
Web3 做社交网络(类Twitter)的项目还挺多,如Deso, Lens, Orbi, Farcaster, Lenster, Beb等。 简单过一圈后,发现Lenster比较有意思,尤其是他的底层协议Lens protocol还是比较web3 native。我觉得有必要研究下。我看到一些web3的社交应用,还是web2的打法,收集用户信息,建立用户数据壁垒,我就不太感兴趣了。
说Lens:
Abstract
Lens 是Aave 团队打造的一个社交协议,我理解,Lens社交协议解决了社交产品的以下几个问题:
-
账号所有权
-
通用社交账号体系
-
数据开放性(我讲的是数据开放,而不是所有权)
-
社交资产的流动性
如果你是在开发社交产品,或对未来web3的社交关系非常关注,那Lens是值得做一些研究的,并不是说Lens就一定能跑出来,而是我认为它很有趣,但同样也有很多的问题。在分析的过程中,会穿插一些区块链的技术点。
文章进一步分析了Lens的技术架构,并指出它的若干问题和可能的改进方案:
1、中心化问题
2、重复工作问题
3、链上数据,链下索引的问题
4、数据失去控制权的问题
5、上链成本问题
社交平台的问题
账号所有权
我们知道,在传统互联网体系中,所有平台的账号并不是归用户所有,虽然看似是用户自己输入账号密码,但这个输入账密这个过程的本质是,有个强大的管理平台核验通过了你的使用权,你有权对这个账号关联的内容进行编辑。账号所有权问题,在各中crypto相关的文章、视频中就讲的差不多了,这里就不赘述了。
那Lens的账号体系是什么?
Lens是基于ETH的侧链Polygon开发,所有的Lens账号信息都绑定到一个NFT上,当Polygon钱包中持有了这个Lens的NFT就拥有了对Lens上所有社交应用的控制权。简单画张图以帮助理解:

那这个NFT的所有权就非常明显。
这个NFT还能够在公开市场Opensea上直接购买到,我自己的测试账号就是在Opensea上直接花40usd买过来的,而我买过来后也不担心这个NFT会被禁用。
其实,就NFT的发展来说,从PFP为主走向功能性逐渐是趋势了,Discord也发展出了基于NFT的权限校验体系,未来以NFT作为社交平台门槛的应用场景也会越来越丰富。
通用社交账号体系
我们知道,在web2中,各个平台之间的账号是割裂的,支付宝的账号是不可能登录微信的账号的,微信账号也不能登录钉钉, 钉钉和支付宝虽然同属于一个集团体系(阿里),也是各自有各自的登录账号,这给用户使用带来了极大的不方便

但是我们在看Lens,用户只需要管理一个账号,即Lens的身份NFT,就可以登录任何所有基于Lens的应用

为了让这个账号体系更有价值,就需要更多的开发者基于这个账号去开发应用,这就涉及一个问题,第三方开发者为什么原因基于某个账号体系去开发应用,显而易见,主要原因是这个账号体系有大量的用户。
比如同样的中心化账号体系,如微信账号,你可以用微信的账号登录公众号、视频号、微信,这些应用大概率是微信公司自己开发的,而不是第三方独立开发者,即使如商家小程序,也是在腾讯公司严格的接口审核和数据审核情况下,能有限使用,而且产生的关键数据也会回流到腾讯公司内部。第三方开发者想基于腾讯账号开发应用的动力完全是想获得它的用户或流量并愿意忍受一些不平等的条款。
再看Lens,它的账号(profile NFT)是基于Polygon这条公链的,公链天然具有开放性,第三方开发者不需要经过任何中心化公司的审核就能基于它开发自己想要的应用,同时还能立即获得同样基于这个协议开发的其它应用的用户数据
数据开放性
Elon Musk 最近接手了Twitter,其要干的其中一件重要的事,就是要清理大量的僵尸机器人账号问题。 到底哪些是机器人,哪些是僵尸账号,我们也并不能找到开放的数据去分析。这是所有web2 系统的通病,而看看数据开放性问题,我们以Twitter 为例,问几个问题:
-
你能很方便的知道当前Twitter具体有多少账号吗,即使不区分机器人?
-
Twitter 每日新增用户多少
-
你能方便的知道Twitter总共有发了多少推,今天发送了多少推?
-
某个用户的粉丝有多少是真实活跃的?
这些数据除了平台本身,是没有任何第三方能轻易获得的,这在很大程度上会非常影响数据的商用性,比如如果有广告主想要找大V做活动,做价格评估的门槛是很高的。
但是基于Lens的社交平台会完全不一样,用户的关键行为数据都是上链的,比如follow,post,like等等。以每日发送的Post量为例,因为所有的post信息都是上链的,链上数据天然就具有公开性,任何第三方
都可以获得到关键的数据。下图是在Dune上 分析的Lens 用户日活情况, 而这样的分析,甚至可以聚焦到某个账号地址维度,这个账号的所有历史行为。

我个人实时不希望在web3时代,开发应用的思路还是web2的那套,还想着如何收集大量用户信息并保存起来,作为自己产品的壁垒,这个模式没有人能玩得过微信、Twitter、Facebook、Google了,这难道不是web3尝试要屠杀的恶龙吗?
社交内容货币化
前面都是站在平台角度或开发者角度去分析Lens的优势,但是站在用户角度,我为什么原因去使用Lens呢?Twitter有几十亿用户流量,如果我想传播观点,显然Twitter是更好的平台。
抛开去中心化和账号所有权这两点,我原因尝试Lens的原因大概率是:1、希望作为早期用户获得Lens的代币空投,2、账号有粉丝之后,未来能直接获得收益。
第1点也不说了,这个期望是目前大部分用户愿意在牺牲用户体验的前提下使用web3产品的主要原因(想想Mirror.xyz的编辑器多么难用,还有那么多人用)。
第2点是, 我认为当我的粉丝逐渐多了之后, 可以直接获得收益,如发一条付费的内容,任何collect(这是Lens的一个特有功能,将post信息直接mint成NFT)我的这条信息的人,都要付费。嗯 yummy!
除了信息的直接收益以外,由于Lens的用户大概率都是web3的深度用户,所以在Lens上发内容,大概率都是面对的web3的用户,比如可以所有collect某条推的用户空投别的权益。

Lens生态
目前,已经有几十个社交相关应用是基于Lens协议开发,包括文字内容发布平台去中心化Twitter: Lenster.xyz, 视频内容平台去中心化YouTube: lenstube.xyz, 去中心化简历平台:orb.ac等等
Lens的技术框架
这里我想从开发者角度,分析一下基于目前的Lens协议,去开发社交应用的优劣。
我们分析三个关键步骤, 来阐述Lens是如何做到开放性的
1、在Lens上获取身份
2、登录一个应用 Lenster.xyz
3、在Lenster发表一个推文
4、读取其他用户的推文
https://polygonscan.com/address/0x12ec0d6Fa6E1f35aae60B520FCA75938739CC287这个链接是Lens部署在Polygon上的主合约,合约定义了非常多的专用于社交场景的接口: 比如创建账号createProfile,post,comment,follow,followWithSign等等

获取身份
获取身份的方式比较简单,也很容易理解,获取身份的方式有两种,直接mint一个NFT,或在公开市场买入一个NFT。跟过去大部分NFT的获取方式是一样的。目前来看,Lens还是测试阶段,mint nft是有白名单控制的。合约中也能看到白名单的控制,这里就不贴代码了。 后续所有在Lens相关的app上的操作,都是基于profile NFT做权限验证的

登录一个应用 Lenster.xyz
Lenster.xyz 是基于Lens协议的一个类似于去中心化Twitter的社交平台。
登录的时候,需要Metamask切换到Polygon网络,并签名,用你的地址签名后,传给后台,后台会去链上真实校验你的地址下是否真实的存在profile NFT。 这里由于有中心化后台服务,所以第二步的链上校验过程其实是可以异步的。
校验通过后,就可以登录使用Lenster.xyz 了,该应用会从它的后台服务器中返回各种信息给你,包括这个profile NFT的身份内容设置,发过的推文,follower列表等等。

在Lenster发表一个推文
基于Lens的协议,发推文分两种,一种是 post, 一种是postWithSign。这两个接口的其实没有太大区别,这里就以postWithSign为例。每次发推文都是需要做一次签名,签名信息中带有ProfileId信息。

签名并不一定是必须的, 在Lenster产品中有设置可免除签名的地方。带签名的Post 和不带签名的Post是有本质区别的,因为所有推其实都是由Lens的后台服务代理上链的,后台服务都是中心化运作,既然代理上链,那后台服务为了刷链上数据,完全有可能以你的名义随便发推,以增加他们平台的DAU。
可以看到,大部分的没有sign的post都是由这个地址代发的0xd1feccf6881970105dfb2b654054174007f0e07e ,目前为止已经代执行了总计4百万多次的Post 和Mirror(相当与Twitter转发)等操作信息。

还有部分是sign的post,是由另外一个地址代发的0xe6ab66ca47b9c6cf5a0269786e6af86a44ff8c49,目前为止总共代执行了10+万比操作,还有大量的失败交易。

通过post接口和postWithSign接口传入上Polygon链的calldata数据结构大体是一样的,只不过后者多了一个sign的信息,理论上,只有这样的操作信息,才是真实可信的用户操作,至少是可验证的,而前者400+万多次的操作是无法真实验证的,当然,这也并不值得去深究。

回到整体的逻辑框架,稍微从接口追踪了一下, 就知道整个Lenster的Post发送逻辑是什么样的:
1、用户发送信息content到后台中心化服务节点,
2、后台服务将内容上Arweave链,付费,拿到Arweave gateway的链接contentUrl,
3、后台服务再将contentUrl + 用户签名信息上Polygon链,付费
为什么要通过中心化服务做代理的事情,原因很简单: 用户体验和免费,大概率现阶段没有用户愿意对每个操作都签名,并自费去使用去中心化社交平台。

Post的架构是:前端代码+中心化节点+链上文件存储系统+合约链上存储。

这里其实有一个很值得讨论的点,我们先抛开中心化服务节点问题,这个我在后面会讨论,我想讲的是,文件内容既然已经存入了Arweave,又为何还需要在此存储到Polygon链上来。因为这里并不涉及到数据所有权问题,Arweave的数据是没有所有权的,Polygon上的数据也没有所有权,因为数据都不是原来User自己发的,只是在每条数据里加了一个用户ProfileId,方便后续离线分析和索引。
所以这里Lens是将Arweave纯粹作为文件存储系统,而将Polygon作为Post内容的某种形式的索引存储,虽然Polygon不具备任何索引能力,但它作为EVM兼容链,可以迅速依赖EVM生态的第三方索引工具如The Graph迅速获得内容索引(Lens好像并没有使用The Graph)
存储在Arweave中的,文件内容中没有完整的用户id信息,下图是存到Arweave中的用户发推文的内容详情,可以同个这个链接直接访问https://arweave.net/2y85bg5UcV5M0kdPt3KGJgxzYYpj5YQbXQhd4yOctUI,显然内容中关于用户的信息只有一个name:Post by @lilissholehah.lens,没有NFT id, 没有用户地址。

获取其他用户的推文
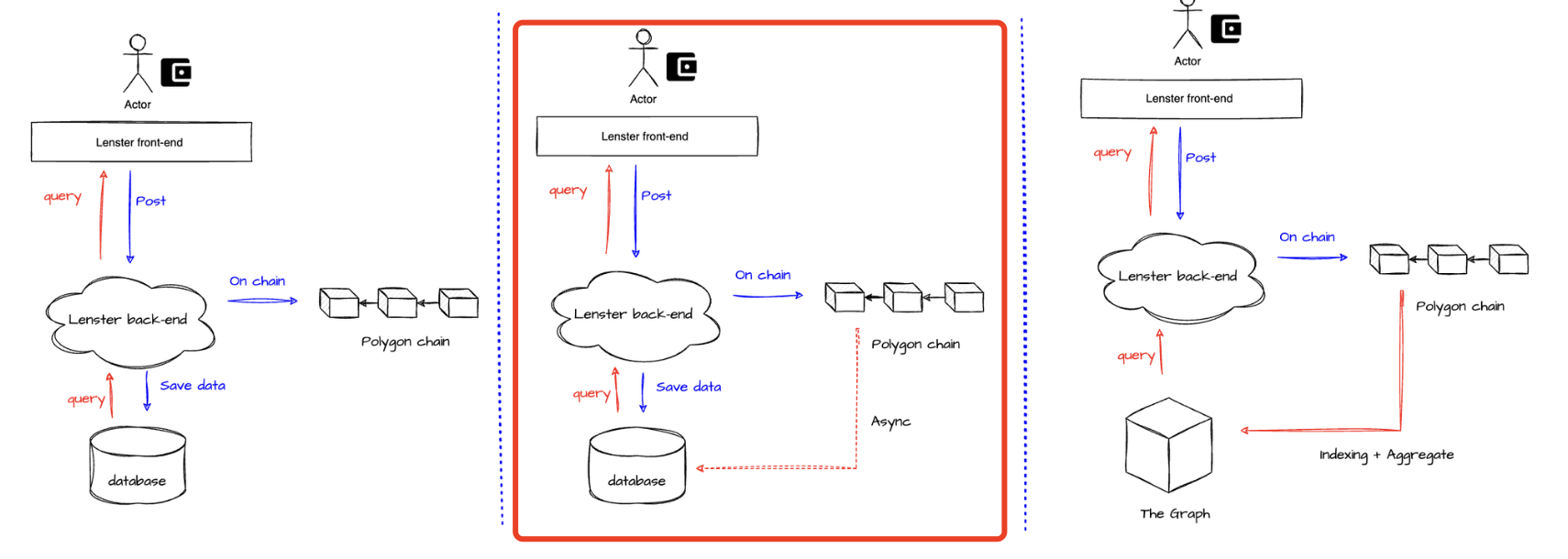
目前为止,我只能知道所有的query都是访问的中心服务器,host为http://api.lens.dev, 这是确定的,只是还不太清楚后台服务所采用的数据访问方案,我下图假设了三种可能(忽略了Arweave),从左往右,更激进也更去中心化(暂且认为The Graph 是去中心化的),我不太清楚他们是否有采用The Graph,但个人揣测,Lens选择中间方案的可能性比较大:数据上链之前,先本地中心化服务存一份,query的时候直接查,对于上链没有成功的,再做一次异步状态更新,把本地存储的数据修改一下状态。
Lens问题
上面Lens的创新很好,但是问题也很明显:
1、中心化问题
2、重复工作问题
3、链上数据,链下索引的问题
4、数据失去控制权的问题
5、上链成本问题
中心化问题
当我对整个Lens生态的多个头部应用分析后,发现一个统一的问题,即大部分应用都依赖同个gateway : api.lens.dev,可以理解为,所有应用都依赖一个中心化数据服务节点,Lens官网中给的sdk也是依赖这个url,并没有提供一个可选的去中心化rpc节点
无论是Lens团队自己开发的上层应用如 Lenster.xyz, 还是其他生态应用,无一不依赖这个中心服务节点。
这也是我在考虑,如果要基于Lens提供的sdk开发应用,会顾虑的问题。

重复工作问题
当然,并不代表你一定要依赖这个gateway,它只是让开发变得很方便,因为所有数据都是公开的,前面也提到过,所以开发者完全可以自己去搭一套系统,同步Polygon上的Lens数据,作为自己的服务节点。新的应用独立搭建数据服务,同步其他Lens相关的用户数据 , 这个过程的成本是非常高的,开发者必须要进行大量的重复工作。如下图右侧,开发者自己搭数据同步服务。

链上数据,链下索引
这个其实也是Polygon这类EVM兼容链固有的问题,即链上数据不能直接被访问,矿工节点不提供数据索引服务。所以需要单独的第三方中心化服务商解决索引问题,如Alchemy,Infura,或者偏去中心化方案一点的The Graph。
这里会引申出非常多问题,中心化节点问题,数据不可信问题(Objective Fact vs Data Presentation)等等,这里就不展开了。
成本问题
这是Lens的商业模式需要考虑的问题,这里的成本也是Lens要承担的成本,
前面有提到,所有上链操作,基本都是由Lens代理上链,上链都是要支付gas费用的。
Lens 要考虑支付的费用包括三个部分:
1、中心服务器存储成本
2、内容上Arweave成本
3、内容上Polygon链的
中心化服务器成本, 这个可以忽略,因为边际成本递减,随着这个费用会随着用户量的上升,gas费用也是成比例上升,并没有传统互联网企业所说的边际成本递减效应。
推文内容存储到Arweave的成本,相对而言比较低,暂且不做计算了,但这个成本同样是线性增加的。
重点看行为数据上链Polygon的成本,我们来看前面提到的那个发送了400+万比交易的代理地址,目前为止它已经支付的gas费用大概为54000Matic,平均用户每个操作的成本为: 0.0135Matic ~ 0.01USD 而当前Lens的总用户量累计才9w+, 随着用户量的增加和日活的增加,这将是一笔巨额的持续性支出, 而且并没有边际成本递减效应,只会指数级增加(用户越多,交互越多)
现在Twitter的每周平均DAU为250M, 如果这是Lens的话,我们假设一个DAU只对应一笔链上交易,Matic维持当前价格不变, 250M*0.01U = 2.5Million USD ,即仅仅是数据上链成本,每周都2.5Million,没有哪个公司能承担这个价格,所以后期Lens持续发展,期待成为大规模的社交应用,必须要做调整: 要么改变数据上链方案,要么把成本转嫁给用户,用户自己上链数据。

数据失去控制权的问题
我为什么没有强调数据所有权,我们看到,所有发布信息都是由第三方账号代理发送上链的, 这显然数据所有权不归用户所有,这个问题存在,但并不是那么重要,它也不归代理账号所有,而是开放数据,谁都可读。Lens将每个上链的数据都标记了ProfileId信息,方便其他应用自行解析用户数据,做到这一步就很好了。毕竟对于社交账号来说,所有的数据都是公开可读的,也就没有所有权的说法,唯一重要的所有权是账号所有权,Lens的NFT体系已经解决了这个问题。
这里的问题是失去控制权问题:用户发送的推文一经上链,即无法更改,更无法删除。
这个问题其实很难解决,在传统Twitter上,你还是可以删除推文的,当然这对于系统管理员来说,你的推文并没有正真删除,只是后台给你这条推做了个标记,不再展示。
但是在Lens协议上,即使是做这种标记的成本也非常高,这也是为什么,lenster.xyz的个人推文好像是没有删除选项的。
构想一个优化的Lens
如果你看到这里,还在继续阅读,那你大概率是个开发者,对web3社交的开发很有兴趣。
那我接下来就打算带货了。讲下我的思路,如何在尝试解决Lens暂时无法解决的问题。
一个理想的web3社交平台,不考虑流量等因素,最好是用户掌管一切,用户直接签名,数据直接上链,前端访问数据也最好是直接查询链上数据,没有中心化中间商,如下图,显然就目前的已存在的这些链,是无法达到这个目的的,原因:并不能保存多少数据,也不能提供链上索引查询能力,而且,就用户体验而言,每次任何操作都需要做签名和付gas费,显然也没有哪个人用户愿意接受。

所以基本的架构就演变为下图,由中间服务层做代理,用户只需要在必要情况下对关键的操作进行签名:

这也是Lens的方案,但是也同样有各种问题,我前面已经讲过了。
我们尝试去解决这个问题:
1、中心化服务+ 重复造轮子的问题
这个就要求有一个真正好用的去中心化数据库,去解决数据索引问题。如果用户的所有索引数据,存在一个去中心化数据库中,我作为应用开发者,不用担心自己所依赖数据被某个中心服务商卡脖子,也不用自己耗费大量精力去维护一套数据索引,这就能大大减少新项目的开发成本。 说实话,我认为现在web3时代,还需要去某个云服务厂商注册一个应用ID,并获得这个云服务层提供的API使用权限,按月付费,这个非常不web3,可以有更好的解法:Web3 Native Serverless , Pay for execution。 这个后面专门写一个方案文章。
2、数据存储成本问题
数据都存储在Polygon链上是非常不现实的,也是为什么Lens把大量文本数据存储到Arweave,图片、视频数据存储到IPFS的原因。
如果Arweave 上层能够把数据索引问题解决,可能Lens也不用把太多数据存储到Polygon,这个可能也是Ceramic要做的事情(我理解Ceramic是基于IPFS的上层数据版本控制协议,因为文件存储到IPFS非常不灵活),而Ceramic的局限性在于,它在一个延迟很高的文件存储系统下搭一个结构化数据存储协议,它的性能天然会被限制,就好比在AWS的S3文件系统基础上搭一个Mysql,所以它不比较难给Lens这样的社交平台提供在线数据服务能力。
3、链上数据,链下索引的Gap问题
目前无论是ETH,Polygon 数据的写入和读取是完全分离的。数据先在链上写入,然后等待区块完成后同步到链下,做数据索引。是否有这样的一套数据查询协议,能够提供高效的数据读取查询能力,而且是去中心化的,数据的写入和查询全都是链上行为,矿工保证网络所有数据的一致性,还提供数据的读取服务。
4、数据控制权问题
这是个非常重要,但不紧急的问题,是否有这样的数据库,能在表维度,将数据的增删改权限交个用户,用户可以直接在链上修改数据。
我们需要这样一个去中心化存储能解决这些问题。如果存在这样一个去中心化数据库之后,上面Lens应用的整体架构可能就变成这样了,Lens只需要定义协议,而不用再维护一个中心化服务节点,更不用花那么多的成本将数据存储到Polygon上。 Lens提供协议,上层应用完全可以自己独立搭建更轻量级的server,做些简单的业务逻辑,用户的内容数据统一在一个去中心化的结构化数据存储上。

这就是我们现在正在做的项目DB3 要解决的问题。
这里方案写的比较简约,其实我是有详细的方案,甚至我最近自己脑子也在构思一个有意思的WEB3社交协议。
如果有人能帮我联系上Lens的项目负责人,并允许我输出一下我的方案,我原因给他/她 一个爱心❤️。或者你们团队正在做类似的社交产品,欢迎联系我,看我能否提供什么帮助。
关于DB3
DB3 要解决这样几个问题:
1、可动态更新的结构化数据链上存储问题
2、链上数据索引问题
3、数据所有权和控制权问题
4、链上数据可编程问题
分别对应下面四张图,我就不在详述了, 最近在写 我们DB3 的Light paper,写完后分享给大家。想知道我们的实时动态,欢迎加入我们的Discord 。




我们项目的每一行代码都是开源的,迭代开发,都是实时同步,欢迎有兴趣的开发者去提issue,一键三连。任何有贡献的开发者,后面都将得到社区丰厚的回报哦
Github: https://github.com/dbpunk-labs/db3/
欢迎关注Twitter:https://twitter.com/Db3Network
Discord: https://discord.com/invite/sgY2bbFCzr
也欢迎关注我个人的 Twitter: https://twitter.com/muran_eth