
My first introduction to the Data Availability(DA) problem was a little over a year ago, I was new to the world of cryptocurrency and just learning the basics of Bitcoin and Ethereum. My experience in researching this topic at the time was quite unpleasant. It seemed like there were too many perspectives and most explanations were half-baked. After multiple attempts at understanding what it was, I still couldn’t visualize the problem. And hence, I resorted to writing this article (as recommended by the Feynman learning technique) in an attempt to crystallize my understanding of the DA problem and help you do the same.
Prerequisites
An understanding of blockchain fundamentals, consensus mechanisms, blocks, transactions, nodes, scaling solutions, Optimistic rollups, and other relevant topics.
Going back to First Principles
Don’t trust, Verify.
Engineers must build upon this principle to ensure the sanctity of blockchain networks as a trustless system is preserved. It assumes the average user to be self-sovereign, where they can verify transactions themselves on their own nodes, Rather than trusting a block scanner. Additionally, they must also ensure whatever solutions or design methods that are proposed, are scalable. When building solutions in the context of scalability and preservation of trust-lessness, we come across a very big obstacle called the Data Availability problem (DA problem)
Scalability is often misunderstood to be a measure of blockchain throughput alone, but I would argue that blockchain scalability can be defined using the following
Scalability = (Throughput * Block Size) / Operational Cost
Where:
-
Throughput - the number of transactions the blockchain network can process per unit of time.
-
Block Size - maximum number of transactions that can be included in a single block of a blockchain
-
Operational Cost represents the cost associated with operating a node in the blockchain network, (computational resources, storage, and energy consumption).
Let’s first visualize a blockchain computing transactions
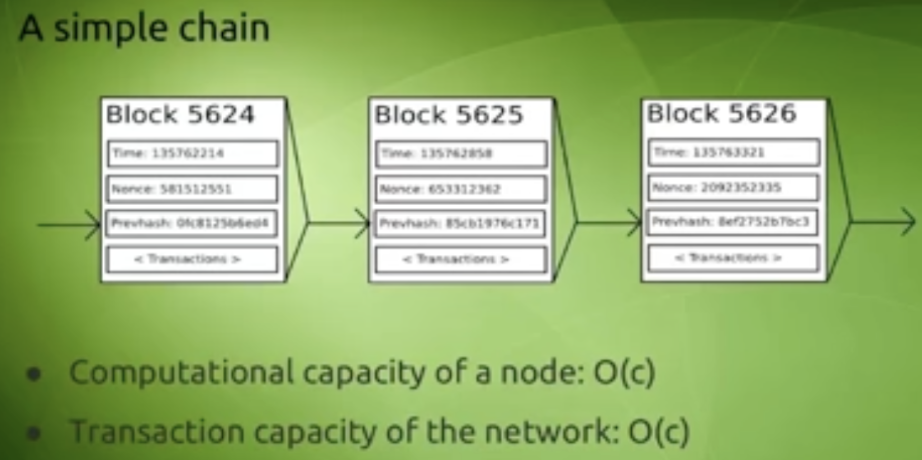
Here, we can assume that all factors of a blockchain that affect the operational cost of a node i.e. number of transactions, storage requirements, bandwidth, no of computations per time interval, etc are proportional and can be represented with c. And accordingly, the computation capacity of a node and transaction capacity of a network is proportional and can be represented in the order of magnitude of c i.e. O(c). This implies that if the transaction capacity of a network is greater than O(c) then one individual can run a full node and the blockchain doesn’t work.
Let’s scale the blockchain
Increase Block-size
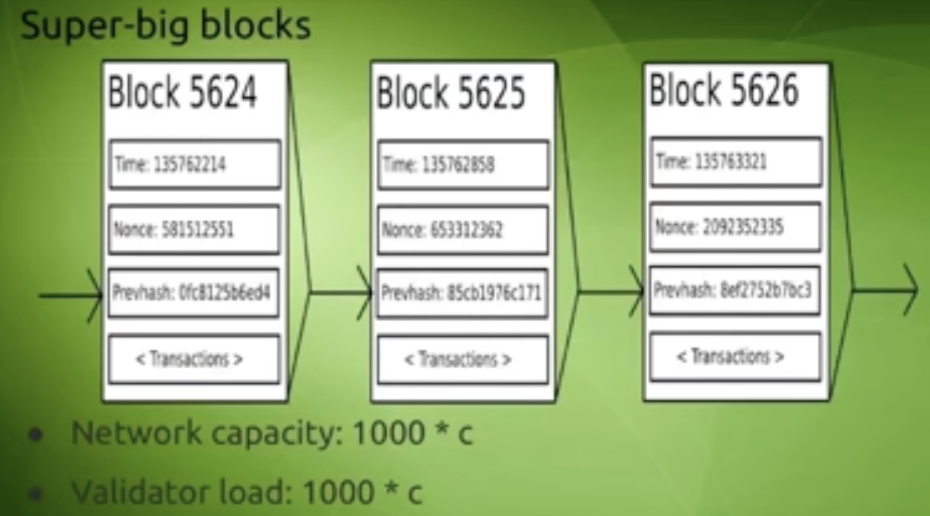
Now if we want to scale these blockchains to include more transactions, then the first approach that comes to mind would be increasing the block size. But this would come with limitations. In the above example, the throughput is up by 1000 and correspondingly the load on each node is also up by 1000. While this would work, this is not what we would want(going back to first principles). Because the only nodes that can process transactions of such magnitudes would be in data centers. We want the average user to have the ability to run a node on a laptop.
Newer Chains
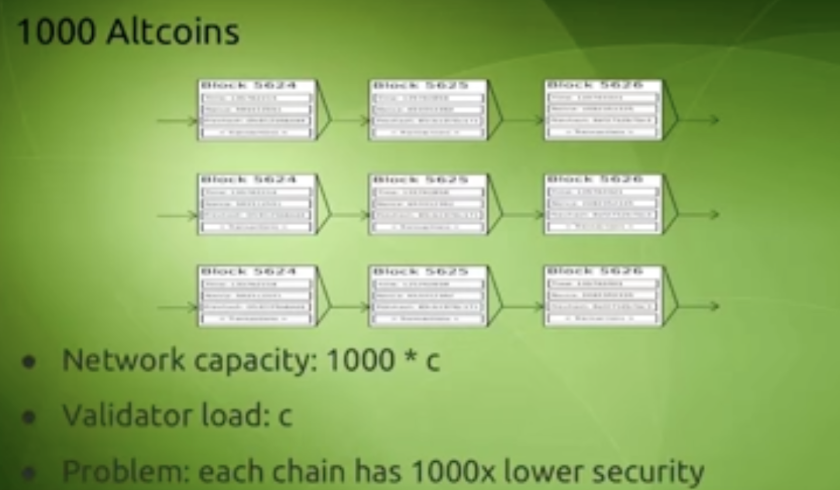
The second most basic approach would then be to move to a newer, cheaper, less congested chain. Technically this can be considered a scaling strategy if we’re still processing 1000x transactions. Here, the load on the node would still remain the same. But the problem is that each chain would eventually get congested(with more adoption) and moving from one chain to the next isn’t sustainable. We would end up in chains like Theranos Chain with a market cap of say $1 million. This would make 51% very affordable.
Now back to the scalability trilemma, which states that each network can only have two out of the three properties (decentralization, scalability & security). We can have Decentralization + Security with the likes of Bitcoin and Ethereum, Scalability + Security with super big blocks and we can have decentralization and scalability with altcoins. To have all three? Very difficult.
This brings us to the most famous strategy to scale Ethereum - rollups and this is where the Data Availability Problem kicks in.
What are Rollups?
In a rollup, transactions happen off the Ethereum chain(execution) and on the rollup chain such as Arbitrum or Optimism. These transactions are then batched(called calldata) and posted on Ethereum where consensus is reached. Thereby, inheriting the security of Ethereum validators while decentralization and scalability are offered by the roll-up chain. For the sake of simplicity let’s focus only on the DA problem wrt Optimistic rollups.
In order to implement a roll-up transaction on Ethereum, the optimistic rollup must implement a system that replays the exact state transitions that were originally executed in the rollup. Optimistic rollups rely on a fraud-proving scheme to detect cases where transactions are not calculated correctly. After a rollup batch is submitted on Ethereum, there's a time window (called a challenging period) during which anyone can challenge the results of a rollup transaction by computing a fraud-proof.
Example of a rollup batch transaction(click).
Light Clients
The ability to run Ethereum nodes on modest hardware is critical for true decentralization. This is because running a node gives users the ability to verify the information by performing cryptographic checks independently rather than trusting a third party to feed them data. A light node is a node running light client software(eg-lodestar/light client). The light node only processes block headers, only occasionally downloading the actual block contents.
In the context of rollups, light clients serve as a bridge between the users and the rollup chain. Instead of requiring users to run a full node and validate all transactions on the rollup chain, light clients provide a lightweight way to access and interact with the rollup. They achieve this by relying on a compact representation of the rollup state, such as transactions bundled in the form of a Merkle tree and submitted as proof (other cryptographic proofs are also possible).
For scalability, ensuring the participation of light nodes in consensus is crucial. But for light nodes to participate in consensus and correspondingly for roll-up techniques to be secure we must overcome the “Data-Availability” problem.
What is the data availability problem?
The data availability problem -
-
Is the need to prove to the whole network that the summarized form of some transaction data(call data) that is being added to the blockchain (from the rollup to Ethereum) represents a set of valid transactions,
-
But doing so without requiring all nodes to download all data. Because the full transaction data is necessary for independently verifying blocks. (requiring all nodes to download all transaction data is a barrier to scaling.)
-
Solutions to the data availability problem aim to provide sufficient assurances that the full transaction data was made available (in some form) for verification and communicated to network participants that do not download and store the data for themselves.
In the context of rollups, it precisely means challenging the submission of an optimistic roll-up via a fraud-proof.
Fraud-Proof
At any point in time, the optimistic rollup’s state (accounts, balances, contract code, etc at a particular time) is organized as a Merkle tree called a “state tree”. The root of this Merkle tree (state root), which references the rollup’s latest state, is hashed and stored in the rollup contract. Every state transition on the chain produces a new rollup state, which an operator(someone who submits blocks to Ethereum) commits to by computing a new state root.

Verifying Blocks
As mentioned earlier, Light clients can be expected to download every single block header(but not the full blockchain state or transaction history). The light client can contain block headers, Merkle tree’s root hashes, a hash of the previous block along with other information. The role of the light client now is to just listen for challenges in the network. It is important to note that the light client does not have any transaction or any portion of the state. However, any such information can be authenticated if the light client is provided with Merkle Branches i.e. the witness data submitted by the challenger.
The possibility of fraud proofs theoretically allows light clients to get a nearly-full-client-equivalent assurance that blocks that the client receives are not fraudulent ("nearly", because the mechanism has the additional requirement that the light client is connected to at least some other honest nodes): if a light client receives a block, then it can ask the network if there are any fraud proofs, and if there are not then after some time the light client can assume that the block is valid.
The incentive structure for fraud proofs is simple:
-
If someone sends an invalid fraud-proof, they lose their entire deposit.
-
If someone sends a valid fraud-proof, the creator of the invalid block loses their entire deposit, and a small portion goes to the fraud-proof creator as a reward.
The Data Unavailability Attack
Data unavailability attacks. A malicious validator publishes a block. The block header is valid but some or all block data is invalid. Ideally, we would assume Fraud Proof to be the solution. But that’s not possible because not publishing data is a fault or error that cannot be directly assigned or linked to a specific entity i.e. it is not a uniquely attributable fault. Alternatively, we can consider zkproofs in the form of ZkStarks or ZkSnarks (a magic way of proving block validity without revealing transactional data). This would still result in some unpleasant consequences.
Consequences of data unavailability attacks-
-
Convince the network to accept invalid blocks
-
Prevent nodes from learning about the state - Even if they prove with zk that the new state root is correct (through the state root hash). Nodes can still not learn about the new state i.e. they cannot learn about the balances of some accounts.
-
Prevent transactions that interact with these accounts and agree on blocks that touch these specific accounts.
To conclude, What is the data availability problem?
-
Incorrectness can be proven, even to a light client
-
But data availability cannot. Because it is not possible to link the fraud to a specific entity. (you can’t say it was this validator and penalize them)
Why is it not possible to link the attack to a specific entity?
Let’s go through two possible cases illustrated in the image below.
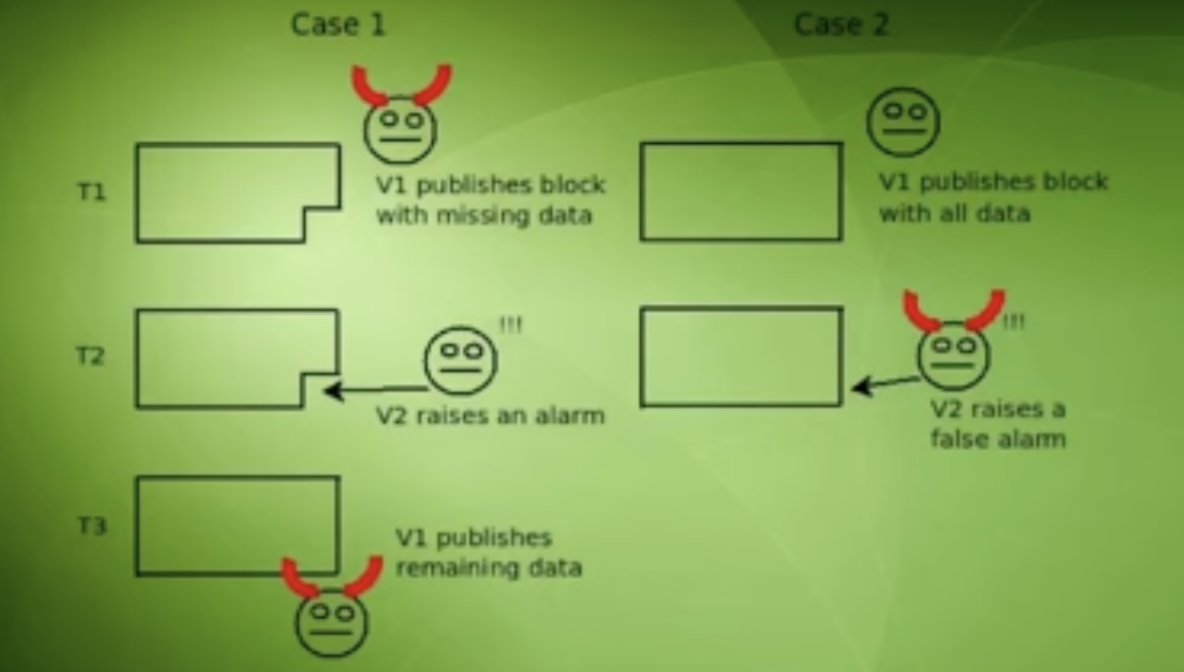
In Case 1, V1 is the attacker
-
At T1, V1 publishes a block with missing data
-
At T2, V2 raises an alarm (eg - as a challenger with a fraud-proof)
-
At T3, V1 publishes the remaining data after seeing the alarm.
In Case 2,
- At T2, V2 raises a false alarm
At T3,
case 1 and case 2 seem completely indistinguishable from each other. As there is a fully published block along with an alarm. Now any client looking at this situation at time T4 has no idea who is at fault. V1 or V2, (Remember we said that this error cannot be linked to a specific entity). This situation brings us to a situation Vitalik call’s the fisherman's dilemma.
Fisherman's Dilemma
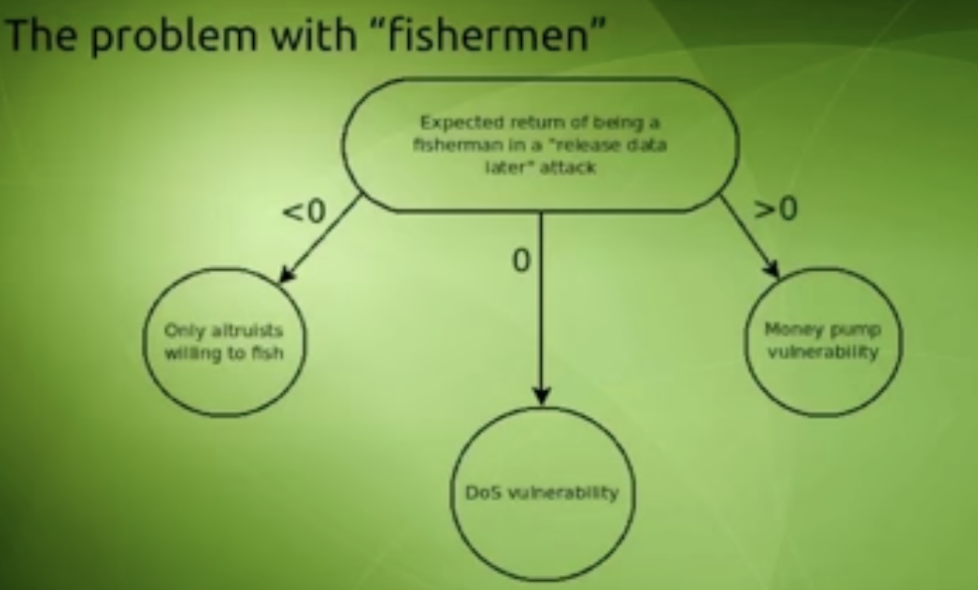
The fisherman here is basically a node, and the dilemma is basically whether should he or should not submit fraud-proof. It basically illustrates the complex trade-offs and uncertainties involved in reporting and challenging the validity of blocks. Recall that not challenging the validity of these blocks would result in some serious consequences.
If Fisherman’s incentive is > 0
Recall that at time T4, both case 1 and case 2 are identical. If there is an incentive (>0 in the figure) for raising an alarm i.e. V2 gets a reward for raising the alarm, we have a money pump vulnerability. Nodes can go on raising false alarms with no penalties
If Fisherman’s incentive is = 0
This is a DOS vulnerability that can be exploited. V2 can raise false alarms and force nodes to download all data in a blockchain and nullify the benefits of light clients, sharding, and scaling solutions.
If the Fisherman’s incentive is < 0
Then raising an alarm is in itself an altruistic act. The attacker now only needs to economically outlast these altruistic fishermen, post which he is free to include blocks with unavailable data.
So what’s the solution?
There are a variety of solutions to how blockchains achieve the data availability problem. While a lot of innovations are still ongoing. At a high level the techniques widely discussed and debated are-
-
Using data availability committees (DAC) within the validator network who can attest to the availability of data
-
Using Data availability sampling (DAS)
-
Or leverage an entirely new layer for Data availability like Celestia.