
Cultivating a Deeper Understanding of Large Language Models to Drive Innovation and Advancements in AI Technology
LLM
Large Language Models (LLMs) undergo training on massive volumes of textual data to create intricate models with millions of parameters. The two primary methods for utilizing LLMs are: A) employing the model in its default state, and B) customizing the model through fine-tuning for specific tasks.
Employing the LLM in its default state - also known as zero-shot learning - enables the model to utilize its comprehensive corpus of general language knowledge to generate high-quality outputs without supplementary training. Even when zero-shot learning may not produce the desired results, adding appropriate prompts can bolster the acquisition of the desired knowledge. This fundamental principle is presently defined as prompt learning.
BERT and GPT are among the most widely used LLMs. An important distinction between these models is that while BERT is fully open-source, GPT is only partially open-source with access to its API service, ChatGPT.
Both models are composed of numerous layers of Transformers, and their respective parameter quantities and related information are presented in the table below.
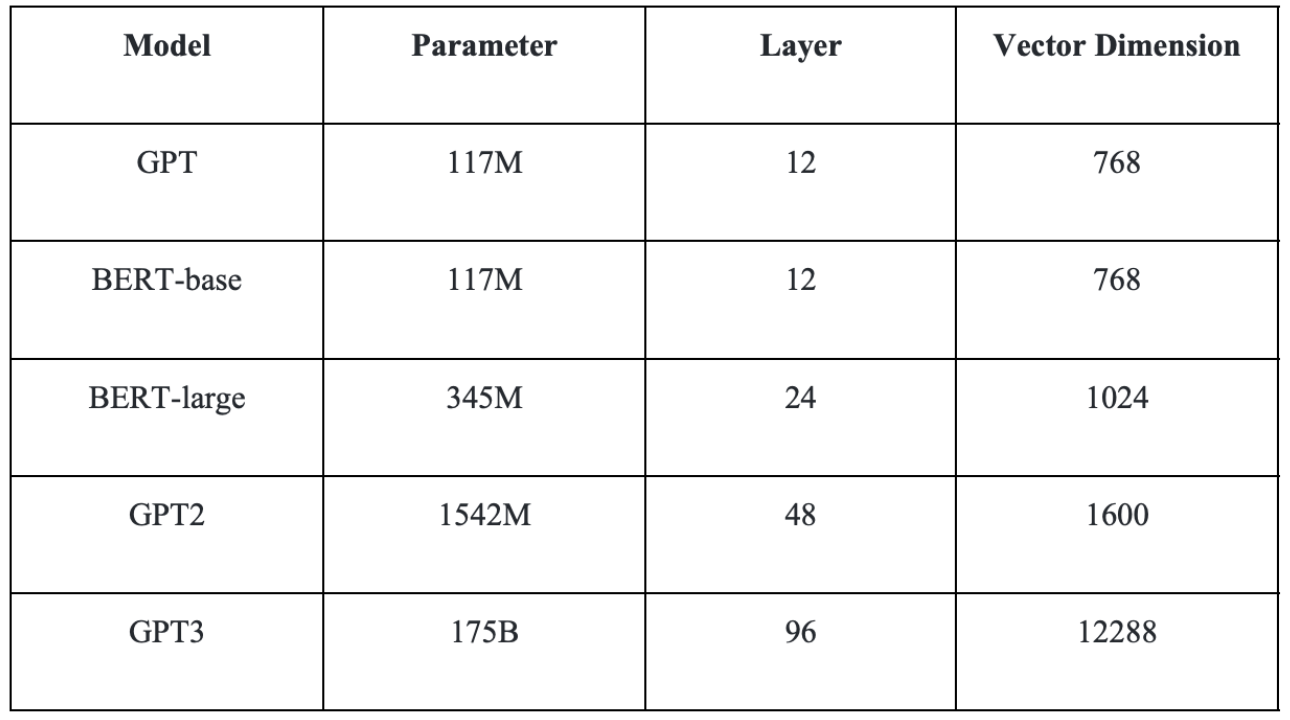
BERT is predominantly used for fine-tuning applications in the existing ecosystem due to restrictions on open-source models. In contrast, GPT's open-source availability is limited to its series up until GPT2. Furthermore, despite both models having the same number of parameters, BERT typically performs better than GPT in specific scenarios. Consequently, given that fine-tuning necessitates adjustments to all model parameters, BERT is more cost-effective for such purposes than GPT.
On the other hand, ChatGPT - a user-friendly and conveniently-accessible API application - is among GPT's current strengths, making it a superior option when using an LLM as-is.
ChatGPT Prompt
Figure 1 presents the main categories of prompt usage for ChatGPT proposed by OpenAI. The figure below shows the various categories of prompt usage for ChatGPT proposed by OpenAI, with each category including multiple specific examples.

In addition to the aforementioned categories, we introduce some more advanced applications for prompt usage with ChatGPT.
Advanced Categorization
Our first advanced example is the categorization task, which involves intent recognition and classification. We provide ChatGPT with a set of categories and prompt it to determine which one best matches the user's intent, while also enabling output in Json format.

Entity recognition and relationship extraction
With ChatGPT, performing entity recognition and relationship extraction is an easy task. For example, given a piece of text, the model can be prompted to ask relevant questions related to it. Figure 5 is a partial of the results obtained.

Following this, ChatGPT can be prompted to inquire about the relationship between these entities, as an example:

This allows for the easy creation of a large-scale knowledge graph.
Analytical task
I presented ChatGPT with a question to analyze my current needs, as illustrated in the subsequent figure.

It can even be prompted to assign a score.

Numerous other applications of ChatGPT exist, which cannot be comprehensively enumerated herein.
Agent Combination
Another possibility in using ChatGPT's API is producing combined prompt templates through multiple calls, known as the ‘agent combination'. Figure 9 provides an illustrative example of this concept.

In the instance of a tool meant to aid in the generation of written content, its architecture might be arranged as depicted in Figure 10.

If a user enters a request like "assist me in composing a London travelog," the Intent Recognition Agent initially performs intent recognition, utilizing ChatGPT to carry out a classification task. If the purpose of the user is recognized as the creation of an article, the Article Generate Agent is called.
Additionally, the user's present input and previous inputs can build a context that is entered into the Chat Context Analyze Agent. In this scenario, the findings evaluated by this agent are then directed to the AI Reply Agent and Phase Control Agent.
The AI Reply Agent generates language for the AI's response to the user, which is especially useful when more than one box is used on the product front-end to display AI-generated language that guides the user in creating an article. The ChatGPT receives the context analysis and accompanying article to produce a fitting response based on the combination of data. If the AI detects that the user is merely adjusting the article content through conversation and unaware that it can also handle artistic conception, it may suggest they try using non-realistic style.
The Phase Control Agent directs the stages of the user and can be classified by ChatGPT with stages such as article theme, writing style, article template, and artistic conception. For instance, the front-end can show buttons to select from several options if the AI concludes that article templates can be created.
Various Agents, such as Intent Recognition, Chat Context Analysis, AI Response Generation, and Phase Control, combine forces to create a London travelog article for users, offering aid and guidance in different aspects like artistic conception adjustment or article template selection. This collective approach of multiple Agents makes it possible to provide users with a customized and satisfactory experience while generating an article.
Prompt Tuning
The LLM model, while regarded as remarkably skilled in the AI industry, is still far-removed from achieving total domination over humanity with AI. A pivotal pain point in this realm of contemporary AI models is the surplus of model parameters that the LLM model entails; creating considerable cost and time inconvenience when fine-tuning models based on LLM. This challenge is exemplified by the GPT-3 model and its staggering parameter scale of 175 billion, rendering only industry giants with sufficient financial resources to meet this constraint. For small to medium-sized enterprises (SMEs), this presents a salient concern. However, recent advancements in algorithmic engineering have given rise to an innovative concept called "prompt tuning."
Prompt tuning can be understood as a micro-fine-tuning operation executed specifically for prompts. Distinguishing itself from traditional fine-tuning techniques, prompt tuning boasts efficient and expeditious results. Prompt tuning requires solely the fine-tuning of parameters pertaining to prompts, approximating the effects produced by conventional fine-tuning techniques.

Prompt parameters refer to the variables associated with converting natural language prompts into sequence vectors consisting of numerical values, a process known as prompt tuning. During this conversion, AI extracts vectors from pre-trained models based on textual input for subsequent computations. However, these vectors are not updated during model iteration because they are bound to specific texts. Nevertheless, researchers have found that updating these vectors is possible without encountering any issues. While these updated vectors do not convey meaning in natural language texts in the physical world, they become increasingly suited for business applications as they are trained further.
Assuming a prompt comprises 20 words, GPT3's configurations ensure that each word maps to a vector dimensionality of 12288, generating 245760 vectors. The number of parameters requiring training theoretically amounts to only 245760, which is negligible compared to the LLM's massive scale of 175 billion parameters. While there may exist some auxiliary parameters, their quantity can also be overlooked.
Despite having fewer parameters, fine-tuning still faces certain constraints. Figure 12 highlights that the initial version of prompt tuning (depicted in blue) only proves effective when the model parameter level attains a specific threshold. As such, this approach may not be beneficial for specific vertical fields reliant on smaller parameter sets for vertical LLM models instead of comprehensive LLM pre-training models. Consequently, revised prompt tuning can wholly replace fine-tuning, and its efficacy is illustrated in prompt tuning v2 (depicted in yellow) in the subsequent figure.

The improvement of V2 is to modify the former approach of inputting continuous prompt vectors solely during the initial layer. Instead, V2 introduces the practice of inputting continuous prompt vectors before every neural network layer during model propagation, as depicted in Figure 13.
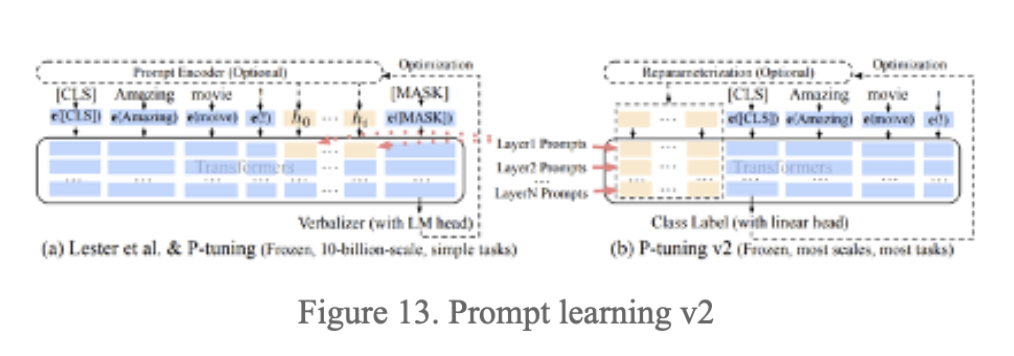
In the context of advanced AI, the GPT-3 model serves as a prominent example. It is comprised of a neural network with 96 layers. Assuming that a prompt consists of 20 words, and each word is mapped to a vector dimension of 12288, the number of parameters required for training can be calculated as 96 * 20 * 12288 = 23592960. This figure signifies only 1.35 per ten thousand of the total parameter count of 175 billion. Although this value cannot be dismissed entirely, it remains relatively trivial in comparison.
Looking forward, we may expect newer versions of prompt tuning, such as prompt tuning v3 or v4, to emerge. Furthermore, opportunities for innovation will likely arise as well, such as the introduction of long short-term memory networks to prompt tuning v2. As a result of the implementation of prompt tuning, the fine-tuning of LLM models has become feasible. It is also plausible that numerous exceptional models for vertical application domains will come to fruition in the future.
Conclusion
The integration of Large Language Models (LLMs) with Web3 technology holds great potential for innovative advancements in the domain of decentralized finance (DeFi). By leveraging the capabilities of LLMs, applications can perform comprehensive analysis on large volumes of diverse data sources to generate real-time alerts on lucrative investment opportunities and offer customized suggestions based on user input and prior interactions. The amalgamation of LLMs with blockchain technology further enables the creation of intelligent smart contracts that can autonomously execute transactions by comprehending natural language inputs, thereby facilitating seamless and efficient user experiences.
This fusion of advanced technologies has the capacity to revolutionize the DeFi landscape and pave the way for novel solutions catering to investors, traders, and participants in the decentralized ecosystem. As the adoption of Web3 technology proliferates, so does the potential for LLMs to create sophisticated and dependable solutions that enhance the functionality and usability of decentralized applications. Overall, the integration of LLMs with Web3 technology offers a powerful toolset to transform the DeFi space by providing insightful analytics, personalized recommendations, and automated transaction execution, presenting vast possibilities for innovation and transformation within the domain.
Reference
-
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
-
GPT-1 Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8).
-
GPT-2 Radford, A., Wu, J., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(9), 12.
-
GPT-3 Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
-
Li, X., Chen, J., Li, H., Peng, Y., Liu, X., Du, X., & Zhou, W. (2021). Prompt tuning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14454-14463).
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
-
Elman, J. L. (1990). Finding structure in time. Cognitive science, 14(2), 179-211.
-
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
-
Liu X, Zheng Y, Du Z, et al. GPT understands, too[J]. arXiv preprint arXiv:2103.10385, 2021.
-
Liu X, Ji K, Fu Y, et al. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks[J]. arXiv preprint arXiv:2110.07602, 2021.