
🔵Introducción
El Optimistic Rollup de Arbitrum es una solución de capa 2 diseñada para abordar los desafíos de escalabilidad de la red Ethereum. Arbitrum ofrece una forma más rápida y económica de realizar transacciones en Ethereum al aprovechar la técnica de los Optimistic Rollups.
En este sistema, la mayoría de las operaciones se realizan fuera de la cadena principal (es decir fuera de mainnet ó off-chain), lo que permite aumentar la eficiencia y reducir los costos.
En este artículo, explicaremos en detalle qué es Arbitrum, cómo funciona su rollup optimista y cómo se lleva a cabo el proceso de transacciones en el mismo.
Índice.
-
¿Qué es Arbitrum?.
-
¿Qué es un Rollup?.
-
¿Qué es un Optimistic Rollup?.
-
Ciclo de vida de una transacción en Arbitrum.
-
El Secuenciador.
-
Flujo de trabajo del Secuenciador.
-
Core Inbox.
-
Caso Feliz/Común.
-
Caso Infeliz/Inusual.
-
-
ArbOS.
-
Mensajes entre L1 Y L2.
-
Contratos L1 pueden enviar transacciones a L2.
-
Transacciones basadas en tickets de L1 a L2.
-
Llamadas basadas en tickets de L2 a L1.
-
-
Gas.
-
El límite de velocidad.
-
Tarifas.
-
Tarifas de gas de L2.
-
Tarifas de calldata de L1.
-
-
Nodos validadores.
-
Desafíos.
-
Protocolo de Disección: Versión Simplificada.
-
¿Por qué la Disección Identifica Correctamente a un actor malicioso?.
-
El Protocolo Real de Disección.
-
Prueba de un Paso (One Step Proofs).
-
Eficiencia.
-
-
Arbitrum Bridge.
-
Depósito y Retiro de Ether (ETH).
-
Depósito y Retiro de ERC-20 tokens.
-
Tipo de Diseño.
-
Implementación canónica L2 por contrato de token L1.
-
Implementación del puente canónico de tokens.
-
Puente estándar por defecto.
-
Ejemplo: Depósito/retirada de Arb-ERC20 estándar.
-
La Gateway personalizada genérica de Arbitrum.
-
Configuración del token con la Gateway personalizada genérica
-
-
Conclusión.
1.🤷♂️¿Qué es Arbitrum?.
Arbitrum es una solución de capa 2, creada por OffChain Labs para agregar escalabilidad a la red Ethereum. Esto significa que al utilizar Arbitrum, los usuarios pueden realizar transacciones en Ethereum de manera más rápida y económica
La plataforma se compone de dos redes diferentes: Arbitrum One y Arbitrum Nova. Arbitrum One es la red original enfocada en aplicaciones de finanzas descentralizadas (DeFi) y es la que utiliza la tecnología de los "Optimistic Rollups” (o “Rollups Optimistas”).
Por otro lado, Arbitrum Nova está dirigida al mundo de los juegos descentralizados (GameFi) y las aplicaciones sociales. Mientras que Arbitrum One implementa el protocolo Rollup, Arbitrum Nova implementa el protocolo AnyTrust. La diferencia clave entre los protocolos Rollup y AnyTrust es que este último introduce un supuesto de confianza adicional en forma de comité de disponibilidad de datos (DAC).
2.⛓¿Qué es un Rollup?.
Los Rollups son una solución de Capa 2 que agrupa o “enrolla” (de allí viene su nombre) los datos de varias transacciones y los transfiere fuera de la cadena principal (es decir offchain). En un rollup, la ejecución de las transacciones se realiza fuera de la cadena principal, mientras que los activos se mantienen en un contrato inteligente en la cadena. Una vez completada la transacción, los datos se envían de vuelta a la cadena principal.
Las principales ventajas que tiene este sistema son:
-
Eficiencia en transacciones: Los rollups permiten aumentar la eficiencia en el procesamiento de transacciones al agrupar múltiples transacciones en un solo bloque, lo que aumenta significativamente la capacidad de procesamiento de la blockchain. Esto resulta en una mayor velocidad de confirmación de las transacciones y una reducción de los costos de gas.
-
Escalabilidad: Al trasladar gran parte de la carga de trabajo fuera de la cadena principal (Capa 1), los rollups permiten que la cadena de bloques maneje un mayor número de transacciones sin comprometer su rendimiento. Esto es especialmente importante en cadenas de bloques con alta demanda y congestión.
-
Costos reducidos: Al realizar la mayor parte del procesamiento de transacciones fuera de la cadena principal, los rollups pueden reducir significativamente los costos asociados con las transacciones en la cadena de bloques. Esto hace que las transacciones sean más asequibles para los usuarios y fomenta la adopción masiva.
-
Interoperabilidad: Los rollups pueden ser utilizados en diferentes cadenas de bloques, lo que permite la interoperabilidad entre ellas. Esto significa que los activos pueden moverse y ser utilizados en diferentes cadenas de bloques sin problemas, lo que amplía las posibilidades y casos de uso.
-
Flexibilidad en las funcionalidades: Los rollups pueden implementar diferentes funcionalidades y características, como contratos inteligentes, sin necesidad de que estén soportadas directamente en la cadena de bloques principal. Esto permite una mayor flexibilidad y personalización en el desarrollo de aplicaciones descentralizadas (dApps).
3.✅¿Qué es un Optimistic Rollup?.
En un Optimistic Rollup, la mayoría de las operaciones y cálculos se realizan fuera de la cadena principal (Capa 1), al igual que en otros tipos de Rollups. Sin embargo, los Rollups Optimistas utilizan un enfoque basado en la presunción de validez de las transacciones. Es decir se asume un ambiente o conducta optimista por parte de todos los participantes.
En lugar de verificar cada transacción de forma exhaustiva en la cadena principal, un Rollup Optimista permite que las transacciones se ejecuten y se incluyan rápidamente en la cadena de bloques de Layer 2. Sin embargo, en lugar de proporcionar pruebas criptográficas de validez en cada transacción, se confía en que los participantes actuaran correctamente y no intentaran realizar actividades maliciosas.
La verificación de las transacciones se realiza de manera retroactiva y periódica, generalmente a través de un mecanismo llamado "periodo de desafío" que dura 7 días. Durante este período, cualquier participante de la cadena puede presentar una prueba de fraude en donde se compruebe que una transacción es inválida y así cuestionar su validez. Si esta prueba de fraude es aprobada, entonces se pueden aplicar sanciones o penalizaciones a los validadores involucrados que aprobaron la transacción errónea, como la pérdida de fondos o garantías depositadas.
De esta manera, se logra que los validadores de las transacciones se comporten de manera correcta, ya que en caso de ser descubiertos en actos maliciosos serán castigados retirándoles todos sus fondos stakeados.
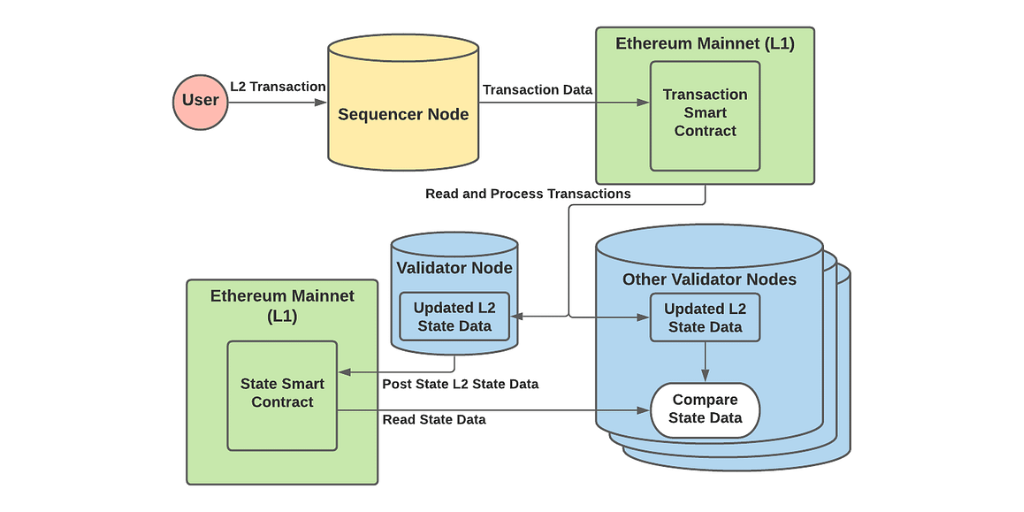
4.📝Ciclo de vida de una transacción en Arbitrum.
-
Las transacciones son recibidas por el Secuenciador, quien las ordena para formar un lote de transacciones.
-
Luego este lote se publica en Ethereum dentro de un contrato inteligente en L1.
-
Después, un nodo validador leerá los datos de este lote y las procesa localmente en su copia del estado L2.
-
Una vez procesadas, se genera localmente un nuevo estado L2 y el validador publicará esta nueva raíz de estado en un contrato inteligente en L1.
-
A continuación, todos los demás validadores procesarán las mismas transacciones en sus copias locales del estado L2 y compararán su raíz de estado L2 resultante con la original publicada en el contrato inteligente L1.
-
Los validadores tienen un período de tiempo determinado (7 días) para reportar cualquier fraude en la raíz de estado.
-
Si uno de los validadores obtiene una raíz de estado diferente a la publicada en L1, iniciará un desafío. El desafío requerirá que el retador y el validador que publicó la raíz de estado original se turnen para demostrar cuál debería ser la raíz de estado correcta.
-
El usuario que pierda el reto, perderá su depósito inicial (Stake). Mientras que, si la raíz de estado L2 original publicada que no era válida, será destruida por futuros validadores y no se incluirá en la cadena L2.
-
Por otro lado, si no se reporta fraude durante el período de tiempo determinado (7 días), el estado del rollup es considerado finalizado en su totalidad, habilitando al puente completar transacciones de retiro incluidas dentro del ciclo.
En el siguiente diagrama se puede visualizar estos pasos:
5.👮♂️El Secuenciador.
El Sequencer (o Secuenciador) es un nodo completo de Arbitrum especialmente designado que, en condiciones normales, es responsable de enviar las transacciones de los usuarios a L1. En principio, el Sequencer de una cadena puede adoptar diferentes formas; tal como está configurado Arbitrum One actualmente, el Sequencer es una entidad única y centralizada; eventualmente, se podrían otorgar capacidades de secuenciación a un comité distribuido de secuenciadores que lleguen a un consenso sobre el orden. Sin embargo, independientemente de su forma, el Sequencer tiene una limitación fundamental que no se aplica a ninguna otra parte del sistema: debe operar bajo sus propias suposiciones de seguridad, es decir, en principio no puede obtener seguridad directamente desde la capa 1 (en este caso Ethereum). Esto plantea la pregunta de cómo Arbitrum mantiene su capacidad de resistencia a la censura en caso de que el Sequencer se comporte de manera incorrecta.
Por ello arbitrum creó una vía alterna que permite evitar por completo al Sequencer para enviar cualquier transacción de Arbitrum (incluyendo una que, por ejemplo, inicie un mensaje de L2 a L1 para retirar fondos) directamente desde la capa 1. Este mecanismo preserva la resistencia a la censura incluso si el Sequencer no responde en absoluto o incluso si actúa de manera maliciosa.
5.1 Flujo de trabajo del Secuenciador.
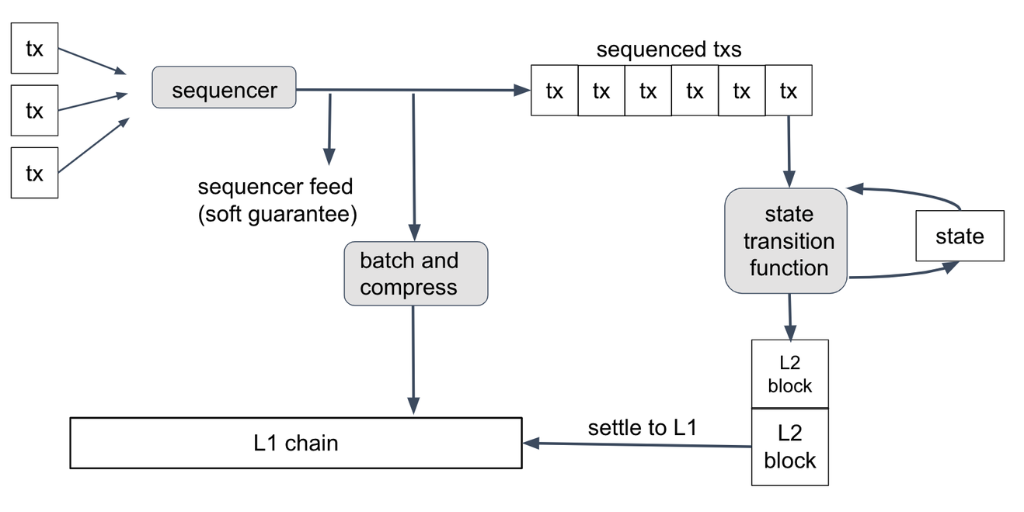
Primero, el usuario crea una transacción, la firma utilizando su billetera y la envía al Sequencer. El trabajo del Sequencer, como su nombre indica, es tomar las transacciones que llegan, colocarlas en una secuencia ordenada y publicar esa secuencia.
Una vez que las transacciones están secuenciadas, se ejecutan a través de la función de transición de estado, una por una, en orden. La función de transición de estado toma como entrada el estado actual de la cadena (saldos de cuentas, código de contrato, etc.) junto con la siguiente transacción. Actualiza el estado y, a veces, emite un nuevo bloque de Capa 2 en la cadena.
Dado que el protocolo no confía en que el Sequencer no inserte basura en su secuencia, la función de transición de estado detectará y descartará cualquier transacción inválida (por ejemplo, mal formada) en la secuencia. Un Sequencer bien comportado filtrará las transacciones inválidas para que la función de transición de estado nunca las vea, lo que reduce los costos y mantiene bajas las tarifas de transacción. Sin embargo, este mecanismo seguirá funcionando correctamente independientemente de lo que el Sequencer incluya en su secuencia. (Las transacciones en la secuencia están firmadas por sus remitentes, por lo que el Sequencer no puede crear transacciones falsificadas).
La función de transición de estado es determinista, lo que significa que su comportamiento depende únicamente del estado actual y del contenido de la próxima transacción, y nada más. Debido a este determinismo, el resultado de una transacción T dependerá únicamente del estado inicial de la cadena, las transacciones anteriores a T en la secuencia y T misma.
Cualquier persona que conozca la secuencia de transacciones puede calcular la función de transición de estado por sí misma, y todas las partes honestas que lo hagan están garantizadas de obtener resultados idénticos. Esta es la forma normal en que operan los nodos en arbitrum: obtienen la secuencia de transacciones y ejecutan la función de transición de estado localmente. No se necesita un mecanismo de consenso para esto.
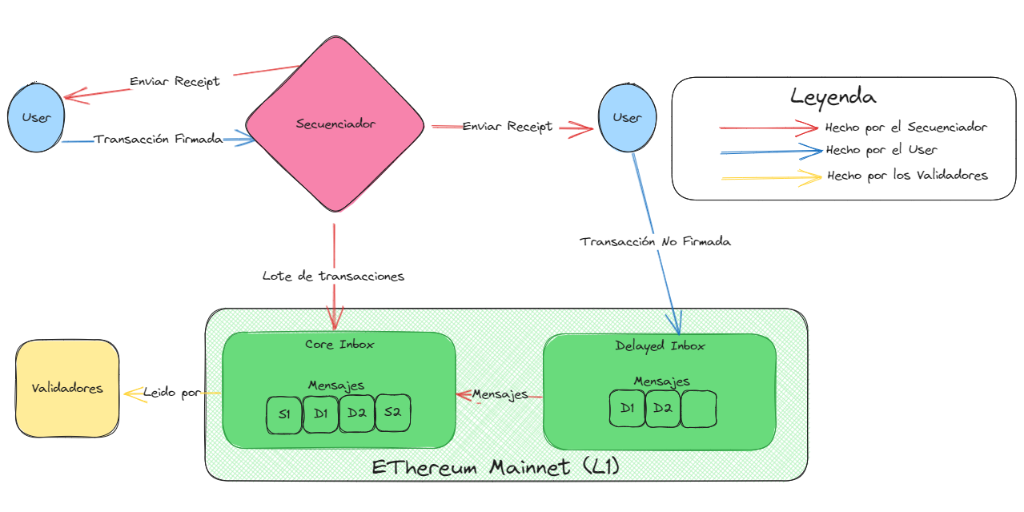
5.2 Core Inbox.
Cuando hablamos de "enviar una transacción a una cadena de Arbitrum", nos referimos a incluirla en la Core Inbox de la cadena. Una vez que las transacciones se incluyen en la Core Inbox, su ordenamiento queda establecido, la ejecución es completamente determinista y podemos considerar el estado resultante como finalizado en el nivel L1. El rol del Sequencer, o su falta de él, se limita estrictamente a lo que ocurre antes, es decir, cómo una transacción que llega a la Core Inbox.
Hay dos posibles rutas que una transacción puede seguir en dos escenarios diferentes: cuando hay un Sequencer que funciona correctamente (Caso Feliz/Común) y cuando hay un Sequencer defectuoso (Caso Infeliz/Raro).
5.3 Caso Feliz/Común.
Sequencer está activo y se comporta correctamente, partimos del supuesto de que el Sequencer está totalmente operativo y funciona con la intención de procesar las transacciones de los usuarios de la manera más segura y oportuna posible. El Sequencer puede recibir una transacción del usuario de dos formas: directamente mediante una solicitud RPC o a través de una L1 subyacente.
Si un usuario está enviando una transacción de Arbitrum "estándar" (es decir, interactuando con una aplicación nativa de L2), el usuario enviará la transacción firmada directamente al Sequencer, de manera similar a cómo un usuario envía una transacción a un nodo de Ethereum al interactuar con L1. Al recibirlo, el Sequencer lo ejecutará y entregará al usuario un receipt casi instantáneamente. Un corto tiempo después, generalmente no más de unos minutos, el Sequencer incluirá la transacción del usuario en un batch (o lote en español) y la publicará en L1 llamando a la función “addSequencerL2Batch” de la Core Inbox. Hay que destacar que solo el Sequencer tiene la autoridad para llamar a esta función; esta garantía de que ninguna otra parte puede incluir un mensaje directamente es, de hecho, lo que le da al Sequencer la capacidad única de proporcionar receipts instantáneos de "confirmación suave". Una vez publicadas en un batch, las transacciones tienen finalidad a nivel de L1.
Alternativamente, un usuario puede enviar su mensaje de L2 publicándolo en la L1 subyacente. Esta ruta es necesaria si el usuario desea realizar alguna operación en L1 junto con el mensaje de L2 y preservar la atomicidad entre ambos. El ejemplo típico aquí es un depósito de tokens a través de un bridge (es decir, poner una garantía en L1, y se mintearla en L2). El usuario lo hace publicando una transacción de L1 (es decir, enviando una transacción normal a un nodo de L1) que llama a uno de las funciones relevantes en el contrato Inbox, por ejemplo, “sendUnsignedTransaction”. Esto agrega un mensaje a lo que llamaremos delayed inbox (representada por delayedInboxAccs en el contrato Bridge), que es efectivamente una cola en la que los mensajes esperan antes de ser movidos a la Core Inbox. El Sequencer emitirá un receipt de L2 aproximadamente 10 minutos después de que la transacción se haya incluido en la delayed inbox (el motivo de este retraso es minimizar el riesgo de reorganizaciones tanto en L1 como en L2 que pueden invalidar los receipt de L2 del Sequencer). Nuevamente, el último paso es que el Sequencer incluya el mensaje de L2 en un batch, especificando cuántos mensajes de la delayed inbox se deben incluir, finalizando así la transacción.
En resumen, en cualquiera de los casos felices, el usuario primero entrega su mensaje al Sequencer, el cual se asegura de que llegue a la Core Inbox.
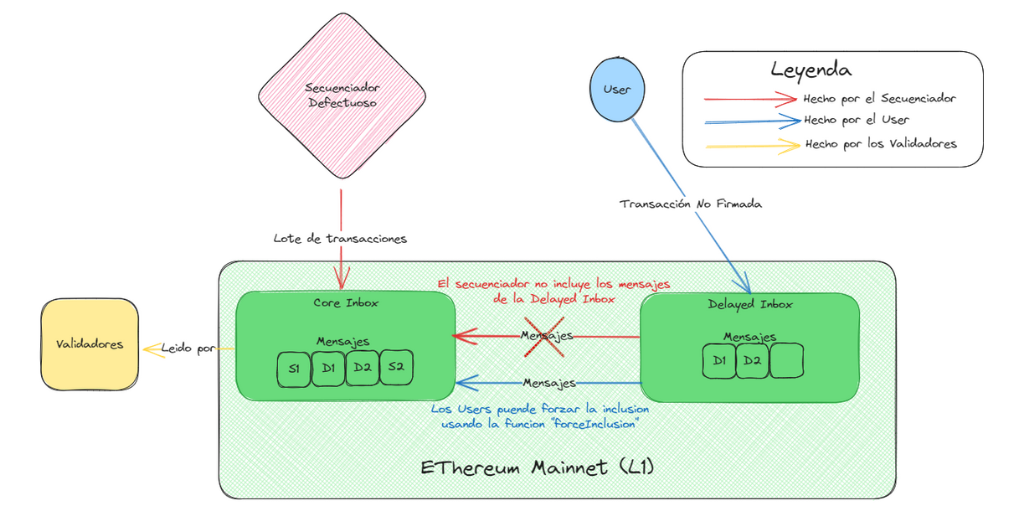
5.4 Caso Infeliz/Inusual.
Supongamos ahora que el Sequencer, por alguna razón, no está llevando a cabo su tarea de enviar mensajes. Aún así, un usuario puede lograr que su transacción se incluya en dos pasos:
Primero, envía su mensaje de L2 a través de L1 a la delayed inbox como se describió anteriormente. Es importante destacar que, aunque los mensajes atómicos (es decir, mensajes rápidos) entre cadenas son el caso común para usar la delayed inbox, en principio se puede utilizar para enviar cualquier mensaje de L2.
Una vez en la delayed inbox, obviamente no podemos confiar en el Sequencer para incluir la transacción en un lote. En su lugar, podemos utilizar la función “forceInclusion” de la Core Inbox. Una vez que un mensaje ha estado en la delayed inbox durante un tiempo suficiente, se puede llamar a forceInclusion para moverlo de la delayed inbox a la Core Inbox, momento en el cual se finaliza. Es crucial destacar que cualquier cuenta usuario puede llamar a la función “forceInclusion”.
Actualmente, en Arbitrum One, el tiempo de retraso entre el envío y la inclusión forzada es aproximadamente de 24 horas. Una inclusión forzada desde L1 afectaría directamente el estado de cualquier transacción de L2 no confirmada; al mantener un valor de retraso alto de manera conservadora, se asegura que solo se utilice en circunstancias extraordinarias. Además del retraso en sí, la ruta de inclusión forzada tiene la desventaja de la incertidumbre en cuanto al ordenamiento de las transacciones. Mientras se espera a que pase el retraso máximo de un mensaje, un Sequencer malintencionado podría, en principio, publicar directamente mensajes delante de él. Sin embargo, en última instancia, no hay nada que el Sequencer pueda hacer para evitar que se incluya en la Core Inbox, momento en el cual se fija su ordenamiento.
Si bien la ruta lenta e "infeliz" no es óptima y rara vez, o nunca, debería ser necesaria, su disponibilidad como opción garantiza que el Rollup de Arbitrum siempre preserve su modelo de seguridad trustless, incluso si las partes con permisos del sistema se comportan de manera defectuosa.
6.💻ArbOS.
El ArbOS es un componente confiable que actúa como un "pegamento del sistema" que se ejecuta en la Capa 2 como parte de la Función de Transición de Estado. ArbOS está diseñado para proporcionar funciones necesarias para un sistema de Capa 2, como la comunicación entre cadenas, la contabilidad de recursos y la economía de tarifas relacionadas con la Capa 2, y la gestión de cadenas.
El ArbOS existe principalmente porque tiene la capacidad de realizar de manera confiable, rápida y económica una gran parte del trabajo que anteriormente se realizaba en la Capa 1 (L1). El soporte de estas funciones en un software confiable de Capa 2, en lugar de incorporarlas en las reglas impuestas por la Capa 1, como lo hace Ethereum, ofrece ventajas significativas en costos, ya que estas operaciones pueden beneficiarse del menor costo de cómputo y almacenamiento en la Capa 2, en lugar de tener que gestionar esos recursos como parte de un contrato de Capa 1.
Tener un sistema operativo confiable en la Capa 2 también tiene ventajas significativas en flexibilidad, ya que el código de la Capa 2 es más fácil de evolucionar o personalizar para una cadena en particular, en comparación con una arquitectura impuesta por la Capa 1.
7.🎫Mensajes entre L1 Y L2.
7.1 Contratos L1 pueden enviar transacciones a L2
Un contrato en L1 tiene la capacidad de enviar una transacción a L2 de forma similar a un usuario, utilizando la llamada al contrato "inbox" en la cadena de Ethereum. Sin embargo, el resultado de esta transacción de L2 no estará disponible para el llamador en L1. Aunque la transacción se ejecutará en L2, el llamador en L1 no podrá ver los resultados.
La ventaja de este enfoque es su simplicidad y baja latencia. No obstante, la desventaja, en comparación con el otro método que se describirá pronto, es que la transacción de L2 podría revertirse si el llamador en L1 no especifica correctamente el precio del gas y la cantidad máxima de gas de L2. Dado que el llamador en L1 no puede ver el resultado de la transacción de L2, no puede estar seguro de que la transacción en L2 será exitosa.
Este escenario puede generar problemas significativos para ciertos tipos de interacciones entre L1 y L2. Por ejemplo, consideremos una transacción que involucra el depósito de un token en L1 para que esté disponible en una dirección de L2. Si la parte en L1 tiene éxito pero la parte en L2 se revierte, los tokens enviados al contrato "inbox" en L1 no se pueden recuperar ni en L2 ni en L1. Esta situación es claramente indeseable.
7.2 Transacciones basadas en tickets de L1 a L2.
Afortunadamente, existe un método alternativo para las llamadas de L1 a L2 que es más robusto ante problemas relacionados con el gas. Este método utiliza un sistema basado en tickets.
La idea principal es que un contrato de L1 puede enviar una transacción "reintentable" a la cadena. La cadena intentará ejecutar esta transacción y, si tiene éxito, no se requerirá ninguna acción adicional. Sin embargo, si la transacción falla, se generará un "ticketID" que identifica esa transacción fallida. Posteriormente, cualquier persona puede llamar a un contrato especial precompilado en L2, proporcionando el ticketID, con el fin de intentar redimir el ticket y volver a ejecutar la transacción.
Cuando se guarda una transacción para reintentar, se registra la dirección del remitente, la dirección de destino, el valor y los datos de la llamada. Todos estos detalles se almacenan, y el valor de la llamada se deduce de la cuenta del remitente y se "adjunta" lógicamente a la transacción guardada. Si el redimir tiene éxito, la transacción se completa, se emite un recibo y el ticketID se cancela, quedando inutilizable. Sin embargo, si el redimir falla, por ejemplo, porque la transacción empaquetada falla, se informará del fallo del redimir y el ticketID seguirá disponible para su redención.
Normalmente, el remitente original intentará que su transacción tenga éxito de inmediato, por lo que nunca será necesario registrarla ni reintentarla. Por ejemplo, en el caso de nuestro ejemplo de "depósito de tokens", en la situación ideal y común, solo se requerirá una única firma del usuario. Si esta ejecución inicial falla, el ticketID seguirá existiendo como una medida de respaldo que otros pueden redimir más adelante.
El envío de una transacción de esta manera tiene un costo en ETH que el remitente debe pagar, y este costo varía según el tamaño de los datos de la llamada de la transacción. Una vez enviada, el ticket es válido durante aproximadamente una semana. Si el ticket no se ha redimido durante ese período, se eliminará.
Cuando se redime el ticket, la transacción preempaquetada se ejecuta con el remitente y el origen siendo iguales al remitente original, y con el destino, el valor y los datos de la llamada proporcionados por el remitente en el momento del envío.
Este mecanismo es un poco más complejo que las transacciones habituales de L1 a L2, pero tiene la ventaja de que el costo de envío es predecible y el ticket estará siempre disponible para su redención si se paga el costo de envío. Mientras haya algún usuario dispuesto a redimir el ticket, la transacción de L2 podrá ejecutarse eventualmente y no se perderá de forma silenciosa.
7.3 Llamadas basadas en tickets de L2 a L1.
Las llamadas de L2 a L1 operan de manera similar, utilizando un sistema basado en tickets. Cuando un contrato de L2 desea enviar una transacción a L1, puede llamar a una función del contrato precompilado ArbSys. Después de que la transacción de L2 se confirma y se ejecuta en L1 (por lo general, después de algunos días), se genera un ticket en el contrato de salida (outbox) de L1. Cualquier persona puede activar este ticket llamando a una función específica del contrato de salida de L1 y proporcionando el ID del ticket correspondiente. El ticket se marca como redimido sólo si la transacción de L1 se completa sin revertirse.
Estos tickets de L2 a L1 no tienen una limitación de tiempo y permanecen válidos hasta que se redimen exitosamente. No se requiere ningún pago de almacenamiento, ya que los tickets (representados por un hash en Merkle tree de tickets) se registran en el almacenamiento de Ethereum, el cual no implica ningún costo de almacenamiento. Los gastos asociados con el almacenamiento de las raíces de Merkle de los tickets están cubiertos por las tarifas de transacción de L2.
8.⛽Gas.
NitroGas (llamado así para evitar confusiones con el gas de Ethereum en la Capa 1) se utiliza en Arbitrum para rastrear el costo de ejecución en una cadena Nitro. Funciona de manera similar al gas en Ethereum, en el sentido de que cada instrucción EVM tiene un costo de gas igual al que tendría en Ethereum.
9.🛑El límite de velocidad.
La seguridad de las cadenas Nitro depende de la suposición de que cuando un validador crea un RBlock (es decir un block en el Rollup), otros validadores lo verificarán y responderán con un RBlock correcto y un desafío si está equivocado. Esto requiere que los demás validadores tengan el tiempo y los recursos necesarios para verificar cada RBlock lo suficientemente rápido como para emitir un desafío oportuno. El protocolo Arbitrum tiene esto en cuenta al establecer plazos para los RBlocks.
Esto establece un límite de velocidad efectivo en la ejecución de una cadena Nitro: a largo plazo, la cadena no puede avanzar más rápido de lo que un validador puede emular su ejecución. Si los RBlocks se publican a una velocidad más rápida que el límite de velocidad, sus plazos se alejarán cada vez más en el futuro. Debido al límite, impuesto por los contratos del protocolo de rollup, de cuán lejos en el futuro puede estar un plazo, esto eventualmente ralentizará los nuevos RBlocks, lo que impondrá el límite de velocidad efectivo.
Poder establecer el límite de velocidad de manera precisa depende de poder estimar el tiempo requerido para validar un RBlock, con cierta precisión. Cualquier incertidumbre en la estimación del tiempo de validación nos obligará a establecer un límite de velocidad más bajo para estar seguros. Y no queremos establecer un límite de velocidad más bajo, así que tratamos de permitir una estimación precisa.
10.💸Tarifas.
Las transacciones de los usuarios pagan tarifas para cubrir el costo de operar la cadena. Estas tarifas son evaluadas y recolectadas por ArbOS en L2. Están denominadas en ETH. Se cobran tarifas por dos recursos que una transacción puede utilizar:
10.1 Tarifas de gas de L2.
Las tarifas de gas de L2 funcionan de manera muy similar al gas en Ethereum. Una transacción utiliza una cierta cantidad de gas, y esto se multiplica por la tarifa base de L2 para obtener la tarifa de gas de L2 cobrada a la transacción.
La tarifa base de L2 se establece mediante una versión del "mecanismo exponencial" que se ha discutido ampliamente en la comunidad de Ethereum y que se ha demostrado equivalente al mecanismo de fijación de precios de gas EIP-1559 de Ethereum.
El algoritmo compara el uso de gas con un parámetro llamado "límite de velocidad", que es la cantidad objetivo de gas por segundo que la cadena puede manejar de manera sostenible a lo largo del tiempo. (Actualmente, el límite de velocidad es de 7 millones de gas por segundo). El algoritmo realiza un seguimiento de un saldo de gas pendiente. Cada vez que una transacción consume gas, ese gas se agrega al saldo pendiente. Cada vez que el reloj avanza un segundo, se resta el límite de velocidad del saldo pendiente, pero el saldo pendiente nunca puede ser inferior a cero.
De manera intuitiva, si el saldo pendiente aumenta, el algoritmo debe aumentar el precio del gas para reducir el uso de gas, porque el uso está por encima del nivel sostenible. Si el saldo pendiente disminuye, el precio debería disminuir nuevamente porque el uso ha estado por debajo del límite sostenible, por lo que se puede dar la bienvenida a un mayor uso de gas.
Para hacer esto más preciso, la tarifa base es una función exponencial del saldo pendiente, F = exp(-a(B-b)), donde a y b son constantes adecuadamente elegidas: “a” controla la rapidez con la que el precio aumenta con el saldo pendiente, y “b” permite un saldo pendiente pequeño antes de que comience la escalada de la tarifa base.
10.2 Tarifas de calldata de L1.
Las tarifas de calldata de L1 se aplican sólo si una transacción entra en L2 a través del Sequencer (es decir, no se recibe a través de una transacción L2 a L2). Estas tarifas se pagan al Sequencer y cubren los costos de operar el Sequencer y mantener la sincronización con L1.
La tarifa se basa en el tamaño del calldata de L1 de la transacción. Hay una tarifa base por unidad de calldata, y la tarifa total se calcula multiplicando la tarifa base por el tamaño del calldata.
Es importante tener en cuenta que estas tarifas no se pagan a los validadores de L2. Los validadores reciben recompensas de validación separadas que provienen del contrato ArbRewarder y están diseñadas para incentivar la validación en lugar de las tarifas de transacción.
11.🕵️♂️Nodos validadores.
Algunos nodos de Arbitrum optarán por actuar como validadores. Esto significa que supervisan el progreso del protocolo de rollup y participan en ese protocolo para avanzar el estado de la cadena de manera segura.
No todos los nodos elegirán hacer esto. Debido a que el protocolo de rollup no decide lo que hará la cadena, sino que simplemente confirma el comportamiento correcto que está completamente determinado por los mensajes del inbox, un nodo puede ignorar el protocolo de rollup y simplemente calcular por sí mismo el comportamiento correcto.
Cada validador puede elegir su propio enfoque, pero esperamos que los validadores sigan tres estrategias comunes:
La estrategia del validador activo intenta avanzar el estado de la cadena proponiendo nuevos RBlocks. Un validador activo siempre tiene un stake, ya que crear un RBlock requiere tener uno. Una cadena realmente sólo necesita un validador activo honesto; tener más es un uso ineficiente de recursos. Para la cadena Arbitrum One, Offchain Labs ejecuta un validador activo.
La estrategia del validador defensivo observa el funcionamiento del protocolo de rollup. Si solo se proponen RBlocks correctos, esta estrategia no realiza stake. Pero si se propone un RBlock incorrecto, esta estrategia interviene publicando un RBlock correcto o haciendo stake en un RBlock correcto que otra parte haya publicado. Esta estrategia evita los stakes cuando las cosas van bien, pero si alguien es deshonesto, realiza una stake para defender el resultado correcto.
La estrategia del validador de vigilancia nunca realiza stakes. Simplemente observa el protocolo de rollup y si se propone un RBlock incorrecto, da la alarma (por los medios que elija) para que otros puedan intervenir. Esta estrategia asume que otras partes disponibles a hacer stake estarán dispuestas a intervenir para tomar parte de la apuesta del proponente deshonesto, y que esto puede suceder antes de que expire el plazo del RBlock deshonesto.
(En la práctica, esto permitirá varios días para una respuesta).
En condiciones normales, los validadores que utilizan las estrategias defensivas y de vigilancia no harán nada más que observar. Un actor malicioso que esté considerando hacer trampa no podrá saber cuántos validadores defensivos y de vigilancia están operando de incógnito. Quizás algunos validadores defensivos se anuncien, pero otros probablemente no lo hagan, por lo que un posible atacante siempre tendrá que preocuparse de que los defensores estén esperando para aparecer.
12.⚔Desafíos.
Para poder entender cómo funciona el sistema de desafíos en arbitrum, usaremos el siguiente ejemplo:
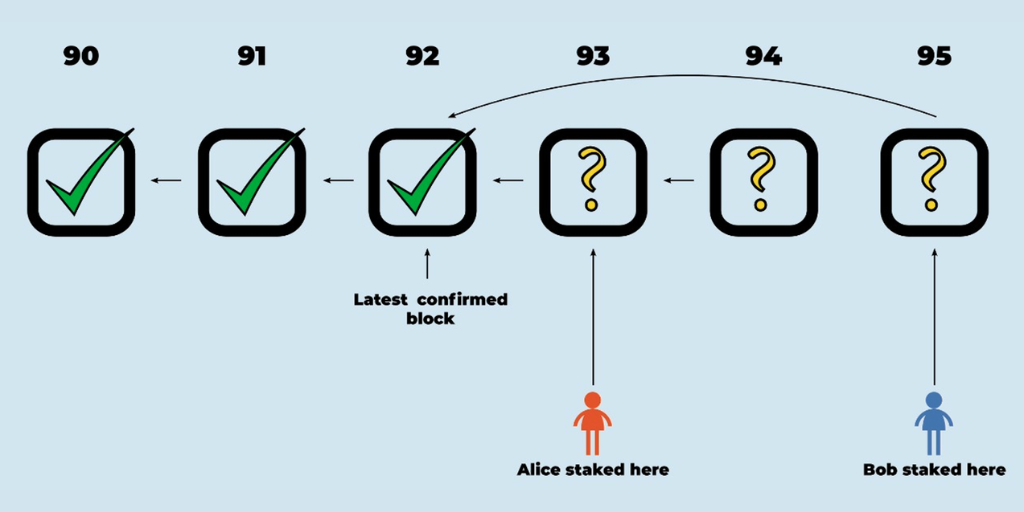
Los RBlocks 93 y 95 son hermanos (ambos tienen 92 como predecesor). Alice tiene un stake en el Rblock 93 y Bob tiene una stake en el Rblock 95.
En este punto, sabemos que Alice y Bob no están de acuerdo sobre la corrección del RBlock 93, ya que Alice está convencida de que el 93 es correcto, mientras que Bob está convencido de que el 93 es incorrecto. (Bob tiene una stake en el bloque 95, que implícitamente afirma que el 92 es el último RBlock correcto antes que él, lo que implica que el 93 debe ser incorrecto).
Cuando dos participantes tienen stakes en RBlocks hermanos y ninguno de ellos está desafiando actualmente, cualquier persona puede iniciar un desafío entre los dos. El protocolo de agregación de transacciones registrará el desafío y actuará como árbitro, declarando eventualmente un ganador y confiscando el stake del perdedor. El perdedor será eliminado como staker.
El desafío es un juego en el que Alice y Bob se turnan para hacer movimientos, con un contrato de Ethereum como árbitro. Alice, como defensora, comienza primero.
El juego consta de dos fases: El protocolo de disección y prueba de un solo paso (o one-step proof en inglés). La fase de disección reducirá el tamaño de la disputa hasta que se trate de una disputa sobre una sola instrucción de ejecución. Luego, la prueba de un solo paso determinará quién tiene razón en esa instrucción en particular.
Describiremos dos veces la parte de la disección del protocolo. Primero, explicaremos una versión simplificada que es más fácil de entender pero menos eficiente. Luego, describiremos cómo difiere la versión real de la simplificada.
12.1 Protocolo de Disección: Versión Simplificada.
Alice está defendiendo la afirmación de que, comenzando con el estado en el RBlock predecesor, la Máquina Virtual puede avanzar al estado especificado en el RBlock A. Básicamente, está afirmando que la Máquina Virtual puede ejecutar N instrucciones, y que esa ejecución consumirá M mensajes de el inbox y transformará el hash de las salidas de H' a H.
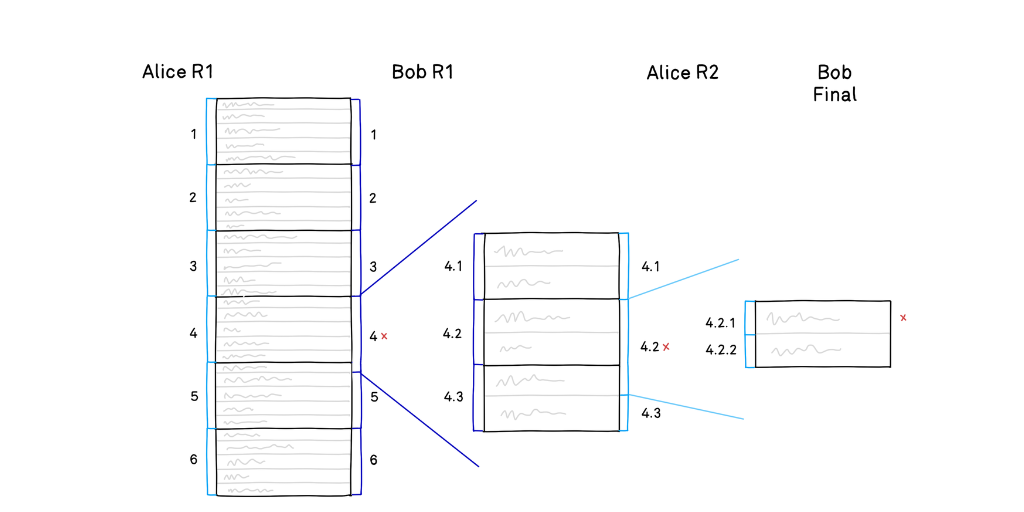
El primer movimiento de Alice requiere que ella divida sus afirmaciones sobre los estados intermedios entre el inicio (0 instrucciones ejecutadas) y el final (N* instrucciones ejecutadas*). Por lo tanto, requerimos que Alice divida su afirmación por la mitad y publique el estado en el punto intermedio, después de que se hayan ejecutado N/2 instrucciones.
Ahora Alice ha dividido efectivamente su afirmación de N pasos en dos afirmaciones de (N/2) pasos. Bob tiene que señalar una de esas dos afirmaciones de tamaño reducido y afirmar que es incorrecta.
En este punto, estamos básicamente en la situación original: Alice ha hecho una afirmación con la que Bob no está de acuerdo. Pero hemos reducido el tamaño de la afirmación a la mitad, de N a N/2. Podemos aplicar el mismo método nuevamente, con Alice dividiendo y Bob eligiendo una de las mitades, para reducir el tamaño a N/4. Y podemos continuar dividiendo por la mitad, de acuerdo con lo cual, después de un número logarítmico de rondas, Alice y Bob estarán en desacuerdo sobre un solo paso de ejecución. Ahí es donde termina la fase de disección del protocolo y Alice debe presentar una prueba de un solo paso que será verificada por el EthBridge.
12.2 ¿Por qué la Disección Identifica Correctamente a un actor malicioso?.
Antes de hablar sobre las complejidades del protocolo real de desafío, detengámonos a comprender por qué la versión simplificada del protocolo es correcta. La corrección implica dos cosas:
-
(1) si la afirmación inicial de Alice es correcta, Alice siempre puede ganar el desafío.
-
(2) si la afirmación inicial de Alice es incorrecta, Bob siempre puede ganar el desafío.
Para demostrar (1), observa que si la afirmación inicial de Alice es correcta, ella puede ofrecer una afirmación veraz del punto intermedio y ambas afirmaciones de tamaño reducido implicadas serán correctas. Por lo tanto, sin importar a cuál de las dos mitades se oponga Bob, Alice estará nuevamente en la posición de defender una afirmación correcta. En cada etapa del protocolo, Alice estará defendiendo una afirmación correcta. Al final, Alice tendrá una afirmación correcta de un solo paso que probar, por lo que esa afirmación será demostrable y Alice puede ganar el desafío.
Para demostrar (2), observa que si la afirmación inicial de Alice es incorrecta, esto solo puede deberse a que su punto final afirmado después de N pasos es incorrecto. Ahora, cuando Alice ofrece su afirmación del estado intermedio, esa afirmación puede ser correcta o incorrecta. Si es incorrecta, Bob puede desafiar la afirmación de la primera mitad de Alice, que será incorrecta. Si la afirmación de Alice sobre el estado intermedio es correcta, entonces su afirmación de la segunda mitad debe ser incorrecta, por lo que Bob puede desafiar eso. Entonces, pase lo que pase, Bob podrá desafiar una afirmación incorrecta de tamaño reducido. En cada etapa del protocolo, Bob puede identificar una afirmación incorrecta para desafiar. Al final, Alice tendrá una afirmación incorrecta de un solo paso que probar, lo cual no podrá hacer, por lo que Bob puede ganar el desafío.
(Si eres exigente con la precisión matemática, debería estar claro cómo estos argumentos pueden convertirse en pruebas mediante inducción sobre N).
12.3 El Protocolo Real de Disección.
El protocolo real de disección es conceptualmente similar al simplificado descrito anteriormente, pero con varios cambios que mejoran la eficiencia o tratan casos especiales necesarios. Aquí tienes una lista de las diferencias.
Disección sobre bloques L2 y luego sobre instrucciones: La afirmación de Alice se basa en un RBlock, que afirma el resultado de crear algunos bloques de Nitro de Capa 2. La disección ocurre primero sobre estos bloques de Capa 2 para reducir la disputa a una disputa sobre un solo bloque de Nitro de Capa 2. En este punto, la disputa se transforma en una disputa sobre una ejecución única de la Función de Transición de Estado o, en otras palabras, sobre la ejecución de una secuencia de instrucciones WAVM. Luego, el protocolo ejecuta nuevamente el subprotocolo de disección recursiva, esta vez sobre las instrucciones WAVM, para reducir la disputa a una sola instrucción. La disputa concluye con una prueba de un solo paso de una instrucción (o una parte que no actúa y pierde por tiempo de espera).
Disección de K vías: En lugar de dividir una afirmación en dos segmentos de tamaño N/2, la dividimos en K segmentos de tamaño N/K. Esto requiere publicar K-1 afirmaciones intermedias en puntos uniformemente espaciados a lo largo de la ejecución afirmada. Esto reduce el número de rondas en un factor de log(K)/log(2).
Responder una disección con una disección: En lugar de requerir dos movimientos en cada ronda del protocolo, donde Alice disecciona y Bob elige un segmento para desafiar, requerimos que Bob, al desafiar un segmento, publique su propio estado final afirmado para ese segmento (que debe diferir del de Alice) y su propia disección de su versión del segmento. Luego, Alice responderá identificando un subsegmento, publicando un estado final alternativo para ese segmento y diseccionándolo. Esto reduce el número de movimientos en el juego en un factor adicional de 2, ya que el tamaño se reduce en un factor de K en cada movimiento, en lugar de cada dos movimientos.
Manejo del caso de inbox vacía: El AVM real no siempre puede ejecutar N unidades de gas sin quedarse atascado. La máquina puede detenerse o puede tener que esperar porque su inbox se agotó y no puede continuar hasta que lleguen más mensajes. Por lo tanto, se permite que Bob responda a la afirmación de Alice de N pasos alegando que N pasos no son posibles. El protocolo real permite que cualquier respuesta (excepto la afirmación inicial) reclame un estado final especial que significa esencialmente que la cantidad especificada de ejecución no es posible bajo las condiciones actuales.
Límites de tiempo: A cada jugador se le asigna un tiempo permitido. El tiempo total que un jugador utiliza para todos sus movimientos debe ser menor que el tiempo permitido, de lo contrario, perderá el juego. Piensa en el tiempo permitido como aproximadamente una semana.
Debería quedar claro que estos cambios no afectan la corrección básica del protocolo de desafío. Sin embargo, mejoran su eficiencia y le permiten manejar todos los casos que pueden surgir en la práctica.
12.4 Prueba de un Paso (One Step Proofs).
Las pruebas de un Paso (OSP, por sus siglas en inglés) se basan en ciertas suposiciones sobre los casos que pueden derivar en una ejecución correcta. En este documento se detallan esas suposiciones sobre lo que se está ejecutando.
Si un caso es "Imposible", es decir, se asume que el caso nunca surgirá en una ejecución correcta, entonces el OSP puede implementar cualquier semántica de instrucción en ese caso.
En un desafío entre partes malintencionadas, cualquier caso puede surgir. El protocolo de desafío debe tomar medidas seguras en cada caso. Sin embargo, la semántica de las instrucciones puede ser peculiar en tales casos, ya que si ambas partes en un desafío son malintencionadas, al protocolo no le importa quién gana el desafío.
En un desafío con una parte honesta, dicha parte nunca necesitará probar de forma incremental un caso Imposible. La parte honesta solo afirmará ejecuciones correctas, por lo que sólo deberá probar casos posibles.
En un desafío con una parte honesta y otra deshonesta, esta última podría afirmar una ejecución que transicione a un caso “imposible”. Sin embargo, tal ejecución debe incluir una ejecución inválida de un caso “posible” anterior en la afirmación. Dado que un desafío que involucra a una parte honesta eventualmente requerirá una OSP sobre la primera instrucción en la que las partes no están de acuerdo, la OSP se realizará en el punto de divergencia anterior y no en la ejecución posterior de un caso “imposible”.
En general, algunos casos “imposibles” serán detectables por el verificador de OSP y otros no. Para garantizar la seguridad, los casos imposibles detectables deben definirse mediante la transición de la máquina a un estado de error, lo que permitiría que la gobernanza eventualmente promueva una actualización para recuperarse del error. Un caso imposible indetectable, en caso de que ocurra en una ejecución correcta, podría provocar una falla de seguridad.
Las siguientes suposiciones, en conjunto, deben evitar que surja un caso imposible en una ejecución correcta:
El código WAVM se genera mediante Arbitrator a partir de WASM válido.
WAVM es el nombre del conjunto de instrucciones personalizado similar a WASM utilizado para las pruebas. Arbitrator transpila el código WASM a WAVM. También invoca a wasm-validate de wabt (WebAssembly Binary Toolkit) para garantizar que el WASM de entrada sea válido. Se asume que el WAVM producido por Arbitrator a partir de WASM válido nunca encontrará un caso inalcanzable. Los mensajes de la inbox no deben ser demasiado grandes.
El método actual de hash de la inbox requiere que el mensaje completo de la misma esté disponible para la prueba. Dicho mensaje no debe ser demasiado grande como para impedir que se suministre para la prueba, y esto está garantizado para las inboxes.
El límite de longitud actual es de 117,964 bytes, que corresponde al 90% del tamaño máximo de transacción que aceptará Geth, dejando 13,108 bytes para otros datos de prueba.
Las preimágenes solicitadas deben ser conocidas y no demasiado grandes.
WAVM tiene un opcode que resuelve la preimagen de un hash Keccak-256. Sin embargo, esto solo se puede ejecutar si la preimagen ya es conocida por todos los nodos y solo se puede probar si la preimagen no es demasiado larga. Las violaciones de esta suposición no pueden ser detectadas por el verificador de OSP. El límite de longitud actual es de 117,964 bytes por las razones mencionadas anteriormente.
A continuación se presenta una lista de las preimágenes que pueden ser solicitadas por Nitro y por qué son conocidas por todas las partes y no son demasiado grandes:
- Headers de los bloques:
Nitro puede solicitar hasta los últimos 256 headers de bloques de Capa 2 (L2). El último header de bloque es necesario para determinar el estado actual, y los bloques anteriores son necesarios para implementar la instrucción EVM BLOCKHASH.
Esto es seguro, ya que los headers de los bloques anteriores tienen un tamaño fijo y son conocidos por todos los nodos.
- Acceso al trie de estado:
Para resolver el estado, Nitro recorre el trie de estado resolviendo preimágenes. Esto es seguro, ya que los validadores retienen el estado de archivo de los bloques no confirmados, cada rama del trie tiene un tamaño fijo y la única entrada de tamaño variable en el trie es el código de contrato, que está limitado por la EIP-170 a aproximadamente 24KB.
Estas suposiciones, en conjunto, están diseñadas para evitar que surja un caso imposible en una ejecución correcta. Se han establecido salvaguardias para garantizar la validez, la seguridad de las ejecuciones y pruebas en el protocolo OSP.
12.5 Eficiencia.
El protocolo de desafío está diseñado de manera que la disputa pueda resolverse con un mínimo de trabajo requerido por el protocolo (a través de sus contratos de Ethereum de Capa 1) en su papel de árbitro. Cuando es el turno de Alice, el protocolo solo necesita realizar un seguimiento del tiempo que Alice utiliza y asegurarse de que su movimiento incluya los K-1 puntos intermedios requeridos. El protocolo no necesita prestar atención a si esas afirmaciones son correctas de alguna manera; solo necesita saber si el movimiento de Alice "tiene la forma correcta".
El único punto en el que el protocolo necesita evaluar un movimiento "por sus méritos" es en la prueba de un solo paso, donde necesita examinar la prueba de Alice y determinar si la prueba proporcionada realmente establece la corrección o incorrección de la instrucción en disputa. Sin embargo, dado que esta es una prueba de un solo paso y el tamaño de la instrucción es relativamente pequeño, el costo computacional y de almacenamiento asociado también es manejable.
En general, el protocolo de desafío está diseñado para ser eficiente y escalable, minimizando la carga en el árbitro y permitiendo resolver las disputas de manera justa y confiable.
13.🌉Arbitrum Bridge.
Gracias a la habilidad de protocolo de arbitrum de intercambiar mensajes entre L1 y L2, los usuarios de la red pueden aprovecharse de esto para mover activos o tokens de una manera trustless de la red de Arbitrum a Ethereum y viceversa. En principio cualquier tipo de activo puede ser punteado, ya sea, Ether, tokens ERC20, tokens ERC-721, etc.
13.1 Depósito y Retiro de Ether (ETH).
Para mover Ether de la red de Etherum a la red de Arbitrum, se debe ejecutar un transacción de depósito usando la función “Inbox.depositEth”. Esto transfiere los fondos hacia el contrato de bridge en L1 y acredita al usuario como los mismos fondos en la red de Arbitrum hacia una dirección específica.
A nivel de programacion la sintaxis se ve de la siguente manera:
function depositEth(address destAddr) external payable override returns (uint256)
La siguiente imagen ilustra todo esto de una manera más sencilla:
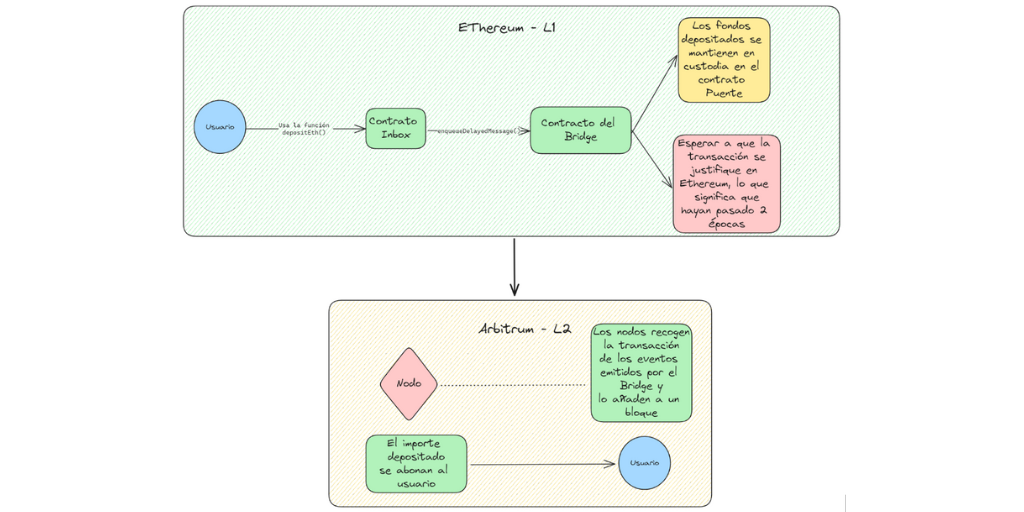
Nota: en criptografía, el término “Época” ( o epoch en inglés) se refiere a una unidad de tiempo en la que los validadores de la red permanecen constantes. Se mide en bloques.
Se puede retirar ether utilizando la funcion “ withdrawEth” de ArbSys:
ArbSys(100).withdrawEth{ value: 2300000 }(destAddress)
Al realizar el retiro, el saldo de Ether se quema en el lado de Arbitrum y luego estará disponible en el lado de Ethereum.
ArbSys.withdrawEth es en realidad una función conveniente que es equivalente a llamar a ArbSys.sendTxToL1 con calldataForL1 vacío. Al igual que cualquier otra llamada sendTxToL1, requerirá una llamada adicional a Outbox.executeTransaction en L1 después de que el período de disputa haya pasado para que el usuario finalice el reclamo de sus fondos en L1. Una vez que se ejecuta el retiro desde el Outbox, el saldo de Ether del usuario se acreditará en L1.
13.2 Depósito y Retiro de ERC-20 tokens.
El protocolo de arbitrum técnicamente no distingue entre los diferentes standards de tokens que existen, por ello, no le da ventajas especiales a ningún tipo de bridge en particular. Sin embargo, el equipo de Off Chain Labs ha creado el “Canonical Bridge”, el cual es el recomendado para los usuarios que usan arbitrum. Básicamente este “Canonical Bridge” es una Dapp con contratos tanto en Ethereum como en Arbitrum que se aprovecha de la capacidad de paso de mensajes entre L1 y L2 explicados anteriormente.
13.3 Tipo de Diseño.
Para el puente de tokens se utiliza el término “Gateway”, el cual es un mecanismo utilizado para facilitar las transferencias de activos entre los dominios de Ethereum y Arbitrum.
La razón principal que motivó a crear el mecanismo “Gateway” fue la funcionalidad.
Generalmente, la funcionalidad de gateway estándar es suficiente para la mayoría de tokens, esto implica lo siguiente: un contrato de un token en Ethereum se asocia con un contrato de token emparejado en Arbitrum. Depositar un token involucra depositar cierta cantidad del token en un bridge contract en L1 y mintear la misma cantidad en el contrato previamente emparejado en L2. En L2, el contrato emparejado se comporta igual que un contrato de token ERC20 normal.
Por otro lado, al retirar es necesario quemar cierta cantidad del token, que luego de un tiempo se puede reclamar del bridge contract en L1.
Sin embargo, muchos tokens requieren sistemas con gateways personalizadas, en donde las posibilidades son complicadas de generalizar. Por ejemplo:
-
Aquellos tokens que producen intereses para sus holders deben garantizar que los mismos sean distribuidos correctamente entre las redes y que no se acumulen en el bridge contract.
-
Las implementaciones de WETH entre dominios (Ethereum y Arbitrum) requieren que los tokens pasen de wrapped a unwrapped a medida que se mueven entre L1 a L2 y viceversa.
Por lo tanto, la arquitectura del bridge no solo debe ser diseñada para la funcionalidad estándar (depósitos/retiros), sino también para casos personalizados que necesiten otras funciones.
13.4 Implementación canónica L2 por contrato de token L1.
Está muy bien tener varias Gateways personalizadas, sin embargo se debe evitar que un único token de L1 pueda estar emparejado por varios contratos en L2 (lo que puede generar problemas de colisión y confusión entre los usuarios y desarrolladores). Por ello, es necesario tener una forma que rastree que token L1 y que gateway utilizará, y al mismo tiempo, tener un oráculo que mapee las direcciones de los tokens a través de los dominios de Ethereum y Arbitrum.
13.5 Implementación del puente canónico de tokens.
Con lo anterior en mente, se muestra una visión general de la arquitectura de puente de tokens. La misma está conformada de 3 tipos de contratos:
-
Contrato de Activos: Son los propios contratos de tokens, es decir, un ERC20 en L1 y su homólogo en Arbitrum.
-
Gateways: Pares de contratos (uno en L1, otro en L2) que implementan un tipo particular de puente de activos entre cadenas.
-
Routers: Exactamente dos contratos (uno en L1, uno en L2) que dirigen cada activo a su Gateway designada.
Todas las transferencias de tokens de Ethereum a Arbitrum se inician a través del contrato llamado L1GatewayRouter. Este reenvía la llamada de depósito del token al contrato L1ArbitrumGateway correspondiente. L1GatewayRouter es responsable de asignar las direcciones de los tokens L1 a L1Gateway, actuando así como oráculo de direcciones L1/L2 y garantizando que cada token corresponde a una única Gateway. El L1ArbitrumGateway se comunica con un L2ArbitrumGateway (usando los tickets reintentables explicados anteriormente).
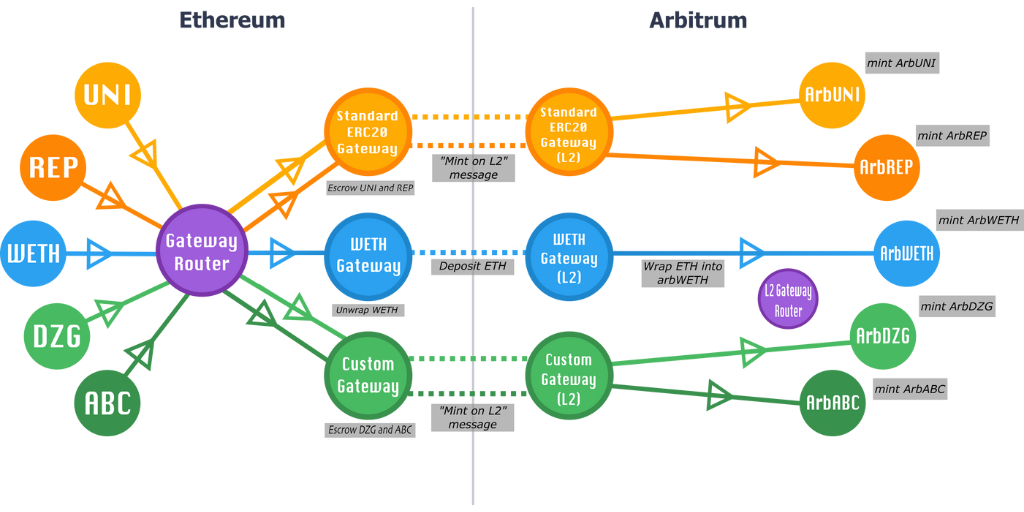
Del mismo modo, las transferencias de Arbitrum a Ethereum se inician a través del contrato L2GatewayRouter, que reenvía las llamadas a la L2ArbitrumGateway del token, que a su vez se comunica con su correspondiente L1ArbitrumGateway (típicamente/esperado a través del envío de mensajes a la Outbox).
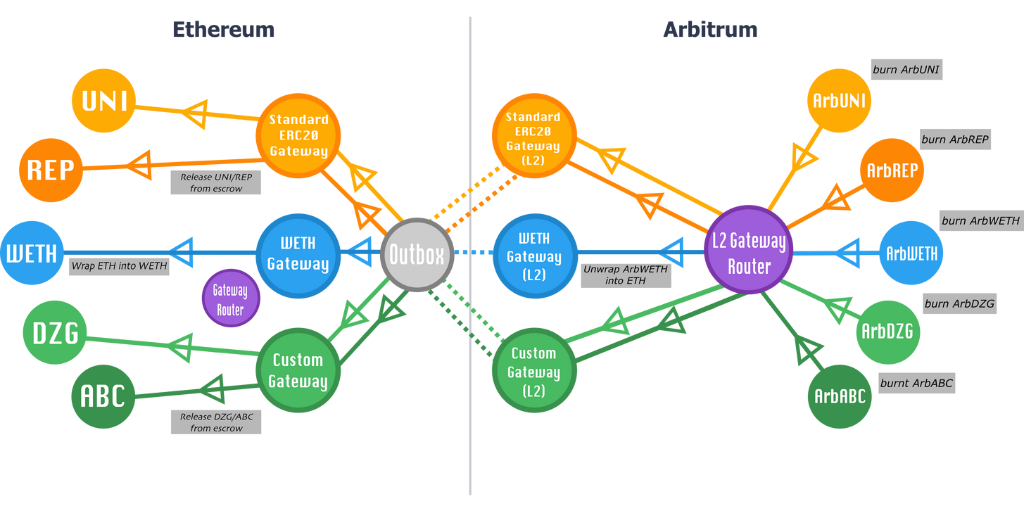
Para cualquier emparejamiento de gateway dado, requerimos que las llamadas se inicien a través del GatewayRouter, y que los gateways se ajusten a las interfaces TokenGateway; las interfaces TokenGateway deben ser lo suficientemente flexibles y extensibles como para soportar cualquier funcionalidad de puente que pueda requerir un token en particular.
13.6 Puente estándar por defecto.
Por defecto, cualquier token ERC20 en L1 que no esté registrado en una gateway puede ser puenteado a la gateway estándar ERC20 sin problemas.
Puede utilizar el front-end del bridge o este script para cruzar un token desde L1 a L2 y viceversa.
13.7 Ejemplo: Depósito/retirada de Arb-ERC20 estándar.
Para ayudar a ilustrar cómo se ve todo esto en la práctica, vamos a ir a través de los pasos de cómo depositar y retirar SomeERC20Token a través de nuestra Gateway ERC20 estándar. Suponemos que SomeERC20Token ya se ha registrado en el L1GatewayRouter para utilizar la Gateway ERC20 estándar.
Depósitos.
-
Un usuario llama a
GatewayRouter.outboundTransferCustomRefund(con la dirección L1 deSomeERC20Tokencomo argumento). -
GatewayRouterbusca la gateway deSomeERC20Tokeny descubre que se trata de una Gateway ERC20 estándar (el contratoL1ERC20Gateway). -
GatewayRouterllama aL1ERC20Gateway.outboundTransferCustomRefund, reenviando los parámetros apropiados. -
L1ERC20Gatewaydeposita los tokens y crea un ticket reintentable para activar la funciónfinalizeInboundTransferdeL2ERC20Gatewayen L2. -
finalizeInboundTransfermintea la cantidad apropiada de tokens en el contratoarbSomeERC20Tokenen L2.
Nota: Hay que tener en cuenta que es posible que algunas gateways personalizadas antiguas no tengan implementado outboundTransferCustomRefund y GatewayRouter.outboundTransferCustomRefund no recurra a outboundTransfer. En esos casos, se utiliza la función GatewayRouter.outboundTransfer.
Tenga en cuenta que arbSomeERC20Token es una instancia de StandardArbERC20, que incluye las funciones bridgeMint y bridgeBurn que solo pueden ser llamadas por la gatewayL2ERC20Gateway.
Retiros.
-
En Arbitrum, un usuario llama a
L2GatewayRouter.outBoundTransfer, que a su vez llama aoutBoundTransferen la gateway dearbSomeERC20Token(es decir,L2ERC20Gateway). -
Esto quema los tokens de
arbSomeERC20Tokeny llama a ArbSys con un mensaje codificado aL1ERC20Gateway.finalizeInboundTransfer, que se ejecutará finalmente en L1. -
Una vez que expira la ventana de disputa y se confirma la aserción con la transacción del usuario, éste puede llamar a
Outbox.executeTransaction, que a su vez llama al mensaje codificadoL1ERC20Gateway.finalizeInboundTransfer, liberando los tokens del usuario de la custodia del contratoL1ERC20Gateway.
13.8 La Gateway personalizada genérica de Arbitrum.
El hecho de que un token tenga requisitos más allá de los que se ofrecen a través de la Gateway StandardERC20, no significa necesariamente que haya que crear una unica Gateway personalizada para el token en cuestión.
Gateway personalizada genérica de Arbitrum está diseñada para ser lo suficientemente flexible como para adaptarse a la mayoría (pero no necesariamente a todas) las necesidades de tokens fungibles personalizados.
Como regla general:
Si un token personalizado tiene la capacidad de aumentar su suministro (es decir, mintear) directamente en el L2, y desea que los tokens minteados en el L2 puedan retirarse de nuevo al L1 y sean reconocidos por el contrato L1, probablemente requerirá su propia Gateway especial. De lo contrario, la Gateway personalizada genérica es probablemente la solución adecuada.
Algunos ejemplos de características de los tokens adecuadas para la Gateway personalizada genérica:
-
Contrato de token L2 actualizable a través de un proxy.
-
El contrato de token L2 incluye whitelisting o blacklisting de direcciones.
-
El deployer determina la dirección del contrato de token L2.
13.9 Configuración del token con la Gateway personalizada genérica.
Aquí se encuentran los pasos para configurar un token para utilizar la Gateway personalizada genérica:
0) Tener un token en L1.
El token en L1 debe ajustarse a la interfaz ICustomToken (para saber como hacer esto puedes ver TestCustomTokenL1) Además, debe tener una función isArbitrumEnabled en su interfaz.
1) Despliegue de su token en Arbitrum.
El token debe ajustarse a la interfaz mínima de IArbToken; es decir, debe tener las funciones bridgeMint y bridgeBurn que solo pueden ser usadas por el contrato L2CustomGateway, y la dirección de su correspondiente token Ethereum accesible a través de l1Address. Para ver un ejemplo de implementación, consulta TestArbCustomToken.
2) Registre su token en L1 a su token en L2 a través del contrato L1CustomGateway
Haga que el contrato de su token L1 realice una llamada externa a L1CustomGateway.registerTokenToL2. Este registro puede realizarse alternativamente como un registro de propietario de cadena a través de una propuesta en la Arbitrum DAO.
3) Registre su token en L1 en el router L1Gateway
Una vez completado el registro de su token en la Custom Gateway, haga que el contrato de su token L1 realice una llamada externa a L1GatewayRouter.setGateway; al igual que en el paso anterior, este registro también puede realizarse alternativamente como un registro de propietario de cadena a través de la propuesta Arbitrum DAO.
14.👨🎓Conclusión.
El Optimistic Rollup de Arbitrum se ha establecido como una solución prometedora para mejorar la escalabilidad de la red Ethereum. Mediante el uso de rollups optimistas, Arbitrum ha logrado aumentar la eficiencia en el procesamiento de transacciones, reducir los costos y brindar una mayor flexibilidad en las funcionalidades de las aplicaciones descentralizadas.
Toda la criptografía asociada al ecosistema de arbitrum, como por ejemplo, el secuenciador, los tickets reintentables, los mensajes de L1-L2 y el bridge,etc. han sido cuidadosamente estudiada y diseñada para tener respuesta ante cualquier evento malicioso o las necesidades personales de cada usuario y, al mismo tiempo, manteniendo los principios trustless y permissionless de Ethereum.
Con su enfoque basado en la presunción de validez de las transacciones y un sistema de desafío para garantizar la integridad, Arbitrum ofrece una alternativa sólida para mejorar la experiencia de los usuarios de Ethereum. A medida que esta tecnología continúa evolucionando, se espera que Arbitrum desempeñe aún más el papel que está tomando en la adopción masiva de las aplicaciones descentralizadas y la expansión del ecosistema blockchain.
🫂 Agradecimientos
🎉 ¡Gracias por leer hasta el final!🎉 Si está interesado en esta solución de escalabilidad te invitamos a revisar nuestra biblioteca de Layer 2 en español.
Si quieren seguir aprendiendo y colaborando con nosotros, le invitamos a unirse a nuestra vibrante comunidad de Telegram L2 en Español y a seguirnos en nuestro Twitter L2 en Español. Allí encontrará una gran cantidad de información sobre Layer 2 y el ecosistema de Blockchain en general. ¡Te Esperamos!