
Today’s cryptoverse is multi-chain and rollup-rich. But this wasn't always the case. Not long ago, Ethereum was without scaling solutions and faced headwinds as new dapps constrained blockspace to the point where a simple transaction required $200 in gas fees. This priced out retail investors, baptized skeptics, and armed Web3 critics, who joyfully celebrated the death of crypto.
As all eyes were on Ethereum, the community dug in and re-centered its focus to address the rising gas fees. This pivot led to Ethereum adopting a rollup-centric roadmap, setting the stage for innovate products like Optimism, Arbitrum, and Zksync.
This pivot is today’s story, and in this article I explore how Ethereum has, and will continue, to transition from a monolithic chain to Web3’s preferred settlement layer.
More specifically, I will cover:
-
What makes a blockchain "monolithic"
-
Why monolithic blockchains struggle to scale
-
How rollups solve some of these challenges
-
Why rollups represent the first step to a more modular blockchain design space
-
Tradeoffs and risks to disaggregating blockchain components
A Primer on Monolithic Blockchains
Monolithic blockchains do it all. They execute transactions. They facilitate consensus. They make transaction data available to stakeholders. And they can also settle (i.e., validate and arbitrate) transactions for other blockchains.
Let's define these four components in the context of Ethereum:
Execution
When a miner wants to create a block, it pulls transactions out of a pool, validates each transaction, orders them into a block, and computes the block's state root. The state root is a single output, resembling a snapshot that reflects all the account balances after applying the block's transactions. Here, a miner is executing each transaction to transition the blockchain’s state form A to B (e.g., Alice sends Bob 2 Eth. Old state: Alice 5 ETH, Bob 10 ETH; New State: Alice 3 ETH, Bob 12 ETH).
Consensus
Reaching consensus means nodes agree on the order in which transactions are processed. When a new block (a) is proposed, nodes can reach consensus by explicitly or implicitly attesting to the block. To explicitly attest, nodes submit votes, just like you would in a presidential election. To implicitly attest, nodes choose to build on top of the proposed block, contributing to the longest chain (i.e., Nakamoto Consensus). Ethereum currently follows the Nakamoto Consensus design but plans to transition to a an explicit voting implementation with its shift to proof of stake.
Regardless of the approach, monolithic blockchains must be able to facilitate consensus to ensure everyone agrees on the state of the chain.
Data Availability
When a miner propagates a block, they must include all the transactions required for validators to recreate the miner's proposed state root. If this data is withheld, other nodes have no way of bridging pre-state to post-state. Moreover, applications, developers, and other stakeholders (that aren't running a full node) are unable to track on-chain activity.
Making this data available is critical to preserve transparency and security, especially in a future where light clients (who can only see block headers) significantly outnumber full nodes.
Settlement
A settlement refers to a payment that is final and delivered. With cryptocurrencies, a transaction is settled after it is stored and confirmed on a blockchain. Layer 2 blockchains (e.g., rollups) can use select Layer 1 blockchains (e.g., Ethereum) as their dedicated place of settlement. Ethereum frequently settles transactions for other chains because it offers battle tested security and finality.
You can think of a settlement layer like the US Supreme Court (in its ideal state): incorruptible, always available, resilient, and called upon only to serve as final arbitrator.
Pulling it all Together
Monolithic blockchains transition state (execution), facilitate consensus on these state transitions (consensus), ensure stakeholders can see the inputs driving these transitions (data availability), and can settle state transitions for other protocols.
But it turns out, the monolithic design is cripplingly inefficient. It is bound by the scalability trilemma, which dictates that higher throughput necessarily means lower security and/or decentralization.
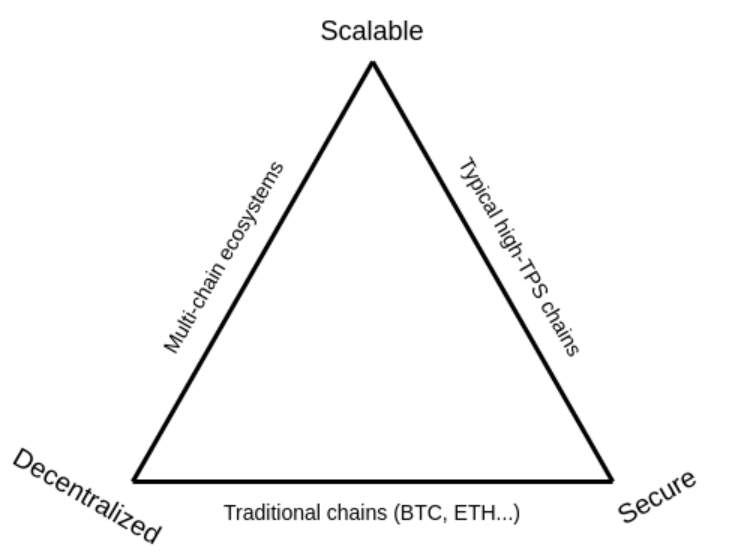
Why Monolithic Blockchains Struggle to Scale
In 2017, when Ethereum’s fees started to escape normal bands, many claimed that the community should increase the target block size. To many, this seemed like a reasonable suggestion. After all, if fees are increasing because block space is limited, why not just add more block space? But this introduces a serious side effect.
By increasing the target block size, nodes must validate and process a longer list of transactions in the same amount of time. As a result, larger blocks require more performant hardware. Hardware, that for some, could be prohibitively expensive.
Put another way, increasing the target block size reduces the amount of people who can afford to run a full node, centralizing the protocol. A more centralized protocol means a less secure network. And at the end of the day, a protocol's value rests on its security and incorruptibility. Even one small exploit is enough to undermine confidence in the protocol and lead to a mass exodus of users.
So, how do you scale a monolithic blockchain without significantly increasing its target block size?
Rollups
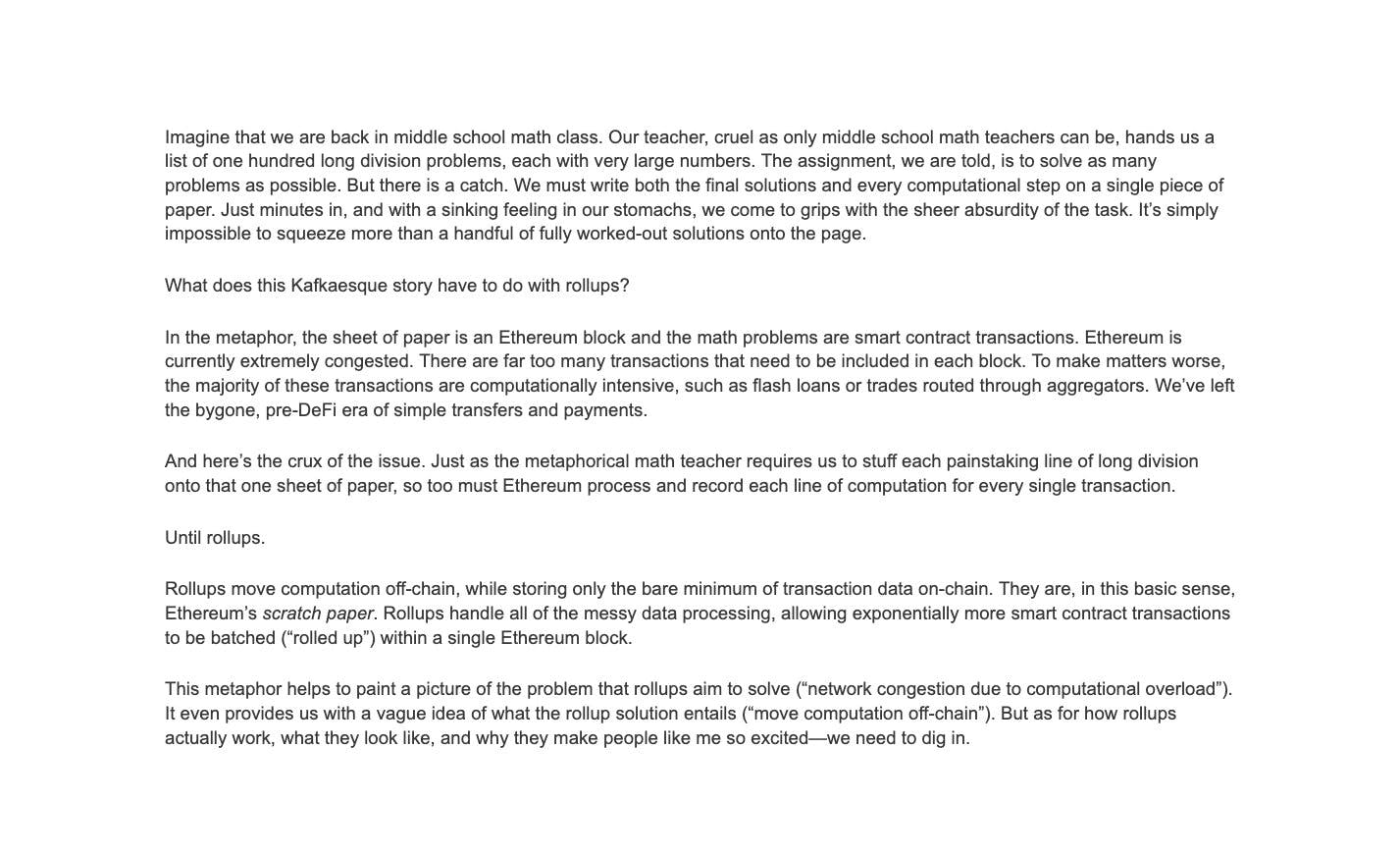
Ethereum requires every node to re-execute every transaction, and this is primarily why it struggles to scale. But what if there was a way to outsource this process to reduce the execution burden on validators?
This is effectively how a rollup works. A rollup is an off-chain execution layer (essentially a separate EVM compatible blockchain), where a handful of nodes process and send transaction batches down to Ethereum in a highly compressed format. Instead of piling many individual transactions into a block, rollups submit one batch, which holds many tightly compressed micro-transactions (i.e., messages holding just the data needed to bridge the pre- to post state root)
@benjaminsimon97 wrote a great analogy to help explain how rollups work.
And Vitalik Buterin illustrates the rollup workflow in this simple graphic.
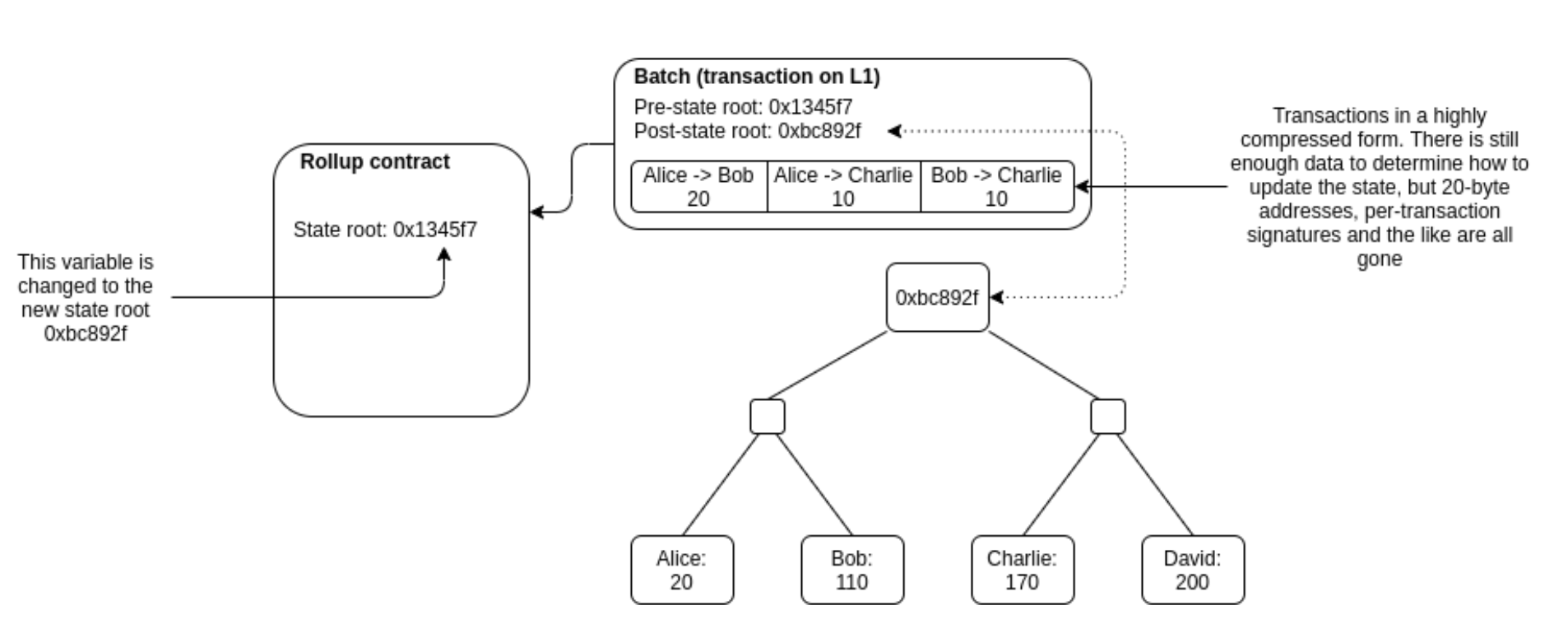
The compression off-chain eliminates the need for Ethereum’s ~11k validators (at Ethereum’s peak) to re-execute these transactions, freeing up precious blockspace and reducing fees for rollup users. And this reduction is meaningful; a simple ERC20 token transfer costs ~45000 gas, while an ERC20 token transfer in a rollup costs under 300 gas.
Moreover, by publishing data back to Ethereum, anyone can locally process all the operations in the rollup, allowing them to detect fraud, initiate withdrawals, or personally start producing transaction batches as a sequencer.
Rollups are an elegant solution to the trilemma as they extend Ethereuem’s security profile to new, cheaper, and EVM compatible execution environments. This has led Ethereum’s founders to claim that, rollups are in the short and medium term, and possibly the long term, the only trustless scaling solution for Ethereum.
Rollups leverage Ethereum's best attributes (security) while managing its weakness (execution). In this way, rollups have illustrated how we can modularize blockchain components to optimize outcomes. Not everything needs to be managed by the same set of nodes. And, in fact, we can continue to unbundle the stack to drive further improvements.
The Great Unbundling
While rollups are a major unlock, they are still limited by their L1's block parameters. Rollups are sending batches back down to the L1 in the form of calldata. When rollups send calldata to an L1, it usually resembles an empty transaction (i.e., no value is exchanged) that encloses data about the transactions processed on the L2 network (i.e., "the micro-transactions" referenced earlier).
Because these batches are processed on an L1, they are subject to gas wars and mainnet congestion. And these gas costs can be significant, in some cases representing over 90% of a rollup’s costs. Just recently, a major NFT auction (Yuga Labs' Otherside Land Sale) catalyzed so much traffic that even a simple DEX swap on Optimism ran ~$130.
What drives a rollup’s gas costs?
Adeets_22, broke down the component parts of a Zk L2 → L1 batch in the below analysis. It illustrates how calldata costs shackle rollup users to Ethereum’s costly gas fees.

The key takeaway from this analysis is that the majority of gas spent in a state update event will be spent on making data available on the L1 and not on the verification of the ZK proof itself.
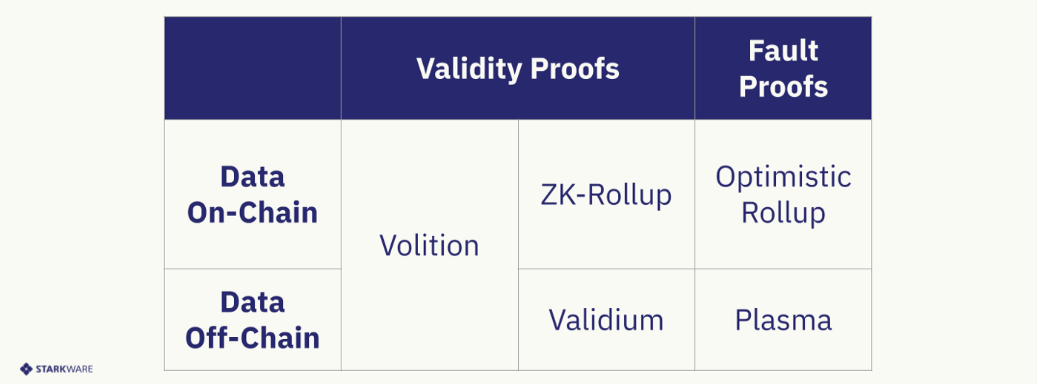
Reducing costs with Validiums and Volitions
Now imagine if a ZK rollup didn't need to make transaction data available on the L1. Imagine if, instead, it only needed to publish the bare minimum (i.e., a proof and state transition) to the L1, while sending everything else (i.e., the details of each transaction) to a separate, cheaper environment. While rollups decouple execution from the L1, this new model goes one step further, and decouples data availability from the L1. The payment for on-chain data is not required in this model. A state update event only costs the gas needed for verifying the proof.
This model has been coined a "Validium."
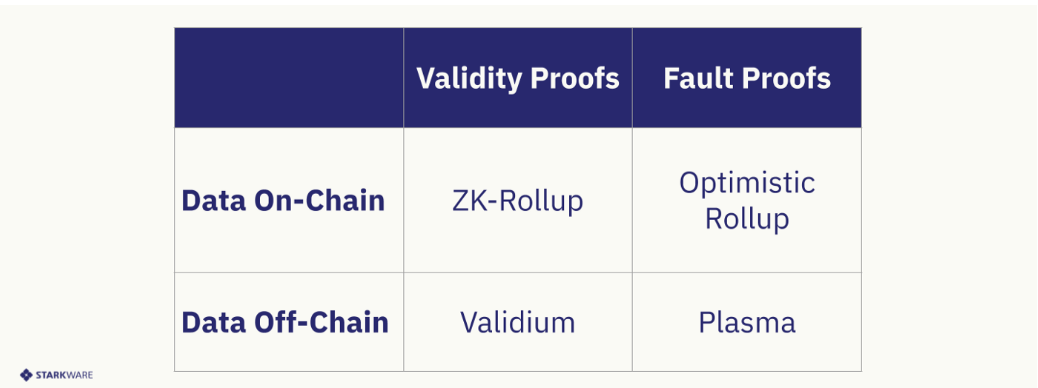
"Volitions" take this concept even further by letting users easily switch between a rollup and a validium. Some applications, such as decentralized derivatives exchanges, might prefer a validium (because keeping data off-chain preserves the privacy of trades), while others, still wanting to interoperate with applications, might prefer a rollup. Volitions allow users and applications to oscillate between solutions depending on their data availability preferences.
Challenges with Modularization
Unbundling blockchain components provides better scaling and cheaper fees without significantly compromising trust assumptions. But there are still assumptions! Each time a component is outsourced, unsurprisingly, new risks appear and compound.
Arbitrum, for example, does not currently have a fully decentralized sequencer. While proposing batches is open to anyone, the system employs a privileged sequencer that has priority for submitting transaction batches and ordering transactions.
Moreover, StarkEx, a relatively new validium, doesn't have a fully decentralized DA solution (they use more of a PoA model with an eight-person committee).
To hammer the point home -- disaggregating monolithic blockchains can unlock significant scalability, but it also introduces new environments with socioeconomic and technological trust assumptions that require special consideration. If you’re interested in exploring these considerations, L2beat does a great job of outlining tradeoffs/risks across the rollup landscape.
Appendix - EIP 4488: Decreasing Rollup Overhead
Validiums and Volitions offer novel ways to manage the data availability problem without changing the core Ethereum protocol. But the Ethereum community is also tackling this problem from a different angle. EIP 4488 was proposed to decrease transaction calldata gas cost and add a limit to how much total transaction calldata can be in a block.
If implemented, this would reduce the cost of L2 → L1 batches, thus reducing the cost of rollup-native transactions. It would also represent a small, but important, step for Ethereum on its path to become Web3’s settlement and data availability layer.
For more information on this proposal checkout proto.eth’s thread below!
If you enjoyed this article, please follow me on Twitter at @jtseig.
Sources: