О проекте с официального сайта:
"Glacier Network создает программируемую, модульную и масштабируемую инфраструктуру блокчейна для хранения, индексирования и запроса данных, расширяя возможности искусственного интеллекта и DePIN.
Glacier расширяет возможности проверяемых вычислений с помощью GlacierDB, GlacierAI и GlacierDA.
Glacier предоставляет ориентированную на данные сеть для беспрепятственной и легкой обработки наборов данных с помощью GlacierDB и GlacierAI поверх Arweave, Filecoin и BNB Greenfield. GlacierDA устраняет необходимость проверки оффчейн и вычисления исполненных состояний GenAI и DePIN."
Аудит
Команда
В wiki есть ссылка на их LinkedIn:

Последний пост 6 месяцев назад, реакций немного...
Люди компании:

Есть только один участник, да и тот без ссылки...
Соцсети
Telegram:

Отвечают на сообщения (даже сегодня), но пока не на моё...
Twitter проекта:

Последний пост 23 часа назад. Подписчиков 128,5 тысяч.
9 мая они опубликовали пост об аэрдропе, и закрепили. У него 315 ответов, 29120 репостов, 5563 лайка (перекос сильный).
Последний пост получил 19 лайков, 20 репостов и 61 лайк.
Пост от 16 мая получил 14 ответов, 26 репостов, 71 лайк.
В общем, активность средняя, но главное - она есть.
Аудит по Tweetscout:

Уровень 3 (High) по ботам, Score 235. Уровень в общем 2 (Noted).
На Glacier подписаны другие проекты: @unstoppableweb, @Galxe, @discoxyz и другие...
Венчурный капитал: Minion, GBV Capital, Ali, Reciprocal Ventures, Signum Capital и другие...
В общем, норм.
Discord:

В анонсах, как видите, последнее сообщение 9 мая.
В основном чате сообщения есть, и недавно тоже, но ответов нет, и много GM:

Но ещё давно: на старте проекта, тестировал функционал, и мне ответили:

(надеюсь видно третий результат поиска).
Есть и тикеты, что удобно.
Medium:

Последний пост 9 мая. Реакции у постов: 219, 5, 1, 1, 8, 1, 1, 4...
В общем, есть.
Итоговая оценка по команде: 3 из 5:
-
Минус балл за отсутствие команды
-
Минус балл за плохую реакцию на сообщения с вопросами
Концепт
-
Интеграции с проектами по распределённому хранению
-
Похож на Mongo DB, что упрощает переход из web2
-
Есть SDK для разработчиков
-
Созданы продукты: база данных и уровень данных векторов для ИИ, БД для других проектов и пользователей
-
Актуально, т. к. альтернатив, по сути, нет, а данные хранить структурировано надо, т. к. не всё стоит пихать в блокчейны.
Итог: оценка 5 из 5.
Коин
По данным Cryptorank, проект собрал 2,9 МЛН $ от Signum Capital, Gate Labs, ForesightX, Cogitent Ventures, UOB Venture, AZA Ventures, Gemhead Capital и Unreal Capital:

На Dropstab та же сумма:

Токеномику не нашёл (минус балл), но есть запущенная программа баллов с указанием тикера. Она прямо кричит о токене ☺!
Инвестиции средние, но проект мало кто использует: конкуренции мало. А проект интересный (СМ. концепт)...
Итог: оценка 4 из 5.
Код
Есть Github проекта:

Список обширный - покажу некоторые...
Glacier-Labs/glacier-playground - основной интерфейс по созданию БД:

Последний коммит на прошлой неделе:

Отображается 1 измененный файл с 1 добавлением и 7 удалениями.
Всего 19 коммитов.
Предыдущий был аж 28 июля 2023:

Отображается 10 измененных файлов с 26 236 добавлениями и 1857 удалениями.
Glacier-Labs/settlement - прувер:

Последний коммит в прошлом месяце, показаны 2 измененных файла с 3 добавлениями и 3 удалениями:

Всего 35 коммитов:

3 было 10 апреля, все - пулл-реквесты, но изменений в коде мало...
До них были 4 апреля коммит и 166 марта...
Изменений везде мало.
Glacier-Labs/glacier-quickstart - инструкции по быстрому старту:

Последний коммит 3 месяца назад:
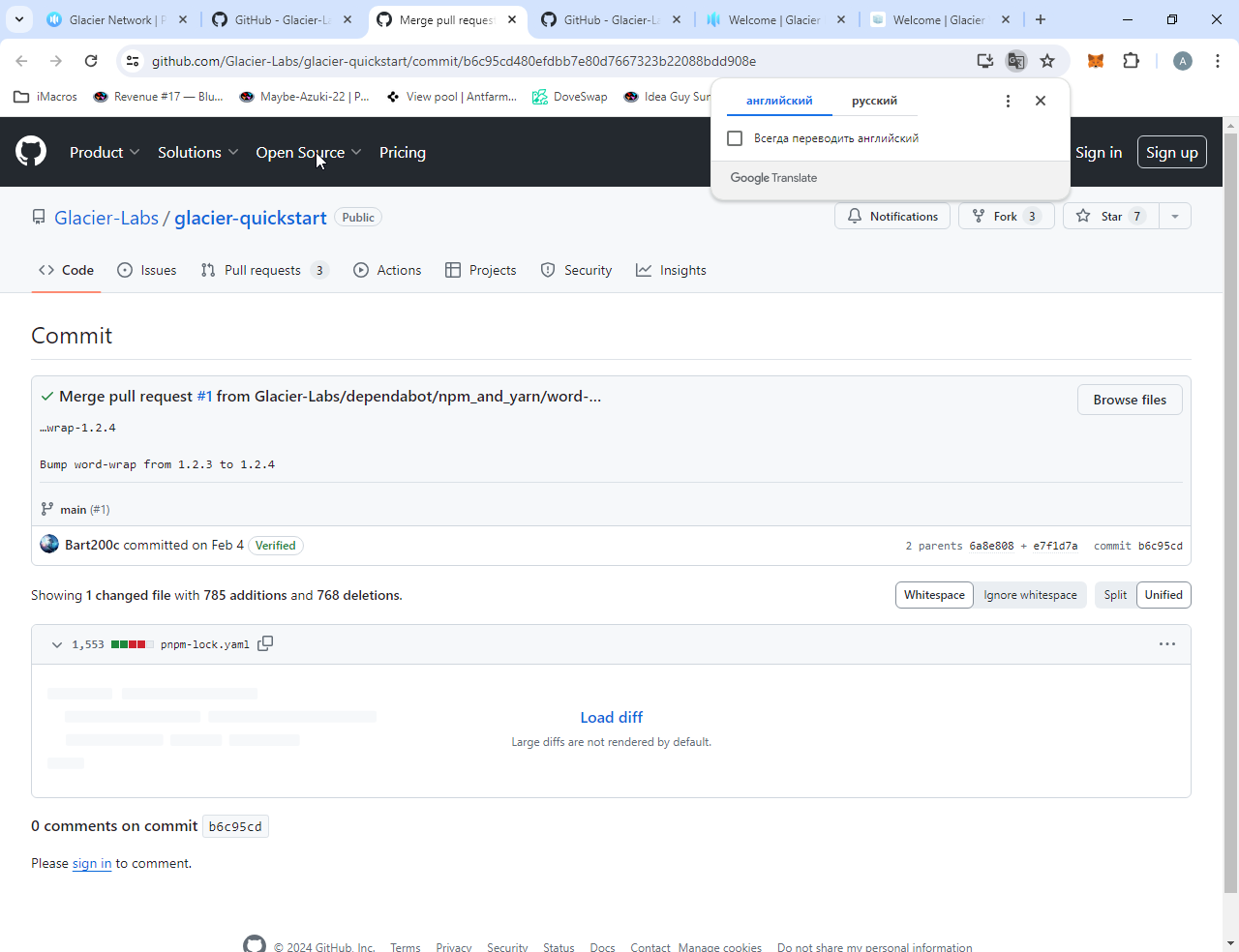
Отображается 1 измененный файл с 785 добавлениями и 768 удалениями.
Но всего 9 коммитов. Предыдущий был 20 июля 2023...

Отображается 1 измененный файл с 785 добавлениями и 768 удалениями.
Glacier-Labs/js-glacier - библиотека для Javascript разработчиков:

Последний коммит в прошлом году:

Показаны 2 измененных файла с 2 добавлениями и 2 удалениями.
Всего 16 коммитов:
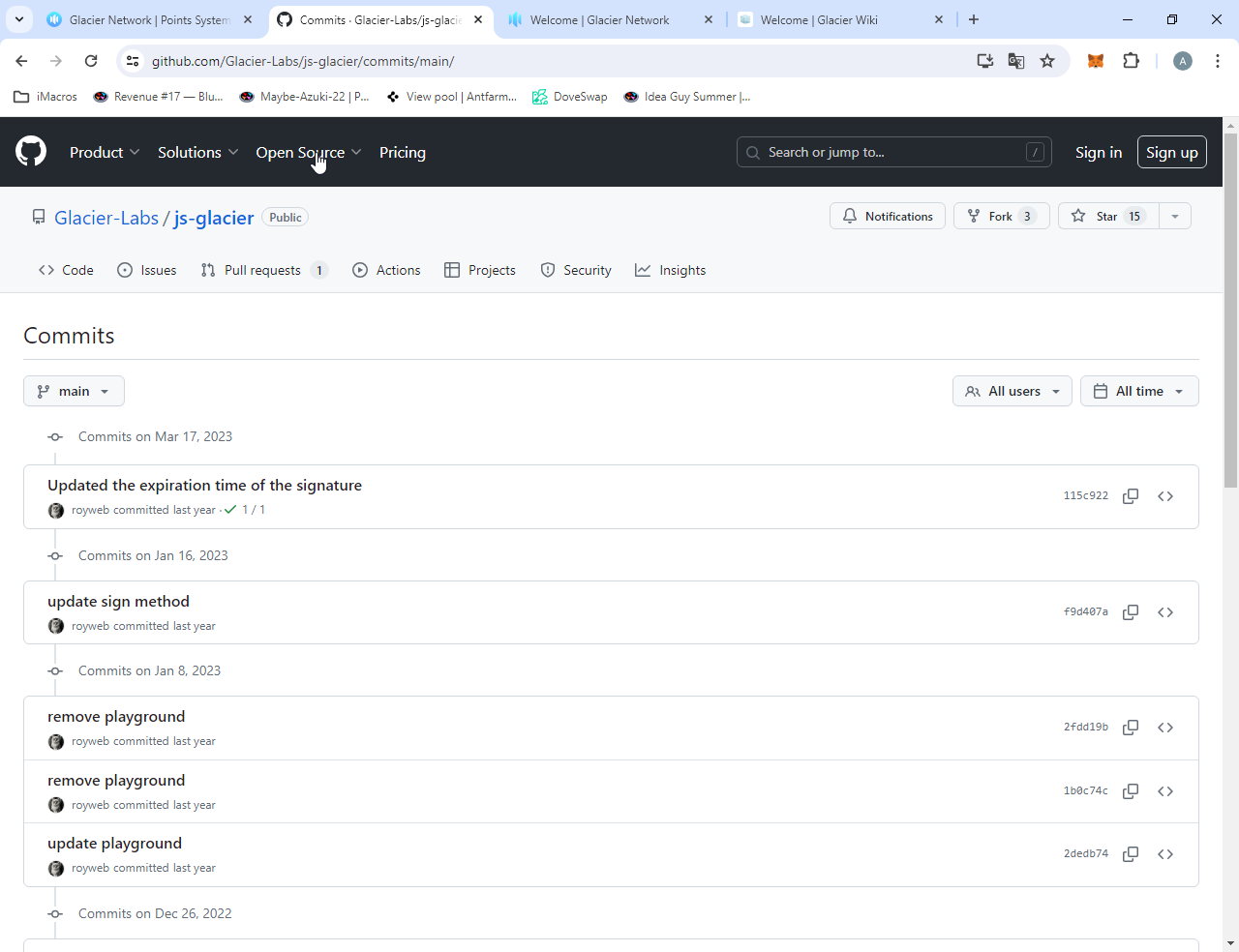
Т. е. последний коммит в марте прошлого года! А до него был в январе:

Показаны 4 измененных файла с 27 добавлениями и 9 удалениями.
В общем, то ли разработка слабо ведётся, то ли открытый код перестали публиковать...
Оценка 3 из 5:
-
минус балл за редкие коммиты с небольшими изменениями
-
Минус балл за заброшенный SDK. Вряд ли в нём нечего менять за столь продолжительное время, если проект выпускает обновления...
-
Возможно всё разработали, и просто незачем постоянно менять код: за это +1 балл.
Документация
Glacier Wiki
Сайт: https://docs.glacier.io/wiki
Glacier network - программируемая компонуемость данных для недоверенных примитивов данных
Glacier - это композитная, модульная и масштабируемая сеть данных L2 для крупномасштабных Dapps.
Glacier позволяет децентрализованным приложениям (DApp) строить на основе децентрализованных баз данных (DDB). Он предоставляет программируемые решения для компоновки данных на базе ZK-rollup, позволяющие легко и непринужденно работать с наборами данных с NoSQL GlacierDB поверх Arweave, Filecoin, BNB Greenfield и других.
🧊Обзор проекта:
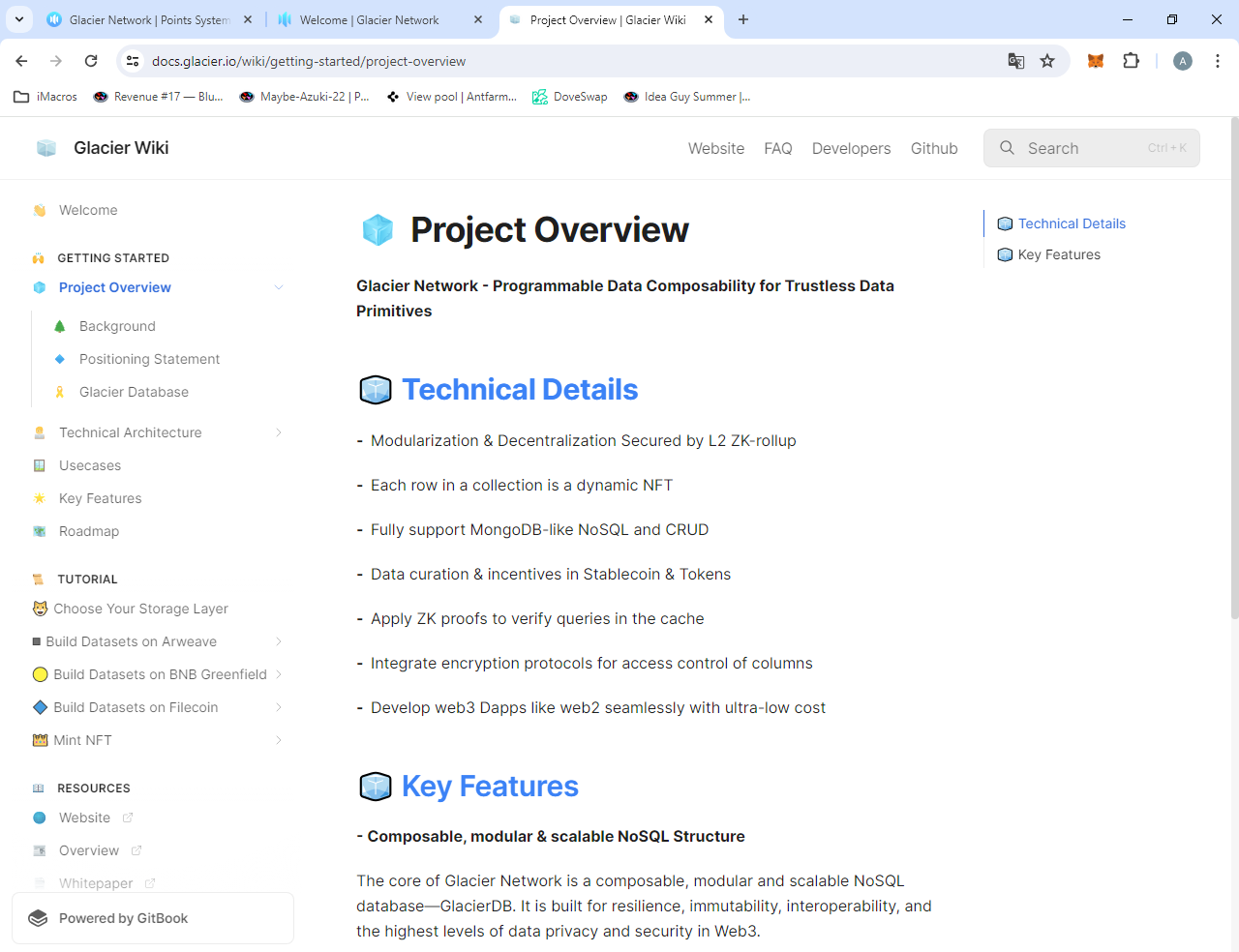
🧊 Технические детали:
-
Модулизация и децентрализация, защищенные L2 ZK-роллапом
-
Каждая строка в коллекции является динамическим NFT
-
Полная поддержка MongoDB-подобных NoSQL и CRUD
-
Курирование данных и поощрения в Stablecoin и токенах
-
Применение ZK-доказательств для проверки запросов в кэше
-
Интегрируйте протоколы шифрования для контроля доступа к столбцам
-
Разработка web3 Dapps как web2 с ультранизкими затратами
🧊 Ключевые особенности
Композиционная, модульная и масштабируемая структура NoSQL
- Ядром Glacier Network является композитная, модульная и масштабируемая NoSQL база данных GlacierDB. Она создана для обеспечения устойчивости, неизменяемости, совместимости, а также высочайшего уровня конфиденциальности и безопасности данных в Web3.
Масштабное внедрение в цепочку с помощью L2 Rollup
- Glacier использует огромные объемы данных в производстве и полностью обрабатывает данные ончейн, чтобы предоставлять пользователям более качественные сервисы данных. Модулизация и децентрализация обеспечиваются zk-rollup.
Построено на основе постоянного хранилища
- Glacier использует IPFS, Arweave и BNB Greenfield для хранения, обмена и размещения наборов данных в масштабе, что делает хранение и запросы полностью безопасными.
Создавайте собственные наборы данных за одну минуту
- С помощью Glacier разработчики могут безопасно создавать собственные базы данных без каких-либо разрешений, что позволяет разработчикам Web3 легко и непринужденно использовать данные с минимальными затратами.
🌲Background:

Поскольку развитие Web3-хранилищ находится на ранней стадии, многие Web3-приложения по-прежнему предпочитают хранить данные на централизованных серверах или в облачных сервисах. К сожалению, централизованные системы сопряжены с такими рисками, как единая точка отказа, потеря данных, утечка конфиденциальности и т. д. Glacier считает, что децентрализованное хранение данных Web3 сейчас обретает форму. По мере совершенствования инфраструктуры хранения данных все больше разработчиков Web3 будут предпочитать хранить данные в децентрализованных протоколах хранения.
С развитием хранилища Web3 протокол хранения файлов, лежащий в его основе, постепенно был принят многими разработчиками Web3. Однако, поскольку базовые распределенные протоколы хранения, такие как Arweave и IPFS, могут хранить только статические файлы, разработчики получают только идентификатор файла хранения. Это не может удовлетворить требования к структурированному хранению, запросам и модификации данных.
Данные Web3 полностью доступны в блокчейне и представляют собой большую ценность. Пользовательские данные, созданные и записанные DApps Web3, также являются одним из самых больших активов для разработчиков Web3. Разработчики Web3 должны создавать новые приложения на основе соответствующих данных и генерировать важные бизнес-понятия, но сейчас это принципиально невозможно из-за следующих проблем:
-
Плохая доступность данных: Сегодня данные Web3 заперты в различных децентрализованных хранилищах, что не позволяет разработчикам получить полный доступ к ним. Это приводит к ухудшению качества обслуживания клиентов, нехватке информации и замедлению разработки приложений.
-
Отсутствие гибкости: Требования более быстрого и простого развертывания на быстро меняющихся рынках Web3 и повышения производительности сдерживаются крайне недружелюбной средой хранения и жесткими реляционными моделями данных, которые существуют сегодня.
-
Ограниченная поддержка данных: Разработчики Web3 имеют ограниченную поддержку данных для удобного анализа, запроса и мониторинга собственных пользовательских данных по различным каналам, таким как веб и мобильные платформы.
-
Высокая стоимость: Дорогостоящая плата за децентрализованное хранение, огромные скачки стоимости при масштабировании рабочих нагрузок и управление многоцепочечными хранилищами создают барьеры для инноваций.
Поэтому существует огромный спрос на уровень базы данных Web3, который мог бы обеспечить полностью децентрализованную службу баз данных, построенную с учетом отказоустойчивости, масштаба и высочайшего уровня конфиденциальности и безопасности данных в Web3.
🔹Заявление о позиционировании:

Во всем техническом стеке Web3 протокол хранения данных от клиента до самого низа можно разделить на шесть уровней. Glacier в основном работает на уровне базы данных, который решает проблемы, связанные с тем, как помочь разработчикам Web3 реализовать структурированное хранение данных.
🎗️Glacier база данных:

Процветание Web3 привело к взрывному росту количества ончейн данных, включая адресную информацию, данные о транзакциях, контент и социальные связи. Если разработчики приложений Web3 хотят добывать данные из этих цепочек пользователей, то базы данных SQL больше не подходят для этих приложений. Вместо них с такими огромными объемами данных хорошо справляются базы данных NoSQL.
Задача Glacier - создать безопасную, децентрализованную и высокомасштабируемую NoSQL-базу данных Web3, чтобы помочь приложениям Web3 хранить огромные объемы институциональных данных и полноценно добывать Web3 ончейн данные для предоставления пользователям более качественных услуг. Основными типами нереляционных баз данных NoSQL, предоставляемых Glacier, являются Key-value, Document, Columnar и Graph.
При децентрализованной архитектуре Web3 разработчикам приходится иметь дело с большим количеством разрозненных и сложных данных ончейн, что значительно затрудняет цикл разработки приложения, а также опыт и масштабируемость самого приложения. База данных Glacier значительно упрощает процесс разработки приложений и протоколов, предоставляя высокомасштабируемое децентрализованное хранилище данных и сервисы запросов, позволяя dApp'ам беспрепятственно вставлять данные из других приложений. Кроме того, благодаря включению децентрализованных ончейн данных в базу данных NoSQL, Glacier поможет разработчикам Web3 лучше хранить структурированные данные для своих приложений.
Данные можно легко вызывать, запрашивать и даже торговать ими. Большое количество пользовательских данных Web3 находится в публичном состоянии в блокчейнах и имеет высокую внутреннюю ценность. В то же время структура данных NFT похожа на структуру базы данных NoSQL. Таким образом, Glacier может сделать очень удобным для пользователей генерирование данных NFT из данных, которыми они владеют, которые затем могут быть монетизированы путем торговли данными в Glacier's Data Marketplace.
🧑💻Техническая архитектура:

Страница повторяет информацию о ключевых особенностях, что писал ранее...
🧱 Технический стек:

Технический стек GlacierDB в основном состоит из следующих уровней:
-
Web3 dApps, которые получают доступ к децентрализованному протоколу Glacier через Glacier Dev SDK.
-
Децентрализованный протокол Glacier, который является основной частью GlacierDB и состоит из следующих сегментов: Glacier Dev SDK, Glacier NoSQL Access Protocol, Database Engine Shards, Database Transaction Rollup (роллап транзакций с данными), Data Permanent Availability Network, L1 (Layer 1) Settlement, Indexer Network.
-
Постоянный уровень хранения базы данных Glacier.
🛢 DB Engine:

Движок базы данных является основным элементом сети Glacier, и вся сеть состоит из множества сегментов базы данных (которые будут подробно рассмотрены в следующих разделах). Движок базы данных отвечает за обработку данных в каждом сегменте.
💿 DB Sharding:

Чтобы горизонтально расширить возможности хранения и вычислений во всей сети Glacier, выполняется сегментирование сети Glacier, которая состоит из большого количества шардов базы данных. Каждое хранилище GID принадлежит одному из доступных шардов базы данных. У Glacier есть глобальный реестр сегментирования БД, в котором записывается шард БД, к которому относится каждое хранилище GID, а также идентификатор и адрес каждого шарда БД.
Прежде чем получить доступ к Glacier, Glacier SDK сначала запросит реестр шардингов БД, к которому принадлежит текущий GID, найдет в реестре местоположение соответствующего шарда БД и, наконец, инициирует запрос доступа к шарду БД.
Каждый шард БД периодически генерирует доказательство данных и блок данных, блок данных публично представляется в Сеть доступности данных и архивируется в децентрализованном хранилище, таком как Arweave. Доказательство данных передается контракту расчетного уровня. Использование L1 в качестве расчетного слоя для шардов БД приведет к линейному росту нагрузки на запись доказательств данных с увеличением количества шардов данных, что серьезно ограничит масштабируемость сети Glacier Network, особенно в сетях с низкой пропускной способностью и дорогими L1, таких как Ethereum.
Чтобы обеспечить масштабируемость и избежать ограничений на количество шардов DB в сети Glacier, был введен DB Meta Rollup для предоставления расчетных услуг для шардов данных. DB Meta Rollup служит решением второго уровня для сети Glacier Network, в то время как многочисленные шарды данных строятся поверх него как сеть данных третьего уровня. Такая многоуровневая структура роллапов позволяет практически неограниченно расширять количество шардов данных.
⚙️ Rollup Sequencer:

Rollup Секвенсор обрабатывает транзакции, создает роллап-блоки, передает доказательства роллапа в блокчейн уровня Layer1 и передает блоки данных роллапа на уровень доступности данных. Чтобы предотвратить такие негативные эффекты, как цензура транзакций и простои, вызванные централизованным секвенсором, в секвенсорах DB Shard и DB Meta Registry используется сеть валидации, состоящая из одного лидера и нескольких валидаторов для обеспечения надежности секвенсора.
Сеть валидации секвенсора состоит из нескольких Нод секвенсора, каждая из которых независима и имеет одну и ту же копию данных. Среди них Нода секвенсора (лидер) отвечает за прием трафика транзакций, а другие Ноды секвенсора (валидаторы) - за проверку данных и реплик. Если новая Нода-секвенсор хочет участвовать в сети валидации, ей необходимо внести определенную сумму $GLC. Если лидер не работает в силу определенных обстоятельств или возникла проблема с генерацией блоков, он будет наказан, а вся сеть валидаторов выберет нового лидера для возобновления работы.
🔑 Индексатор:

Индексирование Glacier состоит из следующих двух ключевых частей:
-
Importer: Importer извлекает данные из исходных наборов данных, соблюдает стандарты типа и достоверности данных, обеспечивает их структурное соответствие требованиям индексатора и затем загружает в индексатор. Как только в источнике данных произойдет новое изменение данных, оно будет захвачено и синхронизировано с системой индексации с максимальной скоростью.
-
Index Creator: Index Creator считывает данные из Importer в соответствии с конфигурацией и форматом индекса, заданными пользователем, и создает экземпляр индекса.
🪟Usecases:
Множество примеров использования с поддержкой Web3:
🏞 База данных NFT
Пространство NFT сегодня развивается быстрыми темпами, и Glacier будет одним из самых профессиональных и дружественных протоколов баз данных, используемых для хранения метаданных NFT, поскольку метаданные NFT также находятся в структуре данных NoSQL. NFT будет наиболее важным пользовательским сценарием, и Glacier в первую очередь будет расширять внедрение в пространстве NFT.
🙌 SocialFi
Приложения SocialFi dApps в основном работают с социальными связями пользователей Web3 и испытывают большие потребности в структурном хранении данных о социальных связях пользователей Web3. Поэтому Glacier поможет разработчикам SocialFi достичь этого дружественным и недорогим способом. В то же время разработчики SocialFi могут использовать движок базы данных Glacier, чтобы легко построить социальный граф для своих пользователей, поскольку они могут хранить пользовательские данные в базе данных графов, которая поддерживается Glacier.
👾 Метавселенная
Проекты GameFi могут иметь тысячи предметов NFT в своих блокчейн-играх, что означает огромную нагрузку по хранению связанных данных об активах и данных о пользователях. Движок баз данных NoSQL Glacier может помочь разработчикам GameFi хранить их структурно в Нодах Glacier и блокчейне Arweave. В то же время с помощью Glacier они могут легко обновлять и запрашивать связанные данные об активах и пользователях, используя SDK Glacier.
💠 Монетизация данных
В приложениях Web2.0 все пользовательские данные хранятся в хранилище, предоставленном одним техническим гигантом, например Apple, Facebook или Twitter. У них нет никакого желания делиться своими пользовательскими данными с другими компаниями, чтобы построить универсальный социальный граф, который мог бы иметь огромную ценность для общества.
🌟Основные характеристики:

Чтобы лучше решить проблемы хранения структурных данных Web3, Glacier будет разработан как протокол базы данных NoSQL для разработчиков Web3 со следующими инновационными возможностями:
-
Масштабируемость: чтобы соответствовать потребностям разработчиков Web3 в базах данных, количество Нод хранения Glacier может быть увеличено до бесконечности, а объем хранения каждой Ноды также может быть гибко изменен.
-
Безопасность: Хранящиеся данные делятся на фрагменты и распределяются по нескольким Нодам Glacier, при этом поставщики услуг не известны и не требуют доверия третьих лиц. Процесс шифрования данных не ограничивается конечными пользователями и программным обеспечением, но также происходит во всех звеньях сетей хранения с помощью таких методов, как доказательство нулевого знания и доступ к закрытым сетевым ключам.
-
Децентрализация: Отсутствие единой точки контроля. Нет единой точки отказа. Glacier предоставит разработчикам Web3 полностью децентрализованный контроль через сеть Нод хранения Glacier и консенсус хранения Glacier Event Sourcing.
-
Интероперабельность: Glacier может обеспечить полную интероперабельность данных Web3, которые структурно хранятся через Glacier Database Engine, и сделать данные Web3 легко запрашиваемыми, передаваемыми и интероперабельными.
-
Неизменность: больше, чем просто устойчивость к взлому. После хранения данные нельзя изменить или удалить.
-
Высокая надежность запросов: Напишите и выполните любой запрос к базе данных Glacier, чтобы найти содержимое всех хранящихся транзакций, активов, метаданных и блоков в сети Glacier.
-
Низкая стоимость: Glacier предоставит разработчикам Web3 услуги по созданию баз данных на блокчейне по низкой цене.
🗺️Roadmap:

Обновление из 2023 Q4 (ZK-rollup Integration Testnet) не внедрён ещё, в прочем, как и "ZK-rollup Integration Mainnet" в Q1 2024.
В 2 квартале 2024 должно было быть улучшение пользовательского опыта, но прошла половина - и этого нет.
Также описаны планы на будущее:
Децентрализованная идентификация
- В Web3 данные принадлежат сетевому адресу, который содержит ключ владельца связанных данных. Однако одного сетевого адреса недостаточно для идентификации профиля или записи личности и социального графа. Хуже всего то, что каждый может легко настроить сотни сетевых адресов за считанные секунды. Это означает, что кто-то должен интегрировать все ончейн данные для формирования единой идентификационной информации, которая может использоваться для входа в систему, социальных связей, системы репутации и кредитного финансирования в пространстве Web3.
Перекрестная передача данных
- Сегодня криптоактивы реализуются в виде перекрестной передачи данных между различными блокчейнами. Однако данные Web3 по-прежнему ограничены в разных блокчейнах и не могут передаваться между ними, что существенно ограничивает интеграцию и потенциал данных Web3. Поэтому Glacier изучит, как обеспечить сквозную передачу данных между различными блокчейнами, чтобы упростить передачу данных в эпоху мультичейна.
База данных Graph для Web3 Social
- Открытость Web3 создает отличную основу для построения социального графа пользователя, чего не удалось достичь в Web 2.0 из-за нехватки данных. При создании социального графа в Web3 разработчикам приходится сталкиваться с большим объемом сетевых данных, которые структурно не хранятся на Нодах блокчейна. В Web2.0 база данных graph, которая является одним из важных типов баз данных NoSQL, используется для хранения данных о социальных связях пользователя для создания социального графа. Поэтому Glacier рассмотрит выпуск специального пакета SDK для базы данных Graph, который облегчит разработчикам Web3 создание социального графа.
Повышенная безопасность журналов
- Использование одного ключа чтения и обслуживания для всего журнала означает, что в случае утечки любого из этих ключей злонамеренным (или другим, возможно, случайным) способом невозможно предотвратить прослушивание событий Нод с утеченными ключами или просмотр истории журнала. Glacier изучит потенциальные решения, которые могли бы обеспечить повышенную безопасность журналов в будущем.
Планы хорошие: главное, чтоб выполняли их вовремя...
😺 Выберите свой уровень хранения:
Glacier создает композитную, модульную и масштабируемую сеть данных L2 для крупномасштабных Dapps с целью расширить возможности децентрализованных приложений (DApp) по созданию децентрализованных баз данных (DDB).
Проект предоставляет программируемую композитность данных на основе решений L2 rollup, позволяющих легко и непринужденно работать с наборами данных с NoSQL GlacierDB поверх Arweave, Filecoin, BNB Greenfield и других.
Прежде чем приступить к работе, выберите предпочтительный децентрализованный слой хранения данных на главной странице Glacier Webside.
-
Arweave: Построив свою базу данных на основе протокола Arweave, вы сможете использовать решение Arweave для постоянного хранения данных.
-
BNB Greenfield: Благодаря встроенной экосистеме смарт-контрактов BNB вы уверенно овладеете искусством управления данными.
Filecoin: Развертывание на базе хранилища Filecoin позволяет легко обрабатывать и контролировать данные, используя могучую силу динамической среды FVM.
Напомню, что FileCoin - от создателей IPFS.
Далее дана инструкция с использованием каждого из проектов, но я опишу в практике пример с BNB, поэтому здесь это пропустим...
И перейдём сразу к минту nft:

Управление данными NFT + искусственный интеллект = AIGN
Glacier NFT Space предлагает динамическую функцию, позволяющую хранить и управлять метаданными NFT на BNB Greenfield.
Он предоставляет пользователям возможность майнить и торговать своими наборами данных для монетизации на OpenSea, работающей на базе блокчейнов opBNB/OKX X Layer/Solana. Любой желающий может создавать бессерверные NFT Dapps, освобождая вас от бремени управления тяжелой инфраструктурой Web3.
На странице подготовки скажут, что надо получить токены, а на странице "➡️Минт NFT для монетизации", что надо создать коллекцию в Glacier Playground, подождать в скане и сминтить nft.
Документация SDK для разработчиков

Здесь также рассказано о проекте, а также для чего он - повторяться не буду.
Концепция glacier:

Эта глава введет вас в основные концепции Glacier. API Glacier разработаны с учетом MongoDB, поэтому, если вы знакомы с разработкой на MongoDB, вы быстро освоитесь с Glacier.
-
Namespace (Пространство имен)Namespace представляет собой коллекцию наборов данных (Datasets). Разработчики должны создать соответствующие Namespace для своих проектов перед использованием Glacier.
-
Dataset (Набор данных)Dataset — это коллекция коллекций (Collections). Однако важно помнить, что каждый Dataset должен быть назначен Namespace, к которому он принадлежит.
-
Collection (Коллекция)Collection похожа на таблицу в MongoDB и используется для хранения записей данных объектов. Для создания Collection необходимо указать Dataset, к которому она принадлежит. Поэтому, если вы хотите использовать Glacier для хранения данных, вам нужно определить первые три пути: Namespace / Dataset / Collection.
-
Ownership (Владение)Glacier ориентирован на разработчиков. Запросы данных доступны публично, но операции, такие как запись, изменение и удаление, должны быть подписаны кошельком Ethereum пользователя, и другие пользователи не могут их изменить.
Glacier SDK поддерживает Node.js и браузер одновременно, что означает, что разработчики могут не только создавать наборы данных (Dataset) и коллекции (Collection) на стороне сервера с использованием управляемого ими приватного ключа, но и позволять пользователям контролировать все их данные через Ethereum-кошелек в браузере. На этой странице рассказано, как быстро начать работу с Glacier SDK.
-
Поддерживаемые энтпоинты:Arweare - https://p0.onebitdev.com/glacier-gateway - работает в mainnet
-
BNB Greenfield - https://greenfield.onebitdev.com/glacier-gateway - mainnet
-
Filecoin - https://web3storage.onebitdev.com/glacier-gateway - testnet
-
BNB Greenfield Vector - https://greenfield.onebitdev.com/glacier-gateway-vector - testnet
Проект поддерживает Arweave, Filecoin и BNB Greenfield в качестве DA-слоя Glacier. В текущей версии эти DA-слои изолированы, но в будущем команда планирует сделать их конфигурируемыми и динамическими.
А далее идут варианты использования...

Описывать не буду, т. к. для разработчиков страница.

Тоже пропущу описание.
Создание блога Web3 с помощью GlacierDB:

Дан пример с использованием React.
Разработка Web3 игр с помощью GlacierDB:

Web3 AI/Машинное обучение с GlacierDB:
В этом руководстве познакомят разработчиков DApp с Glacier VectorDB и расскажут, как использовать GlacierDB для искусственного интеллекта /машинного обучения.
Перед к кратким описанием, вам следует ознакомиться с основной концепцией. Здесь рассказано о некоторых основных понятиях для вас
-
Embedding: https://en.wikipedia.org/wiki/Word_embedding
-
Huggingface: https://huggingface.co/docs/api-inference/quicktour
Ну и описано, как начать работу...
Откройте пространство NFT с помощью GlacierDB:

Пространство NFT сегодня развивается быстрыми темпами, и Glacier станет одним из самых профессиональных и удобных протоколов баз данных для хранения метаданных NFT, поскольку метаданные NFT также имеют структуру данных NoSQL. NFT будет самым важным сценарием использования, и Glacier сначала расширит свое применение в сфере NFT.
В этом руководстве рассказано, как создать безсерверное приложение для NFT на Glacier.
Основные понятия:
Перед тем как следовать руководству по быстрому старту, ознакомьтесь с основными понятиями:
-
Collection (Коллекция): Коллекция аналогична таблице в MongoDB. Используется для хранения записей данных сущностей.
-
Document (Документ): Документ — это данные сущности в коллекции.
-
NFT721: ERC721
-
NFT1155: ERC1155
-
Стандарт метаданных Opensea: Opensea Metadata standard
Необходимые условия:
-
Эндпоинт Glacier GreenField: https://greenfield.onebitdev.com/glacier-gateway/
-
Glacier SDK NPM: @glacier-network/client
-
Deno Fresh: https://fresh.deno.dev/
-
Deno Deploy: https://deno.com/deploy
-
Демо-кошелек: создайте новый кошелек только для тестовых целей!
Проектирование пространства NFT:
Разработано два безсерверных сервиса для пространств NFT в демонстрационных целях. Вы можете изучить онлайн-демо в Github развернуть приложения самостоятельно:
-
NFTGateway: Служит документом как URI метаданных NFT, преобразуя бинарное поле документа в изображение NFT.
-
NFTMint: Площадка, которая помогает пользователям чеканить коллекционные NFT1155.
Далее описано само создание - его пропущу: при желании сможете ознакомиться.
Далее идут разделы с SDK и API.
В SDK первой страницей является GlacierClient:

GlacierClient - это сервер, который мы используем для доступа к Glacier. Если вы хотите создать клиент только для чтения, вам не нужно указывать PrivateKey при создании экземпляра или provider. Вам нужно только указать эндпоинт службы.
Приведены примеры подключения Клиента и указания приватника / провайдера (типа Metamask) для отправки данных.

Пространство имен (Namespace) является единицей первого уровня в Glacier. Обычно выполняются только две операции: создание и перечисление.
Приведены их примеры кода.

Набор данных (Dataset) является вторичной единицей в Glacier, аналогичной базе данных в MongoDB, но каждый Набор данных должен принадлежать Пространству имен (Namespace).
В коде сначала необходимо получить Пространство имен, к которому он принадлежит, через client.namespace(name), а затем уже создавать его.
Если вы хотите запросить подробную информацию о наборе данных, вы можете использовать метод queryDataset, предоставляемый Namespace, пример на странице.

Коллекция (Collection) является третьей единицей в Glacier, она соответствует Коллекции в MongoDB и должна принадлежать Набору данных (Dataset). Для создания Коллекции можно использовать метод createCollection, предоставляемый Набором данных, и необходимо указать модель проверки данных, требуемую для создания Коллекции, то есть JSON Schema. Пример кода на странице.
Коллекция (Collection) используется для хранения каждой конкретной записи данных. Вы можете получить экземпляр Коллекции для работы через dataset.collection(name). Операции включают добавление, удаление, изменение и запрос данных.
Приведены их примеры.
Важно, что, в частности, find должен вызвать функцию toArray() в конце, чтобы получить окончательный результат запроса.
Обновление данных в Glacier отличается от MongoDB. В данном случае updateOne всегда является частичным обновлением, а не заменой всей записи при обновлении данных, что эквивалентно использованию $set в MongoDB для обновления данных.

Мы их видели ранее...

Здесь описаны методы, которые можете использовать в API.
Остальные показывать не буду, т. к. интересно только разработчикам.
Скажу лишь, что описано всё подробно
Итог по документации
Оценка 5 из 5: всё подробно и понятно.
Правда я не совсем понимаю, зачем лишняя сущность (dataset) - структуру данных можно было бы делать при создании коллекции документов, но что есть то есть, и это не относится к документации...
Практика
Запускаем DApp по ссылке https://www.glacier.io/points/?inviter=0xaeac266a4533CB0B4255eA2922f997353a18B2E8
(буду рад, если воспользуетесь моей ссылкой):

"Connect Wallet":
Выбираем кошелёк и подключаемся. Далее подписываем:

И видим страницу:

Получаем реферальную ссылку: можем скопировать и поделиться в Твиттере.
Приглашайте людей, и получайте за это поинты.
Ниже найдёте FAQ, где можем узнать подробности программы поинтов:
Вы можете накапливать баллы, выполняя 2 обязательных задания и 1 реферальное задание.
Обязательное задание:
-
Создайте свой децентрализованный набор данных, коллекцию и mint NFT —> +100 баллов
-
Выполняйте задания на Galxe —> +100 баллов
Заметки:
-
Вы должны использовать один и тот же адрес кошелька для выполнения заданий на Glacier & Galxe.
-
Для каждого адреса баллы NFT minting будут начисляться только один раз.
Реферальное задание:
- Приглашайте друзей по своей реферальной ссылке —> 50 баллов как за действительного приглашающего, так и за действительного получателя приглашения.
Заметки:
-
Действительный приглашающий: Пользователи, выполнившие обязательные задания и получившие действительных приглашенных.
-
Действительные приглашенные: Пользователи, которые впервые вошли в Glacier Network по реферальной ссылке и выполнили обязательные задания.
Также найдёте лидерборд.
Создаём данные в Glacier DB
Или выполняем первое задание.
Жмём по ссылке "Build Now", переходя в основное пространство:

"Connect Wallet":

Выбираем и подключаемся. Страница после входа:

Сначала нажимаем "Create a new Namespace" и вводим название без пробелов:

"Ok":

Подписываем, и идём далее:

Не обращайте внимание, что namespace ещё не виден. Кликаем по "Create Dataset":
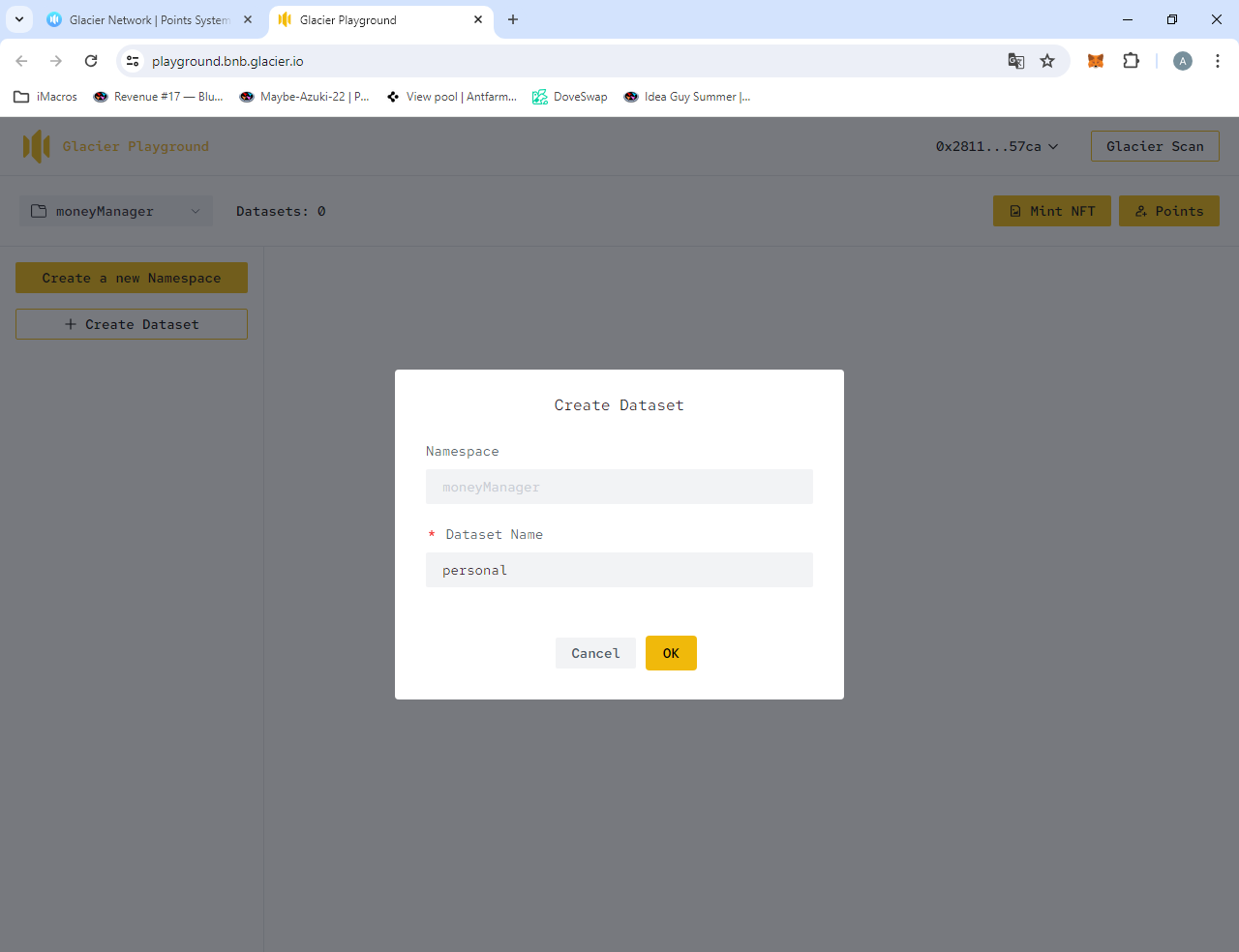
Вводим название, Ok, подписываем, и видим его:

Клик по кнопке возле названия (в моём случае Personal), откроет создание коллекции:

Вводим название коллекции, а затем заполняем поля.
Отмечаем галочку, чтоб стало поле обязательным. Кнопка первая добавляет поле:

Нажав по "String", можем выбрать тип поля:

К сожалению доступны только строки, числа и логический типы.
Добавил третье поле:

Нажав по второй кнопке после добавления поля, можем настроить паттерн и минимальное / максимальное кол-во символов:

Можете заполнить. Третья кнопка удалит поле:

Добавил поле даты и настроил такой паттерн:

Итоговый список:

"OK":

Коллекция появилась на странице:

Можно добавить и другие коллекции, но я, поскольку это для статьи, пропущу это (суть понятна).
Нажму по "ExpensesProfit" (обратите внимание, что сократил название, т. к. придыдущее не влазило в 16 символов):

"Share to Twitter" позволит поделиться в Твиттере, а "Insert Document" - вставит документ:

Но я неверным указанием паттерна испортил коллекцию: её не удалить и не изменить. Поэтому создал другую:

"Insert document":

"Ok":
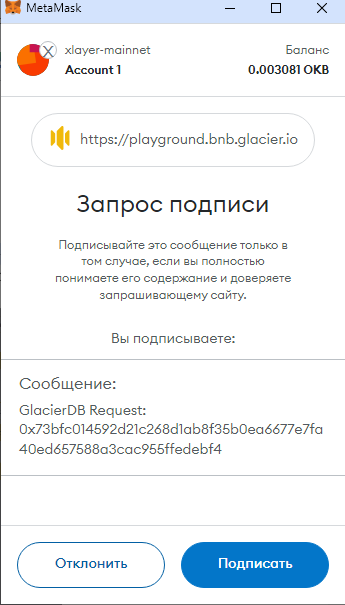
И подписываем.
Кстати, паттерн указал "\d\d\.\d\d\.\d\d\d\d" - он сработал...
Появился документ:

Первая кнопка откроет документ в формате json:

Вторая - открывает редактирование:

"Ok", подпись - изменения сохранятся.
Третья удаляет:

Добавим ещё поле:

Нажав "JSON Mode", вы можете вставить документ в формате JSON:

"Form Mode" возвратит к формату полей.
Заполнил JSON:

"Ok" и Подписал. Появился документ:

Для чего первая кнопка в документе? Для поиска...
Допустим, вы хотите найти документ с датой 12.05.2024. Открываете структуру, смотрите, и вставляете между фигурных скобок в "find({}).skip(0).limit(10)" нужное. Например, так:
find({date: "12.05.2024"}).skip(0).limit(10)
"Apply", и видим только выбранный документ:

Аналогично можете создавать другие документы...
Mint NFT
Жмём по соответствующей ссылке:

"Mint my NFT":

Кликаем по списку, выбираем namespace:

Выбираем dataset:

И коллекцию. Далее заполняем описание:

"Mint", подписываем сообщение, а после него подтверждаем транзакцию минта. Всё: если будет транзакция успешная в кошельке, минт прошёл. К сожалению на странице в таблице почему-то не отображается...
Задание 2: Galxe
Идёте на https://app.galxe.com/quest/glacierlabs/GCv5Utzo3j

Подписываетесь на Twitter аккаунт проекта, ретвитите твит, подписываетесь на канал и чат в Telegram, вступаете в Discord и получаете роль подтверждённого (капча) и подписываетесь на проект в Galxe. Нажимаете по значку проверки пунктов задания, а затем "Claim oat & 100 points" (она появится вместо неактивной "Tasks Incomplete"). Всё.
На странице поинтов ждите, когда появится подтверждение заданий.
Итог по практике
Оценка 4 из 5: всё удобно, но вот подтверждения nft минта долго нет...
Общий итог
Оценка 24 из 30 или 4 из 5. Проект нормальный.
Подробнее:
Информации о команде, фактически, нет; концепт интересный и актуальный; токеномики нет, но есть инвестиции 2,9 МЛН $ и поинты; код есть, но активной разработки нет; функционал полный, но nft минт не проверяет (по крайней мере в день отправки транзакции).
Всё
Благодарю за внимание. С вами был незрячий программист, автор https://t.me/blind_dev - подписывайтесь для получения новых обзоров, дайджестов интересных статей и новостей по моим разработкам.