
本周我们将继续介绍我们的Portfolio公司,挖掘Stable Diffusion的所有信息。在正式解析前,我们先为大家做一个初步介绍。
Stable Diffusion 是Stability AI 公司开发的一款文本到图像的产品模型,它将使数十亿人能够在几秒钟内创作出令人惊叹的艺术作品。它是速度和质量方面的突破,意味着它可以在消费类 GPU 上运行。模型权重由托管合作方Hugging Face处理。
这是由 Runway 的 Patrick Esser 和慕尼黑大学机器视觉与学习研究小组的 Robin Rombach(以前是海德堡大学的CompVis实验室)领导的,基于他们之前在CVPR'22上的潜在Diffusion模型工作,并结合了社区的支持在 Eleuther AI、LAION 和Stability 生成 AI 团队。
该模型本身建立在 CompVis 和 Runway 团队在其广泛使用的潜在扩散模型中的工作基础上,结合我们的首席生成 AI 开发人员 Katherine Crowson、Open AI 的 Dall-E 2、Google Brain 的 Imagen和其他AI专家 对条件扩散模型的见解。
我们很高兴AI媒体生成成为了一个开源社区驱动的领域,我们也希望能够继续吸引越来越多的创造性人才加入我们。

本周我们挖掘Stable Diffusion的所有信息:
-
什么是Stable Diffusion?
-
它是如何生成那些很酷的动画的?
-
它如何衡量文本数据和图像数据之间的相似性?
-
让我们用文字提示和Stable Diffusion生成音乐。

什么是Stable Diffusion?
它类似于DALL-E 2,因为它是一个Diffusion模型,可以用来从文本提示中生成图像。与DALL-E 2不同的是,它是开源的,有PyTorch实现[1]和HuggingFace[2]上的预训练版本。它是用LAION-5B数据集[3]训练的。Stable Diffusion由以下子模型组成:
我们有一个自动编码器[4],它是由感知损失[5]和基于补丁的对抗性目标[6]的组合训练而成。有了它,我们可以将一个图像编码为一个潜在的表示,并从它那里解码。
随机噪声被逐步应用到嵌入中随机噪声被逐步应用到嵌入中[7]。文本提示的潜在表征是从CLIP对齐到图像表征中学习的[8]。
然后,我们然后使用U-Net,一个带有ResNet块的卷积网络来学习对Diffusion嵌入进行去噪[9]。文本信息通过交叉注意层注入网络[10]。得到的去噪图像然后由自动编码器解码器进行解码。
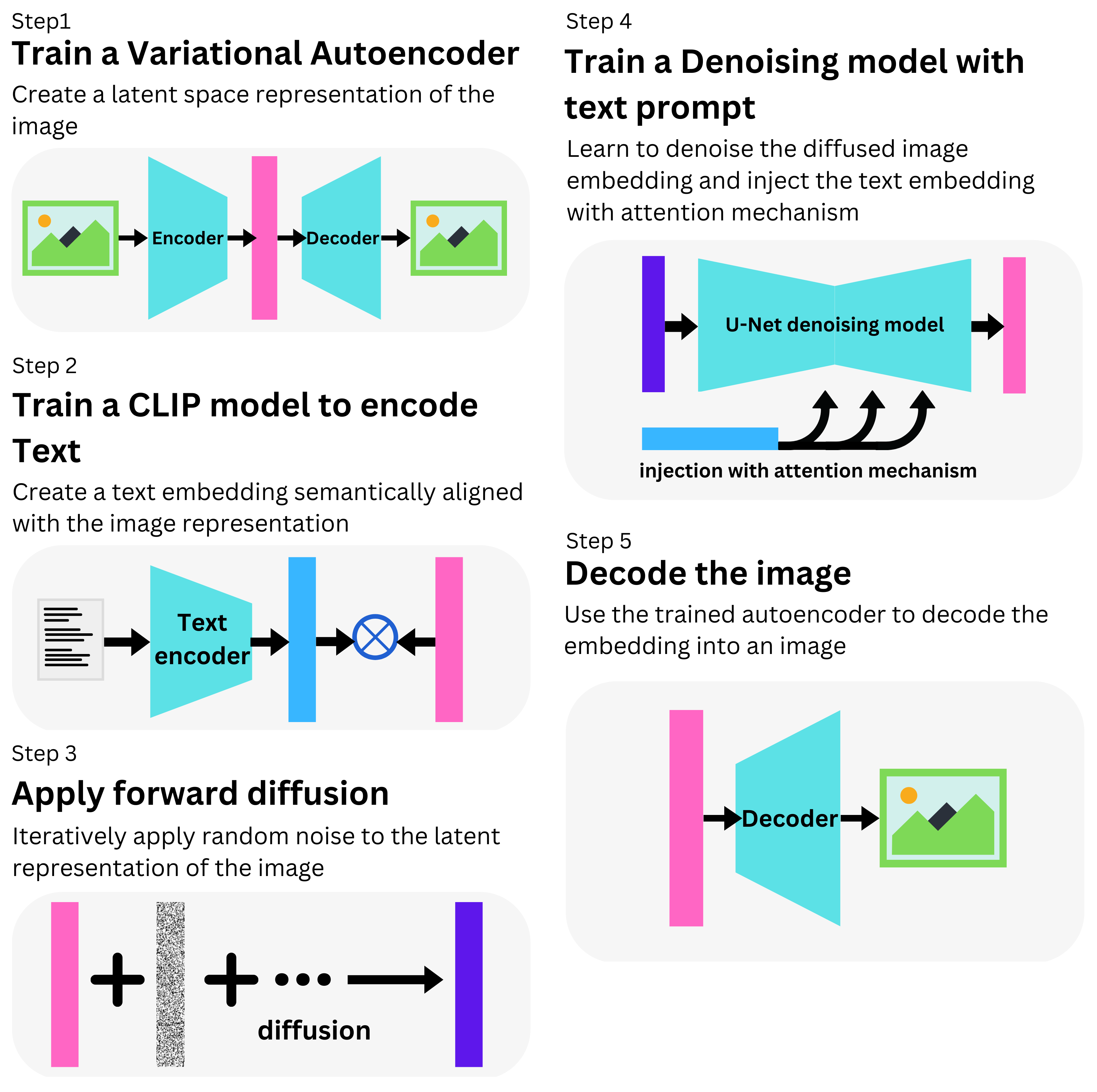
你可以在这里找到这篇文章: Stable Diffusion的文章[11]。有趣的模型!
它是如何生成那些很酷的动画的呢?
请看我在Replicate中做的:我的Stable Diffusion动画。那些动画主要是由于在潜伏空间(嵌入表征)中,很容易在2张图片或2个文本提示之间进行插值。DALL-E 2的文章对此有很好的解释: 。那些动画主要是由于在潜空间中的2张图片或2个文本提示之间的插值很容易(嵌入表征)。DALL-E 2的文章很好地解释了这一点[12]。
你需要一个开始和结束提示。我选择了 "一只熊的图片 "和 "一个苹果的图片"。
然后你用CLIP模型的文本编码器[13]在潜空间中对这些文本进行编码 ,你用这2个文本提示之间的插值来指导随机图像的去噪过程的几个步骤。这只是为了将去噪过程固定在两个提示之间,使动画的跳跃性更小。
然后,你在2个提示之间创建尽可能多的中间插值,因为你需要在你的动画中的帧,并继续去噪过程,直到你得到干净的图像。如果你需要更平滑的动画,你只需在潜空间中生成的图像之间进行插值。

我对Andreas Jansson用Stable Diffusion技术实现的动画玩得很开心[14]。他在使用Hugging Face[2]的预训练模型。
如何测量文本和图像数据之间的相似性?
你怎么知道一张图片与它的文字说明是否 "相似"?从概念上讲,你可以 "简单地 "测量图像和文本之间的余弦相似度。这就是CLIP(对比性语言-图像预训练[13])背后的想法,它是Dall-E 2和Stable Diffusion的基础OpenAI算法。图像和文本的中间潜在向量表示被学习,这样点积的高值就表明了高相似度。以下它是如何建立的)
首先,他们从互联网上公开的数据集中创建了一个由4亿对(图像、文字)组成的数据集。
然后他们使用了一个63M参数的转化器模型(A small GPT-2 like model 然后他们使用了一个63M参数的转化器模型(A small GPT-2 like model [15])来提取文本特征T和一个视觉转化器[16]来提取图像特征I。
得到的向量被进一步转化,使文本和图像向量具有相同的大小。有了N个(图像,文字)对,我们可以生成N^2-N个图像与文字标题不对应的对。然后,他们在图像与文字说明不对应的对之间进行归一化点积(余弦相似度)。如果文本对应于图像,模型就会收到一个标签1,否则就是0,这样,模型就学会了对应的图像和文本应该产生一个接近于1的点积。

这个模型在零点学习中有很多的应用! 在典型的图像分类中,我们给模型提供一个图像,而模型从监督训练期间使用的一组预定义的文本标签中提供一个猜测。但是有了CLIP,我们可以提供一组我们希望模型将图像分类的文本标签,而不需要重新训练模型,因为模型将试图衡量这些标签和图像之间的相似性。我们实际上可以通过切换文本标签来建立无限量的图像分类器! CLIP文章[8]展示了它的稳健性,可以概括到不同的学习任务,而不需要重新训练模型。在我看来,ML模型的这种适应性显示了我们离真正的人工智能有多远! CLIP是一个开源项目(展示了它的鲁棒性,以概括不同的学习任务而不需要重新训练模型。在我看来,ML模型的这种适应性表明我们离真正的人工智能有多远!"。),所以一定要试试。
让我们用文本提示生成音乐
想象一下,如果你能告诉机器学习模型 "用爵士萨克斯管演奏放克基调",它就会合成人工音乐!这就是我们的机器学习。实际上,你不需要想象,你可以直接使用它! 介绍一下RIFFUSION,一个根据Spectrogram图像数据训练的Stable Diffusion模型。这个想法很简单。
只要挑选一个预先训练好的Stable Diffusion模型[2]就好了。
将大量的音乐及其文字描述转换成Spectrogram图像数据。
微调到Stable Diffusion模型。
你现在有了一个模型,可以根据其他谱图或文字提示预测新的谱图。只要将这些频谱图转换回音乐。

如果你想了解更多关于如何自己做的细节,你可以按照这里的流程:https://www.riffusion.com/about。
引用
-
Stable Diffusion的Pytorch实现:https://github.com/CompVis/stable-diffusion
-
HuggingFace上的预训练版本:https://huggingface.co/spaces/huggingface-projects/diffuse-the-rest
-
LAION-5B数据集: https://laion.ai/blog/laion-5b/
-
Taming Transformers for High-Resolution Image Synthesis by Patrick Esser et al: by Patrick Esser et al: https://arxiv.org/pdf/2012.09841.pdf
-
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric by Richard Zhang et al: by Richard Zhang et al: https://arxiv.org/pdf/1801.03924.pdf
-
Phillip Isola等人:Phillip Isola等人:https://arxiv.org/pdf/1611.07004.pdf《用条件对抗网络进行图像到图像翻译》
-
Jascha Sohl-Dickstein等人的《使用非平衡热力学的深度无监督学习》:Jascha Sohl-Dickstein等人:https://arxiv.org/pdf/1503.03585.pdf
-
Learning Transferable Visual Models From Natural Language Supervision by Alec Radford et al: by Alec Radford et al: https://arxiv.org/pdf/2103.00020.pdf
-
U-Net。Olaf Ronneberger等人的《卷积网络用于生物医学图像分割》:Olaf Ronneberger等人:https://arxiv.org/pdf/1505.04597.pdf
-
感知器IO。Andrew Jaegle等人的《结构化输入和输出的通用架构》:Andrew Jaegle等人:https://arxiv.org/pdf/2107.14795.pdf
-
使用潜伏Diffusion模型的高分辨率图像合成 作者:Robin Rombach: https://arxiv.org/pdf/2112.10752.pdf
-
Aditya Ramesh等人的《用CLIP潜望镜进行分层文本条件的图像生成》:Aditya Ramesh等人:https://arxiv.org/pdf/2204.06125.pdf
-
OpenAI的CLIP模型: https://openai.com/blog/clip/
-
Andreas Jansson的用Stable Diffusion实现动画的方法。Andreas Jansson用Stable Diffusion实现的动画:https://replicate.com/andreasjansson/stable-diffusion-animation
-
OpenAI的GPT-2: https://openai.com/blog/tags/gpt-2/
-
一张图片胜过16x16个字。Alexey Dosovitskiy的《用于规模化图像识别的变压器》: https://arxiv.org/pdf/2010.11929.pdf