
Your data is being farmed…
“Tumblr and WordPress are reportedly set to strike deals to sell user data to artificial intelligence companies OpenAI and Midjourney” (Will Shanklin, 2024).
“[L]icensing [Reddit] user posts to Google and others for AI projects could bring in $203 million of revenue over the next few year” (David Paresh, 2024).
In response to Web2’s inequitable and extractive model of data monetization, a new wave of Web3 data networks has emerged to redefine data contribution, ownership, and value. These networks introduce what I define as “data assetization,” which uses blockchain technology to convert data into portable digital assets. This enables users to own, aggregate, program, and transact with their data as part of an emerging Web3 data economy.
This article examines the technical design of Web3 data networks, focusing on data assetization, validation, and token-incentivized data contribution models that aim to redefine data ownership and value distribution.
Data Network Design
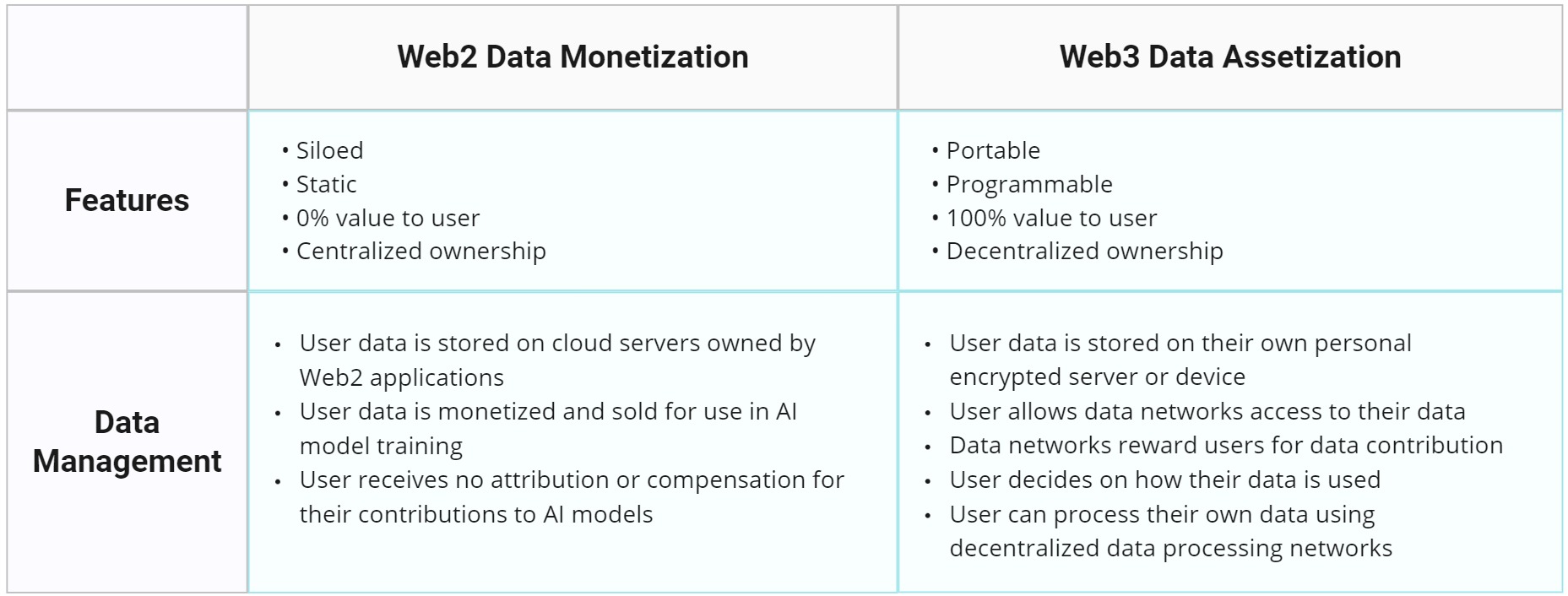
Data networks provide frameworks that enable blockchain-based access control to encrypted off-chain data. They serve as a transparent ledger, recording data transactions and storing metadata, such as data access rights, data properties, encryption keys, and links to data storage locations.
When users contribute their data to data networks, they essentially tokenize their data access rights as transferable units of value. This allows users to grant network validators permission to access, validate, copy, and process their off-chain data.
Data networks provide the basis for a transparent and permissionless data economy, where users can aggregate their data within online communities, train their own models, and exchange data access rights for incentives.
Data Access
How data is accessed and processed is specific to each data network’s design. Here are some examples of how leading data networks manage access control to off-chain data.
Vana provides the framework for users to securely store and maintain custody of their data on their own personal encrypted web servers based on the Solid standard. To contribute data to the Vana network, users allow validators access to their data by sharing their public key. When data is accessed by a validator, it is then encrypted by a validator key. This ensures that user data is always encrypted throughout validation and processing.
Vana is exploring the use of zero-knowledge proofs so that validators can verify user data without the need for decryption.
FractionAI's Off-Chain Storage
FractionAI stores the hash of each data sample, as well as data contribution and verification records, on-chain while keeping the actual data (content and labels) off-chain. This protects user privacy and enables the high storage and throughput necessary for data processing and model training.
FractionAI is currently in testnet. As of now, data contributions are stored on encrypted FractionAI servers. The team is exploring decentralized storage solutions.
AO’s Perpetual Storage and Verifiable Compute
The emergence of AO proposes an interesting possibility for data assetization. AO processes can read and write data stored on Arweave’s perpetual storage network. This opens up the possibility for data stored on Arweave to function as data assets that can be processed by AO smart contracts on-chain. Essentially, AO provides a fluid framework for converting data into programmable units of value supported by verifiable compute and storage.
Data Validation
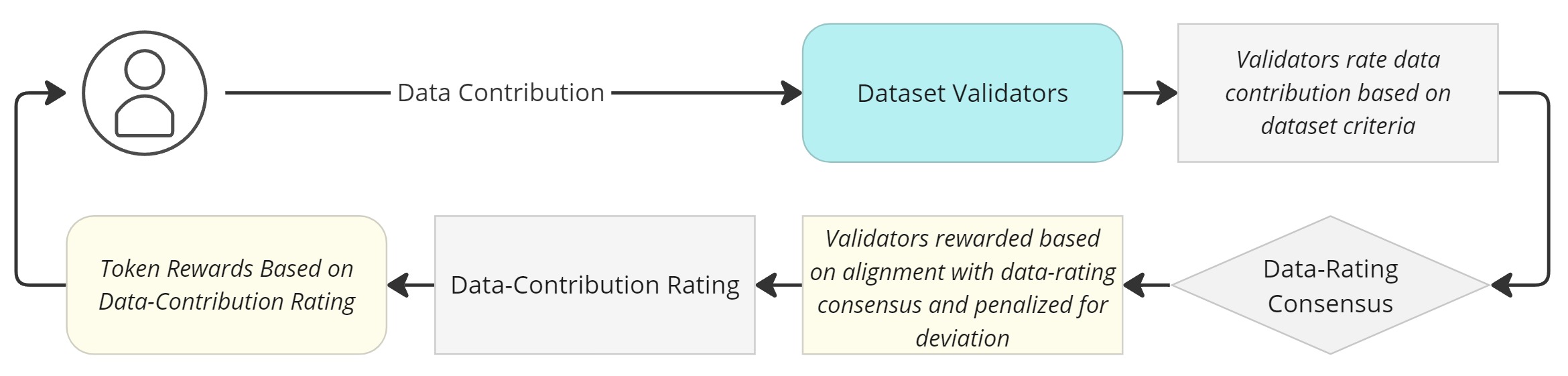
Ensuring data accuracy and quality is crucial for assetizing data and determining its value within a data network. To prevent centralization bias when assessing data quality and value, data networks utilize decentralized validation frameworks. While each network designs its own specific validation framework, most follow the same basic structure:
Dataset or network validators agree upon the value of data submitted to a network dataset based on the criteria set out by the dataset creator. Depending on each network's consensus model and parameters specific to different types of datasets, other factors may influence the validation process, such as stake-weighted voting, where validators' influence is proportional to their staked tokens.
Validation Frameworks
How data is validated is specific to each data network’s design. Here are some examples of data validation frameworks by leading data networks:
Vana's Proof-of-Contribution System
The goal of Vana’s Proof of Contribution (PoC) system is to reward data contributions that impact and improve network datasets and AI models.
-
Data submitted to Vana datasets is rated by validators based on criteria set by the dataset creator. This often includes data completeness, accuracy, and relevance to the dataset's goal.
-
To reach consensus on data ratings, the system averages validator ratings, weighted by each validator's stake in the dataset. This means validators with a higher stake have more influence on the final data rating.
-
This stake-weighted consensus mechanism discourages biased or inaccurate ratings. Validators who deviate significantly from the consensus rating risk having their staked tokens slashed.
Vana's PoC system is based on their proprietary consensus model, Nagoya Consensus, which is a rendition of Bittensor's Yuma Consensus.
FractionAI's Reputation-Based Consensus
Reputation-based consensus functions such that data submitted to FractionAI's network datasets undergoes two passes of verification.
-
The data is initially verified by a pool of AI agents. If accepted, the data then undergoes manual verification by human verifiers, who assess and rate submissions based on criteria set by a dataset creator.
-
Verifiers' ratings are sent to an off-chain judge (presumably a model or algorithm) that calculates a combined score and records it on-chain.
-
This combined score represents the consensus of all verifiers. Verifier reputation is determined by their alignment with the consensus.
-
Verifiers whose rating strongly aligns with the consensus receive an increase in reputation, whereas verifiers whose rating deviates from the consensus receive a decrease in reputation, as deviation indicates potential inaccuracies or biases.
FractionAI’s network rewards are distributed based on reputation rating. Verifiers are incentivized to act honestly to increase their reputation and rewards.
Token-Incentivized Data Contribution
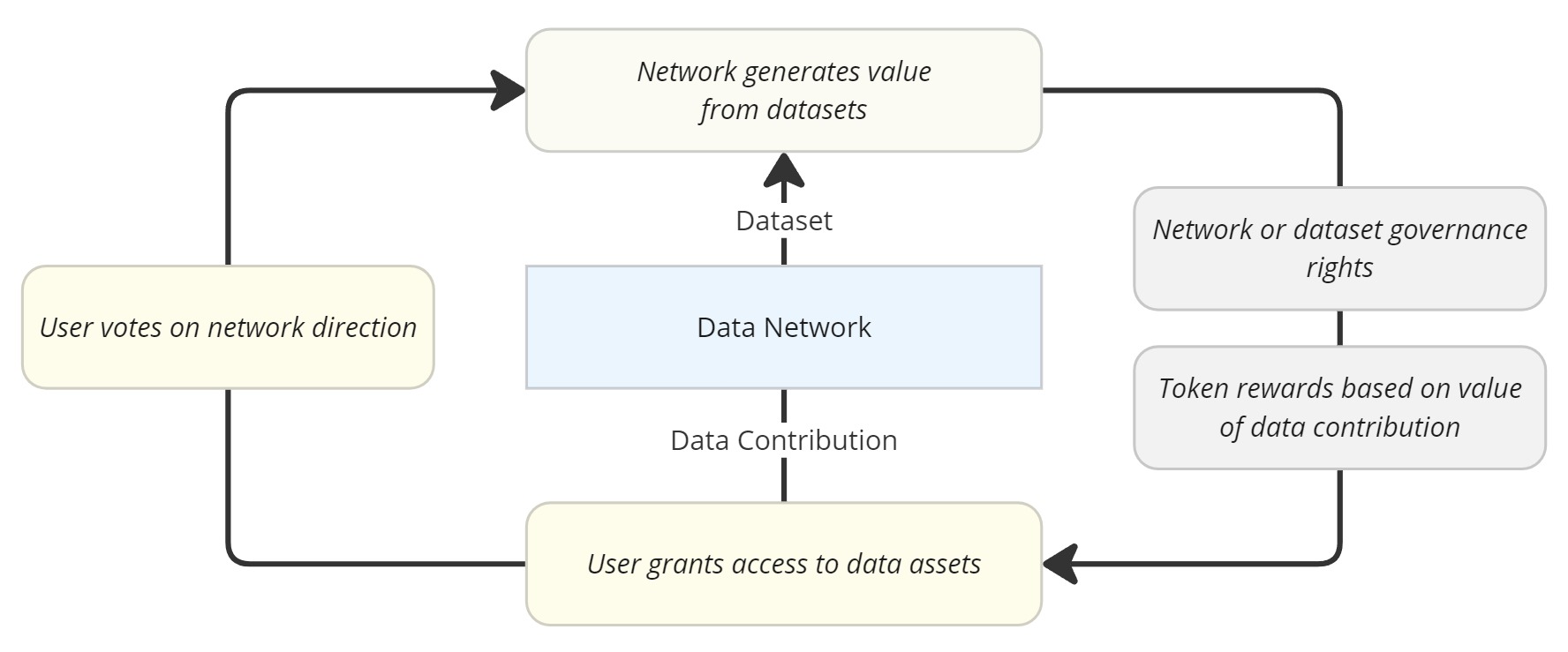
Most data networks use token-incentive models to coordinate network participation and data contribution. While the field of data contribution tokenomics is nascent, several projects are implementing their own unique token-incentivized data contribution models. These incentive models often include:
-
The exchange of user data access control for network or dataset governance tokens;
-
Token staking in exchange for dataset licensing rights and revenue generated by data aggregation or processing; and
-
NFTs representing the data contributions as immutable units of value that can be exchanged in a marketplace.
Data Contribution Projects
The following list highlights some notable projects pioneering token-incentivized data contribution models.
Grass is building a data layer focused on decentralizing public data scraping. When users run a Grass node, they allow Grass access to their IP and unused bandwidth. Grass accesses the user IP and bandwidth to scrape publicly available web data. Users are compensated with network governance tokens for allowing Grass access to their devices.
Grass has plans to build out an entire data ecosystem as an L2, which will include data labeling to verify the attribution of data scraped from websites as metadata stored on the blockchain.
Vana’s Data DAOs introduce coordinated data contribution and dataset governance rights. When users contribute data to a specific Data DAO, they receive governance rights to that DAO.
Here’s how Vana’s Data DAOs function: A Data DAO is created to gather data contributions from LinkedIn users. Vexed by the notion that LinkedIn is profiting from user data, LinkedIn users are motivated to export and pool their LinkedIn data. Users can then vote on how their pooled LinkedIn data will be used: this includes whether it should be sold, with the profits distributed among the DAO members, or used to train user-owned models, which all DAO members can benefit from.
Vana is building an entire ecosystem of Data DAOs that represent proprietary datasets and distinct online communities, such as LinkedIn, Meta, or Reddit.
Rainfall is developing an app that allows users to train their own self-sovereign “personalized agent on [their] phone” by providing access to their data. This incentive structure empowers users to gain value from their data in the form of a personal AI agent.
What makes Rainfall unique is its attempt to integrate edge-AI onto mobile devices. Users can passively contribute data, train their own agents, and then sell access to their data or personal models on Rainfall’s future data marketplace.
While Rainfall has yet to release a white paper outlining the technical details of their application, their concept for self-sovereign AI and edge-AI is innovative.
AminoChain is building a blockchain framework to decentralize biobanking for healthcare institutions. The framework enables biobank entries to be represented as NFTs. This allows biomedical data sample contributors to monitor, grant access rights to, and earn royalties whenever their biomedical data samples are transacted upon.
AminoChain’s model for biomedical data attribution aims to increase donor participation and redistribute some of the scientific upside from profitable research back to the biomedical data contributors.
AminoChain represents one of many examples of innovation within the emerging DeSci ecosystem.

Author’s Note: Data Liquidity Vampire Attacks
If data is a commodity and generative AI increases its capacity to replicate all software applications, vampire attacks on proprietary data silos through the use of marketing and incentives could create a highly competitive data liquidity market.
For example, if users are incentivized to extract their data from Facebook, and generative AI can fork Facebook’s code and UI in a matter of minutes, then what value does Facebook have other than brand recognition? The question then remains, how will incentivized data contribution and data portability affect existing Web2 power structures, and how will these power structures retain users?
Decentralized Data Processing
Processing data contributions is an evolving aspect of many data networks. Projects like Vana and Rainfall aim to enable distributed model training from private servers and mobile devices. This approach includes the potential for edge-AI and federated learning, where user data is processed on edge-AI nodes and remains private, with only AI model weights being shared with the network.
Alternatively, some data networks may offload data processing to separate networks within the DeAI stack. This may involve partnerships or the direct sale of dataset licensing rights. An in-depth analysis of the data processing layer is beyond the scope of this article; however, here are some innovative decentralized data processing solutions:
-
Flock* AI Co-Creation Platform (Federated Learning)*
-
Nillion* Blind Compute (Multi-Party Computation) *
-
Inco* Confidential Computing (Fully Homomorphic Encryption) *
-
AO* Processes (Verifiable Compute)*
-
Bacalhau* Compute over Data (Edge-Based Distributed Computation)*
-
AIOZ* Node V3 Upgrade (Federated Learning)

Will Data Networks Increase Global Data Liquidity?
We are at an inflection point with data, where the world will soon run out of high-quality data necessary for advancing AI development. To address data shortage, we must reimagine our approach to data management and monetization. Data networks challenge Web2 power structures by providing a framework for users to assetize their data into portable and programmable units of value. Although novel, I believe further innovation in data-network design, data validation, and token-incentivized data contribution models will provide solutions for:
-
Democratizing the ownership and value generated by user data;
-
Creating new high-quality datasets; and
-
Increasing global data liquidity.
The Future of Data Contribution
I envision data networks evolving to include mobile devices and distributed IoT hardware nodes that track live environmental and spatial data. Combined with edge-AI AR, and VR, this will enable hyper data-enhanced applications and completely new user experiences.
Additionally, I believe that data contribution will expand into the social realm with real-world MMORPGs that incentivize collective data creation through social quests indistinguishable from normal social engagement.
For my next article, I will explore data-enhanced, new-user-experience-based AI applications.