作者:Samehada
时间:2023/03/18
文章: 《IPFS - Content Addressed, Versioned, P2P File System》
版权声明:文章采用 BY-NC-SA 许可协议,转载请注明出处!
前言
今天,我们要阅读的是一篇白皮书。这是一个非常有名的去中心化项目—IPFS 星际文件系统,该白皮书于2014年7月发布,此时IPFS项目还没有上线,其中许多内容都尚且是技术构想阶段。虽然目前最新的IPFS技术规范有一些更新,但总体设计和白皮书的内容是基本一致的。
这里简单介绍一下白皮书作者Juan Bennet,他毕业于斯坦福大学的计算机科学专业。低调的胡安并不像中本聪,V神那样被世人所熟知,但他所创建的IPFS在这几年确实风头很劲,很多人知道IPFS,但是对胡安一无所知,这也很正常,主要因为IPFS或者说IPFS所成就的分布式存储可能成为区块链未来发展的重要支撑。
2014年5月胡安就自己成立了公司,起名协议实验室,并且在当年夏天得到了YC的资助,这个YC就是全球著名的创业孵化器,投资了非常非常多优秀的早期创业项目。现在在中国YC掌舵的正是百度前COO陆奇。在胡安拿到投资之后,开始对IPFS、LIBP2P以及其他项目的进行开发。
0️⃣摘要
首先,Juan对IPFS进行了定义——一个点对点的分布式文件系统,旨在用同一个文件系统连接所有的计算设备。
随后,Juan称,在某些方面,IPFS对标于WEB互联网,但更像是单一的BitTorrent集群,使用Git作文件存储和数据交换。换句话说,IPFS使用基于内容寻址的超链接,提供了一个高吞吐量的、基于内容寻址的块存储模型。这种模型构成了一个广义的Merkle DAG(Directed Acyclic Graph,有向无环图)数据结构,可用来构建版本控制文件系统、区块链甚至永恒的互联网体系。IPFS整合了三大技术,分布式哈希表、带有奖励机制的块交换协议和自认证的命名系统。IPFS还解决了单点故障问题,可在节点无需相互信任的情况下正常运行。
1️⃣概述
第一段,Juan说已经有很多人尝试构建全球化的分布式文件系统,并列举了学术界和商业界的一些案例。在学术届,AFS获得了比较广泛的成功并至今仍在使用,而能获得如此成功的其他产品则寥寥无几。在商业界,分布式文件系统主要应用于点对点文件共享,尤其是音视频的共享。并列举了Napster、KaZaA和BitTorrent这些分布式文件应用
这些分布式文件应用承载了上亿的用户规模,至今,BitTorrent仍保持着上千万的活跃节点。 但是Juan认为这些商业系统虽然用户量很大,但是都在应用层。这些软件没有专注于底层协议框架以便于基于基础设施进行开发,没能实现全球开发者共享这些商业系统的分布式和低延迟的优势。
HTTP协议,作为互联网传输文件的公认标准,在大多数场景下已经足够成功。和浏览器伴生,HTTP协议已经积攒了很强的技术和社会声望。但是HTTP协议实在是太老了,并没能利用好近十几年出现的优秀的新文件分发技术。这些新技术与HTTP协议难以兼容,并且许多相关方都在现有的HTTP模型上有很多投资,所以WEB网络的发展陷入了停滞。但是从另一个角度,HTTP协议之后许多优秀的新协议出现并得到了广泛使用,这是令人兴奋的。目前所需要升级的是:在不降低用户体验的情况下引入新的文件分发技术,从而加强如今的HTTP的网络。
第二段,Juan谈到HTTP的成功在于处理小文件的表现很好,但是目前新网络时代的数据分发有以下5点挑战:
-
托管和分发数据量达到PB(1PB = 1024TB)级别
-
跨组织大数据运算
-
分发海量的高清晰度媒体流
-
海量数据的连接与版本控制
-
防止重要文件丢失
Juan总结说,新时代的数据量激增,“海量数据,无处不在”,这时候Juan团队不再对HTTP协议抱有幻想了,转而努力开发新的数据分发协议。
Many of these can be boiled down to “lots of data, accessible everywhere.”
第三段,Juan说分布式系统要解决的两大问题就是数据同步和版本控制,而Git则是一套非常实用的源码版本控制系统。现在完全可以讲Git技术作为启发,尤其是将它基于内容寻址的Merkle DAG数据模型应用到分布式文件系统中。当然,还需解决高吞吐量和升级WEB网络的问题。
白皮书提出了IPFS:一种点对点的、基于版本控制的文件系统可以解决前面的问题。IPFS的核心原则就是将所有数据作为同一Merkle DAG的一部分来建模。
The central IPFS principle is modeling all data as part of the same Merkle DAG.
2️⃣背景
这一章,Juan回顾了IPFS系统所整合的一系列技术,这些技术对构建一个优秀的点对点系统非常重要。
2.1 分布式哈希表DHT(Distributed Hash Tables)
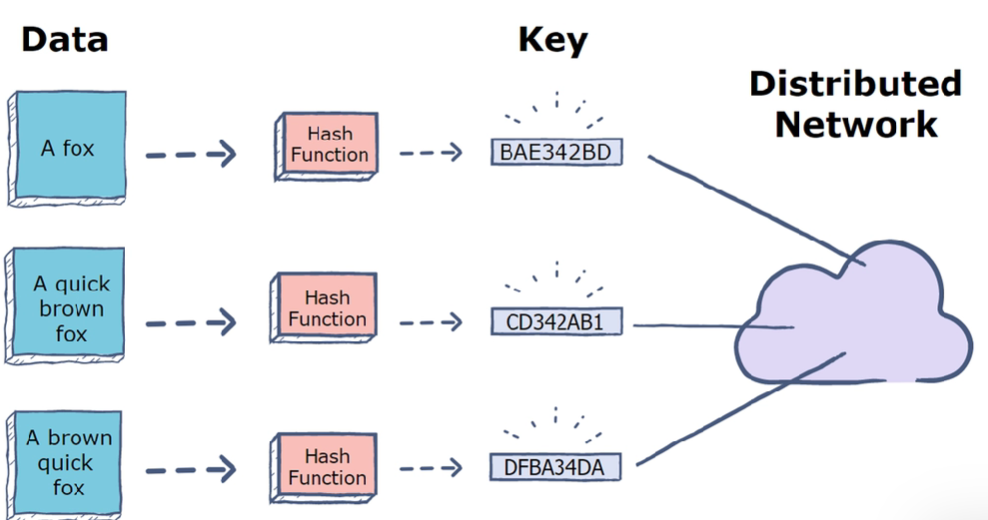
分布式哈希表,即为分散存储在不同位置的哈希表,而哈希表就是存储文件哈希值和文件地址的表结构,一般是结构。DHT在点对点系统中广泛用于存储和同步元数据。下面,Juan介绍了三种DHT应用,分别是 Kademlia,Coral DSHT 和 S/Kademlia。

Kademlia是非常流行的一种DHT算法(简称KAD),在eMule,BitTorrent,Guntella这些软件中都有使用。KAD算法的优点是查询高效(log(n)),同步开销低,抗攻击性强,应用广泛。
-
Coral DSHT,是对KAD的改进。在KAD协议中,使用XOR距离,信息永远存储在XOR距离最近的节点中,但是这些节点可能并不需要这些数据,这样会浪费存储和带宽资源。所以Coral将地址存储在可以提供数据的节点上,放宽了get_value(key)函数,改成了get_any_values(key),将DSHT根据位置和大小分成不同的cluster,优先查询低延时的节点。
-
S/KAD算法扩展了KAD来防止恶意的攻击。首先,它通过一些机制生成NodeId防止女巫攻击。第二,S/KAD算法的节点在不相交的路径上查找值,即使网络中存在一般不诚实节点也能达到85%的成功率。
2.2 块交换技术
BigTorrent是一个广泛应用的P2P文件共享系统,它的一些特性给IPFS带来了3点启发:
-
BitTorrent的数据交换协议使用了一种针锋相对的激励策略,奖励多做贡献的节点,惩罚只会索取资源的节点。
-
BitTorrent追踪文件片段的有效性,优先传输稀有资源。
-
对于一些消耗带宽的共享策略,BitTorrent的tit-for-tat策略表现脆弱,而PropShare表现非常好。
2.3 版本控制系统-Git
Git是当前最流行的文件版本控制系统,它可以对文件内容的更新进行建模和分发。Git提供了一种强大的Merkle DAG对象模型,可以将文件版本更新记录在文件树中,同时对分布式环境也非常友好。Juan列举了Git的6种特性:
-
模型中有3种对象:文件、目录和commit更新
-
基于对象内容的哈希来寻址
-
对象之间的链接是嵌入式的,形成有向无环图 DAG
-
大部分版本化的元数据基于指针引用,创建和更新资源更高效
-
版本变化只需要更新引用或者增加对象
-
分布式的版本更新只需要传输文件和更新远程引用。
2.4 自认证文件系统
这里提到了SFS实现了分布式信任链和平等共享的全局命名空间。此外,Juan还提到了一种SFS远程文件寻址机制:
# Addressing remote filesystems using the following scheme:
/sfs/<Location>:<HostID>
# where Location is the server network address, and:
HostID = hash(public_key || Location)
3️⃣IPFS模型设计
Juan在第三章提到IPFS融合了DHT,BitTorrent,Git以及SFS等系统的思想。IPFS的贡献就是将这些技术简化、优化和整合,并凝聚成一套更完整优秀的系统。IPFS也具备平台能力供开发者在平台上部署各类应用。IPFS所有的节点都是平等的,没有特殊的节点。这些节点需要在本地存储IPFS对象,并且互相通信和传递数据。
接着,Juan将IPFS协议按照功能划分为7个子协议栈:
-
Identities(身份标识),负责节点的身份生成和身份验证。
-
Network(网络),负责管理节点之间的通信。
-
Routing(路由),负责维护数据寻址的结构。
-
Exchange(交换),建立一种新的数据交换协议(BitSwap)来管理数据块的分发。
-
Objects(对象),采用Merkle DAG连接内容寻址的对象。
-
Files(文件),借鉴了Git的文件版本控制模型。
-
Naming(命名),建立了一种自认证的、可变更的命名系统。
这些子协议最终融合一体,构建整个IPFS模型,下面Juan分别介绍了这7个协议。
3.1 Identities(身份标识)
IPFS使用NodeId标识节点,它是由生成的公钥进行hash后的结果。用户可以在每次启动前,实例化一个新的节点标识。但是系统不鼓励节点经常更新NodeId,因为这样会消耗网络资源。
type NodeId Multihash
type Multihash []byte
// self-describing cryptographic hash digest
type PublicKey []byte
type PrivateKey []byte
// self-describing keys
type Node struct {
NodeId NodeID
PubKey PublicKey
PriKey PrivateKey
}
上面是节点身份标识的数据结构,下面是节点身份生成的生成算法。
// S/Kademlia based IPFS identity generation
difficulty = <integer parameter>
n = Node{}
do {
n.PubKey, n.PrivKey = PKI.genKeyPair()
n.NodeId = hash(n.PubKey)
p = count_preceding_zero_bits(hash(n.NodeId))
} while (p < difficulty)
假设首次连接新节点other时,要判断它的公钥哈希hash(other.PubKey)和NodeId(other.NodeId)是否相等。如果不相等则节点无效,断开连接。
3.2 Network(网络)
IPFS的节点要连接上百个来自整个互联网的其他节点,Juan给出了IPFS网络的5种特性:
-
Transport(数据传输层),IPFS会使用多种传输层写有,这里Juan推荐WebRTC DataChannels和uTP协议。
-
Reliability(可靠性),即便底层网络不可靠,IPFS也可以使用uTP或SCTP来提升可靠性。
-
Connectivity(连接性):IPFS使用ICE NAT穿透技术。
-
Integrity(完整性):IPFS可以通过hash checksum,来校验消息完整性。
-
Authenticity(权限可验证性):通过用发送者的私钥对消息进行数字签名,来验证消息的权限。
在最后,Juan补充了关于节点地址结构的说明。由于IPFS支持多种协议,所以可以应用在多种网络层。这种情况下,IPFS用一种多层地址multiaddr的结构来存储地址数据。
# an SCTP/IPv4 connection
/ip4/10.20.30.40/sctp/1234/
# an SCTP/IPv4 connection proxied over TCP/IPv4
/ip4/5.6.7.8/tcp/5678/ip4/1.2.3.4/sctp/1234/
3.3 Routing(路由)
IPFS需要一个路由系统来查找目标节点,这里用到了基于S/Kademlia和Coral的DSHT技术。IPFS的DHT,就是分布式哈希表,是基于value值的大小区别存储的。如果value比较小,小于1kb,那么直接存在DHT上,如果value比较大,那么DHT上只存储引用,就是能够提供对象内容节点的NodeId。下面是Juan给出的IPFS的DSHT接口设计代码:
type IPFSRouting interface {
FindPeer(node NodeId)
// gets a particular peer’s network address
SetValue(key []bytes, value []bytes)
// stores a small metadata value in DHT
GetValue(key []bytes)
// retrieves small metadata value from DHT
ProvideValue(key Multihash)
// announces this node can serve a large value
FindValuePeers(key Multihash, min int)
// gets a number of peers serving a large value
}
3.4 Block Exchange - BitSwap Protocal(块交换)
IPFS使用的BitSwap协议收到了BitTorrent的启发,通过节点间交换数据完成数据的分发。像BitTorrent一样,每个节点向其他节点下载需要的数据want_list,同时提供已有的数据have_list,用这种方式实现数据交换。与BitTorrent不同的是,BitSwap不局限于一个torrent种子文件中所记录的数据块,它更像一个永久的交易市场,节点可以获取任意想要的数据块,这些数据碎片可能来自不相关的文件。所有节点都要在这个市场交易数据。交易市场的概念往往需要一个流通的虚拟货币支撑,这就需要一个全局账本来记录交易。
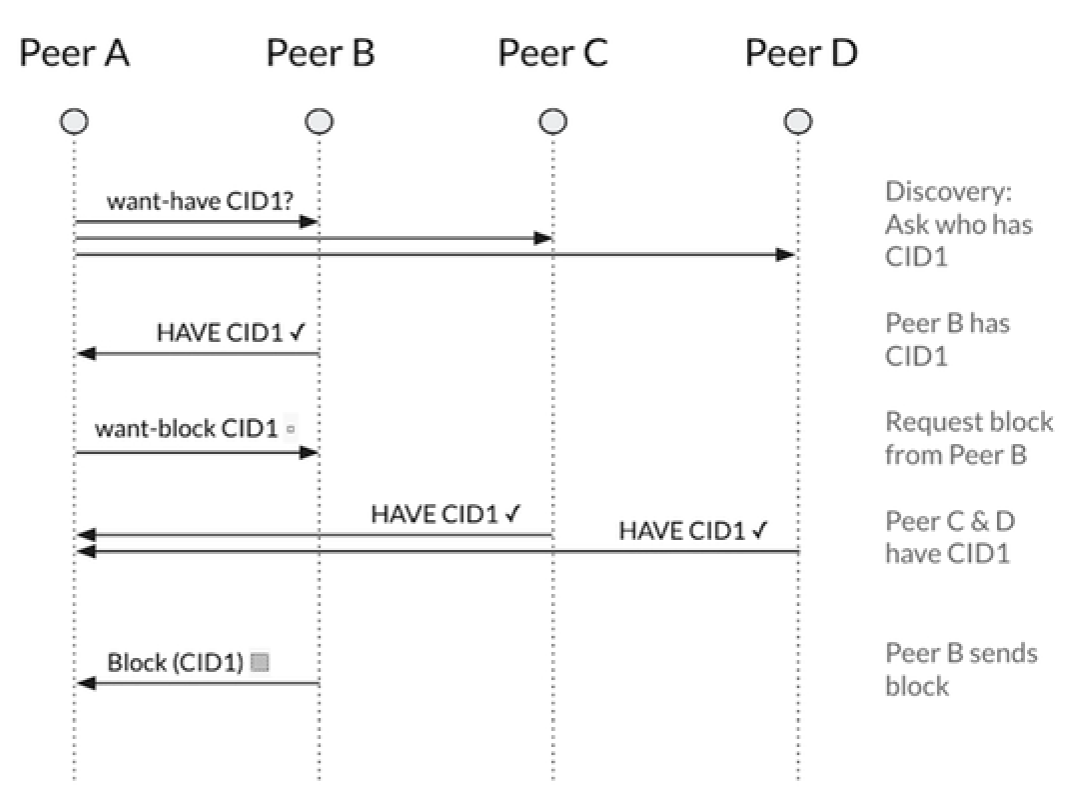
常规情况下,BitSwap节点之间直接能各取所需是最好的。但是,很多情况下,一方拥有对方需要的数据,而另一方没有。那可以,以较低的优先级去获取其他节点需要的数据。这就激励每个节点,能缓存和传播一些冷门的数据,即便并不是该节点所需要的。
下面,Juan介绍了BitSwap信用、策略、账本和规范四部分内容。
3.4.1 BitSwap信用
BitSwap鼓励节点多存储和传播数据,即便自己不需要但是其他节点可能需要。节点乐观地相信,预先付出以后会得到回报,可以后面催其他节点还债。这就可以防止只免费索取不愿分享的节点,可以建立信用系统(credit-like system)来解决这些问题:
-
追踪节点之间相互可用的信用额度。
-
节点给另一个债务节点发送数据的可能性与债务大小成反比。
换句话说,对方欠我数据越多,我想它发送数据的可能性越小,并且设计一个函数来计算这个概率。但如果一个节点不打算理睬另一个节点,可以给出一个ignore_cooldown超时,表达断交的通知。
3.4.2 BitSwap策略
IPFS每个节点可以采用不同的BitSwap策略,不同的策略对块交换的性能会产生很大影响。BitTorrent指定tit-for-tat作为标准默认策略,但也有许多第三方非标准策略,如BitTyrant、BitThief和ProShare。BitSwap节点也应支持多种协议,不论是善意的还是恶意的。Juan给BitSwap的协议提出4点目标:
-
最大化节点和网络的交易性能
-
防止吃白食的负载节点消耗和破坏交易
-
谨慎对待或拒绝使用未知策略的节点
-
宽仁地对待信任的节点
Juan提到实践中,sigmoid函数是一个被证实有效的选择。这个函数可以根据负债率(r)来调节。

发送给负债节点的概率公式如下所示:
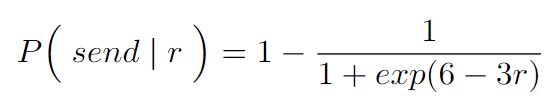
概率曲线如下所示:
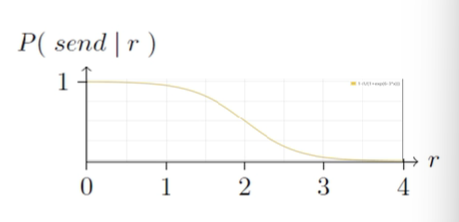
这种策略对长期交易的节点宽松,对未知节点严格,这样有几点好处:
-
抵制攻击者创建大量新节点发起女巫攻击
-
对长期合作的节点,即便偶尔不稳定也能维持友好关系
-
不跟表现恶劣的节点合作,知道对方有所改变
3.4.3 BitSwap账本
BitSwap节点保存一个记录与其他节点交易的账本,这样可以追踪历史记录、避免篡改。每建立一次连接,节点之间就要交换账本信息。如果双方的帐对不上,就要创建一个空账本初始化数据,同步给对方。所有不同步的借贷数据就会丢失。当然恶意节点有可能会故意制造这种债务丢失,不过这种数据不匹配的情况,很快就会发现,不会让恶意节点占太多便宜。如果发生次数较多,其他节点就不会再信任它了。
type Ledger struct {
owner NodeId
partner NodeId
bytes_sent int
bytes_recv int
timestamp Timestamp
}
节点可以自由处理自己的账本数据,一般只有新的数据是有用的,无用的数据可以进行垃圾回收。
3.4.4 BitSwap协议规范
下面是BitSwap协议的数据结构,以及节点Peer的数据结构和4个接口:
// Additional state kept
type BitSwap struct {
ledgers map[NodeId]Ledger
// Ledgers known to this node, inc inactive
active map[NodeId]Peer
// currently open connections to other nodes
need_list []Multihash
// checksums of blocks this node needs
have_list []Multihash
// checksums of blocks this node has
}
type Peer struct {
nodeid NodeId
ledger Ledger
// Ledger between the node and this peer
last_seen Timestamp
// timestamp of last received message
want_list []Multihash
// checksums of all blocks wanted by peer
// includes blocks wanted by peer’s peers
}
// Protocol interface:
interface Peer {
open (nodeid :NodeId, ledger :Ledger);
send_want_list (want_list :WantList);
send_block (block :Block) -> (complete :Bool);
close (final :Bool);
}
BitSwap结构的字段包括:当前节点的账本ledger、当前有效连接active,需要的block的校验码need_list,拥有的block的校验码have_list。
Peer结构的字段包括:NodeId,节点与当前peer之间的账本ledger,上一条消息时间last_seen,当前peer节点需要的block数据块校验码want_list,其中包括当前peer的peer所需要的数据块。
Peer协议接口包括:open,send_want_list,send_block,close四个接口。
Peer节点连接有4种声明状态:
-
Open:对方节点请求建立连接并且发送账本
-
Sending:节点间交换需求块列表和数据块
-
Close:节点之间关闭连接
-
Ignored:策略认为该节点可以忽略,返回超时
后面,Juan详细介绍了Peer接口4个函数的流程,这里不再多做赘述。
3.5 Object(对象) Merkle DAG
前面提到的分布式哈希表DHT和块交换协议BitSwap,能够使IPFS构建点对点系统,高效稳定地存储和分发数据,但是这些数据是如何存储的呢?在这一章,Juan介绍IPFS会构建有向无环图Merkle DAG将对象进行连接。
Merkle DAG对IPFS来说,有3种重要特性:
-
内容寻址,所有内容都是由多重哈希校验来唯一标识
-
无法篡改,所有内容都用checksum来验证,数据被篡改,IPFS会检测到
-
有效去重,所有拥有一致内容的对象被IPFS看作同一个对象并只存储一次
IPFS数据格式如下:
type IPFSLink struct {
Name string
// name or alias of this link
Hash Multihash
// cryptographic hash of target
Size int
// total size of target
}
type IPFSObject struct {
links []IPFSLink
// array of links
data []byte
// opaque content data
}
IPFS Merkle DAG 可以很灵活地处理数据,他只需要满足内容索引,以及上面的对象格式。IPFS不会干涉每个应用如何管理自己的数据,或是使用什么数据格式。Juan列举了一些IPFS对象连接表地操作指令:
- 列出一个对象的引用对象。
<object multihash> <object size> <link name>
-
解决了路径查找问题,如foo/bar/baz这样的路径,可以很容易通过link表来遍历。
-
递归遍历所有对象的引用,这就是遍历对象的指令。
> ipfs refs --recursive \
/XLZ1625Jjn7SubMDgEyeaynFuR84ginqvzb
XLLxhdgJcXzLbtsLRL1twCHA2NrURp4H38s
XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x
XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5
XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z
...
3.5.1 Paths
IPFS对象可以通过路径来查找,格式与UNIX文件系统或者WEB路径差不多。Merkle DAG link结构让这种查找非常简单:下面是路径的例子:
# format
/ipfs/<hash-of-object>/<name-path-to-object>
# example
/ipfs/XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x/foo.txt
假设一个对象路径是:/bar/baz,则以下三种方式都可以访问baz:
-
/ipfs//bar/baz
-
/ipfs//baz
-
/ipfs/
3.5.2 本地化存储
IPFS客户端需要一定的本地存储空间,一般存储于磁盘上或者内存种,用来存储一部分对象和原始数据。
3.5.3 对象锁定
IPFS节点可以将对象进行锁定,这样对象就可以一直保存在本地,也可以通过递归,将对象的所有关联对象全部锁定在本地。
3.5.4 发布对象
IPFS是全球化的分布式网络,需要满足海量文件同步工作。通过DHT技术,可以更安全、公平、分布式地分发对象。每个人都有权分发对象,只需要把对象的key,添加到DHT表中,把自己添加成为peer节点,也就是value中,再将路径分享给其他用户,就完成了发布。对象是永远不可变的,如果数据更新版本了,hash也会随之更新。
3.5.5 对象级密码学
IPFS支持对象级的密码学操作,加密或者签名的对象,可以用下面的数据结构:
type EncryptedObject struct {
Object []bytes
// raw object data encrypted
Tag []bytes
// optional tag for encryption groups
}
type SignedObject struct {
Object []bytes
// raw object data signed
Signature []bytes
// hmac signature
PublicKey []multihash
// multihash identifying key
}
对象加密以后,hash发生变化成为了一个新的对象。所谓对象级加密,就是一个父节点对象,可以用一个密钥加密,另一个子对象可以用其他对象加密或者不加密,这即是对象级别的保护。
3.6 Files(文件)
3.5中的对象是相对抽象的数据结构,这一章,Juan在Merkle DAG上定义了四种对象类型。建立了一种可版本化的文件系统:
-
block:大小可变的数据块
-
list:block的集合或者list的集合
-
tree:block、list或者tree的集合
-
commit:tree的版本历史快照
相比于Git模型,IPFS做了一些改进,如增加了总字节数字段(方便快速查询 ),增加了list对象(方便去重大文件)。下图是论文中的Object Merkle DAG样例图:
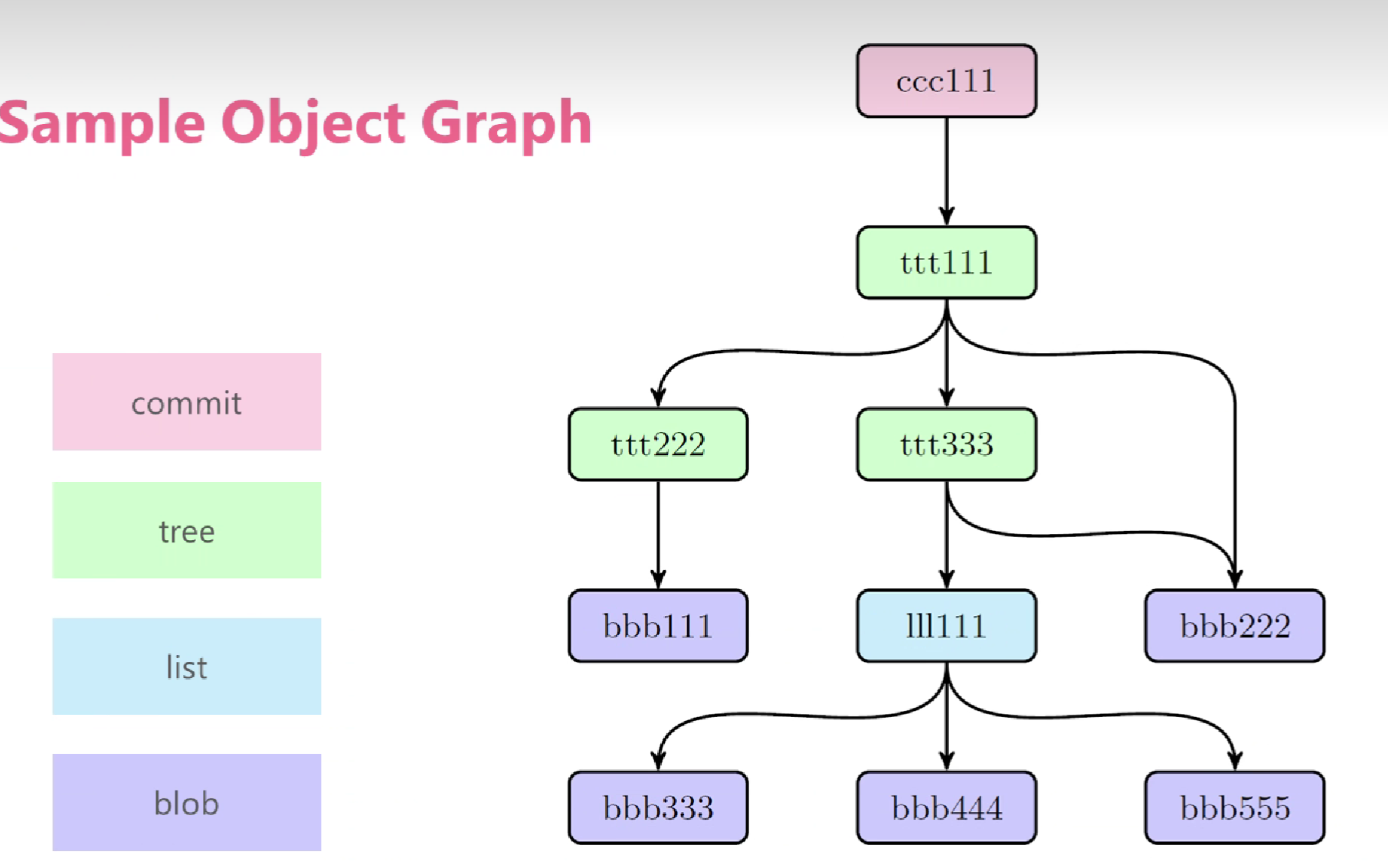
样例图中有4中不同颜色的节点,代表4种不同的对象类型,接下来论文重点介绍这4种类型:
🕛blob对象
blob对象是可寻址的文件数据单元,用来存储文件数据.
{
"data": "some data here",
// blobs have no links
}
这里是blob对象bbb222的数据样例:
> ipfs file-cat <bbb222-hash> --json
{
"data": "blob222 data",
"links": []
}
blob对象没有link字段,它是树的叶节点。IPFS的文件既可以用blob也可以用list。
🕛list对象
list对象一般代表由多个blob组成的大文件,list可以包含blob和list。
🕛tree对象
tree对象和Git一样,代表目录,是一组名称和哈希的映射,下面是tree对象的数据结构:
{
"data": ["blob", "list", "blob"],
// trees have an array of object types as data
"links": [
{ "hash": "XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x",
"name": "less", "size": 189458 },
{ "hash": "XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5",
"name": "script", "size": 19441 },
{ "hash": "XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z",
"name": "template", "size": 5286 }
// trees do have names
]
}
这里的哈希指向连接的blob,list和其它的tree或者commit,下面是ttt111对象的数据结构:
> ipfs file-cat <ttt111-hash> --json
{
"data": ["tree", "tree", "blob"],
"links": [
{ "hash": "<ttt222-hash>",
"name": "ttt222-name", "size": 1234 },
{ "hash": "<ttt333-hash>",
"name": "ttt333-name", "size": 3456 },
{ "hash": "<bbb222-hash>",
"name": "bbb222-name", "size": 22 }
]
}
ttt111对象link了两个tree和一个blob对象。
🕛commit对象
commit对象表示对象的历史版本快照,它可以指向任何类型的对象。下面是commit对象ccc111的数据结构:
{
"data": {
"type": "tree",
"date": "2014-09-20 12:44:06Z",
"message": "This is a commit message."
},
"links": [
{ "hash": "<ccc000-hash>",
"name": "parent", "size": 25309 },
{ "hash": "<ttt111-hash>",
"name": "object", "size": 5198 },
{ "hash": "<aaa111-hash>",
"name": "author", "size": 109 }
]
}
这一章最后,Juan讲了IPFS文件的一些特性。IPFS和Git的对象模型略有差别,但基本兼容。很多Git上的文件管理工具稍加修改也可以用在IPFS上。IPFS文件系统路径的格式和UNIX也是兼容的,tree代表unix目录,commit既可以表示目录也可以隐藏。对于一些大文件的管理和分发,主要的挑战是如何将它们分割成一些独立的数据块,这里Juan刚给了三种大致思路。紧接着Juan谈到了路径查询的新性能问题。通过一个路径去查询数据,要在DHT中找到key,再连接映射的peer节点拉取数据。如果路径比较深,效率可能比较低。Juan提出了两个方案:tree cacheing(树缓存)、flattened trees(扁平树)。
3.7 IPNS: Naming and Mutable State(命名系统)
目前,IPFS系统已经构建了点对点的块交换协议以及基于内容寻址的对象DAG。但目前的系统,发布的对象都是不可变的,这样会有什么问题呢?基于内容寻址很大的问题是,内容一变,之前的地址就失效了。文件都是通过hash来寻址的,但是有一些文件是经常变化的,每变化一次它的连接地址也会发生变化。而且哈希地址这种字符串,对人类识别很不友好,所以希望建立一种当文件变化时,路径可以保持不变的机制,这就是IPNS。
IPFS借鉴了自认命名系统SFS的命名机制:
-
计算node id
-
给每个用户分配一个可变的空间
-
用户可以在路径空间下添加对象,用其私钥签名
-
其他用户找到这个对象后,通过该用户公钥验证是否是其本人发布
IPNS虽然能够帮助重新命名,但长串的hash对用户很不友好,Juan列举了4种技术提升体验:
- 节点链接,Peer Links,通过这种方法可以将其他用户的对象连接到我的对象,当然也要通过权限验证,这就建立了一个可信网络。
# Alice links to bob Bob
ipfs link /<alice-pk-hash>/friends/bob /<bob-pk-hash>
# Eve links to Alice
ipfs link /<eve-pk-hash/friends/alice /<alice-pk-hash>
# Eve also has access to Bob
/<eve-pk-hash/friends/alice/friends/bob
# access Verisign certified domains
/<verisign-pk-hash>/foo.com
- DNS TXT记录,对于一个有效的域名,IPFS要在DNS TXT记录查找,找到对应映射的IPNS路径
# this DNS TXT record
ipfs.benet.ai. TXT "ipfs=XLF2ipQ4jD3U ..."
# behaves as symlink
ln -s /ipns/XLF2ipQ4jD3U /ipns/fs.benet.ai
- 转换成可读的标识符,就是把一些无规则的加密字符串,变成一组可识别的单词
# this proquint phrase
/ipns/dahih-dolij-sozuk-vosah-luvar-fuluh
# will resolve to corresponding
/ipns/KhAwNprxYVxKqpDZ
- 短域名服务
# User can get a link from
/ipns/shorten.er/foobar
# To her own namespace
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm
3.8 Using IPFS(应用)
最后的一小节,Juan列举了12种期望的应用场景,还有3个需要实现的目标 :
-
建立IPFS库,可以导入到开发者的应用程序
-
通过命令行工具直接操作对象
-
实现可挂载的文件系统
4️⃣展望
Juan认为,IPFS沿着前人的成功足迹,结合了许多优秀的分布式系统的思想精华。除了BitSwap是一个新的协议,其他的都是各种现有技术的整合。IPFS有一个伟大的构想,构建分布式的互联网基础设施,并且支持各种应用程序。
