Nowadays, Web3 startup teams have increasingly complex needs for handling blockchain data and are no longer satisfied with just building dashboards. For example, build machine learning models to serve prediction or recommendation scenarios, run graph analysis algorithms to find abnormal transaction addresses, or provide metrics data for upper-layer business. Whichever of the above methods means one must build a blockchain warehouse based on on-chain data.
But building a stable, easy-to-use blockchain warehouse is no easy task. ethereum-etl and ethereum-etl-airflow are two excellent open-source projects. Users can get full volume data directly through ethereum-etl and build a pipeline of T+1 data through ethereum-etl-airflow. However, having them alone is just half of the story.
Build blockchain warehouse with open-source components
This is a complete data processing pipeline:
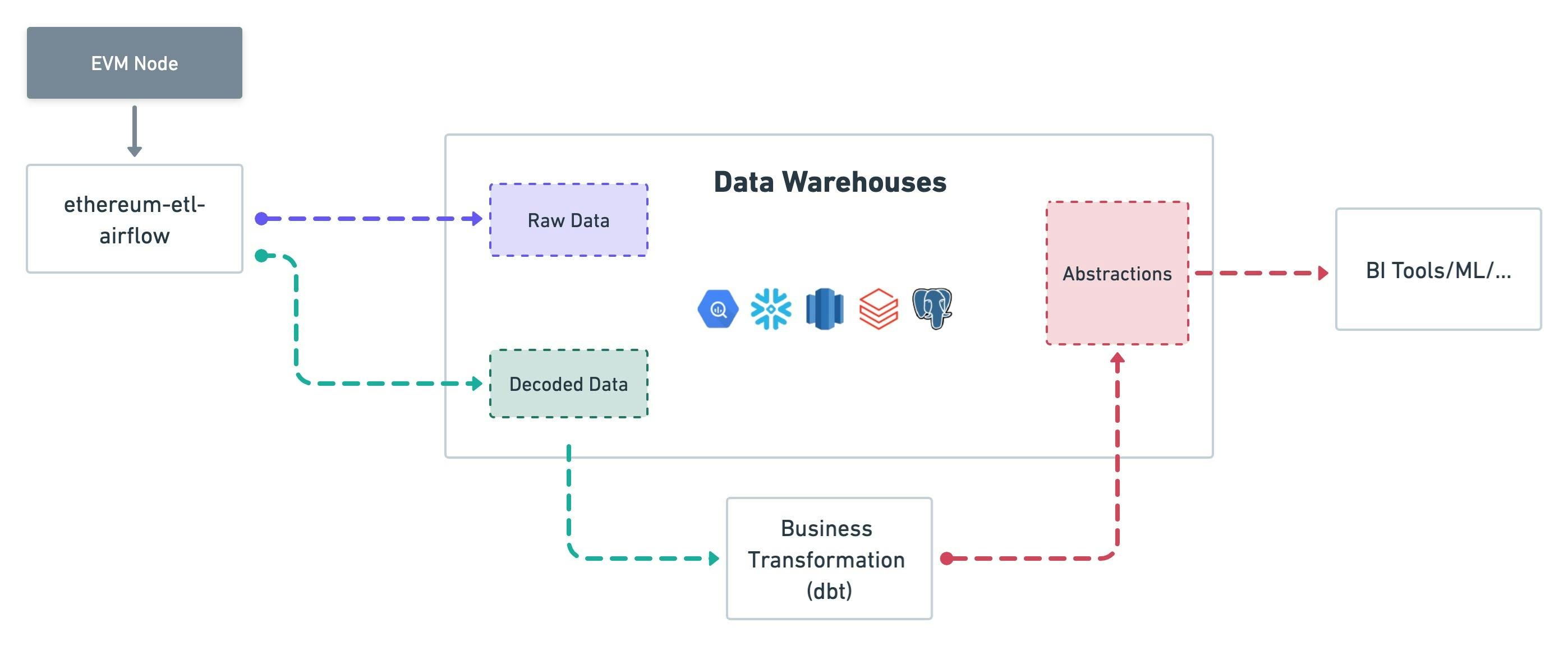
- The user first needs an EVM node with all-history data and access to trace data (which is expensive)
- The data is then regularly synchronized to the data warehouse via
ethereum-etl-airflowand subsequently decodes contracts.ethereum-etl-airflowis an excellent library for most data extract and transformation needs. Still, one huge problem is that it is bound to the compute engine and currently only fully supports BigQuery requirements. So if you're not using Google Cloud, you'll need to re-implement the operator and contract decode logic.- Once the number of contract events/functions that need to be decoded rises to a certain level, it's not easy to keep these tasks scheduled and completed on time. Usually, the pipeline maintainer needs to have sufficient experience in Airflow and Kubernetes.
- Finally, the user will need to have another transform project to translate the activities emitted by the smart contract and model the upper-level business logic.
Build blockchain warehouse with Datawaves ETL
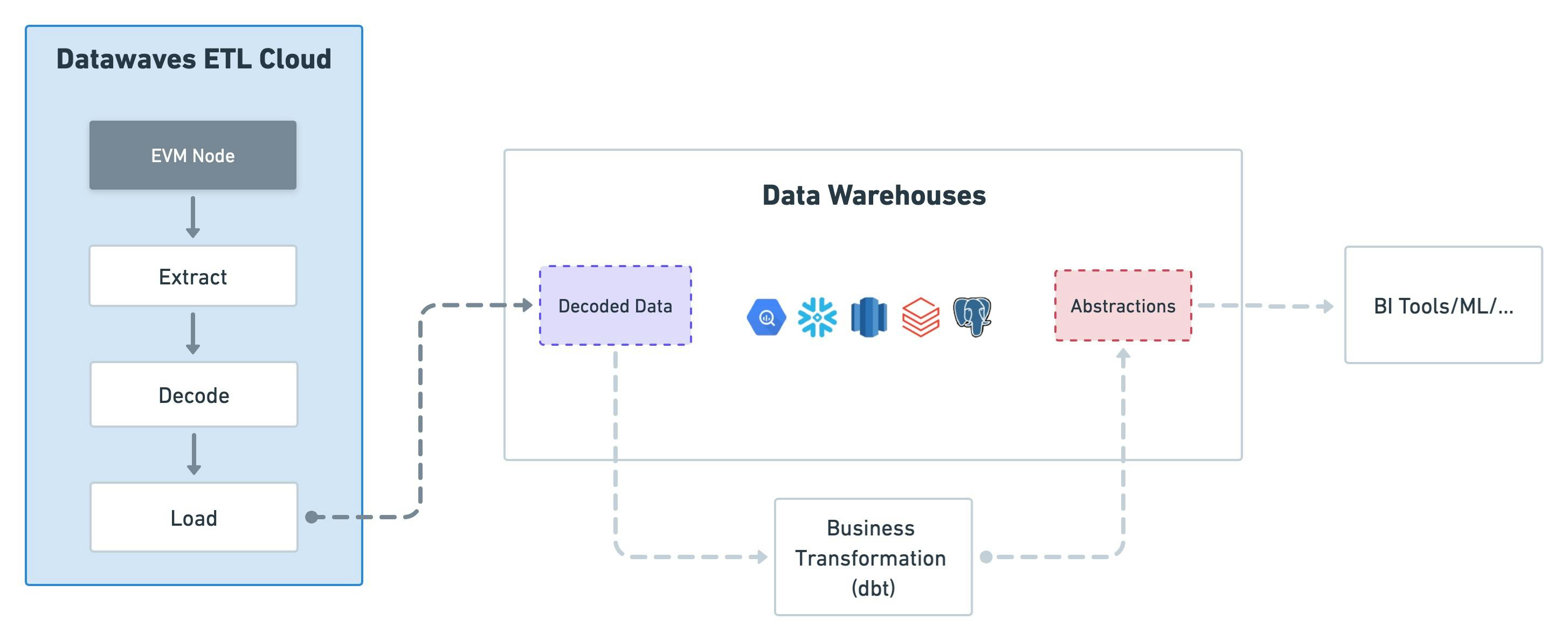
We are building Datawaves ETL, which integrates multiple standardized components to provide the ability to automatically synchronize data into the user's data warehouse, providing directly:
- EVM raw data (e.g.,
transactions,traces,logs, etc.) - decoded contract data (e.g.
erc721_evt_transfer,opensea_WyvernExchangeV2_call_atomicMatch_etc.)
The user only needs to provide the data warehouse connection URL, and cloud file system (e.g., AWS S3) configuration. And then, the cloud server can directly access and transform the data needed by the user into the user's data warehouse or s3 bucket daily and create tables in the data warehouse. It has the following advantages:
- You don't need to buy a node with all history and access to traces data (in QuickNode, this costs $500+/month)
- Extract the total amount of raw data very quickly at a meager cost (in QuickNode, it would be close to $2000+, with a higher machine cost to achieve a similar speed to ours)
- QuickNode charges for the number of requests after the exceeded plan, and there is no batch extracting of traces in the EVM Node interface, so this data is costly to extract.
- Because we already have data compressed using columnar storage, the block file is smaller and has fewer files to be transferred faster.
- Eliminating the need to maintain the underlying data ETL pipeline, which is standardized and tedious, leaving this to a cloud service that devotes more resources to work on the data movement and smart contract decoding, so your team can deliver business insights faster.
- The Airflow that schedules these tasks is cumbersome to maintain, and the more contracts that need to be decoded, the more tasks there are for the entire Airflow. Keeping an Airflow on the Kubernetes cluster with thousands of tasks running can also be a pain.
- Save the type design and namespace design work. We found many types of accuracy issues in building our data warehouse. These experiences are packaged in a complete solution for the user to use, and the user gets clean data that is the easiest to use in its data warehouse.
- Execution speed is essential in contract decoding. When there are thousands of events/functions to decode every day, it is not easy to ensure that the data is ready before the user uses it. Saving time in developing automated contract decoding tools, in the solution, we provide automated contract decoding tools that are 100 times faster than libraries like
web3.py.- We have rewritten the entire decoding process in Java in the Spark engine, enabling a speedup of hundreds of times over the python implementation in high concurrency scenarios.
If you’d like to play with Datawaves ETL, join our waitlist, and ask any questions in Discord.