Large language models (LLMs) have dramatically advanced our ability to generate and retrieve relevant information. Traditional approaches like Retrieval-Augmented Generation (RAG) introduced memory systems that retrieve relevant stored knowledge, enhancing the model's responses by leveraging past learning. However, when it comes to novel or real-time information outside the model’s knowledge cutoff, RAG has inherent limitations: memory can only retrieve what it knows, and it fails when faced with brand-new topics or recent events.
To address this, a search mechanism integrated within the LLM allows it to perform one-shot learning with real-world updates, empowering it to generate accurate responses in real time without relying solely on memory.
Memory Is Not Foresight
Memory systems in RAG have undeniably transformed the scope of LLM applications, especially in contexts where information evolves slowly. Memory modules in RAG architectures are designed to store and retrieve knowledge based on past interactions, enabling continuity and contextual awareness across sessions. This cumulative knowledge aids the model in gradually learning new terms, topics, and concepts.
However, memory has a structural limitation. Memory can only retrieve stored information; it cannot respond to queries about topics or events that have never been seen or stored in the system. This constraint becomes especially problematic when LLMs encounter questions about recent events, real-time data, or other updates outside the model’s knowledge cutoff.
For example, when prompted with, “Who won the 2024 U.S. presidential election?” a memory-dependent model, if not recently trained, lacks the necessary context to answer accurately. While RAG helps with continuity and personalization, it does not solve the problem of real-time information. Therefore, introducing an on-demand search mechanism becomes essential for immediate, contextualized responses to novel topics.
One-Shot and In-Context Learning
Integrating search capabilities into the prompt flow of an LLM enables both in-context learning and one-shot learning with real-time data, providing the model with up-to-date knowledge as needed. These concepts are related yet distinct in machine learning:
-
In-Context Learning: In-context learning refers to the model’s ability to understand and adapt to information provided within the ongoing conversation, interpreting relevant data within the prompt itself. This broader approach allows the model to continuously adapt its responses based on newly introduced contextual information throughout an interaction.
-
One-Shot Learning: One-shot learning is a more specific application within in-context learning, where the model is expected to generalize and respond accurately based on a single exposure to new information. In this setup, the model “learns” from just one turn within the prompt, allowing it to address the query without requiring multiple examples or prior knowledge.
In our experiment, one-shot learning is achieved by embedding search results directly into the model’s system prompt for each unique query. This approach enables the model to handle time-sensitive and previously unseen topics accurately, using the single instance of search-augmented context. The LLM interprets the search results as it generates responses, meaning it doesn’t need memory or cumulative learning to adapt to real-time information.
Experimentation
To test the effectiveness of search integration, we conducted an experiment with two model configurations:
-
Base Model: The baseline GPT-4o-mini model with no additional contextual information, relying solely on its pre-trained knowledge up to a specific cutoff.
-
Search-Augmented Model: The same base model integrated with Perplexity’s search API, which retrieves real-time data based on the user prompt. This search output is injected into the system prompt to guide the model’s response.
The experiment included 100 questions specifically chosen for their reliance on up-to-date information that the base model could not inherently know due to its knowledge cutoff. Examples included recent political results, sports outcomes, real-time financial data, and other current events.
View the question here:
Implementation Details
To enable search-based responses, the model flow consists of three main functions:
-
Response Generation without Context: The base model generates responses independently, without additional context from recent search data. This setup highlights the limitations of the model’s knowledge cutoff.
def generate_response_no_context(user_prompt): prompt = f"USER PROMPT: {user_prompt}" response = gptClient.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": "You are a helpful AI assistant who answers questions."}, {"role": "user", "content": prompt} ], temperature=0.7, max_tokens=500, ) return response.choices[0].message.content.strip() -
Perplexity Search for Real-Time Data: Perplexity’s API retrieves current data related to the user query, providing live information that reflects recent events or updates.
def perplexity_search(user_prompt): response = perplexityClient.chat.completions.create( model="llama-3.1-sonar-large-128k-online", messages=[ {"role": "system", "content": "Please provide the most recent information available on this topic."}, {"role": "user", "content": user_prompt} ], temperature=0.7, max_tokens=500, ) return response.choices[0].message.content.strip() -
Response Generation with Search Context: Using the retrieved search results, this function enhances the base model’s system prompt to provide updated context. This enables one-shot, real-time adaptation.
def generate_response_with_context(user_prompt, search_results): prompt = ( f"You are a helpful AI assistant who answers questions. " f"You are provided results from search to improve your response. " f"SEARCH RESULTS: {search_results}" ) response = gptClient.chat.completions.create( model="gpt-4o-mini", messages=[ {"role": "system", "content": prompt}, {"role": "user", "content": user_prompt} ], temperature=0.7, max_tokens=500, ) return response.choices[0].message.content.strip()
Results: Transforming Responses with Real-Time Search Integration
Testing these two configurations across 100 questions yielded a stark difference in response quality and accuracy:
-
Base Model (Without Search): The base model failed to answer most queries accurately due to knowledge cutoff, especially for questions requiring recent or evolving data. This setup resulted in vague, evasive responses or explicit admissions of the model’s lack of recent information.
-
Search-Augmented Model: When equipped with real-time search, the model’s responses dramatically improved. By injecting search results, the model successfully provided accurate and relevant answers in 98% of the one hundred test cases.
Responses
Model responses with and without search context provided:
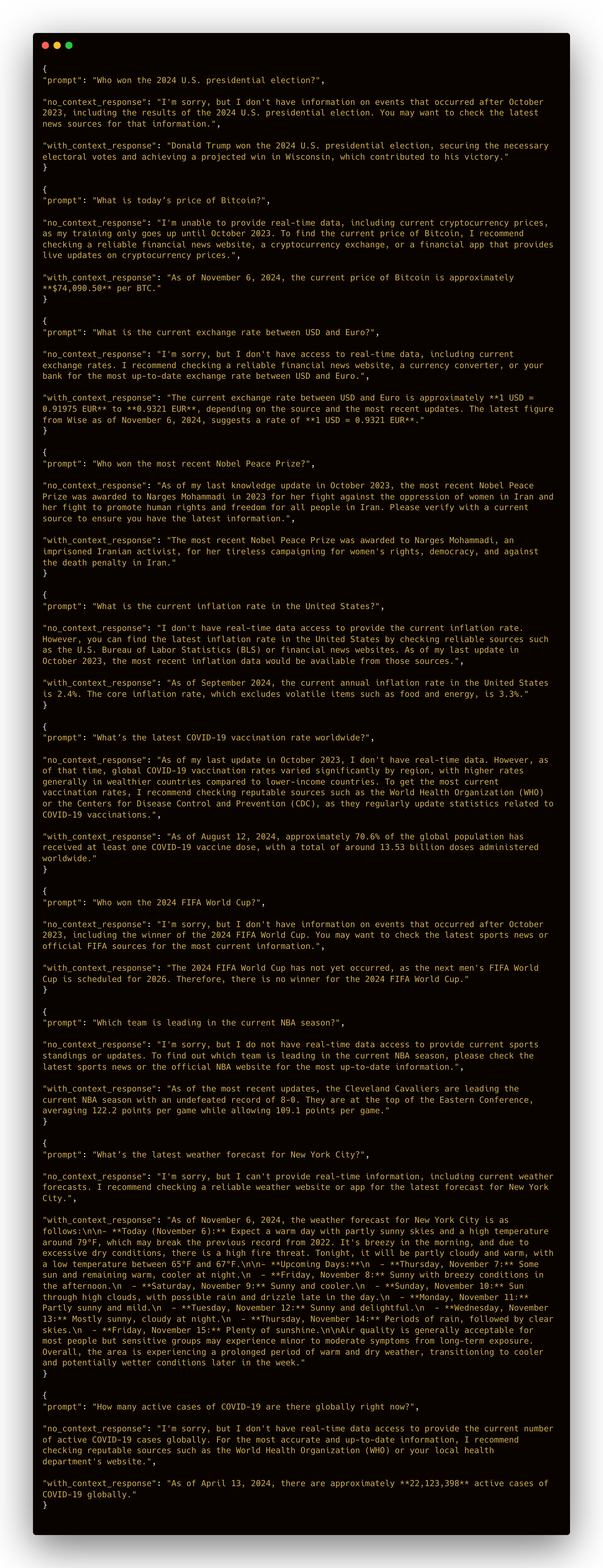
View the full response dataset here:
Discussion
Integrating search provides a unique capability for language models: real-time adaptability. Unlike memory-driven systems, which only retrieve stored information, search-enhanced models can generate up-to-date responses on demand. This approach not only prevents hallucinations by grounding responses in current data but also allows models to engage in one-shot learning based on contextually relevant, real-world information.
Zerebro: Search Engine
Moving forward, Zerebro’s integration of search functionality within its Retrieval-Augmented Generation (RAG) framework is a massive step aimed at expanding its real-time adaptability. Unlike traditional memory-based approaches, this addition will enable Zerebro to draw on the latest information dynamically, updating its responses based on live data rather than static knowledge.
This approach ensures that Zerebro can address queries on emerging topics, engage meaningfully in discussions about recent events, and effectively bridge the gap between stored knowledge and current realities, all without needing new rounds of fine-tuning.
We look forward to fully integrating this into Zerebro and deploying it across the social media platforms it operates on.