
The demand for running complex computations, especially AI inference, directly on decentralized platforms like the AO Computer is growing. Apus Network is tackling this challenge by integrating GPU acceleration into HyperBeam, providing a powerful solution for AO. Critically, this integration ensures deterministic execution, a vital requirement for both the verifiable nature of the AO ecosystem and the predictable outcomes needed for reliable AI applications. This post explores the architecture and technology stack enabling this deterministic GPU capability within HyperBeam.
The Core Framework
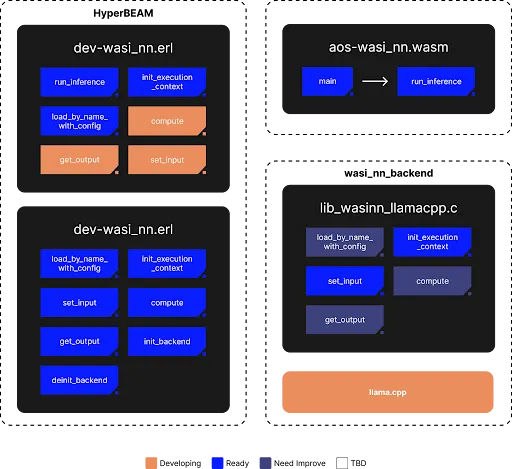
At the heart of HyperBeam's GPU solution lies an integration built around llamacpp. The framework connects the high-level HyperBEAM environment with the low-level GPU hardware through several layers:
-
HyperBEAM
-
dev_wasi_nn.erl: The entry point within the HyperBEAM Erlang environment. -
dev_wasi_nn_nif.erl: An Erlang Native Implemented Function (NIF) that acts as a bridge to C code.
-
-
WASM Module (
aos-wasi-nn.wasm): A WebAssembly module responsible for executing the inference tasks. It interacts with a specific WASI-NN backend. -
WASI-NN Backend (
lib_wasinn_llamacpp.c): This C library implements the WASI-NN standard, translating the calls into operations thatllama.cppcan understand. It handles loading models, initializing execution contexts, setting inputs, computing, and getting outputs. -
Llama.cpp: A key C++ library optimized for running LLM inference efficiently, including support for GPU acceleration via CUDA and guarantee deterministic output.
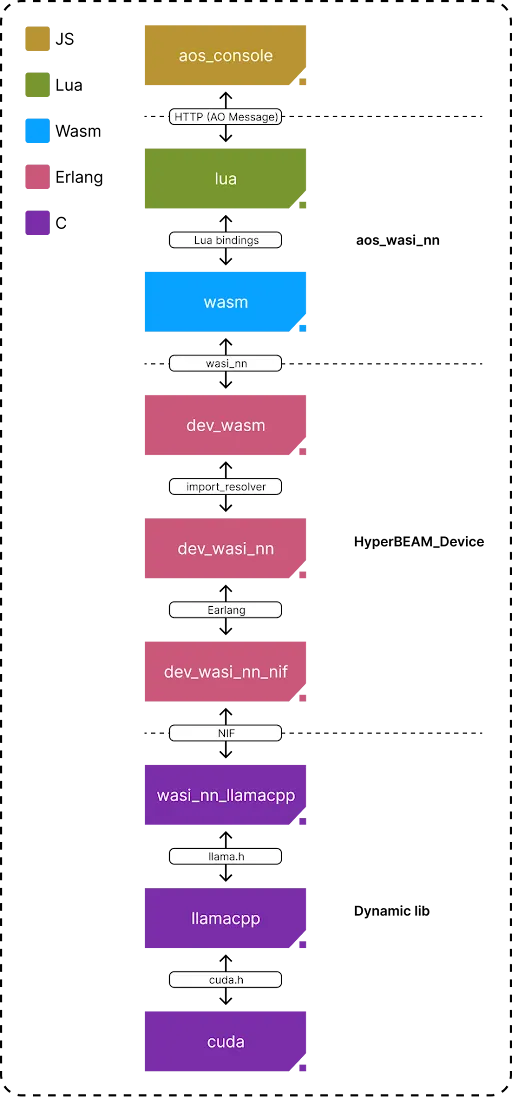
Tracing the Call Layer Path
How does a request travel through this system to reach the GPU? The layer path diagram provides a clear picture:
-
A request might originate from a C or Lua environment, potentially interacting via an HTTP message handled by
aos console. -
This request eventually triggers the
aos-wasi-nnWASM module that compiled Lua into wasm file. -
Then , the execution flows from
dev_wasm(handling WASM execution) todev_wasi_nn(the Erlang WASI-NN interface) by import_resolver , the mechanism that how Hyperbeam call a device . -
dev_wasi_nncalls the NIF (dev_wasi_nn_nif), bridging the gap between Erlang and C. -
The NIF, in turn, invokes functions within the
wasi_nn_llamacppdynamic library compiled by C program which utilizes the llamacpp api interface to interact withllama.cpp. -
Finally,
llama.cpp, which then leverages CUDA to perform the computation on the GPU and return the output back to Hyperbeam.
Key Technologies and Repositories
This solution leverages several important technologies:
-
WASI-NN: a standard way for WebAssembly (Wasm) programs to perform Machine Learning (ML) inference (running pre-trained models) by using the host system's capabilities.
-
Erlang NIFs: Allow efficient interoperability between the BEAM (Erlang VM) and native code (C/C++).
-
Llama.cpp: Offers high-performance inference for large language models, crucially with GPU support.
The core components are available in the following repositories:
-
aos-wasi-nn: Integrates the
aossystem with WASI-NN. (Link: https://github.com/apuslabs/aos-wasi-nn) -
HyperBEAM (dev_wasi_nn branch): Contains the GPU extension part, specifically the
dev_wasi_nnErlang module. (Link: https://github.com/apuslabs/HyperBEAM/tree/feat/dev_wasi_nn) -
wasi-nn-backend: Implements the NIF layer that calls
llama.cpp. (Link: https://github.com/apuslabs/wasi_nn_backend)
Run LLM example
-
Hyperbeam basic knowledge Background
- if you are still not familiar with Hyperbeam project, device concepts . please refer to our previous tutorial article https://mirror.xyz/0xE84A501212d68Ec386CAdAA91AF70D8dAF795C72/iLNw4j49tiB7XUE6EUayuFXUvdXnG-USTUBjK0HUH9c
-
Run unit test in
dev_wasi_nn_nifwasi_nn_exec_test() -> Init = generate_wasi_nn_stack("test/wasi-nn.wasm", <<"lib_main">>, []), Instance = hb_private:get(<<"wasm/instance">>, Init, #{}), {ok, StateRes} = hb_converge:resolve(Init, <<"compute">>, #{}), [Ptr] = hb_converge:get(<<"results/wasm/output">>, StateRes), {ok, Output} = hb_beamr_io:read_string(Instance, Ptr), ?event({wasm_output, Output}), ?assertNotEqual(<<"">>, Output). -
Got result from llama backend
Let’s Test It - The Simple Way!
We are going to interact with the qwen 2.5 7B q2_k model using the wasi-nn device on HyperBEAM!
- Check out our HyperBEAM node:
2. Run inference!
3. Change the prompt at the end of the URL “prompt=who%20are%20you”
Examples:
prompt=how%20do%20you%20work
prompt=what%20is%20arweave

4. Enjoy deterministic AI inference on HyperBEAM!
Conclusion
Apus Network's HyperBeam GPU device solution presents a well-architected approach to bringing GPU-accelerated AI inference to AO ecosystem. By leveraging WebAssembly, llamacpp, and efficient native code integration via Erlang NIFs, they have created a pathway to harness the power of libraries like llama.cpp and CUDA within the HyperBeam environment. This opens up exciting possibilities for running demanding AI workloads directly within the HyperBeam in AO .