coinbase
- http://info-coinbase.net/sign-in
- http://institutocec.com/coinbase
- https://www.zenawoken.com/coinbase/admin/index.php
6.2.2 被谷歌浏览器屏蔽
6.3 kucoin
6.3.1 被谷歌浏览器拦截