
作者介绍:changbin,某全球区块链企业高级技术总监,拥有十多年R&D开发经验,并且积累了超过5年的区块链工程经验。亲自实现过的共识协议包括POW,POS, POS+BFT, Tendermint等,目前主要的兴趣点是高性能公链、区块链大数据、去中心化应用平台。
本次内容大部分来源于编译于CFG Labs 第六次Office Hour,对内容感兴趣的童鞋可以看CFG Labs@0x_Atom第6次office hour-高性能公链(单片链)的扩展方法 =》https://youtu.be/BBsrFZFkNBg
提示:本文的内容洞察和认知,部分来自演讲者所在的组织的研究,仅代表演讲者本人观点,不代表 cfg labs 和演讲者所在的组织的观点,也无任何投资建议,DYOR。本文内容来自视频转录编译,第一次发布之后,演讲者发现诸多信息失真提出意见。本着实事求是的态度,本文在邀请演讲者校对后重新发布。欢迎感兴趣的同学进入我们的社群交流。
总览

本次 officehour 诸多观点和 insight 是来自目前所在的组织@stars_labs多位同学的共同研究,无财务建议,DYOR。

本次 officehour 将会从四方面介绍L1 性能调优。
1)首先是模型,因为我们要做优化,所以我们必须了解业务模型、网络模型、数学模型是怎么样的,之后我们才知道在哪些地方,哪些部分可以做优化。
2)其次要关注环境,当我们在做性能测试或者读到超高性能的数据的时候,第一个问题就要问这个测试环境是怎么样的。
3)有了这两个背景支持之后,我们介绍下现在工业界都有哪些办法去做优化,有哪些比较好的例子。
4)最后做个总结
模型
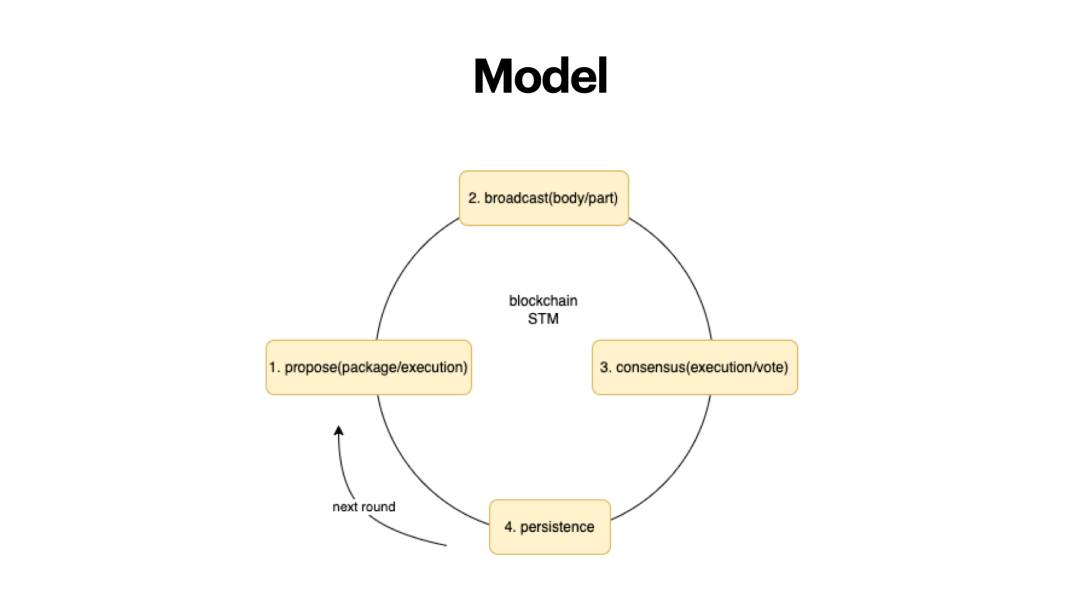
首先是模型,这是以太坊公链的区块链模型,其他的公链大框架跟这个也是类似。
第一步,区块的proposer,提议一个区块,负责打包,涉及到两部分内容,1)交易的顺序 2)交易的执行的结果 传统以太坊模型 propose POW miner(矿工)打包交易,将几百个交易,多少笔交易,每一笔交易都会执行一遍。以太坊世界状态本质是一棵状态树,状态树上的内容,根据交易的内容做改变,最后会生成默克尔树的根。
第二步,需要将区块,连同区块头或者区块体,一起广播出去,广播有不同的做法,比如说,可以把整个区块广播出去的,不过这个效率可能比较慢,也有可以把区块头广播出去,这里面包括区块哈希,可以标识到区块的唯一性,也有部分区块链是两者折中,最终区块的交易要广播出去。
第三步,共识,也涉及到两部分,因为别的节点在共识之前,需要去验证你的账本对不对,需要去验证这里面有没有双花的交易,恶意交易,错误的交易,需要去执行一遍。如果是BFT共识的话,又涉及到两轮超过2/3的投票。在这个过程中,你发现第一步和第三步,都有执行的过程,同一笔交易在多个节点上执行了多次,带来了优化的空间。
第四步,写入区块链,如果是 POW,nonce的验证、交易执行之后哈希状态数的根也是合法的,最后写到了本地数据库(账本)。
周而复始。
在这样的模型中,有一些事情是可以做优化的。区块提议出来之后,广播内容优化,使用区块哈希取代完整的区块,Algorand 最早就是这个做法,Solana也采用了类似的树状广播方式,让区块、交易的广播会变得更快。
环境

本人入行区块链的一位老师认为,区块链无非要突破的是三个层次的物理环境局限:计算、带宽、存储。
计算(CPU)
第一层是计算的瓶颈,如果我们观察区块链程序运行的CPU消耗,我们会发现,验签/签名的时候是比较消耗CPU的,因为椭圆曲线的计算是 CPU 密集型。我们曾经做过测试,占据30%左右的 CPU 时间。也就是说,家庭电脑1秒钟验证的交易签名数量是有限的,例如说几千/1万笔交易,或者更高一点。
优化方式:可以通过密码学本身的进步、定制硬件、硬件加速等方式进行优化。
带宽(bandwidth)
当你突破了计算的瓶颈之后,你要将区块发出去,需要将状态广播到其他的节点上去,这里会带来时间的问题。比如说1MB的区块在比特币网络上的传播,需要的时间是有统计数字的,平均时间大约是 6-12s时间。因此,如果区块链是搭建在民用带宽(不用专线),假设我们用的是经典的广播区块的方式,能达到的性能也是有限的。这里我们计算下,假设我们用的民用带宽是50Mb-100Mb的中位数,计算一下每个交易的大小,可知道TPS是数千的级别。现在很多的高性能区块链,其用的并不是民用带宽,用的是IDC之间的高速直连,如果是多数据中心的话,也是有专线互通的。
如果没有部署过区块链的话,会将区块链看做很理想的状态,但其实不是。一般很多POS区块链活性很低(liveness), 如果不小心,整个网络会挂掉。不过这是题外话。
优化方式:上文提到的,用区块 hash 替代完整区块,或者使用有组织的广播方式,而不是完全的 gossip。
存储(storage)
第三个瓶颈,就是存储的瓶颈,因为你做了所有的优化,包括几千TPS,几万TPS,最后你所有的数据都会落到磁盘上面,带来存储空间压力。同时磁盘相对于CPU和内存来讲,硬件性能是差很多的。所以你会发现在以太坊的gas消耗表里面,sload/ sstore 这种指令,对存储的这种调用指令,是非常消耗gas的。他需要通过这种方式控制,或者免受DDOS攻击,否则一个交易上来,我拼命调用存储,可能会让整个链停掉。
区块链数据包含几种类型:
1)交易数据,原始的交易数据,这部分历史数据可以删除,不影响正常的共识。
2)账户的信息数据,比如以太坊的事件状态,这个数据是无法删除的,如果删除的话,该节点可用程度就低了。
这部分数据的膨胀会带来状态爆炸的问题(state explosion)。以太坊目前的数据超过1T,如果运行时间长些会更大。
优化方式:1)根据 MPT 的组织结构和 statedb 的特性进行优化。采用剪枝的规则,可以减少一些空间占用,也会有一些新的客户端(erigon)采用不同的组织方式,使得数据组织过程中对磁盘读取的压力降低。
2)存储的计费模型优化。例如存储租赁。存储租赁意味着内空间不像以太坊,如果放上去就可以永久存储在上面,而是以租赁的方式存储。如果不继续续费,空间就变得不可用。最早的案例可以追溯到nervos这个项目上,我们上周介绍的 Sui也采用了类似这样的机制。这个机制在一定程度上在经济上激励去关注存储,但本质上我认为并没有解决问题,所以最终数据都会带来状态爆炸的问题。
比如BSC, 我们日常会运行BNB的节点,普通的节点在10T,archive节点也会在10T,20T, (运行时间长的话),这样的结构其实是不具有可持续性的。不过目前BSC目前也没有很好的解决方案,所以其采用了多链的结构。也就是说你有个超火的应用,他就会推荐你使用Appchain。将不同的应用存储进行分离,不会竞争。我们在联盟链上,也看到解决方案。Sui,Aptos也都是联盟链出身的,我相信之后他们也会采用联盟链的一些扩容的做法,比如说在存储上做分布式,可能看起来很中心化,但是一个有效、直接的实现数据扩容的机制。
环境小结
上述就是环境的问题。所以,如果我们看到谁提出了几万,几十万TPS的,我们需要看测试环境是怎么样的。
1)首先它用的是什么样的硬件,比如什么 CPU、多少内存,什么硬盘,什么网络带宽。
2)节点数量,这个指标非常关键,我们查看了Sui的文档和测试数据,只用了4个或者10个节点,在1个IDC上面,这个并没有很强的说服力。我们自己在做数据压测的时候也会很注意这样的数据,你组一个3个节点的网络和100个节点的网络,概念是不一样的。
3)节点分布方式,你的节点都是分布在全球、多个大洲,还是腾讯云上一个IDC的同一个可用区下的几台机器,这里面是完全不一样的,我们在看到指标的时候要看具体数据测试环境,有利于我们辨识到其真正性能。
4)同时我们也要看交易里面(TPS),有很多水分,比如Solana有投票环节,也会将投票交易算到TPS里,所以TPS在5000左右,但这个也会有潜在问题(下文介绍)。
方法
Flow
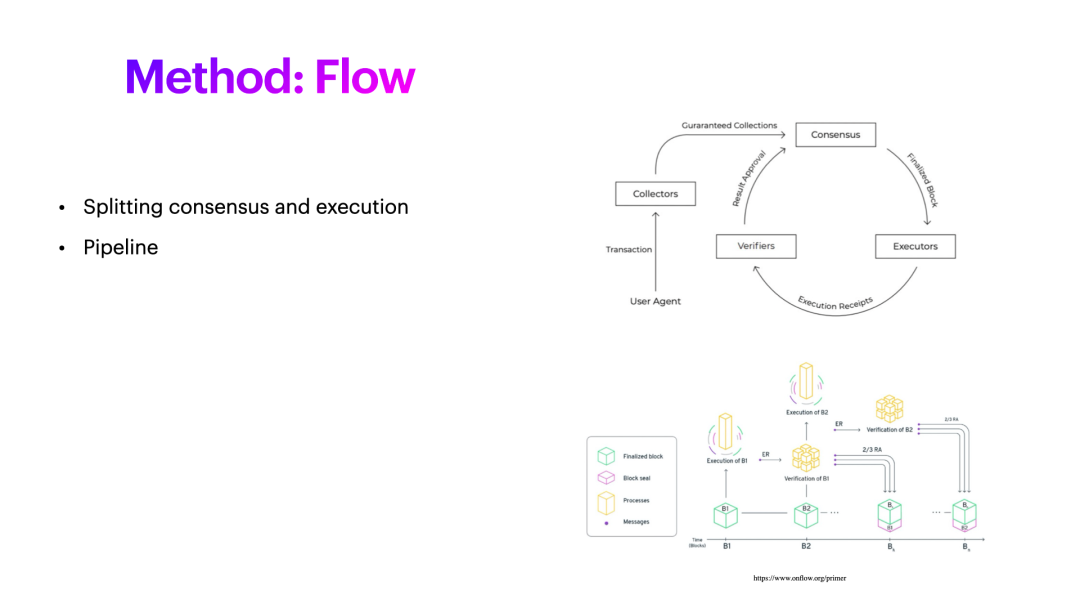
接下来我们看办法来优化性能。比如说我们看到的Flow这个链,他比较早的做了共识和执行的拆分,也就是说一个区块他的执行,和共识是可以拆开的,不一定放在一起,或者可以组成一个流水线,可以执行多个区块,接下来再延后去做共识,这样产块可以一直往前产。甚至还有一些方法,比如在一个Epoch里面选定了一个排列顺序,那么验证节点按照顺序去产块,每个节点知道自己什么时候该去产块,我就去产块,或者下一个epoch我去产块,这也可以帮助提高性能。还有一个方法就是一个生产者可以同时多产几个区块,一般以太坊是轮着来,但是一个验证节点可以产十个区块,再往前移一个,这也是扩容的方式。生产区块之后,结果对不对,能否成为真正成为权威区块链的一员,需要交给共识延后去执行,因为共识很慢的,假设你是投票式的,那肯定需要几轮的投票,时间肯定是比较长的,可以将共识和执行拆开。
Flow的设计中还多了些角色,比如说collector, collector收到交易之后,可以做预校验,在以太坊中,最简单的就是校验其签名,当然这里面会很消耗性能。同时,你可以做些基础校验,比如转账的时候,可以校验余额有没有这么多。所以这些基本的内容都可以做校验。Collector 接下来会把一批的交易给Consensus做共识,执行,之后得出结果,我们称为Receipt。这个执行并不代表验证,执行就是你有结果,你拿着这个结果验证你这个执行对不对,所以这里面可以再细分为Verifier。这里是拆分多个角色。第二部分,也提到了将整个共识过程做成流水线,没必要等完一个区块,共识,执行验证之后再做下一个区块,可以同时在做1,2的产块,同时共识的过程可以延后,这是Flow的做法。
Solana
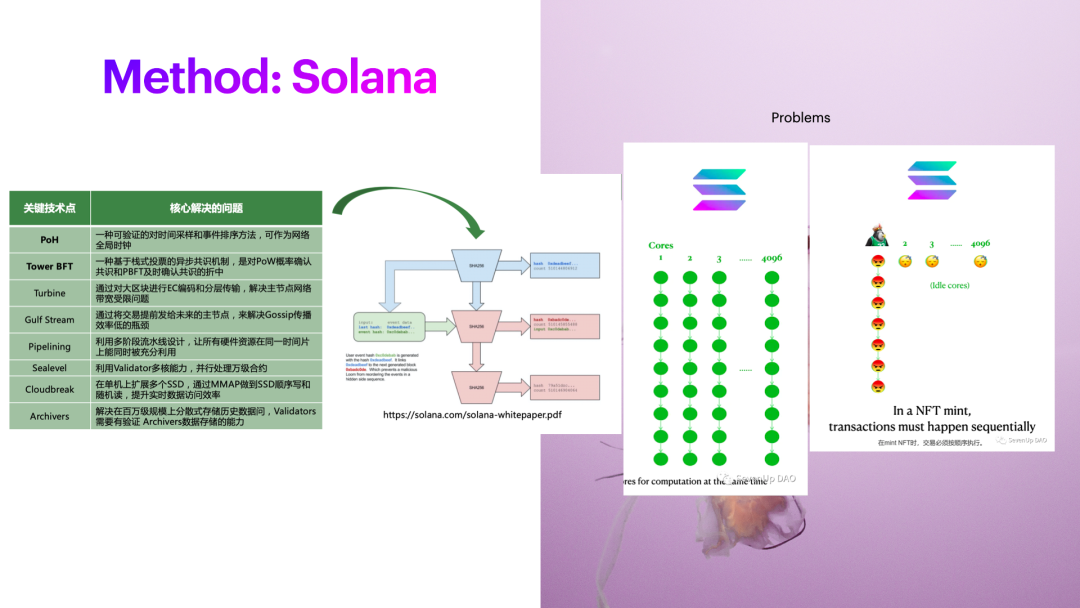
图片来自 @andrew 、@sevenupdao
我们再看下Solana的做法。Solana我们认为是一个眼前一亮的项目。全局时钟在计算机中并不算一个新东西,但是第一次用这种计算哈希的方式实现了全局时钟,用到了区块链上是第一次,有利于交易的排序。也用到了turbine机制,本质上将区块通过这种特殊的传输方式,解决在网络broadcast阶段的性能瓶颈问题。Guild Steam也是,当每个节点知道接下来哪个阶段改产区块了,区块里面该包含哪个内容的时候,我不需要像以太坊那样做P2P广播,也不需要去做这么多的交易对比。
但这里也会带来一些问题。举个例子,Solana引入了比较多的并行执行,并行执行的前提是你这些交易,他的读写集,修改的内容,是不冲突的。只有不冲突的内容才能把它放到GPU上去执行。例如GPU有4096个核,但是问题来了,假如你现在在币安上做提现,币安的主要的热钱包账户可能只有1个或者几个,所以所有人的账户都会堵在这里。
有些知名的NFT项目Mint时候,发生情况是一样的。因为所有的都在冲同一个NFT项目,会涉及到NFT项目本身读写数据的问题,无法将交易进入到4096这么多核中去。只能放在一个核去执行。假设交易特别多,会导致你的 leader 崩掉,需要重新混乱。因为规则一定制定了,为了优化性能减少了冗余性,所以接下来需要费劲的过程重新跳过这个lead,重新执行交易。
Sui

Aptos这个项目,我没有提,因为我看了白皮书和论文,基本原理,还是基于高度交易并行化改造,我认为相对于Solana没有那么强的革新性。
但是我认为,Sui是革新的,Narwhal & Tusk。Narwhal是Mempool的协议,Tusk是共识协议,将交易池和共识本身连在一起进行优化, 这也是我个人认为区块链优化的一个方向。之前我也想过这样类似的思路,本质上打包或者共识的过程,你需要合理的巧妙的去组织这些交易,使得这些交易恰当的出现在某些该出现的这些生产者上面,最好这里面消息的损耗至少是O(1)的,或者说是O(nlogn),这样的话最大减少网络消息的开销,加快交易的最终化的速度。
https://arxiv.org/pdf/2105.11827.pdf 这篇文章拿了EuroSys 2022, 顶级学术会议的最佳学术论文。贡献点引入了DAG结构组织交易池子,并且用这个Tusk基于Narwhal-HotStuff 共识做了改造,这些人就是Libra的同一拨人。当你做共识算法的时候,需要考虑联盟链和公链适用的环境。联盟链中,不会出现恶意作恶的节点,提议非法区块的情况,但是在公链,是无准入的,所以需要考虑。这个协议可能没有考虑公链,这种情况下该如何处理的这个问题。下周会继续分享这篇文章。
DAG
这里我们重温下DAG, 很多新入行的同学,或者对这个概念不是那么清晰,同时也会有一定的抗拒。
- blockchain
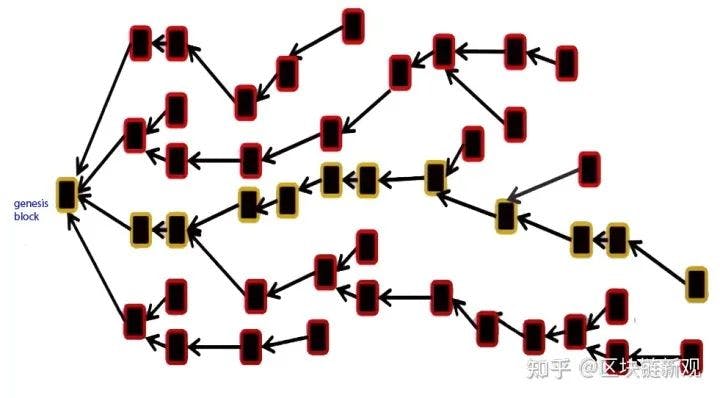
- dag
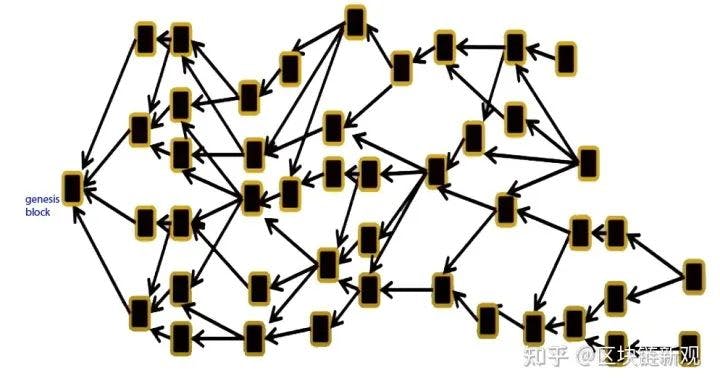
我在第一次读相关概念的时候,也产生了同样的想法。Conflux运用了DAG。
DAG的核心是:
1)交易可以随便发,但是每个交易你需要去包含对前面一些交易的确认,区块需要对一些交易的确认,这样自然组织成了网状的模型。上面是一个区块链,每一个区块只有一个parent, 只会对前面一个区块进行确认,而下面则是一个DAG结构。1个区块会reference多个区块,那么问题就来了,DAG成为一个有效无环图,图论里面的一个概念(大学学习),为什么会抗拒这个概念?在我们学数据结构,离散数学的时候,这个会比较难,离散数学会比概率要难,数据结构的时候,图论算法比列表的算法会更加困难。
2)需要有个机制,能够找到真正的规范链,否则你的账本结构不知道如何去表达。这导致了第二个coordiate,引入中枢,coordiate这个结构,大部分是偏中心化的。所以要假设,公正不作恶的情况,所以纯DAG的共识是打折扣。DAG 不好理解,本身涉及到图的东西,比一般的算法要难。不那么直观。
3)目前很多的实现,都需要引入中心化的成分才能去支持智能合约,因为需要最终的状态,否则会跟我们日常的感知很不一样。举个例子,假设一个账户,可能在不同节点,不同时刻,内容是不一样的,没有一个中枢链的情况而导致的。假设是账本结构的账户结构,不是UTXO,还需要支持智能合约,这时候需要偏中心化的机制实现中枢。Sui的优化,DAG用在了mempool 中,将DAG嵌入到BFT的共识。
总结

1)当发现新项目的时候,听说其超高性能的时候,首先我们要了解其结构,超高性能是如何实现例如模块化的,还是个纯L1,不一样的
2)其次性能要看他的测试环境,做了哪些事情,可以有这么高的性能,如果发现交易池子,也没有做优化,广播也没有做优化,也没有做流水线,也没有做并行执行,就不太可能。需要了解环境
3)相信创新,我是17年入的行,这几年一直在做公链相关的事情,亲自实现的共识协议包含 POW、POS、POS+BFT、Tendermint等。经历过几个图领奖项目之后,一度觉得没有什么可做的。例如 Algorand,论文中将VRF引入区块链惊为天人,但是最终看代码实现的时候,也退化到普通的类PBFT的实现。
这两年新公链如火如荼,例如Solana、Libra系公链等,性能上取得了数量级的提升,信心和兴趣又回来了。细致分析发现,已经进入到了精耕细作的时代了,区块链的每个阶段都需要根据设计需求进行极致调整。在接下来,我们还是会坚持在公链性能提升这个道路上去继续深入,力求将 L1 性能再提升一个数量级,到百万TPS。希望与各位朋友一起同行。
Reference
Information Propagation in the Bitcoin Network:https://sites.cs.ucsb.edu/\~rich/class/cs293b-cloud/papers/bitcoin-delay
以太坊->Solana->Aptos:高性能公链竞争的终局在何方?:https://mp.weixin.qq.com/s/07MlRKpL6IqACRRI26KHzg
社区提问:
1)Frank:怎么理解以太坊的去中心化程度高?
Changbin:如果你去参加过开发者的大会,看过research的东西,他们是将去中心化这个东西作为基本的保证。
1)节点数量举个例子以太坊2.0节点,去中心化程度取决于节点的数量,以太坊矿工6000-7000个,验证者超过几万个(当然1个机器可以跑好几个)。验证者的数量足够多带来的足够的随机性,合谋攻陷网络或者一部分的可能性大大降低
2)节点的要求要尽量低,才可以让更多的普通人,开着电脑,很短的时间进入网络。以太坊1.0的改进,为了让用户在很短时间内,比如几个小时内,快速同步最新的状态,他们花了多大的工程量。所以去中心化是核心能力。所以也导致了以太坊的进度发展比较慢。
3)再看EOS,Tron, HECO, BSC, 缩小共识规模,21个节点,并且超级节点,需要很高配置,这个会带来中心化的问题。这些网络都有核心内网存在,这些网络节点非常少,如果没有核心内网,随便一个DDOS会把网络打挂,所以网络活性非常低,所以必须有内网,内网和内网之间是相互连通的,产块节点和产块节点之间是联通的,通过IP地址,白名单进行联通,外部访问不到。极致中心化换取性能。我们再来看Solana,往前走了一步,号称几百个节点,有什么问题呢,1个epoch里面节点的产块顺序是固定的,如果闲着没事情,真的可以DDOS,你知道哪个时间,哪些节点在产块。你发DDOS流量好了,发了个几百G,打死了,就出不了块了。一旦产块候选阶段没有随机性存在,用一个固定的顺序是为了速度,为了性能,这就没有随机性,网络的活性,被DDOS的可能性就高了,去中心化程度就低了。以太坊网络是充分冗余了,如果一个节点被打死了,还有其他节点能继续工作。以太坊2.0 有几万个验证节点,而且产块的顺序也比较随机的,未来他们用的VDF函数,延迟函数来决定,你没法提前预知,一个节点被临时分配到哪每个分片上,每个出块委员会上面,带来的高度随机化,安全性就提升了。这个是很不一样的。
2)Chloe:Solana的机制问题和 DDOS攻击,以及网络上很多的投票交易,怎么解释?
Changbin:Solana 没有一个市场竞争的机制,不像在以太坊上,你需要提高gas费,才能将交易往前排。Solana直接将交易放在交易池。假设特别火的NFTmint 几百万人冲进来,交易相关,只能在一个Core上,交易堆在一个lead节点上,把lead节点打挂,这个节点很难起来。准确来说不是攻击,而是没有引入合适的机制。其实以太坊gas 市场调节机制,很好地应对网络可用性的问题。1)交易特别多的时候,以太坊缓存一个用户的发出来交易,数量是有限的,不会无限缓存交易2)如果你想让交易快的,打包交易会根据交易gasprice,会倒排,天然有一个市场存在,可以抵抗这个DDOS攻击,3)在gas消耗机制,对于速度比较慢的指令,也是做了比较好的保护,提到了对于存储的访问,非常高的gas。Solana攻击的问题,和内网部署没有关系。是接收了大量这些交易,处理不过来导致的。
TPS中包含了投票交易。因为BFT 类共识,必然会有共识投票过程。大部分用BFT这种共识的链,都不会将投票放在交易池,一般是有一类叫共识消息,共识消息是独立的。Solana是特殊的做法。这个跟他优化性能,一整套解决方案是一起的,共识变得更快,将投票交易也作为交易,并且计算在里面,这是有他的设计原理的。
DDOS攻击也有很多类型,区块链出现以前,是通过一些TCP一些特殊的指令,比如发起一个连接sync指令,但是什么事情也不干,占用服务器资源,让你服务器没法用,在区块链之后,会发送很多交易,把区块给站住,也叫DDOS的方法。攻击以太坊的成本比攻击Solana高,发很多交易把以太坊堵住的话,消耗的钱太多,Solana每天产生的交易费太少,攻击比较容易。
3)Jazzlost: 聊共识的话题,L1有些公链 流水线,并发处理的创新,包括Avalanche,Solana。我认为共识层面的创新对于整个L1的改进会比单纯从流水线的改进有更好的效果。
Changbin:其实这两年本质上没有出新的东西,进入了精耕细作的时代。