
Author introduction: Changbin, senior technical director of a global blockchain company, has more than ten years of R&D development experience, and has accumulated more than 5 years of blockchain engineering experience. The consensus protocols that he personally implemented include POW, POS, POS+BFT, Tendermint, etc. His main interest areas include high-performance public chains, blockchain big data, and decentralized application platforms. Most of the content in this article is compiled from the sixth Office Hour of CFG Labs. For those interested, you can watch the sixth office hour of CFG Labs@0x_Atom Scalability method for high-performance public chain (Monolithic chains) via the links below: https://www.youtube.com/watch?v=BBsrFZFkNBg
Reminder: The content insights and perceptions of this article are partly derived from the research of the speaker's organization, which only represents the speaker's own views, not the views of cfg labs and the speaker's organization, nor any investment advice, DYOR. The content of this article comes from the video transcription and compilation. After the first release, the speaker found that many information was distorted and made comments. In the spirit of seeking truth from facts, this article is republished after proofreading by invited speakers. Interested community members are welcome to join our community to communicate.
Overview

The opinions and insights of this office hour are the joint research of many students from the current organization @stars_labs, no financial advice, DYOR.

This office hour will introduce L1 performance tuning from four aspects.
- The first is the model, because we want to optimize, so we must understand what the business model, network model, and mathematical model are, and then we know where and which parts can be optimized.
- Secondly, we should pay attention to the environment. When we are doing performance tests or reading ultra-high-performance data, the first question is to ask what the test environment looks like.
- With the support of these two backgrounds, we will introduce what methods are currently available in the industry for optimization, and what are some good examples.
- Finally make a conclusion
Model
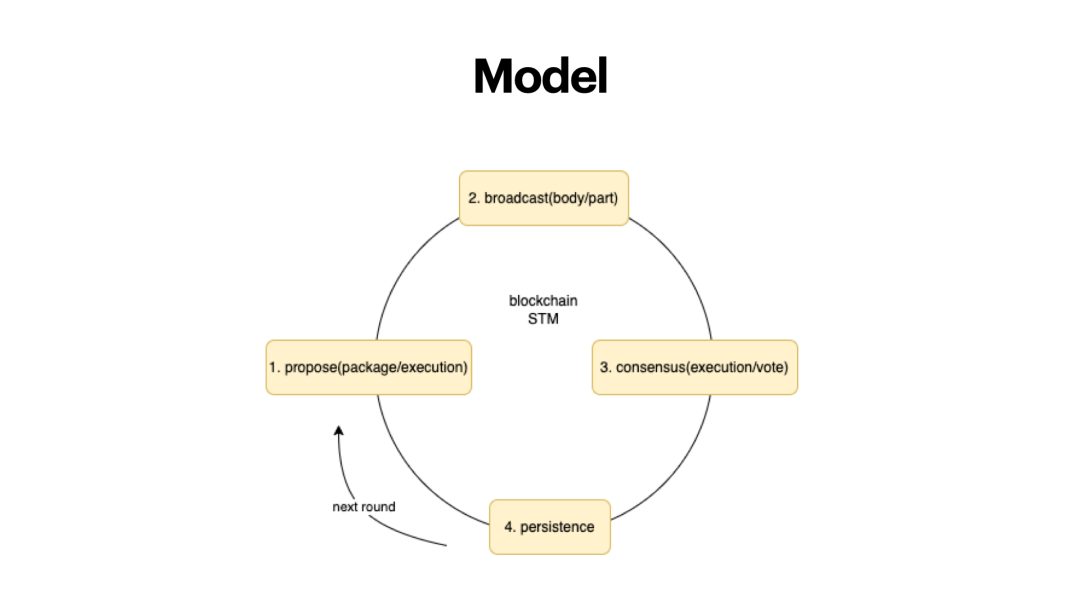
The first is the model, this is the blockchain model for Ethereum, and other public chain frameworks are similar to this.
The first step, proposer of the block, proposes a block, and is responsible for packaging, which involves two parts, 1) the order of the transaction and 2) the result of the execution of the transaction. The traditional Ethereum model proposes POW miner (miner) to package the transaction and combine several Hundreds of transactions, how many transactions, each transaction will be executed once. The state of the Ethereum world is essentially a state tree. The content of the state tree changes according to the content of the transaction, and finally the root of the Merkle tree is generated.The second step is to broadcast the block together with the block header or block body. There are different methods for broadcasting. For example, the entire block can be broadcast, but the efficiency may be relatively slow. The block header can also be broadcast, which includes the block hash, which can identify the uniqueness of the block, and some blockchains use a compromise between the two. Finally, block transactions must be broadcast.
The third step, consensus, also involves two parts, because other nodes need to verify that your ledger is correct before consensus, and to verify whether there are double-spending transactions, malicious transactions, and wrong transactions. If it is the BFT consensus, it involves two more rounds of voting with more than 2/3 votes including pre-voting and commit voting. In this process, you find that the first and third steps are both executed. The same transaction is executed multiple times on multiple nodes, which brings a lot of room for optimization.
The fourth step is to write to the blockchain. If it is POW, the verification of the nonce and the root of the hash state number after the transaction is executed are also legal, and finally written to the local database (ledger).
In such a model, there are a few things that can be optimized. After the block proposed, the broadcast content can be optimized, and the block hash is used to replace the complete block. Algorand is the first to do this. Solana also adopts a similar Turbine broadcast method to make the broadcast of blocks and transactions faster.
Environment

I think the blockchain has to solve the limitations of the physical environment through three ways: computing, bandwidth, and storage before mass adoption.
Computing (CPU)
The first layer is the computational bottleneck. If we observe the CPU consumption of blockchain programs, we will find that the verification/signature process consumes more CPU, because the calculation of elliptic curves is CPU-intensive. We have done tests and it takes about 30% of the CPU. That is to say, the number of transaction signatures verified by the home computer in one second is limited, for example, several thousand/10,000 transactions, or a little higher.
Optimization method: It can be optimized through the progress of cryptography itself, customized hardware, hardware acceleration, etc.
Bandwidth
When you break through the computational bottleneck, you need to send out blocks and broadcast the state to other nodes, which will bring about time problems. For example, the propagation of a 1MB block on the Bitcoin network requires the average time of 6-12s. Therefore, if the blockchain is built on civilian bandwidth (without dedicated lines), assuming we use the classic way of broadcasting blocks, the performance that can be achieved is limited. Here if we calculate, assuming that the civilian bandwidth we use is the median of 50Mb-100Mb, and calculate the size of each transaction, we know that the TPS is in the thousands. Nowadays, many high-performance blockchains do not use civilian bandwidth, but use high-speed direct connections between IDCs. If there are multiple data centers, there are also dedicated lines for intercommunication.
If you have never deployed a blockchain, you would see a blockchain as an ideal state, but it is not. Generally, many POS blockchains have low liveness, and if you are not careful, the entire network will terminate. But this is off topic.
Optimization method: Use block hash instead of full block, or use organized broadcast method instead of full gossip.
Storage
The third bottleneck is the storage bottleneck, because you have done all the optimizations, including thousands of TPS, tens of thousands of TPS, and finally all your data will fall on the disk, bringing storage pressure. At the same time, the hardware performance of disk is much worse than that of CPU and memory. So you will find that in the gas consumption table of Ethereum, the sload/sstore instruction, the call instruction to the storage, consumes a lot of gas. He needs to be controlled in this way, or protected from DDOS attacks, otherwise when a transaction comes up, I desperately call storage, which may stop the entire chain.
Blockchain data consists of several types:
- Transaction data, original transaction data, this part of historical data can be deleted without affecting normal consensus.
- The data for the account information, such as the event status of Ethereum, this data cannot be deleted. If it is deleted, the availability of the node will be low.
The expansion of this part of the data will bring about the problem such as state bloat. The current data of Ethereum is more than 1T, and it will be larger if the running time is longer.
Optimization method: 1) Optimize according to the organizational structure of MPT and the characteristics of statedb. Using the pruning rule can reduce some space occupation, and some new clients (erigon) will adopt different organization methods, which reduces the pressure on disk reading in the process of data organization. - The storage billing model is optimized. For example storage leases. Storage leasing means that the internal space is not like Ethereum, which can be permanently stored on it if it is put on it, but is stored in a leased manner. If you don't renew, the space becomes unavailable. The earliest examples can be traced back to the Nervos project, and Sui, which we have written about last week, uses a similar mechanism. This mechanism incentivized players to store but in essence I think it does not solve the problem, so eventually the data will bring the problem of state explosion.
For example, in BSC, we will run BNB nodes on a daily basis. Ordinary nodes are at 10T, and archive nodes are also at 10T and 20T (if the running time is long). The archive node is the node starting from block 0 and will always increase. Most of the ordinary nodes are nodes that have been cut to save some space.
This structure is actually not sustainable. However, there is currently no good solution for BSC, so it adopts a multi-chain structure. In the modular blockchain thesis, you can use the app-chain structure where the storage for different app-chains is separated. We have also seen some similar solutions for the Consortium Blockchain. Sui and Aptos are also good examples. I believe there will also be some scalable solutions for the consortium blockchains. For example, distributed storage is an efficient and direct mechanism for data scalability.
Environmental Summary
The above is the problem of the environment. So, if we see who has proposed tens of thousands, hundreds of thousands of TPS, we need to see what the test environment is like.
- First of all, what kind of hardware does it use, such as what CPU, how much memory, what hard disk, and what network bandwidth.
- The number of nodes, this indicator is very critical. We checked Sui's documents and test data, and they only used 4 or 10 nodes on 1 IDC, this is not very convincing. We will also pay attention to such data when we are doing data stress testing. If you set up a network with 3 nodes and a network with 100 nodes, the concepts are different.
- The node distribution method, your nodes are all distributed in the world, on multiple continents, or several machines in the same availability zone of an IDC on Tencent Cloud, which is completely different. We need to check the specific data testing environment, which will be helpful. When we check the indicators, we need to understand its real data test environment which will help us to identify its real performance.
- At the same time, we also need to look at the transaction (TPS). For example, Solana has a voting mechanism and will also include the voting transaction into the TPS, so the TPS is around 5000 (including transactions), but this will also have potential problems (introduced below) .
Method
Flow
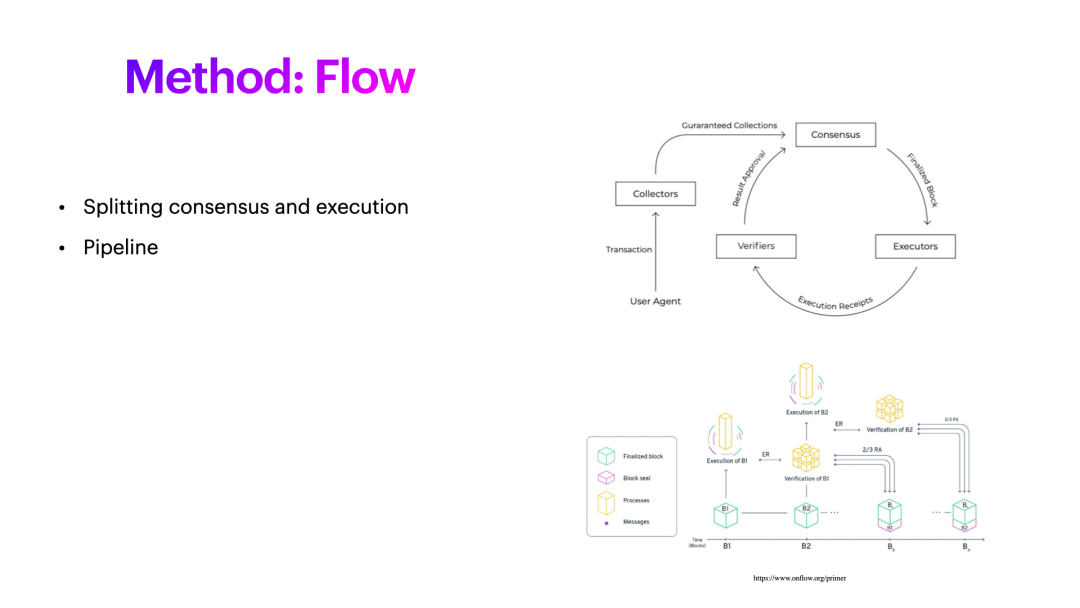
There are more roles in the design of Flow. For example, the collector, the transaction is received, the collector can do pre-verification. In Ethereum, the easiest way is to verify its signature. Of course, this will consume a lot of performance. At the same time, you can do some basic verification, such as when transferring money, you can verify whether the balance is enough. So these basic contents can be checked. Collector will then send a batch of transactions to Consensus for consensus, execution, and then get the result, which we will call Receipt. This execution does not mean verification. Execution means that you have a result, and you use this result to verify whether your execution is correct. So there is an additional role for the verifier. In the second part, it is also mentioned that the entire consensus process is made into a pipeline. It is not necessary to wait for a block to complete the consensus. After the verification is performed, the next block can be made. You can do two blocks at the same time. It can be delayed, which is what Flow does.
Solana
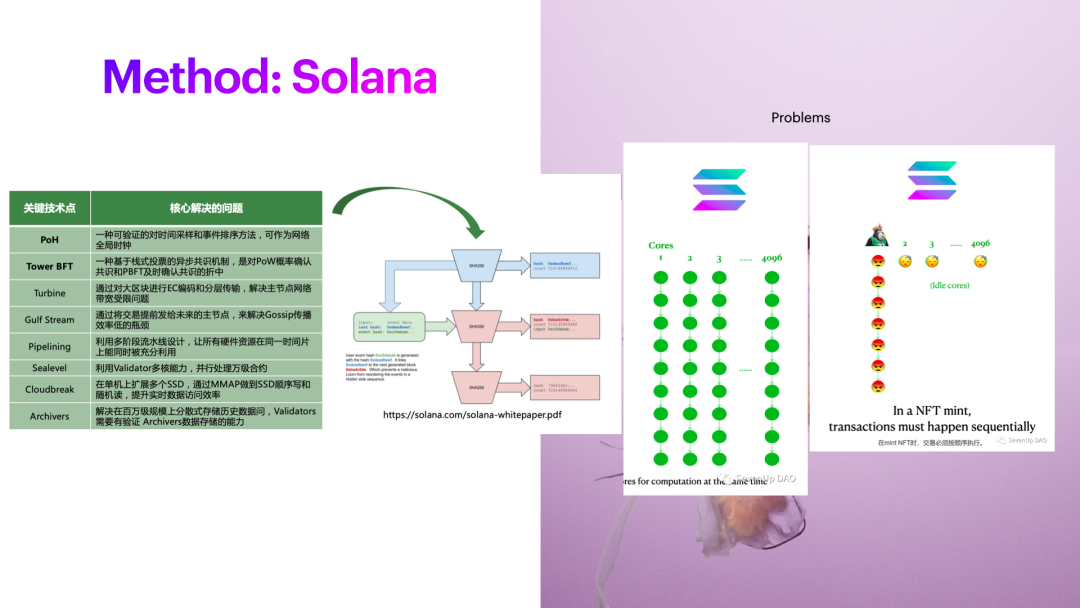
Let's take a look at Solana's approach. Solana is a different project. The global clock is not a new thing in the computer, but it is the first time that the global clock is implemented through a way of calculating hashes, and it is the first time that it is used on the blockchain, which is conducive to the ordering of transactions. The turbo mechanism is also used, which essentially solves the performance bottleneck problem during the network broadcast process by passing blocks through this special transmission mechanism. Guild Steam is the same. When each node knows when to produce blocks in the next stage, and what content should be included in the block, I don’t need to do P2P broadcasting like Ethereum, and I don’t need to do so many transaction comparisons. .
But there are also some problems here. For example, Solana has introduced a lot of parallel execution. The premise of parallel execution is that your transactions, the read and write sets, and the modified content don’t conflict. Only content that does not conflict can be put on the GPU for execution. For example, the GPU has 4096 cores, but here comes the problem. If you are making cash withdrawals on Binance, there may only be one or a few main hot wallet accounts on Binance, so everyone's accounts will be blocked here.
When some well-known NFT projects Mint, the situation is the same. Because all are rushing to the same NFT project, it will involve the problem of input/output data in the NFT project itself, and it is impossible to enter the transaction into so many cores of 4096. It can only be executed on one core. Suppose there are too many transactions, which will cause your leader to collapse and need to be re-chaotic. Because the rules must be formulated, in order to optimize performance and reduce redundancy, the next step is to skip the lead and re-execute the transaction. So basically The premise that multiple transactions can be executed in parallel is that transactions do not have the same set of input and output.
Sui

Sui is innovative, Narwhal & Tusk. Narwhal is the protocol of Mempool, and Tusk is the consensus protocol, which connects the Mempool pool and the consensus itself for optimization, which is also the future direction for blockchain optimization. In essence, in the process of packaging or consensus, you need to organize these transactions reasonably and ingeniously, so that these transactions appear appropriately on some of these producers that should appear, preferably here The loss of messages is at least O(1), or O(nlogn), in this way, the overhead of network messages is minimized and the speed of transaction finalization is accelerated.
https://arxiv.org/pdf/2105.11827.pdf This article has won the best academic paper of EuroSys 2022, the top academic conference. Its main contributions include the DAG structure to organize the mempool, and used this Tusk to transform based on the Narwhal-HotStuff consensus. When you make a consensus algorithm, you need to consider the applicable environment of the Consortium Blockchain and the public chain. In the Consortium Blockchain, there will be no malicious nodes that propose illegal blocks, but a public chain is permitted, so it needs to be considered.
DAG
Here let’s revisit DAG.
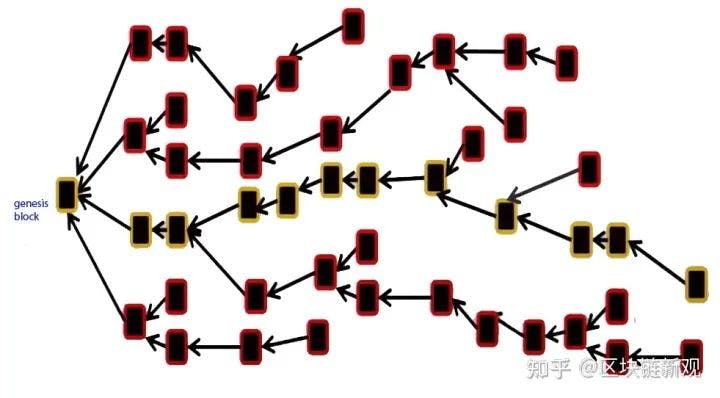
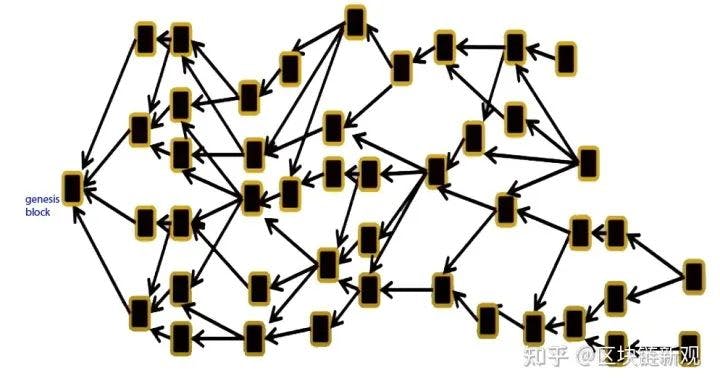
The core of the DAG is:
- Transactions can be sent at will, but each transaction needs to include confirmation of some previous transactions, and blocks need to confirm some transactions, which is naturally organized into a mesh model. The above is a blockchain, each block has only one parent, and can only confirm for the previous block, and the bottom is a DAG structure. One block will reference multiple blocks, so the question arises. DAG becomes an effective acyclic graph, a concept in graph theory, why do you resist this concept? When we learn data structure and discrete mathematics, this will become more difficult, discrete mathematics will be more difficult than probability, and for data structure, graph theory algorithms will be more difficult than list algorithms.
- There needs to be a mechanism to find the real canonical chain, otherwise your ledger structure doesn't know how to express it. This leads to the second coordinate, the introduction of the center, and the structure of the coordinate is mostly centralized, hence the assumption that no malicious attack is required. So the consensus of pure DAG is not perfect. DAG is not easy to understand, and it is more difficult than general algorithms when it involves graphs. Not so intuitive.
Conclusion

- At present, many implementations need to introduce centralized components to support smart contracts. For example, suppose an account may have different content at different nodes and at different times, which is caused by the absence of a central chain. Suppose it is the account structure of the ledger structure, not UTXO, and needs to support smart contracts. At this time, a centralized mechanism is required to realize the center. The optimization of Sui, DAG is used in the mempool, which is then embedded in the consensus of BFT.
- When discovering a new project for the ultra-high performance, we must first understand its structure, how to achieve ultra-high performance, such as modularization, or a pure L1
- Secondly, the performance is dependent on its test environment. What things have been done to achieve such high performance. If a mempool has not been optimized, broadcast has not been optimized, no pipeline has been done, and no parallel execution has been done. It will be unlikely to achieve the performance.
- I believe in innovation. I have been in the industry for 17 years. I have been working for the public chains in the past few years. The consensus protocols that I have implemented for the Turing Award include POW, POS, POS+BFT, Tendermint, etc. In the past two years, new public chains are in full swing, such as Solana, Libra public chains, etc., the performance has been improved by orders of magnitude. After careful analysis, we are entering the era of intensive cultivation, and each stage of the blockchain needs to be adjusted to the extreme according to the design requirements. In the future, we will continue to work for the public chain performance improvement, and strive to improve the L1 performance by another order of magnitude to millions of TPS.
Reference
Information Propagation in the Bitcoin Network: https://sites.cs.ucsb.edu/\~rich/class/cs293b-cloud/papers/bitcoin-delay
Ethereum->Solana->Aptos: Where is the end of the competition for high-performance public chains? : https://mp.weixin.qq.com/s/07MlRKpL6IqACRRI26KHzg
DAG introduction: https://www.zhihu.com/column/c_1430668549379903488(https://www.zhihu.com/column/c_1430668549379903488
Community questions:
- Frank: How to understand the high degree of decentralization of Ethereum?
Changbin: If you go to the developer conference and read the research, they take decentralization as a basic guarantee. - The number of nodes Take the Ethereum 2.0 node as an example. The degree of decentralization depends on the number of nodes. There are 6000-7000 Ethereum miners and more than tens of thousands of validators (of course, one machine can run several). A sufficient number of validators brings enough randomness, and the possibility of collude to attack the network or part of it is greatly reduced.
- The requirements for nodes should be as low as possible, so that more ordinary people can enter the network with their computers on quickly. The improvement of Ethereum 1.0, in order to allow users to quickly synchronize the latest state in a very short time, such as a few hours, they have spent much of the engineering effort. So decentralization is the core capability. Therefore, the progress of Ethereum has been relatively slow.
- Look at EOS, Tron, HECO, BSC, reduce the consensus to 21 nodes, and super nodes normally require high configuration, which will bring about the problem of centralization. These networks all have core intranets, and because these network nodes are very few. If there is no core intranet, any DDOS will stop the network, so the network liveness is very low, so there must be an intranet. The connection between the intranet is interconnected, the block-producing node and the block-producing node are connected through IP addresses and whitelists, which cannot be accessed from the outside. Extreme centralization in exchange for performance business Let's look at Solana again, and take a step forward. It claims to have hundreds of nodes. What's the problem? The block production sequence for nodes in each epoch is fixed. If you are idle, you can really DDOS. Do you know when? , which nodes are producing blocks. As you know which nodes are producing blocks in which epoch. If you send DDOS traffic, you send a few hundred gigabytes. If you kill it, you won't be able to get a block. Once there is no randomness in the block generation candidate stage, a fixed order is used for speed, for performance, there is no randomness, the activity of the network, the possibility of being DDOS is high, and the degree of decentralization is low. The Ethereum network is fully redundant, and if one node is killed, other nodes can continue to work. Ethereum 2.0 has tens of thousands of validating nodes, and the order of producing blocks is relatively random. In the future, they will use the VDF function and the delay function to decide. You cannot predict in advance which shard a node is temporarily assigned to. On each block-producing committee, the high degree of randomization will be possible and it significantly increases the security. This is very different.
- Chloe: How to explain Solana's mechanism problems and DDOS attacks, as well as many voting transactions on the network?
Changbin: Solana does not have a market competition mechanism. Unlike on Ethereum, you need to increase the gas fee to move the transaction forward. Solana places transactions directly in the mempool. Assuming that millions of people joined the particular mint, the transactions can only be done by one Core, and the transactions are piled on one lead node.This lead node will be difficult to become available again. It's not an attack to be precise, but a proper mechanism is not actually introduced. In fact, the Ethereum gas market adjustment mechanism is a good solution to the problem of network availability. 1) When there are too many transactions, Ethereum caches the transactions sent by a user, the number is limited, and will not cache transactions indefinitely 2) If you want to make the transaction faster, the packaged transaction will be reversed according to the transaction gasprice, naturally There is a market that can resist this DDOS attack. 3) In the gas consumption mechanism, relatively slow instructions are also well protected. It is mentioned that the access to storage is very high. The problem of Solana attack has nothing to do with intranet deployment. It is caused by receiving a large number of these transactions and being unable to process them.
Voting transactions are included in TPS. Because of the BFT-type consensus, there must be a consensus voting process. Most of the consensus chains using BFT do not put votes in the mempool. Generally, there is a type of consensus message, which is independent. Solana is a special practice. This optimizes the performance with a complete set of solutions such as the faster consensus. The voting transaction is also regarded as a transaction and included which is based on his own design principle.
There are also many types of DDOS attacks. Before the emergence of the blockchain, some special TCP commands were used, such as initiating a connection sync command, but nothing was done, occupying server resources and making your server useless. After that, a lot of transactions will be sent to stop the block, which is also called the DDOS method. The cost of attacking Ethereum is higher than that of attacking Solana. If a lot of transactions are sent to block Ethereum, it will consume too much money. Solana generates too little transaction fees every day, and the attack is easier. - Jazzlost: Talking about consensus, L1 has some public chain pipelines and innovations in concurrent processing, including Avalanche and Solana. I think innovation at the consensus level will have a better effect on the improvement of the entire L1 than the improvement from the pipeline alone.
Changbin: Actually, nothing new has been produced in the past two years, and we have entered an era of intensive cultivation.
The seventh Office Hour of CFG Labs will be held at 9:00 pm on August 17th. Please scan the code to join the group if you are interested.