
翻译:团长(https://twitter.com/quentangle_)
Part 1
如果开发者熟悉类C语言(Java、C、javascript等),Solidity是一种非常容易学习的语言,但管理gas成本是在区块链的背景下才有的概念,很少出现在其他领域。
让我们在下面的gist中看看一个mint函数的典型工作流程。mint功能是web3应用程序的区块链后台的一部分,用户通过点击mint按钮并同意发送一定数量的加密货币来铸造一个NFT。
下面是一个典型的solidity工作流程,反映了生产环境中的NFT智能合约一些功能特性:
mapping (address => uint256) public alreadyMinted;
bool public enablePublicMint = true;
uint256 constant public PRICE = 0.06 ether;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
require(totalSupply() < MAX_SUPPLY, "max supply"); // limit the total supply of NFTs for the collection
require(enablePublicMint, "public mint enabled"); // only allow public mint if the owner has enabled it
require(msg.sender == tx.origin, "no bots"); // block smart contracts from minting
require(publicMintingAddress == // check if the contract owner signed the buyer's address
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(alreadyMinted[msg.sender] < 2, "too many");// limit per-address mints to 2
require(msg.value == PRICE, "wrong price"); // require the sent ethereum to be the price set
alreadyMinted[msg.sender]++;
_safeMint(msg.sender, totalSupply());
}
这段代码是在一个可以报告gas成本的hardhat环境中执行的。为了简洁起见,合约的其余部分没有显示,但它继承了OpenZeppelin的ERC721Enumerable合约。如果你想跟着一起做,可以从这个代码仓库作开始。
上面的gist中没有定义函数totalSupply(),而是从自ERC721Enumerable继承该功能。它的作用正如它的名字所表示的那样,返回到目前为止铸造的所有代币的总供应量。
这里我们将解释代码中一些不太明显的方面。首先是msg.sender == tx.origin这一行。当一个钱包直接调用mint函数时,msg.sender是该钱包的地址。然而,如果一个智能合约调用publicMint,msg.sender将是智能合约的地址。在这种情况下,tx.origin是发起智能合约调用publicMint的事件的钱包地址。当智能合约进行调用时,tx.origin将不等于msg.sender。这就阻止了智能合约进行mint。
其次,我们看到一个由toEthSignedMessageHash和recover组成的 require语句。这将在后面全面解释。这里的想法是用户用私钥签署在并返回签名。智能合约知道钱包的地址(存储在 publicMinting地址变量中)。智能合约将检查签名是否与相关的地址相匹配。这样一来,他们就知道私钥所有者授权了这笔交易。这可以作为一种反机器人的措施,因为我们可以使用类似验证码的接口来确保人类有公平的机会来造币。稍后会有更多这方面的内容。
其余的代码应该是不言自明的。
Hardhat有一个很好的功能,就是告诉你一个函数的调用要花费多少gas,也就是
REPORT_GAS=true npx hardhat test
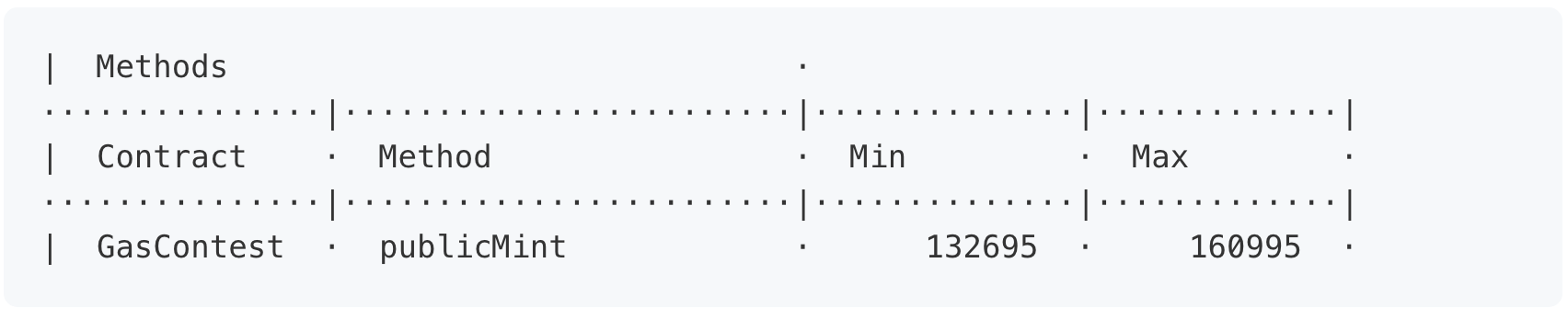
代码中的单元测试(见前面链接的资源库),从同一个地址mint两次。第一个mint花费160,995个gas,第二个mint花费132,695个。
这在实际意义上意味着什么呢?gas成本(以美元计)可以用以下公式计算:
Gas $ = Gas Cost ÷ 1 Billion × Gas Price in Gwei × ETH Price $
gas价格随需求而变化,但在撰写本文时,根据ethgasstaion.info的数据,其价格为80Gwei。以太坊在写这篇文章时的价格为3600美元,所以如果我们把所有的东西都相乘(160,995÷10 Billion×80×3600),我们得到的gas价格为46美元。
对于那些习惯于100美元的mint的人来说,请记住,按照最近的行情,80Gwei有些低,它可以很容易地涨到150Gwei。如果以太坊超过4000美元,铸币成本将很容易进入三位数。
因此,如果我们想降低gas成本,我们可以等待gas价格低的时候,或者我们可以修改合约,使其尽可能有降低成本,这当然是本文的重点。
了解EVM
像其他的编程语言一样,编译solidity 时,它被转化为一连串的操作代码。每个操作代码都有一个相关的gas成本。Trail of Bits在这里编制了一个表格,鼓励读者浏览一下。操作码的相对成本是合理的。例如,用KECCAK256取一个哈希值至少需要30个gas,但两个数字相乘只需要5个gas。有道理吧?
为了减少gas,我们需要把重点放在真正昂贵的操作上。SSTORE(20,000 gas)和SLOAD(800 gas)。这些操作分别是写和读区块链数据。以太坊的设计者让这些操作变得昂贵,因为一旦有东西被写入区块链,它就有可能在剩下的时间里存储在那里,所以高成本是为了抑制占用宝贵的区块链空间。如果你深入了解它的机制,SSTORE有一个有趣的特性:将一个存储值从零设置为非零需要花费20,000 gas;但将一个非零值改为另一个非零值需要花费5,000个gas。这就是为什么第二个mint要比第一个mint便宜得多。在第一次迭代中,totalSupply将一个存储变量从0增加到1,而在第二次mint中,alreadyMinted[msg.sender]++中改变的值从1增加到2,而不是0增加到1。
了解存储操作码
我们当然可以编译到Ethereum字节码并查看,但坦率地说,这没有必要。让我们一行一行地看,看看我们可能从存储中读写的地方:
mapping (address => uint256) public alreadyMinted;
bool public enablePublicMint = true;
uint256 constant public PRICE = 0.06 ether;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
require(totalSupply() < MAX_SUPPLY, "max supply"); // READ
require(enablePublicMint, "public mint enabled"); // READ
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress == // READ
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(alreadyMinted[msg.sender] < 2, "too many"); // READ
require(msg.value == PRICE, "wrong price");
alreadyMinted[msg.sender]++; // READ and WRITE
_safeMint(msg.sender, totalSupply()); // ??
}
对于_safeMint()函数,我们需要深入到OpenZeppelin contract内部去看看它做了什么:
function _mint(address to, uint256 tokenId) internal virtual {
require(to != address(0), "ERC721: mint to the zero address"); require(!_exists(tokenId), "ERC721: token already minted");
_beforeTokenTransfer(address(0), to, tokenId); // see below
_balances[to] += 1; // READ AND WRITE
_owners[tokenId] = to; // WRITE
emit Transfer(address(0), to, tokenId);
}
由于我们继承了ERC721Enumerable,_beforeTokenTransfer做了一些其他的事情。在mint时调用了_addToAllTokensEnumeration。
function _addTokenToAllTokensEnumeration(uint256 tokenId) private {
_allTokensIndex[tokenId] = _allTokens.length; // READ
_allTokens.push(tokenId); // WRITE
}
_addTokenToOwnerEnumeration也调用了:
function _addTokenToOwnerEnumeration(address to, uint256 tokenId)
private
{
uint256 length = ERC721.balanceOf(to); // READ
_ownedTokens[to][length] = tokenId; // WRITE
_ownedTokensIndex[tokenId] = length; // WRITE
}
存储操作的最终得分是8次读取和6次写入,总计超过120,000的gas成本!(以太坊在相同的操作中对存储读取做了一些缓存,所以比这更复杂一些,但数量级是正确的)。
摆脱ERC721Enumerable
ERC721Enumerable的附加功能是另一篇文章的主题。但本质上,它允许外部智能合约查询ERC721Enumerable合约,以了解客户拥有多少代币,然后逐一询问用户的每个代币拥有哪个token ID。
就个人而言,我不喜欢这种功能。迭代持续的时间没有理论上的限制(所以gas成本是无限制的)。迭代在链外进行时是免费的(从gas角度来看)。几乎所有与NFT的互动都是通过网络浏览器进行的,可以使用Infura或Etherscan等以太坊节点来完成迭代。
如果建立一个NFT游戏,这可能是必要的,但可以通过链外迭代并将结果转发给外部智能合约来恢复同样的功能,它可以验证这些ID中的每一个确实是由地址拥有的。
总之,我想说的是。让我们用vanilla ERC721替换ERC721Enumerable,看看会发生什么。
由于我们失去了函数totalSupply(),我们将需要自己实现它:
mapping (address => uint256) public alreadyMinted;
uint256 constant public MAX_SUPPLY = 7777;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 0;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
require(totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(alreadyMinted[msg.sender] < 2, "too many");
require(msg.value == PRICE, "wrong price");
alreadyMinted[msg.sender]++;
totalSupply++;
_safeMint(msg.sender, totalSupply - 1);
}

还记得我们说过,从零写到非零要花费20,000个gas,但当数值从非零值变为另一个非零值时,要花费5,000个gas吗?这意味着如果我们把totalSupply从1开始,而不是从0开始,我们就可以轻松地节省15,000个gas。(我们还需要更新单元测试和MAX_SUPPLY以反映token Id的变化)。
mapping (address => uint256) public alreadyMinted;
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
require(totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(alreadyMinted[msg.sender] < 2, "too many");
require(msg.value == PRICE, "wrong price");
alreadyMinted[msg.sender]++;
totalSupply++;
_safeMint(msg.sender, totalSupply - 1);
}

Wow,我们从16万gas降到了10.7万gas!这对最终用户来说可能是超过40美元的节省,这取决于市场条件!但仍有优化的空间!
使用balanceOf而不是alreadyMinted
如果你回过头来看看OpenZeppelin是如何实现铸币功能的,你会看到这一行
_balances[to] += 1;
事实证明,我们通过在一个单独的映射中跟踪这个变量,实际上是重复了一次读和写。OpenZeppelin通过balanceOf提供了一个接口给这个变量,我们可以从我们的代码中调用。
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
require(totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin);
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
totalSupply++;
_safeMint(msg.sender, totalSupply - 1);
}

gas成本下降了20,000多!很值吧?当我们删除alreadyMinted[msg.sender]++时,就去掉了一次写和一次从存储中读。
提高totalSupply的效率
事实证明,我们在管理totalSupply的过程中有点浪费了。在上面的要点中,它被从存储空间中读取3次并写入一次。请记住,从存储器中读取是很昂贵的,所以如果把它写到一个局部变量中,对其进行操作,然后再写回存储器,我们就可以节省一些成本。
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin);
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
_totalSupply++;
_safeMint(msg.sender, _totalSupply - 1);
totalSupply = _totalSupply;
}

这节省了141个gas。节省的gas不是很大的原因是,如果你在相同的执行环境中从相同的存储变量中读取,EVM不会收取全部的800。不过,在成千上万的mint中,这还是节省了不少以太坊的数量。
另一件在人们看来可能很滑稽的事情是在调用_safeMint后存储totalSupply。这样做是安全的,因为_safeMint不是一个外部调用。如果_safeMint**是一个外部调用,你就会有一个重入漏洞!**但是_safeMint是父合约,所以这是安全的。另外,与常规编程不同,以太坊的状态更新是全有或全无。要么整个执行成功,要么完全不成功。因此,不可能出现一个token被铸造出来,但totalSupply没有被更新的情况。实际上,你可以把require语句放在函数的末尾,功能会保持不变。
如果是这样的话,那么为什么我们在增加_totalSupply的同时,还要在下一行减去一个?好问题!让我们重新安排一下我们的数学运算!
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
_safeMint(msg.sender, _totalSupply);
_totalSupply++;
totalSupply = _totalSupply;
}

这为我们节省了188个gas,这对于加法和减法来说似乎很多。如果你看一下ADD和SUB(加法和减法)的操作码,每个操作代码只有3个gas。但是,当你编译成字节码时,记住EVM必须不断地洗牌正确的变量,以保持正确的变量在堆栈的顶部。编译成字节码对读者来说是一个练习,但你会看到简单的数学实际上包含了几个从内存中读和写的指令,以及一些PUSH和有时DUP指令。这些都是单独的小事,但加起来却很重要。
移除溢出检查
从solidity 0.8.0开始,算术溢出保护被默认为包括在内。但是我们已经有了一个溢出保护,因为我们要求总供应量小于7777。因此,在斗篷下,有两个溢出检查,这显然是在浪费gas。让我们用一个未检查的块来解决这个问题。
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
_safeMint(msg.sender, _totalSupply);
unchecked {
_totalSupply++;
}
totalSupply = _totalSupply;
}

又节省了123个gas!
开启优化
精明的读者可能已经注意到,我还没有打开 solidity 优化。这是故意的,这样我可以深入研究存储,优化不能减少操作码的成本,只是发出更少的操作码。这里是优化设置为200时的情况。
·-------------------------------|---------------------------|
| Solc version: 0.8.10 · Optimizer enabled: true ·
································|···························|
| Methods ·
···············|················|·············|·············|
| Contract · Method · Min · Max ·
···············|················|·············|·············|
| GasContest · publicMint · 66718 · 83818
这是设置我1000的情况。
·-------------------------------|---------------------------|
| Solc version: 0.8.10 · Optimizer enabled: true ·
································|···························|
| Methods ·
···············|················|·············|·············|
| Contract · Method · Min · Max ·
···············|················|·············|·············|
| GasContest · publicMint · 66674 · 83774 ·
这样做的好处是,如果优化器设置为一个较高的数字,部署将更加昂贵。数字越大,编译器就越能优化被使用数千次而不是数百次的函数。由于我们计划使用数以千计的mint,而且想把节省的gas集中在mint功能中,所以一个较高的数字是有意义的。
mint vs safeMint
这两个函数之间有什么区别?safeMint函数调用mint,并检查接收器是否是智能合约,并实现ERC721Receivable接口。
function _safeMint(
address to,
uint256 tokenId,
bytes memory _data
) internal virtual {
_mint(to, tokenId);
require(_checkOnERC721Received(address(0), to, tokenId, _data),
"ERC721: transfer to non ERC721Receiver implementer"); }
由于我们不支持对智能合约进行铸造,可以跳过这个检查。另外,还记得我们之前关于以太坊是一个全有或全无的执行方式的讨论吗?在这里,你可以看到require语句发生在业务逻辑之后!
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
bool public enablePublicMint = true;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(enablePublicMint, "public mint enabled");
require(msg.sender == tx.origin);
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
_mint(msg.sender, _totalSupply);
unchecked {
_totalSupply++;
}
totalSupply = _totalSupply;
}

由于这一变化,我们节省了315个gas。再次,请确保你了解你的业务需求。如果你期望智能合约可以铸造你的NFT,你应该使用safeMint来代替。
移除对启用公开mint的冗余检查
虽然我们没有重复代码,但我们确实有重叠的功能,可以修剪掉。
签名方案还允许我们仅仅通过将签名地址设置为20个随机字节来防止公开mint。(设置为零地址来禁用公开mint不是一个好主意,因为根据OpenZeppelin,一些签名恢复失败会导致零地址,有人可以绕过这个门槛!)。通过移除隐藏在toEthSignedMessageHash中的哈希函数来节省gas可能也是很诱人的(后面会有更多的介绍),但OpenZeppelin特别指出不要这样做。
移除这个检查后,我们看到节省了几千美元的gas。
用toEthSignedMessageHash保存一个函数调用
也就是说,我们仍然可以复制和粘贴这个函数的代码,以避免函数调用并节省一点gas。从技术上讲,我们也可以用recover()函数做同样的事情,但这对可读性影响非常大,而且只能节省一点gas。而且说实话,我对ECDSA算法并不了解,所以我就不碰这些代码了。
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress ==
keccak256(
abi.encodePacked(
"\x19Ethereum Signed Message:\n32",
bytes32(uint256(uint160(msg.sender)))))
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
_mint(msg.sender, _totalSupply);
unchecked {
_totalSupply++;
}
totalSupply = _totalSupply;
}

这只节省了28个gas。我希望solidity的开发者有一天能解决这个问题。调用一个内部函数应该被优化掉。无可否认,solidity在财务上鼓励坏的编码做法。我想因为这还是新技术的早期阶段。
ERC721 _mint中的冗余操作
让我们再把ERC721的mint功能挖出来吧
function _mint(address to, uint256 tokenId) internal virtual {
require(to != address(0), "ERC721: mint to the zero address");
require(!_exists(tokenId), "ERC721: token already minted"); _beforeTokenTransfer(address(0), to, tokenId); _balances[to] += 1;
_owners[tokenId] = to;
emit Transfer(address(0), to, tokenId);
}
**在这一点上,我们正在进入危险区。**除非你知道你在做什么,否则修改深度审计的库通常不是一个好主意!下面的修改之所以有效,是因为我们的代码库中只有一个进入mint功能的入口。如果有几种方法来mint,可能会出现交易顺序的错误,所以只有在你知道你在做什么的情况下才会做这些修改。节省的gas并不是很大。
在我们的例子中,我们不需要零地址检查,因为msg.sender从来不是零地址。因为tokenId是递增的,所以我们不需要检查token是否已经存在(记住,要么铸币成功,总供应量增加,要么整个操作被还原)。同样地,_beforeTokenTransfer也没有被使用,所以我们可以删除它。
我们还可以将_balances改为内部变量,而不是私有变量,这样我们就可以直接访问它,而不是使用函数调用。下面是结果
uint256 constant public MAX_SUPPLY = 7778;
uint256 constant public PRICE = 0.06 ether;
uint256 public totalSupply = 1;
address private publicMintingAddress;
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(msg.sender == tx.origin, "no bots");
require(publicMintingAddress ==
bytes32(uint256(uint160(msg.sender)))
.toEthSignedMessageHash()
.recover(_signature),
"not allowed"
);
require(balanceOf(msg.sender) < 2, "too many");
require(msg.value == PRICE, "wrong price");
_mint(msg.sender, _totalSupply);
unchecked {
_totalSupply++;
}
totalSupply = _totalSupply;
}

把节省gas做的太过
从技术上讲,在目前的形式下,可以再减少一次存储写入,一些项目也是这么做的。这些解决方案将_balances[to] += 1和_owners[tokenId] = to替换成一个数组owners.push[to],然后在数组上循环,实现 ERC721的balanceOf功能。通过将两次存储写入改为一次,可以节省20,000个gas。问题是,所有者可能是数以千计的。
一个简单的功能可能花费数百万的gas。无界循环是solidity中一个已知的反模式。虽然确实,也许很多项目可以摆脱永远不需要称为链上的balanceOf,但我们不知道未来会建立什么样的去中心化市场。如果去中心化市场由于gas成本高而无法与智能合约互动,那么NFT的价值将受到影响。有这个弱点的gas优化不能接受。
我们也不需要猜测未来的需求。在允许mint之前,我们需要知道钱包的余额(即一个地址持有一个NFT项目的多少个token,译注),因为我们不希望有太多的钱包来持有一个NFT。一个在第6,000个mint进来的人,将不得不在6,000个地址中循环,看看他们是否被允许铸币。这不是一个可行的解决方案。
如果钱包限制是不必要的呢?
有一种说法是,如果有人想要更多的mint,他们可以给他们的朋友一些ETH,让他们同时mint。请记住,这是一个公开的mint,签名只用于门槛,以阻止僵尸,而不是用于预售名单。唯一能保证没有一个持有者拥有太多作品的方法是只做私下销售,但即使这样人们也可以使用多个身份。
当然,这不是一个简单的问题,但对于那些希望取消限制的人来说,以下是基准测试。
function publicMint(bytes calldata _signature) external payable {
uint256 _totalSupply = totalSupply;
require(_totalSupply < MAX_SUPPLY, "max supply");
require(publicMintingAddress ==
keccak256(
abi.encodePacked(
"\x19Ethereum Signed Message:\n32",
bytes32(uint256(uint160(msg.sender)))))
.recover(_signature),
"not allowed"
);
require(msg.value == PRICE, "wrong price");
_mint(msg.sender, _totalSupply);
unchecked {
_totalSupply++;
}
totalSupply = _totalSupply;
}
require(msg.sender == tx.origin) 和 require(ERC721._balances[msg.sender]) 两行消失了。 这两行都是为了限制每个钱包的mint而需要的。否则,有人可以创建一个智能合约,在一个循环中调用publicMint,同时将这一片转移到另一个地址,以保持_balances值低。整个循环在以太坊中被认为是一个交易。
请注意,没有任何东西可以阻止人mint,然后转走以减少余额并再次铸币,但在公开mint期间有动机这样做的人可以更容易地只是使用他或她控制的地址来让所有的交易进入一个区块(女巫攻击)。在第三部分中,我们讨论了一种限制每个钱包铸币的省gas方法,该方法对人们将NFT转移走有免疫力(注意这只有在地址添加到预售列表时,一些防御女巫攻击的方法才有意义)。
请记住,将公开mint地址限制在2个是相当随意的决定,可能是也可能不是项目的正确选择。
不要使用<=或>=比较运算器
在EVM中,有一个小于和大于的操作码,但不是小于等于或大于等于。使用<=或>=运算符的代码,那么它的gas消耗量将更大,因为它将检查值是否小于,同时也检查值是否相等。
这就是为什么totalSupply < 7778比totalSupply <= 7777好,msg.value == PRICE比msg.value >= PRICE好。如果可能的话,最好将常数移一,而不是使用这些更昂贵的运算符。
不要使用 uint256 以外的东西
在solidity中,变量打包是指将小的存储变量放在彼此旁边,使它们位于一个256位的槽中。比如说:
uint64 public var1;
uint64 public var2;
uint64 public var3;
uint64 public var4;
占用的存储空间与下面的语句一样:
uint256 public var;
这是变量打包,如果你不需要完整的256位,可以节省部署成本。
然而,在前面的代码中,totalSupply是一个uint256变量。尽管可以通过变量打包来节省部署的费用,但用户将不得不支付额外的费用。每当一个小于256的uint(甚至是一个bool)从存储中被拉出时,EVM就会将其转换为一个uint256(详见文档)。这种额外的铸造要花费gas,所以最好是避免。对于那些对gas不那么敏感的功能,变量打包是一个好主意。
当可以使用external时,不要使用public
注意publicMint函数在写的时候是:
function publicMint(...) external payable {
而不是:
function publicMint(...) public payable {
除非你的合约由于一些非常不寻常的原因,需要从合约内部调用publicMint,否则不要使用public 。两者之间的区别是,external不允许合约本身调用该函数,但允许外部调用。尽管它们完成了同样的事情(允许外部调用),但external的效率更高,因为Solidity不需要允许两个入口点。
不使用不必要的重入检查
记住,只有当你调用另一个合约时(比如你明确地调用另一个合约的函数或转移以太币),才可能发生重入漏洞。在整个mint序列中,没有调用外部合约,也没有发送以太。我看到有几个项目在不需要检查的地方把这些检查加到了mint函数中。当然,有安全意识是好的,但重入检查需要从存储中写入和读出,如前文所述,这很昂贵,而且在这种情况下,它们实际上并没有增加安全性。
结论
其中一些节省的gas导致非常小的节省,所以开发者将不得不决定权衡利弊。尽管如此,希望这个练习能让我们对EVM有更深的了解,以及在哪里可以找到省gas的方法。
在第二部分,我们将比较mapping、Merkle树和公开签名作为允许选定的买家购买的机制。公开签名是一个明显的赢家(否则我们为什么要在这里使用它呢?
Part 2:默克尔树和签名
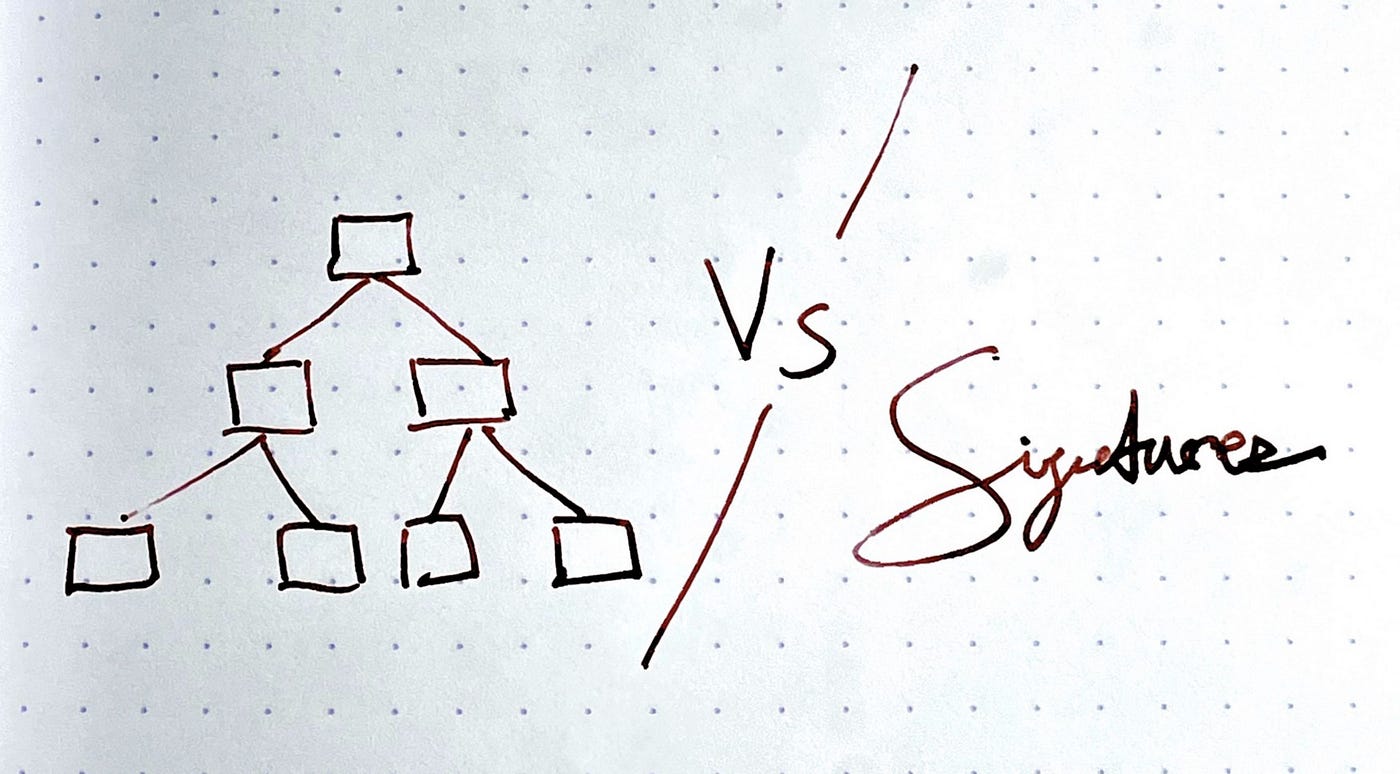
当代币空投,或进行私下许可销售(只有选定的地址被允许购买代币或铸造NFT的销售)时,有三种流行的机制,只允许选定的地址列表购买。
- 将地址存储在一个映射中
- 用私钥签署地址,并在链上验证该签名
- 使用默克尔证明
下面是solidity中的实现方案:
function benchmark1Mapping() external {
require(allowList[msg.sender] == 1, "not allowed");
// business logic
}
function benchmark2PublicSignature(bytes calldata _signature) external {
require(
allowListSigningAddress ==
keccak256(
abi.encodePacked(
"\x19Ethereum Signed Message:\n32",
bytes32(uint256(uint160(msg.sender)))
)
).recover(_signature),
"not allowed"
);
// business logic
}
function benchmark3MerkleTree(bytes32[] calldata merkleProof) external {
require(
MerkleProof.verify(merkleProof,
merkleRoot,
keccak256(
abi.encodePacked(msg.sender))),
"not allowed");
// business logic
}
在第一个函数中,我们检查调用者是否是allowList映射的成员。在第二个中,调用者发送一些证明,证明msg.sender被允许进行交易。
实验很简单,从gas成本的角度来看,这三种方法中哪一种是最好的?
默克尔树的机制
假设读者已经知道Merkle树的工作原理,但为了基准测试,我需要做一个快速回顾。这里可以找到一个奇妙的解释。
Merkle树需要一个提议的成员和一个证明该成员在集合中的证据。每个成员都是一棵(平衡的)二叉树的叶子,证明是兄弟节点的哈希值序列,这样Merkle根就可以通过 “哈希值到根 ”的方式重建。如果根部的哈希值与序列的哈希值相匹配,那么该候选人确实是一个成员。
这里需要注意的是,允许的地址池越大,证明的时间就越长,与树的高度成对数关系。因此,在允许的列表上有32个地址需要5个证明长度,256个需要8个,而4096个需要12个等等。对于这个基准,我们使用4096,因为在一个典型的NFT发布中,这大概是会被添加到预售中的地址数量。
公开签名机制
对于公开签名,买方的地址哈希通过私钥签署。智能合约知道签名者的公钥,它使用地址的哈希值和提供的签名来了解它是否真的由私钥签署。如果是,那么用户就被允许购买。与默克尔树不同,这种机制不受添加到预售或空投中的地址数量的影响。
方法和结果
solidity编译器被设置为上一篇文章中每个实验的优化水平为1000。Hardhat被用来测量gas成本。你可以在这里克隆仓库:https://github.com/DonkeVerse/PrivateSaleBenchmark
要把这些数字放在上下文中,请记住,启动一个以太坊交易需要21,000个gas。所以你需要减去这个值,才能看到归于允许列表机制的成本。在下面的表格中,我们使用了4096个地址进行测试。

可以预见的是,使用映射是最便宜的,因为你所要做的只是从存储中读取。然而,每一个添加到预售的地址都要花费20,000 gas的存储。当有成千上万的地址时,这变得非常昂贵。那么就有一个风险,项目方花了ETH将一个地址添加到允许的列表中,但客户并没有购买,这笔费用就会损失。如果你在用户开采代币后将allowedList mapping设置为零,那么gas成本将更低,因为EVM会将设置存储量退还为零。在这种情况下,新的gas成本从23,424下降到21,598。这基本上是无可匹敌的,因为交易不能低于21,000。这无疑会让客户更高兴,但请记住,在后面的操作中,会有更多的以太币被烧掉,牺牲给矿工。增加一个地址需要花费20,000 gas,但在mint只保存了约2,000 gas。因此,价值18,000 gas的以太坊被蒸发了。另一方面,签名需要牺牲价值约8,293个gas的以太坊。从长远来看,这是较少的浪费。
Merkle树成本与地址数量的关系
当有128个地址或更多时,Merkle Trees显然没有优势。只有当Merkle树中有127个或更少的地址时,它们才会比签名有效。因为地址是随机产生的,所以在gas测量中可能会有轻微的差异。
+---------------------+----------------------+
| Number Of Addresses | Merkle Tree Gas Cost |
+---------------------+----------------------+
| 16 | 27,862 |
| 32 | 28,732 |
| 64 | 29,636 |
| 128 | 30,517 |
| 256 | 31,389 |
| 512 | 32,284 |
| 1,024 | 33,195 |
| 2,048 | 34,036 |
| 4,096 | 34,906 |
| 8,192 | 35,801 |
| 16,384 | 36,746 |
+---------------------+----------------------+
签名地址是否影响到gas费用?
通过对不同地址的实验(感谢Convex Labs在Honest NFT的建议!),我们发现有一个地址比一般的地址节省了大约12个gas。看来,添加前导零并不是节约的原因。
+---------------------------------------------+----------+
| Public Key | Gas Cost |
+---------------------------------------------+----------+
| 0x2132bC228dcAe17EE18Bbf078FA48FB12d90C015 | 29273 |
| 0x0D9A6F68f2A49DBa6e8991e64c3173088c25a566 | 29261 |
| 0x00c53Da2e09bc19c02bb56aE480eEa48081E8bF2 | 29273 |
| 0x000C6a093B079Bd237079213881Ce9DD8283c9FC | 29281 |
| 0x00008Eb5Faf23B93c85Fa87BBA3641e3E20475C4 | 29273 |
| 0x00000e71C7532da2f6Fe9d10942f25C565E0b045 | 29273 |
+---------------------------------------------+----------+
替代方法
一个解决方案是布隆过滤器bloom filter(以及它的亲戚XOR过滤器和ribbon过滤器),但事实证明并不可行。布隆过滤器是一个概率集,其返回结果是 “也许在这个集子里”或 “肯定不在这个集子里”。问题是,对手可以不断尝试不同的地址,直到他们找到一个 “可能在集合中”的地址。即使布隆过滤器被设置为具有极低的false-positive率,对抗者在GPU的帮助下也不难找到一个例外。
另一个不足的解决方案是使用公共签名,但比特数较少,这将无法使用操作码ECRECOVER。
下面是一些复杂的解决方案,可能值得探索。我们没有做任何基准测试,所以要谨慎对待。
- zk-snarks。零知识并不有趣,但简洁的部分是。如果tornado.cash(使用zk-snarks)的gas成本作为指标,这将不会起作用,但它值得一提。
- Verkle树就像Merkle树,但有一个恒定的大小证明
- 一些允许以比特形式进行编码的树/Trie。如果所有的地址都可以存储在一个长的比特序列中,而证明成员资格只是以某种方式遍历这些比特
- Patricia Tries或Radix Trees。一个地址可以被编码为一串十六进制符号或一串比特。因此,如果有办法以位的形式对树进行编码,这可能是可行的。
- 带有位图的位数Trie很有意思,因为位数运算符可以节省大量的gas。
结论
在预售和有超过127名参与者的空投中使用签名。否则,使用Merkle树。
未来希望可以研究和开发出一个更有效的方案。
该系列的第三部分,我们不仅跟踪用户是否在预售中,而且跟踪他们可以铸造多少件。
Part 3:利用位操作节省30,000美元的预售gas
在公开mint中,人们一般可以随心所欲地铸造NFT,通过反复铸造,或者通过与其他买家勾结。这在私下销售(有时被称为白名单)中是不可取的,因为名单上的每个成员都被保证有指定数量的铸币。一个典型的工作流程在solidity中是这样的:
mapping(address => uint256) amountMintedSoFar;
function presale(bytes calldata _proof) external payable {
require(totalSupply() < MAX_TOKEN_SUPPLY);
require(msg.value == PRICE);
require(validateUser(_proof, msg.sender);
require(amountMintedSoFar[msg.sender] < MAX_PER_USER);
amountMintedSoFar[msg.sender]++;
_mint(msg.sender, totalSupply());
}
(请注意,为了简洁起见,这并不包括第一部分中列出的优化。不要实际使用这段代码! 它没有require信息!)
这个工作流程对于任何曾经对NFT进行过编程的人来说都应该很熟悉。在我们实现了第一部分和第二部分的所有优化后,还有一件事要做。
这里造成不必要的高gas的罪魁祸首是 amountMintedSoFar[msg.sender]++ 。该变量是一个从地址到该用户迄今已铸币数量的映射,我们要确保它不超过他们的分配额。
虽然这对任何经验丰富的程序员来说应该是一个显而易见的解决方案(哈希图有一个臭名昭著的名声,即它们在面试时总是正确的答案),但将地址映射到整数在以太坊上使用时有一个缺点。
通过回顾,如果我们有一个映射mapping(address => uin256) myMap ,操作myMap[myAddress] += 1在第一次执行时要花费20,000 gas,因为在以太坊中把一个零值设置为非零值要花费这么多。非零到另一个非零则要便宜得多,只需5,000gas。所以myMap[myAddress]+=1,如果里面的uint值不是零,就会花费5,000个gas。
另外,作为回顾,将gas成本翻译成美元的方法如下
cost in $ = gas used × gas price (gwei) × ETH price ($) / 1 Billion
你可以从etherscan或ethgasstation等网站获得当前的gas价格。
将一个存储变量从零增加到非零是最昂贵的以太坊操作之一。这大概是进行一次以太坊转账所需的费用,这足以在2022年初购买一杯非常昂贵的咖啡。下面是用典型数字进行的计算。
20,000 × 100 gwei × $3,800 / 1 Billion = $7.6
如果我们不为每个我们认为会在预售期间铸造代币的地址手动设置映射,我们可以为用户节省大量的gas。在这种情况下,代码将看起来像这样:
mapping(address => uint256) amountLeftToMint;
addUserToPresale(address _buyer, uint256 _amt) external onlyOwner {
amountLeftToMint[_buyer] = _amt;
}
function presaleSingle(bytes calldata _proof) external payable {
// ... other require statements
require(amountLeftToMint[msg.sender] > 0);
amountLeftToMint[msg.sender]--;
_mint(msg.sender, totalSupply());
}
这对用户来说将便宜得多,因为将非零存储设置为非零值需要花费5,000个gas,这就便宜了75%!
但问题是,现在合约所有者必须为她想加入预售的每一个地址支付20,000个gas!这是不可能的。假设我们有一个5,000件的预售。这将花费1亿gas。假设gas价格为100Gwei,以太币价格为3800美元,为所有这些用户设置映射的总成本将花费至少38,000美元,这还不包括额外的开销!而且肯定会超,因为在写这篇文章的时候,一个以太坊区块只允许在一个区块内有3000万Gas,所以要把所有的预售分配分成许多以太坊区块中可管理的批次,这就是大量的交易。
因此,要么合约所有者支付一辆新车的gas价格,要么五千名用户浪费了一辆豪华咖啡的以太坊价值。有更好的方法吗?
balanceOf在这里不起作用
在第一部分中,我们在公共铸币期间使用了ERC721库中的balanceOf,以确保没有人在一次交易中铸币超过一定数量。回顾一下,ERC721规范中的balanceOf告诉你一个地址拥有多少个代币。这更像是一个速率限制器,而不是一个绝对的限制,因为人们可以使用不同的钱包来绕过限制。
BalanceOf在预售期间不会起作用,因为人们可以铸币,将铸造好的转移到另一个钱包以降低其余额,然后再次铸币。因此,在技术上,一个有勤奋的人可以铸造整个预售分配。
在公开销售中,我们并不关心这个问题,因为我们无法阻止第一部分中提到的女巫攻击。但是对于许可销售来说,这可能是一个真正的问题!
更好的方法
映射允许我们有效地存储无限数量的地址,但我们实际上并不需要这种能力 在现实中,我们所做的是确保我们承诺的5000件作品事实上将提供给上述买家。
理论上的信息限制
我们真正关心的是一个特定的NFT是否已经被认领。我们只需要一个比特来存储这个信息。如果我们想跟踪5,000件,我们只需要5,000比特或625字节来存储这一信息。这相当于以太坊的21个存储单元(一个存储单元是32字节)。使用前面的经济假设,21个存储单元将花费所有者160美元来设置,这比38,000美元有了很大的进步!
想象一下,我们可以以某种方式说,用户1被许诺bits 0,1,2,用户2被许诺bit 3,用户3被许诺bit 4和5,等等。预售清单将看起来像这样:
| User | Amount Promised |
+-------+-----------------+
| User1 | 3 |
| User2 | 1 |
| User3 | 2 |
...
将地址映射到bit
当然,我们不想使用另一种mapping来从地址到bit,因为这将违背本练习的目的!
在第二部分中,我们注意到,使用ECDSA签名是将地址添加到预售、允许列表或空投中的最有效方式。
因此,我们可以不只是签署地址,而是同时签署地址和它们被分配的比特号。这样我们就会有5,000个已经设置为1的位。现在这个表看起来是这样的:
| User | Amount Promised | Signatures (ticket to presale)
+-------+-----------------+-----------------------------------------
| User1 | 3 | sig(User1,0), sig(User1,1), sig(User1,2)
| User2 | 1 | sig(User2,3)
| User3 | 2 | sig(User3,4), sig(User3,5)
...
如果用户能提交一个有效的组合:1)他们的地址;2)票据号码;3)与之对应的签名,才允许交易。我们在本文中称这个三联体为 “票ticket”。因此,一个能铸造三个NFT的人有三张票。
在他们使用他们的票后,智能合约将票号对应的位设置为零。这个操作只需要花费5,000个gas(因为我们把一个非零的存储量改为非零,假设存储槽中还有其他非零的位)。EVM不允许我们只写一个位的存储,你只能以32个字节为单位写。所以我们必须找到目标bit所在的32字节槽,并将其翻转,其他255位保持不变。用户永远不需要将存储空间从零设置为非零,也不需要支付20,000美元的gas。相反,我们支付160美元将5,000位设置为1(160美元的gas),并在链外签署所有地址和票号(没有gas)。
Show Me the Code!
contract PresaleBenchmark {
uint256 private constant MAX_INT = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;
uint256[3] arr = [MAX_INT, MAX_INT, MAX_INT];
function claimTicketOrBlockTransaction(uint256 ticketNumber) external {
require(ticketNumber < arr.length * 256, "too large");
uint256 storageOffset = ticketNumber / 256;
uint256 offsetWithin256 = ticketNumber % 256;
uint256 storedBit = (arr[storageOffset] >> offsetWithin256) & uint256(1);
require(storedBit == 1, "already taken");
arr[storageOffset] = arr[storageOffset] & ~(uint256(1) << offsetWithin256);
}
}
如果你想跟着做,你可以把上面的代码粘贴到remix.ethereum.org中,按照第一部分的讨论,把优化器设置为1000,然后把你选择的票据号码放到claimTicketorBlockTransaction的函数调用中(本例中为票据号码10)。
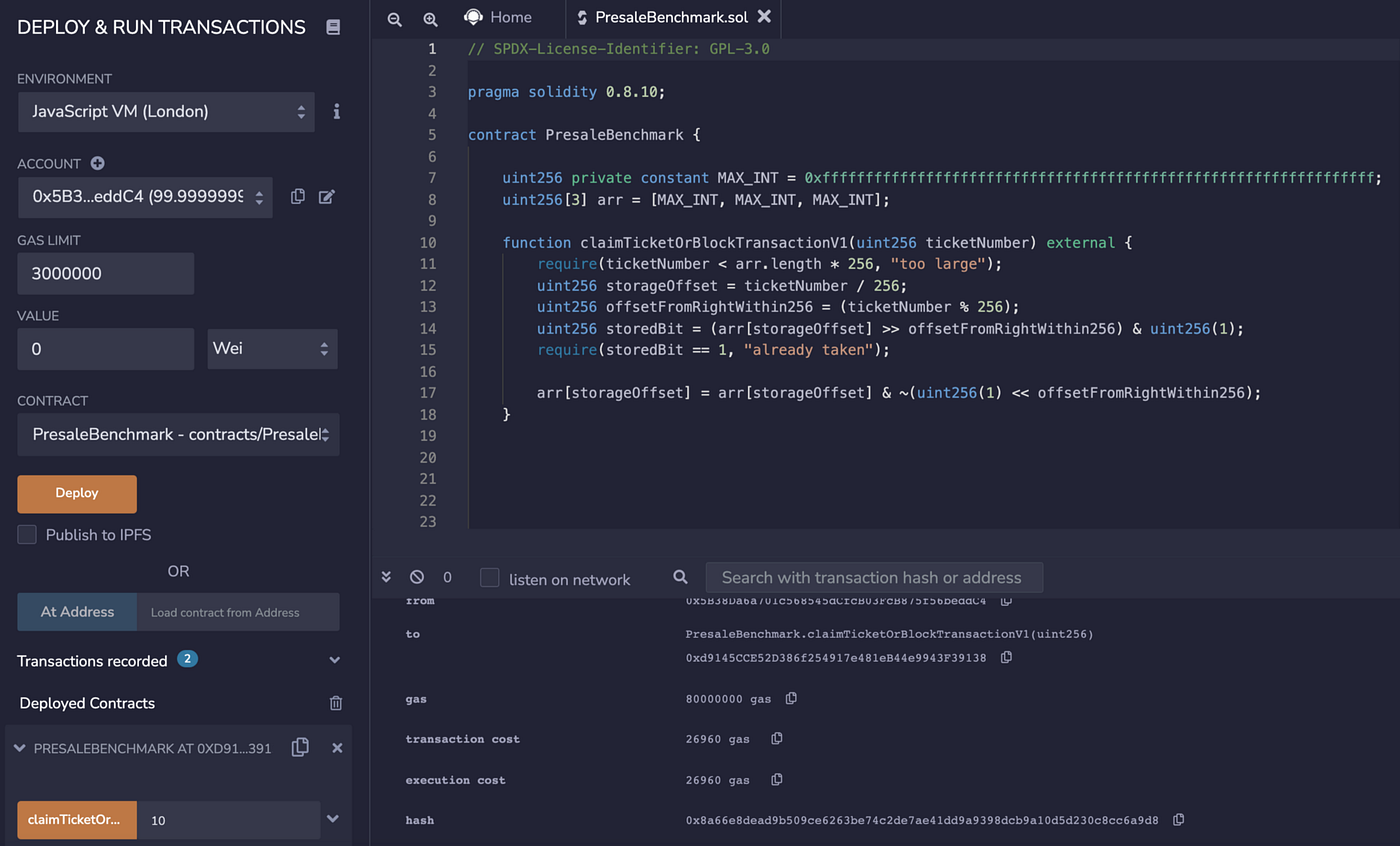
根据remix的数据,这需要花费26,960个gas。
别忘了,我们必须减去从智能合约外调用一个函数所需的21,000个gas。所以我们的成本是由买方支付的5,960个gas。这比20,000 gas有了很大的进步! 还有优化代码的空间,但我想暂时保持代码的简单性,因为有很多东西需要解释!
解释一下
第7、8行
uint256 private constant MAX_INT = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;uint256[3] arr = [MAX_INT, MAX_INT, MAX_INT];
变量arr存储了3组256位,全部设置为1。(如果你觉得很无聊,你可以转换十六进制数字,看看它等于2²⁵⁶减去1)。
这是为了将每个比特设置为1,表示该票还没有被认领。我们任意选择了768张票(3×256)以保持简单。
第11行
require(ticketNumber < arr.length * 256)
检查ticketNumber是否真的包含在我们的位组中。由于这里的数组长度为3,每个槽容纳256位,我们最多可以有768张票(当然如果需要我们可以让数组更长)。
第12和13行
uint256 storageOffset = ticketNumber / 256;
uint256 offsetWithin256 = ticketNumber % 256;
如果收到一个ticketNumber 0–255,就知道它们在数组的第4个槽中。这就是变量storageOffset的作用。比方说,我们正在看票号258。在这种情况下,我们知道我们是在1号槽(中间的槽),以及从末尾开始的第三位(3 % 256 = 3)。因此,对于第258位,storageOffset=1, offsetWithin256=3。
这段代码帮助我们将一长排的1放在正确的位置上。
第14行
storedBit = (arr[storageOffset] >> offsetWithin256) & uint256(1);
查看存储在有关槽中的256位,并将它们向右移动storageOffsetWithin256单位。因此,如果arr[storageOffset]包含000…01000,而我们向右移动3个单位,它将看起来像000…00001。
这就把目标位放在了256比特的最右边。然后我们用000…0001(uint256(1))做一个位运算,将目标位左边的所有位清零。如果移位后的最后一位是1,storeBit将是1,反之亦然。
第15行
require(storageBit == 1, “already taken”);
如果这个位以前没有被使用过,storageBit将等于1,代码将不会被还原。如果该位已经被设置为0,代码将被还原。这可以防止用户重新使用该票。
第16行
arr[storageOffset] = arr[storageOffset] & ~(uint256(1) << offsetWithin256) ;
最后,为了将该位设置为零,我们取000…0001,即uint256(1),并将其向左移动适当的数量。我们想再次翻转票据258,以表示它被认领。所以我们把000…0001左移3个单位,以达到000…01000。然后,我们用~做一个比特翻转,将掩码变成111…10111。通过对存储变量做位的&,我们将把零所在的位置的位清零,其他的位保持不变。
预售代码中看起来如何?
function presale(
bytes calldata signature, uint256 ticketNumber) external payable {
// ... other require statements
require(verifySig(msg.sender, ticketNumber, signature)); claimTicketOrBlockTransaction(ticketNumber, msg.sender);
_mint(msg.sender, totalSupply());
}
同样,为了清楚起见,我们跳过优化。
对于5,000个预售,你可以想象,我们有5,000个签名。如果有人想申请他们的预售,他们的地址从metamask与他们在网络应用中的一张票相匹配,以找到他们的签名,该签名与ticketNumber一起被发送到函数presale中。
在verifySig中,我们验证该签名是否真的签署了msg.sender和ticketNumber的组合。然后,我们通过将位设置为零,然后铸币来索取ticketNumber。
诚然,这是个稍显复杂的方法。但这是否值得大量的节约呢?我想是的。孤立地看,复杂性是不可取的。复杂性是相对的,不是绝对的。
请记住,如果你想限制一个用户在预售期间购买多少NFT,你必须在某个地方跟踪它。
如果所有的预售分配都是平等的,那么捷径是什么?
值得注意的是,Azuki NFT有一个聪明的解决方案,在ERC721内balanceOf的同一槽中,将迄今为止的铸币量作为一个128位的数字存储起来(代码在此,文件4的第366行)。在造币过程中,当balanceOf被增加时,用户到目前为止的造币数量也会在同一个槽中被更新(记住,两个uint128变量可以放在同一个uint256槽中)。如果每个人都有相同的预售限额,这是一个非常好的解决方案。然而,如果每个地址的预售限额发生了变化,你将需要把它储存在某个地方,而且你将再次回到不得不更新一个可能相当大的映射的状态。如果你的预售对每个地址有一个固定的数量,他们的解决方案将更容易实现。
我们能做得更好吗?
基本的想法已经到位了。对于那些对以太坊虚拟机的内部运作不感兴趣的人来说,可以随意略过直接看结论。但对于那些喜欢打磨东西的人来说…

让我们来看看我们可以调整的东西(这是第一部分的回顾)。
contract PresaleBenchmark {
uint256 private constant MAX_INT = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;
uint256[3] arr = [MAX_INT, MAX_INT, MAX_INT];
function claimTicketOrBlockTransaction(uint256 ticketNumber) external {
require(ticketNumber < arr.length * 256, "too large");
uint256 storageOffset = ticketNumber / 256;
uint256 offsetWithin256 = ticketNumber % 256;
uint256 storedBit = (arr[storageOffset] >> offsetWithin256) & uint256(1);
require(storedBit == 1, "already taken");
arr[storageOffset] = arr[storageOffset] & ~(uint256(1) << offsetWithin256);
}
}
arr[storageOffset]从存储空间中被读取两次require语句已经保护我们不受整数溢出的影响,所以我们可以把数学放在一个unchecked的块内
这是新的结果:
function claimTicketOrBlockTransactionV2(uint256 ticketNumber) external {
require(ticketNumber < arr.length * 256, "bad ticket");
uint256 storageOffset;
uint256 offsetWithin256;
uint256 localGroup;
uint256 storedBit;
unchecked {
storageOffset = ticketNumber / 256;
offsetWithin256 = ticketNumber % 256;
}
localGroup = arr[storageOffset];
storedBit = (localGroup >> offsetWithin256) & uint256(1);
require(storedBit == 1, "already claimed");
localGroup = localGroup & ~(uint256(1) << offsetWithin256);
arr[storageOffset] = localGroup;
}
Gas cost: 26,740
Execution - transaction cost (21,000): 5,740
这比上次测试节省了220个gas,但仍有更多空间。
对Solidi存储的另一次深入研究
我们已经讨论了存储gas成本如何取决于我们是否将一个值从零设置为非零和非零设置为非零。我们现在讨论一下我们之前的数组是如何实际得到存储的。
阅读关于EVM存储布局的文档是有用的:但我要在这里总结一下关键点。每个智能合约将固定大小的存储值保存在一连串的32字节槽中。想象一下,我们有一个这样的合约:
contract Storage {
uint256 public var1; // sits in storage slot 0
uint256 public var2; // sits in storage slot 1
uint128 public var3; // sits in storage slot 2 with offset 0
uint128 public var4; // sits in storage slot 2 with offset 1
uint256[3] = [1,1,1] // takes up slots 3, 4, and 5
}
256位相当于32个字节,所以var1和var2占用了整个存储槽。var3和var4都在槽2里,因为两个128位的数字都可以放在一个256位的槽里。
使用汇编
大多数时候,Solidity 编译器是相当聪明的,使用汇编不会省gas。然而,在这种情况下,我们实际上可以节省一点。
说句冒犯的话(对不起!),如果你不是百分之百地适应使用汇编,而且你没有对代码进行过健壮的测试,请不要在生产中使用它!汇编给了你更多的机会,让你在不知不觉中产生奇效。尽管如此,我还是保留了这一节,因为我认为它很有趣,而且我相信有些人将会从中受益。汇编并不邪恶。只是在正确的情况下使用的一种工具。
从技术上讲,我们在这里不需要数组,因为我们所关心的只是连续存储槽中的位。让我们来做几个小技巧:
- 与其使用一个增加管理开销的数组,不如使用一个丑陋但更有效的
uint256序列。由于数组的长度在本质上是硬编码的,除了没有数组的记录功能,在其他功能上没有任何改变。我们基本上想要一连串的762个比特被设置为1,虽然一个数组可以完成这个任务,但是一个最大值的uint256序列可以用更少的开销完成这个任务。 - 由于我们对比特列表进行了硬编码,验证
ticketNumber是否过大的要求也可以进行硬编码。这也节省了arr.length的一些开销。 - 与其用
storageOffset对数组进行索引,我们不如用assembly获得第一个变量的槽,并将storageOffset加到这个槽中,这样我们就可以在正确的槽中着陆。然后我们将sload这个变量,就像我们加载一个普通的256位存储槽一样。 - 下面是插入remix的代码
uint256 private constant MAX_INT = 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff;
uint256 private ticketGroup0 = MAX_INT;
uint256 private ticketGroup1 = MAX_INT;
uint256 private ticketGroup2 = MAX_INT;
uint256 private constant MAX_TICKETS = 3 * 256;
function claimTicketOrBlockTransactionV5(uint256 ticketNumber) external {
require(ticketNumber < MAX_TICKETS, "bad ticket");
uint256 storageSlot; // rename storageOffset to storageSlot to be more clear since we aren't using an array
uint256 offsetWithin256;
uint256 localGroup;
uint256 storedBit;
unchecked {
storageSlot = ticketNumber / 256;
offsetWithin256 = ticketNumber % 256;
}
//solhint-disable-next-line no-inline-assembly
assembly {
storageSlot := add(ticketGroup0.slot, storageSlot) // ticketGroup0.slot is the storage slot, we add storageSlot
localGroup := sload(storageSlot) // load whatever slot we are pointing to into localGroup
}
storedBit = (localGroup >> offsetWithin256) & uint256(1); // same code as before
require(storedBit == 1, "already claimed");
localGroup = localGroup & ~(uint256(1) << offsetWithin256);
//solhint-disable-next-line no-inline-assembly
assembly {
sstore(storageSlot, localGroup) // store localGroup at the original storage slot
}
}
Gas Cost: 26,541
Gas Cost - Transaction Cost (21,000): 5,541
总的来说,这为我们节省了约300个gas,这对一个交易来说并不是很多。但在成千上万的用户中,这实际上是节省了相当多的以太。
而节省的费用是…
这里的基本技巧是,将一个存储槽从0设置为1需要花费20,000个gas,但将存储槽从0设置为256位都是1的数字也是如此。这让我们以1的价格为256个地址分配一个预售。第二个技巧是通过同时签署地址和比特索引(ticketNumber)来创建一个从地址到特定比特索引的隐性映射。
如果我们分配5,000个用户,我们必须将21个存储单元设置为所有的1才能有足够的比特。(21 x 256 = 5,376)。这相当于21杯昂贵的咖啡,这是可以管理的。如果我们用一个映射单独分配给5,000个用户,那就是5,000个这样昂贵的咖啡,相当于一辆新的奔驰车的成本。这些钱要么来自卖家,要么由买家集体支付,但它来自某人的ETH钱包。
结论
在第三部分中,我们一石二鸟:我们有一个机制来查看用户是否在使用公共签名的预售名单上,并且我们使用比特跟踪他们在每个用户的基础上铸造了多少。