原文:CYC Labs咕咕
STARK的出现是为了解决计算完整性(CI)的问题。CI是商业的基本属性,有了CI我们才能信任银行账单和账户余额。文章讨论了无需可区块链中在无信任的情况下完成CI。
在旧世界的金融系统中,会有机制激励他们诚信的给社会服务,还有一个变体,就是可信执行环境(TEE)。比如Intel生产SGX芯片,Intel是一个可信的硬件制造商,所以现在的CI是基于对硬件和它的制造商的信任,并且假设不可能在这样的物理设备中提取密钥。在新世界中,即区块链,提供了一种更加直接的方式实现CI,“dont trust, verify” ,就是直接验证,只需要一个节点,只需要它设置了标准计算,比如一个联网的笔记本电脑就可以给所有交易提供完整性验证。但是这也直接导致两个挑战,隐私和可扩展。所以这就引出了证明系统。
证明系统开始于1985年提出的交互证明(interactive proof),通过prover和verifier两个实体,发送信息进行多轮交互,利用随机性产生零知识证明,验证者最后会输出一个决策来接受或者拒绝这个新状态。当状态A更新到B,证明系统解决了CI时,就会有可靠性(completeness)和完备性(soundness)特性。可靠性和完备性在逻辑学里的一对概念词,这里用病例来做简单解释:
**可靠性:**所有病人+假阳性(不会把有病的人说成没病的人)
**完备性:**所有病人-假阴性(不会把没病的人说成有病的人)
作为解决CI的方法。ZK就是一个成熟的解决隐私问题的证明系统。ZK目前有两个主流方案,zk-snark和zk-stark,简单说一下两个方法的步骤:
**zksnark:先将原是复杂计算的代码扁平化,转换成只有加法和乘法的两种形式的代码,或者称为电路门,然后将它转换成rank-1约束系统(即R1CS),在转换成QAP,使用拉格朗日插值法,**目的是为了同时检查所有约束条件,检查通过即完成一次完整的stark。优点是安全可靠,检查一次多项式等价于检查了所有的电路门,但正是这个原因,也是stark的缺点,计算所有的逻辑门说明复杂度会很高,计算量也会非常大(一般都会超过100万个电路门)。
**zkstark :将CI语言转换成代数语言,一般包括执行追踪和一组多项式约束,参考在超市消费的小票,执行追踪就是将每一行和前后相邻的那一行相关。多项式约束可以进行局部检查,即低度测试,而且有容错冗余,**之前用RS编码进行举例:*比如要发送2345,实际根据编码本发送的值是two thvee four fiva,比要证明的值长,并且有错误,但是也可以推出原始数据2345。*FRI协议就是stark自己的检查正确性的协议。简单总结一下优点是生成简短并且能快速验证的证明。这么看下来stark缺点几乎是没有,不过在一些以太坊支持者来看,可能缺点就是不能兼容evm。
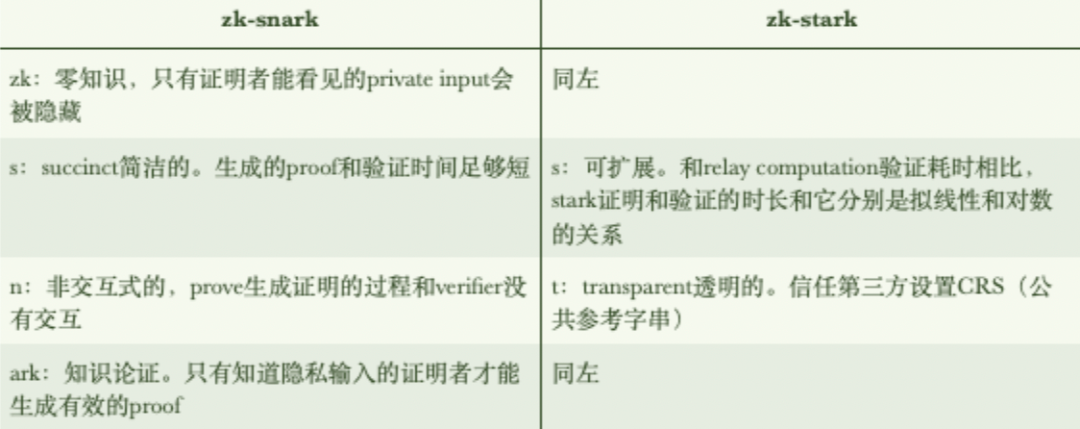
两者的不同点:
-
简洁性:
a. snark的简洁性体现在生成proof的size,小于stark;
b. stark则体现在验证者简洁性;
-
CRS:
a. snark需要可信第三方设置公共参考字串;
b. stark不需要CRS,更透明;
STARK的优势:
-
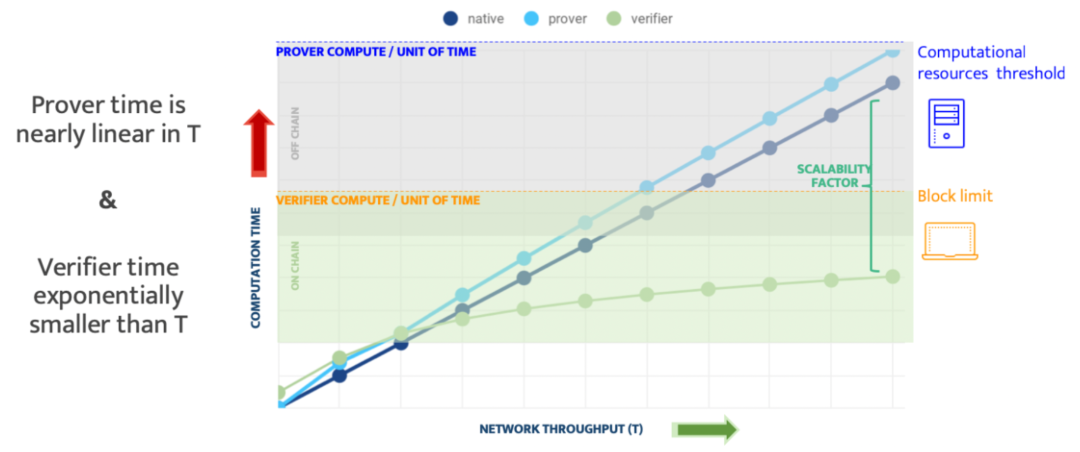
**可扩展性:**意味着两个效率属性同时具备:
证明者可扩展:证明者运行时间是“接近线性的”
验证者可扩展:验证时间呈指数缩小
经过计算,吞吐量增加100倍的时候,验证器的时间只增加了2.25倍
-
**透明:**Stark里面没有可信设置这一说,系统中没有秘密设置,消除了由参数设置产生的单点故障
-
**后量子安全:**抵抗量子攻击
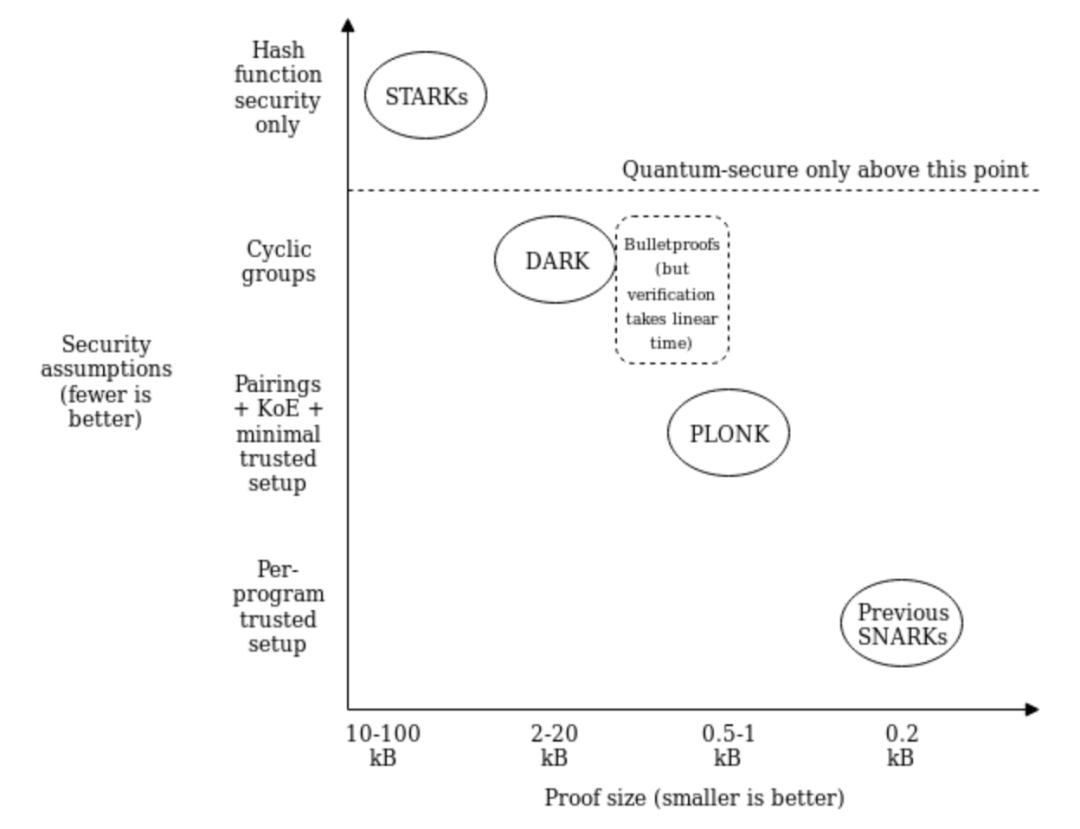
- **具体效率:**经过给定的计算,stark证明者比snark和bulletproof证明者快10倍,验证者比snark快2倍,比bulletproof快10倍。证明时间呈拟线性和验证时间呈对数关系图如下:
stark关键步骤:
算数化
算数化第一步就是取一些CI语句把它变成代数语言,主要有两个组成部分:
-
执行追踪
-
一组多项式约束
执行追踪
执行追踪简单来说就是一个底层计算表格,每一行代表执行步骤追踪,而且我们希望构建的执行追踪要具有简洁测试的特征,每一行都可以用靠近它的行来进行验证,这些特征会直接影响证明的大小。用超市的收据作为简洁证明的例子:
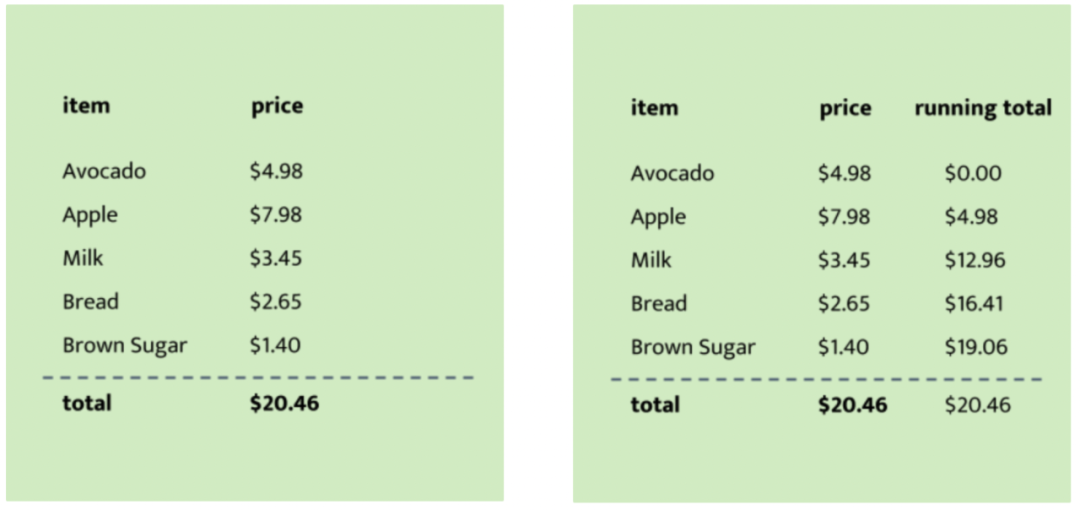
多项式约束
因为从头验证需要很多消耗,所以把执行追踪转化为多项式约束目的是将一个大的多项式约束拆分成小的一组约束,可以用局部约束进行验证(简洁性)。
用下面的一组多项式约束来表示上面的收据:
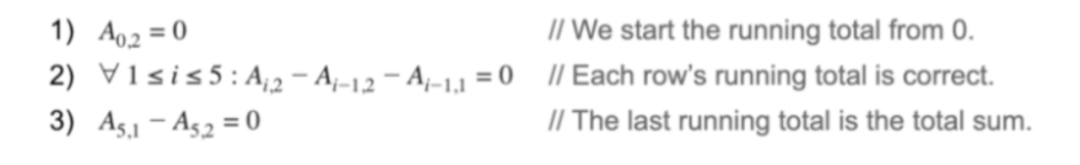
第二个约束就可以通过更改i的值来进行局部验证。
小结一下上面的目的,是通过验证者通过询问证明者少量的问题,来决定接受或拒绝证明(高准确性),验证者让证明者证明几个随机的执行追踪,检查多项式是否符合。正确的执行追踪就会通过和这个测试。但是构建一个完全错误的也不难,只要在一个地方违反约束,就会得到一个完全不同的结果,少量的随机询问并不能识别到某些故障。下面就介绍一下解决方法。
低度测试(Low degree Testing)
在少量随机询问不能识别故障的时候,通常使用的是纠错码。纠错码可以将短的字符串变成长字符串并且替代之前的字符串,而且一组相似的字符串可以转变为一组完全不同的结果。里德-所罗门编码,利用的是代数理论:**任何长度为k的码,都可唯一表示成一个阶数最多为k-1的多项式。**发送者表明一个在有限域中的k-1阶的多项式,表示k个数据点。这个多项式根据在个点的赋值被编码,实际传送的是这些值(一般来自编码本)。在传输过程中,一些值被破坏,所以实际发送的不止k个,只要正确的接受了足量的数值,接收方就可以推算出原始多项式,得到原始数据。比如要发送2345,实际根据编码本发送的值是two thvee four fiva,比要证明的值长,并且有错误,但是也可以推出原始数据。比如要发送2345,实际根据编码本发送的值是two thvee four fiva,比要证明的值长,并且有错误,但是也可以推出原始数据2345。
Stark的解决方法是利用低度测试。先将执行轨迹改写成多项式,再将多项式扩展到一个更大的域,并且把多项式约束转换为另一个多项式,当且仅当执行轨迹有效时。首先,使用低度测试的原因是为了简洁,插值是低度测试里面经常用到的一种寻求近似值的一种方法,因为很多科研实验中的函数是离散的,虽然函数关系是存在但是具体的函数可能非常难找到或者非常复杂,也不便于分析和计算。这时候利用插值函数就可以代替原有函数,特点是能表达原函数的特征,简单且容易计算。比如平时看到的天气预报温度的折线图,并不是简单的折线图,而是都利用了插值函数进行拟合,所以我们会看到在整点之间会有温差,这是因为实际函数并不是折线图所表达的函数,但是都会在一定的误差范围内。

插值函数**一般选择多项式,因为实际计算中,多项式只有加法和乘法,非常简单,并且多项式有一个特性,就是可以无限接近于一个连续的函数,不管这个连续的函数表达式有多复杂。因为根据魏尔斯特拉斯逼近定理,**闭区间上的连续函数可以用多项式级数一致逼近。比如说f(x)是连续的并且给定了一个闭区间,那么总可以找到一个n次多项式,误差可以小于事先给定的一个常数。下图就可以表示P_n(x)是f(x)的插值函数,虽然是有误差,但是在给定的几个点的数值中,是一定重合的。
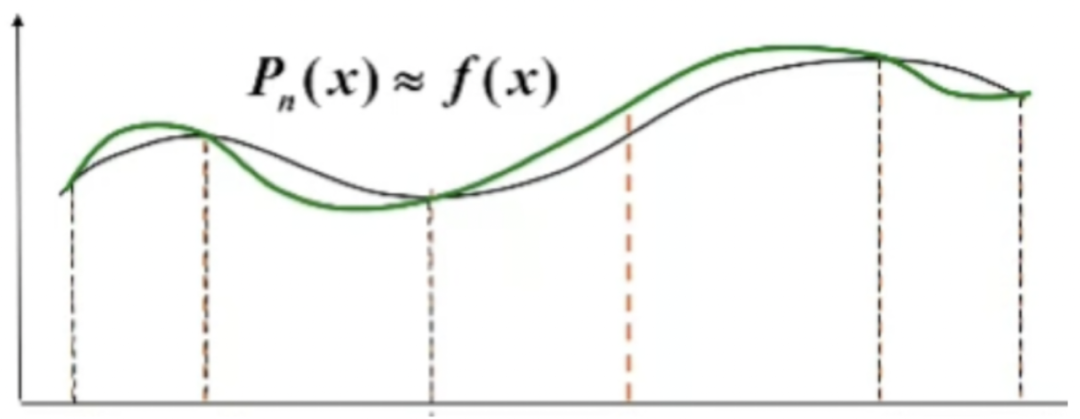
常用的插值法一般就是牛顿插值,泰勒插值,拉格朗日插值,样条插值(常用的三次样条)。
Vitalik在snark文章中有详细解释过,snark使用的就是拉格朗日插值法,优点就是计算方法简单,通过下面的公式
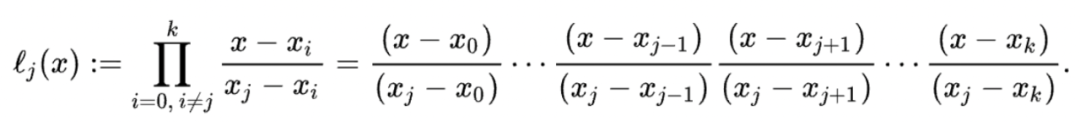
需要说明的是,对于非常复杂的函数,拉格朗日方法有一定的缺陷,就是在区间的头和尾误差非常大,数学里称作龙格效应,用三次样条插值来举例,因为大部分复杂函数会使用三次样条插值来获得一个平滑的曲线,让每一段函数衔接自然。这里给一个图就可以直观的看出来。
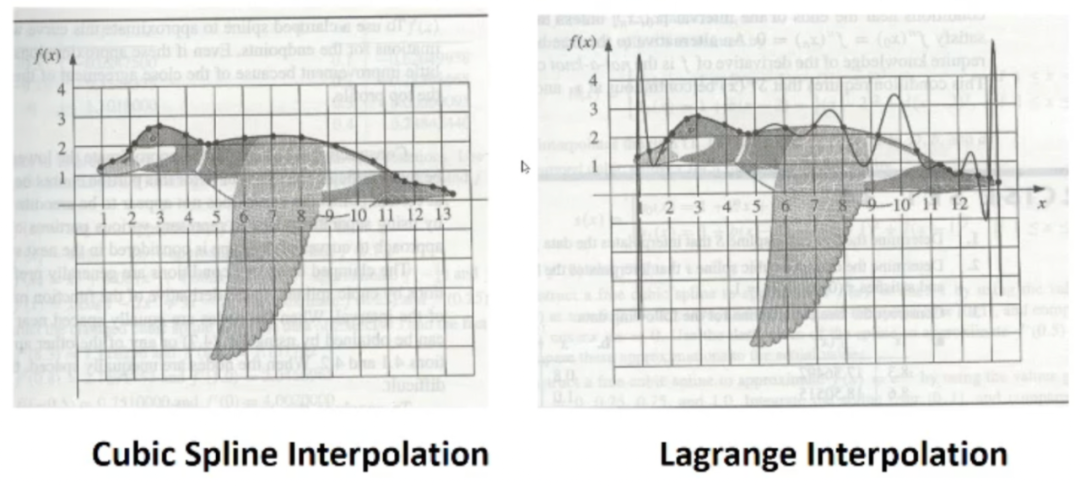
左边是三次样条插值计算出来的头背部曲线拟合函数,而右边就是拉格朗日插值,在区间头尾函数震荡的非常严重。两个算法都是通过分段的方法,但是在每段之间的衔接上,显然是三次样条做得更好,并且在给定条件下,准确率可以在99.99%。但是三次样条插值法拟合近乎完美,为什么starkware不使用,这是因为电路门的数量太多,一般都要大于100w,所以函数的阶次是在100w到1亿之间浮动,那么如果x^1000000到x^1000000000方程用x^3函数进行插值,那么计算量显然很大,意味着复杂度很高,所以还要解决复杂度的问题。
下面看一下starware使用的低度测试方案怎么降低复杂度:FRI协议
FRI:Fast RS IOPP。FRI主要优势就是更有效,原理是测试一个点的集合大部分是在一个度小于某个值的多项式上。
-
Bob声明自己有10^6个整数,并且每个整数都在0~9之间,请问Alice能不能再询问两次之后99%确认Bob的声明是正确的?
-
Bob声明自己有10^9个数,并且每个整数都在0~9之间,请问Alice能不能再询问两次之后99%确认Bob的声明是正确的?这时候需要增加一个条件:Bob需要提供一个多项式g,阶次在10^7-10^6,
此时Alice就可以通过分别在原函数和条件函数g中各询问一个随机点,就可以99%通过Bob的声明。
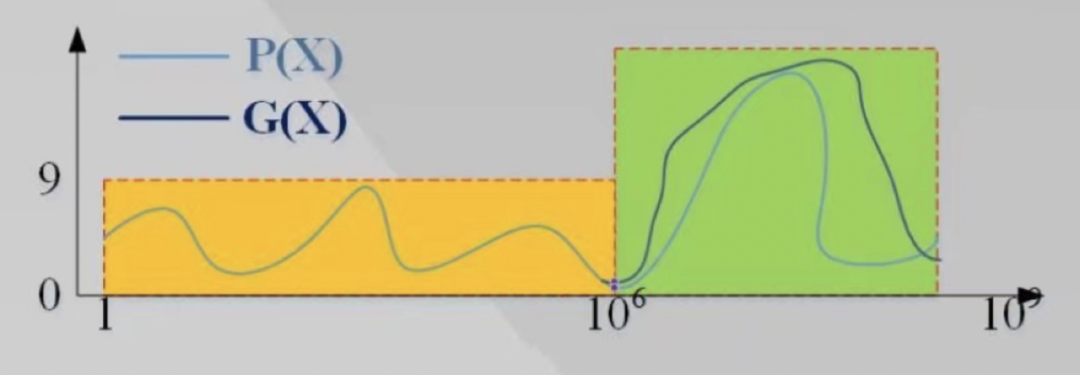
第2步将函数的范围扩展,目的之一是为了不透漏原函数的一些具体信息,可以在10^6之后进行插值测试,同时RS编码用来保证容错率。
简单来说**FRI协议的过程就是分为两个阶段,commit和query,**验证者发送随机数给证明者,证明者生成新的函数,验证者根据证明者发来的结果检查一致性(不矛盾性),如果一致则通过。那么通过的可信概率方面,1-10^{-2k},k是询问的次数,询问一次有99%的概率,询问两次达到99.99%的概率,所以理论上,通过询问但是错误的概率可以忽略不计了。
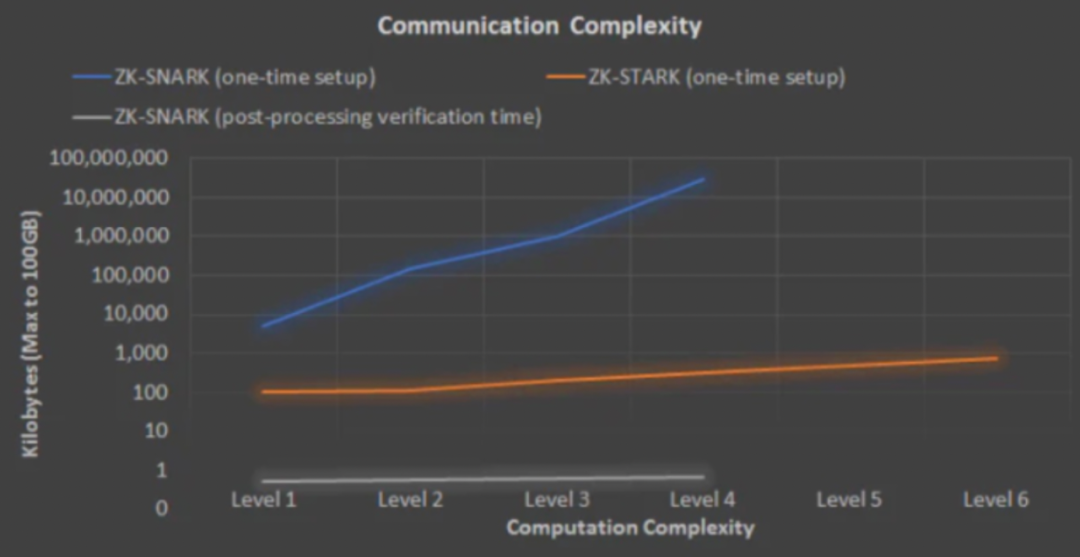
下面再通过两幅图的比较,可以看出作为snark的替代版协议,stark在复杂度和验证时间上都有很好的现。横坐标是复杂度等级,复杂度每提升一个level,相当于复杂55倍,这里的复杂度是指电路门的复杂度。黄色线条显然是比蓝色上升速度要缓慢很多,包括验证者时间,复杂度提升几个度,和snark相比,stark的验证者花费的时间几乎没太多变化。主要原因就是插值函数和验证方面的改变,将这些做了很大的提升。
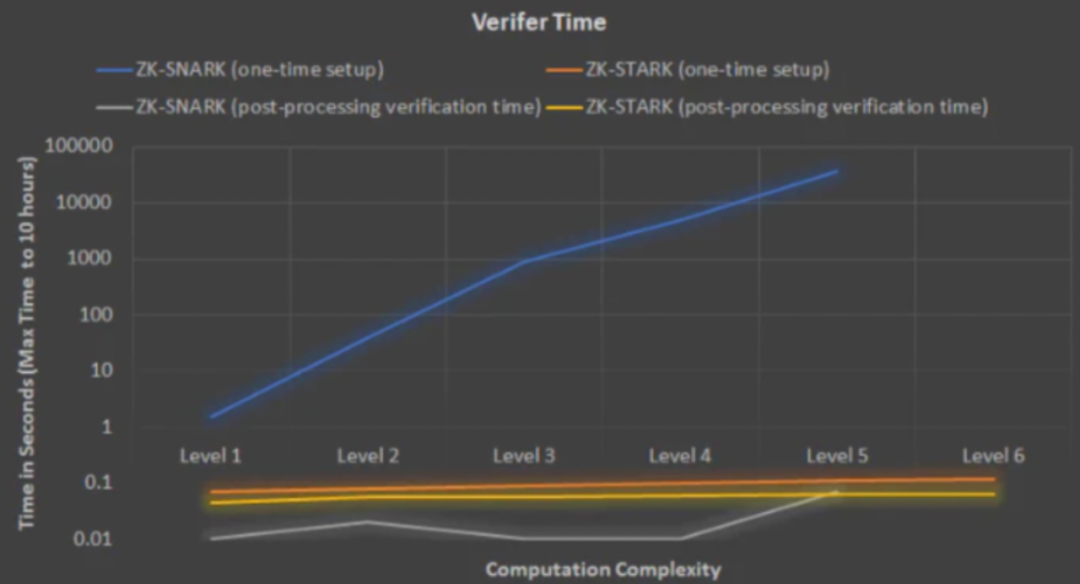
**Starkware的FRI协议,可以保证零知识证明的属性,**验证者不能访问轨迹多项式里面的点,因为多项式里包含了隐私值,只需要随验证,由验证者和证明者协商确定,并且不需要第三方的可信设置。不依赖任何数学难题。和snark相比,确实有很大程度的优化。
现在来说一下stark的架构,首先目标是给定程序A,输入x,输出y和时间界限T,生成一个证明π来证明:
“A(x)在T个计算步骤内输出y”
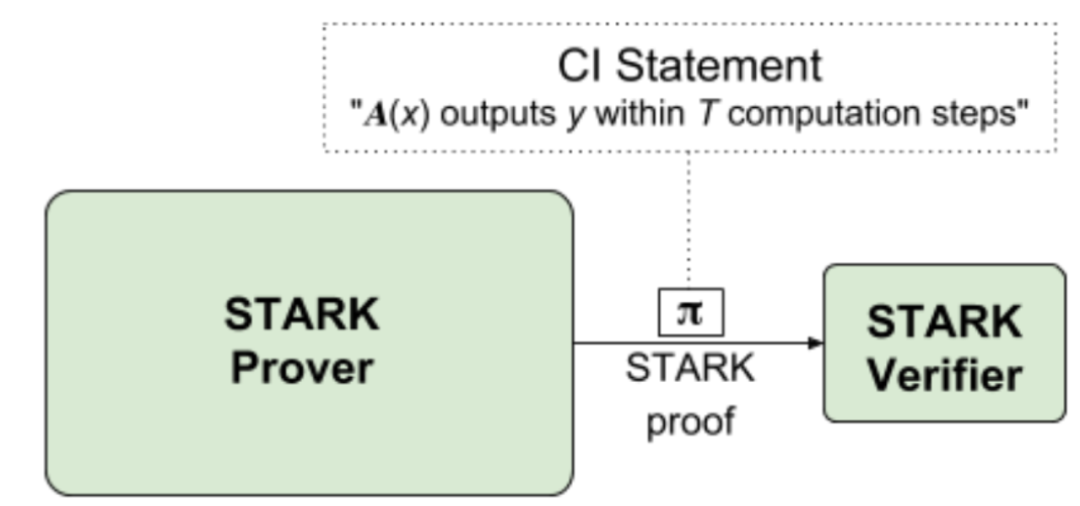
Stark满足以下属性,并且以下所有涉及到的模块都是为了让stark程序满足这两个条件
-
可扩展性(生成π的时间和T成拟线性)
-
透明度(没有陷门)
大致步骤:
-
首先是**证明系统,用的micali结构,**这种结构的证明系统统称为PCP(概率可检查证明),并且提供透明和可扩展性。
-
**交互式预言机证明(IOP)**设计更高效的协议,PCP只是一种非交互式IOP
-
**BCS结构,**它是Micali结构的扩展结构,高效的Stark都是通过BCS构造的
先来说**PCP密码证明:**设计低成本的本地检查和长证明Ψ, Ψ的步骤要比T长很多,但是优点是可以通过概率测试来验证,并且概率测试值读取Ψ的一小部分,如果发现错误,会有很高的概率去拒绝该证明。
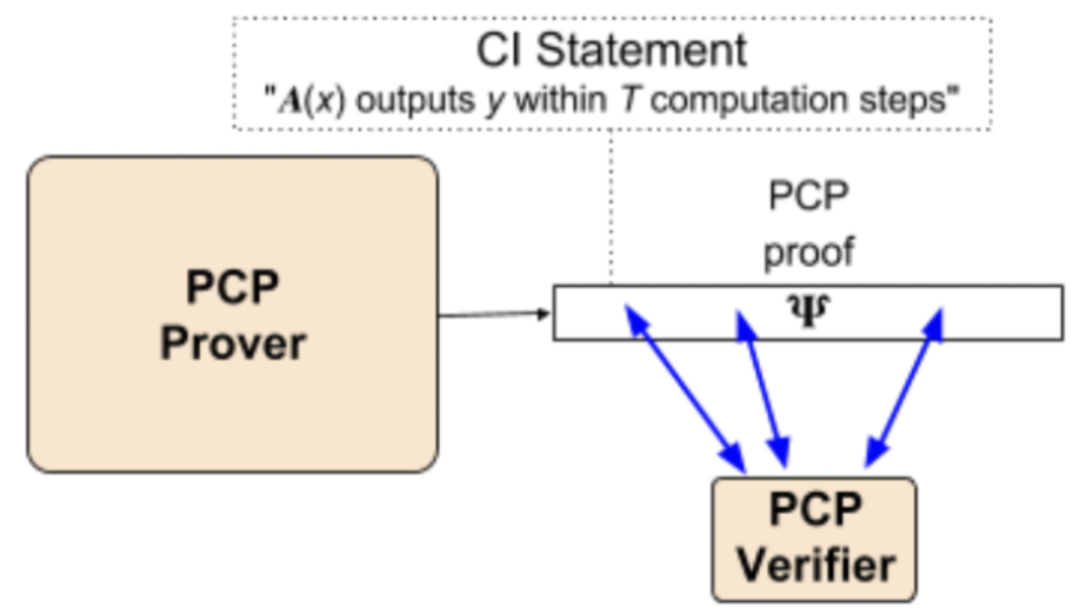
但是再回想stark本身的目的,是生成简短并且能快速验证的证明π,这和PCP完全不同,PCP是长证明Ψ和低成本的本地检查。那么如何从Ψ到π。这可以通过加密散列函数来实现。
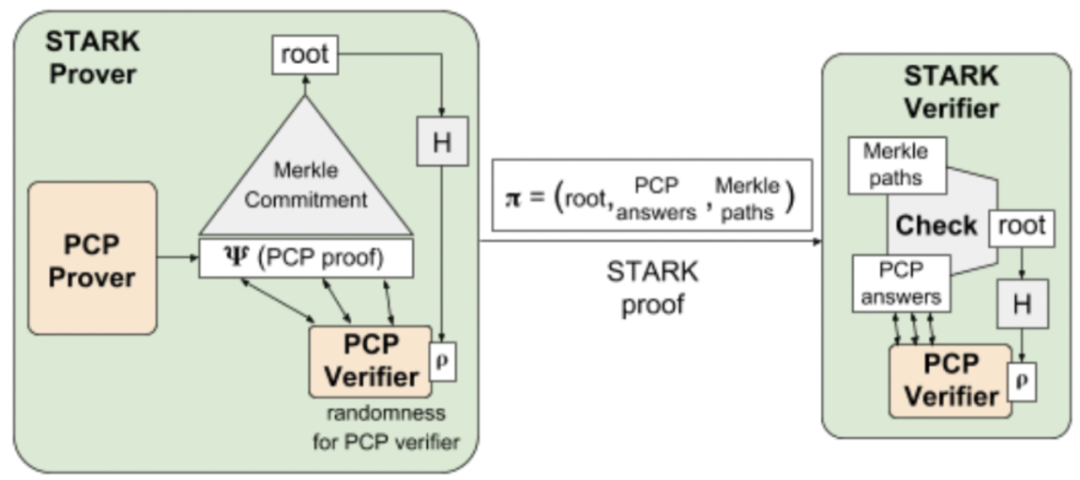
证明者需要使用哈希函数H通过merkle根提交长证明Ψ,然后通过H对merkle根哈希,得到随机性ρ,确保随机性。**总而言之就是用哈希函数H来实现安全预采样。**但是因为在实际应用中,PCP的成本很高,所以stark并不是给PCP,而是交互式的概率证明:
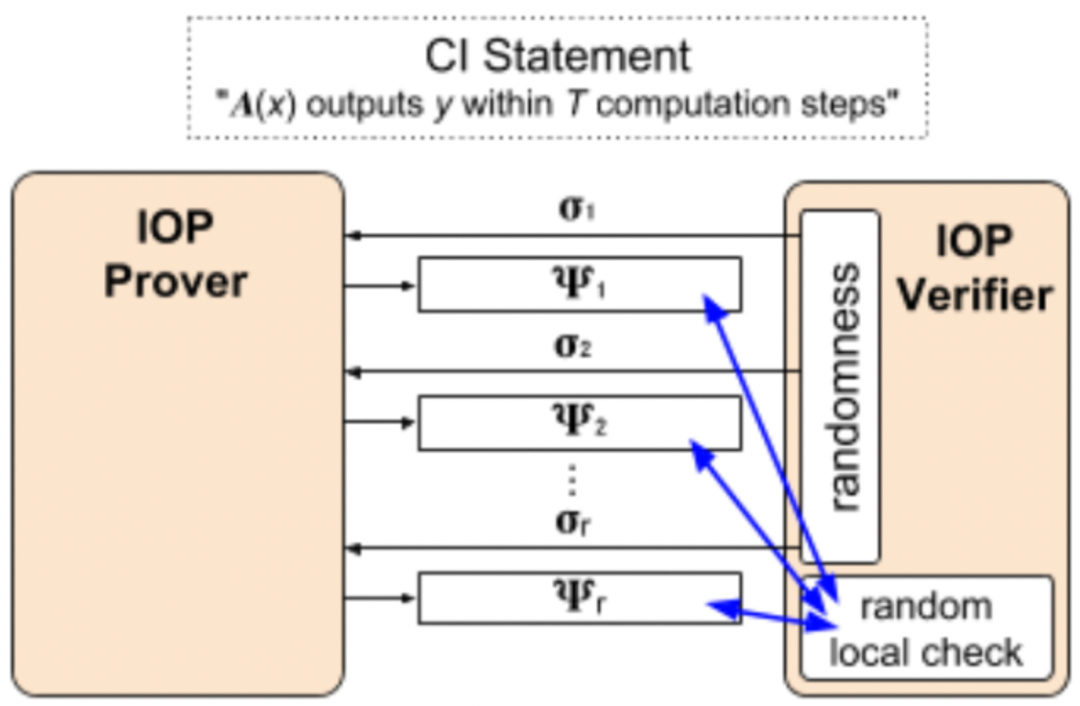
结合之前所说的,流程就是结合给定的CI语言转换为多项式,算数化,在进行低度测试,局部检查一致性,一致的话就会以高概率通过通过检查,反之亦然。
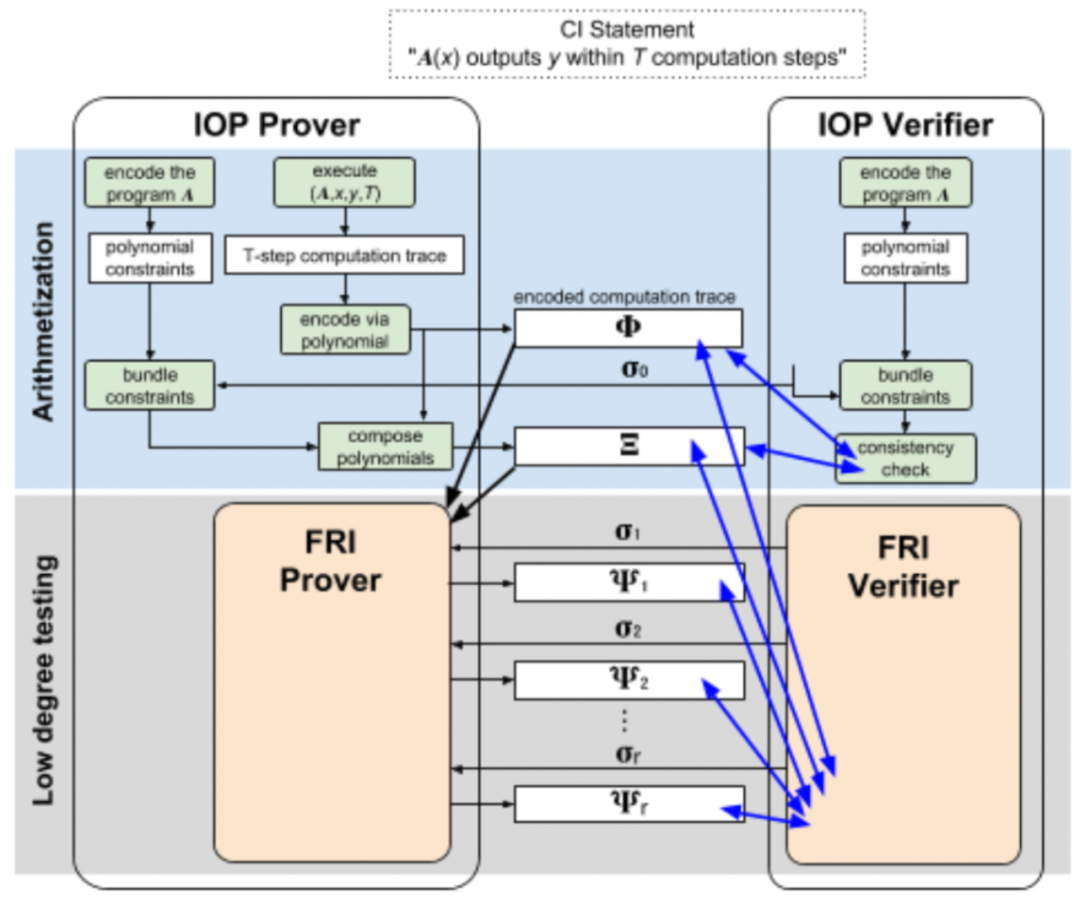
最后通过BCS(区块链服务)构造高效的stark,将IOP和H结合获得密码证明,并将每一轮提交在哈希链中。
总结
Stark可以解决区块链新世界中的CI问题。高效STARK是由一种概率证明IOP和哈希函数H结合构建的而来,可扩展性由IOP提供,透明性由哈希函数提供。吞吐量可以大大提高,并且在性能方面超过snark和bulletprrof很多倍。