
Introduction
At Talent Protocol we use Ruby on Rails for our back-end server.
Problem Definition
How do we know which HTTP requests take too long to be processed? With too long we mean more than 2 seconds.
Solution
AWS CloudWatch Logs
We collect all Rails server logs into AWS CloudWatch. Hence, when we inspect the logs we can see lines like the following:
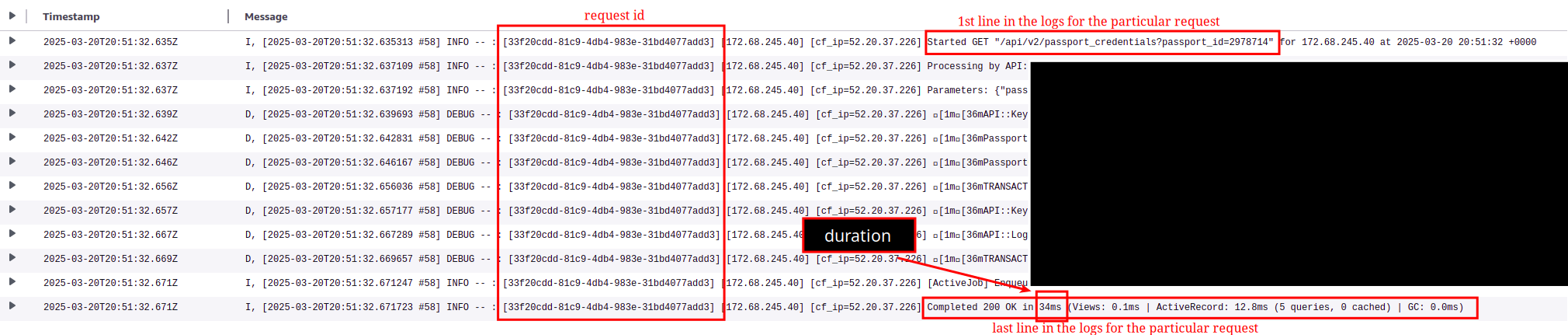
Completed OK - More than 2 Seconds
So, it is quite easy to select the lines individually. For example, the following Logs Insights QL statement gives me the successful HTTP requests that took more than 2 seconds:
filter @message like /Completed 200 OK in \d+ms/
| parse @message /Completed 200 OK\sin\s(?<duration>\d+)ms/
| filter duration >= 2000
| display duration, @message
| sort duration desc
| limit 10000
Note: this also sorts these lines in descending order of the duration.
An example result set is this:
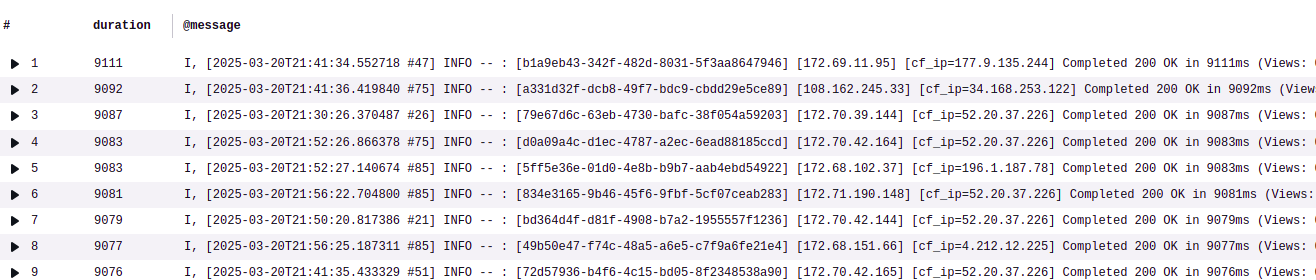
The problem is that I don’t know which requests, in terms of path and query parameters are these. This is because this information is coming on another line, the one that contains the pattern Started…, i.e. the 1st line that is logged for a particular request.
Working with OpenSearch SQL
I understand that I need a way to combine, join, two lines by a common piece of information.
I know that this sounds like SQL joins and the common piece of information is the request id.
This is where I switched to the CloudWatch Logs Insights OpenSearch SQL tool.
Let me work with this tool, step-by-step.
Get the Completed lines with duration >= 2 seconds
I will write this statement first:
SELECT
c.`@message` as message,
REGEXP_EXTRACT(c.`@message`, 'INFO -- : \\[([0-9a-f-]+)\\] .+ Completed 200 OK', 1) as request_id,
CAST(REGEXP_EXTRACT(c.`@message`, 'in ([0-9]+)ms', 1) as INT) as duration_in_ms
FROM `play-production-play-server` as c
WHERE c.`@message` like '%Completed 200 OK%' AND CAST(REGEXP_EXTRACT(c.`@message`, 'in ([0-9]+)ms', 1) as INT) >= 2000
As you can see, this is an SQL-like language that I am using. SELECT … FROM…WHERE….
Look how I use the REGEXP_EXTRACT to get the request_id from the @message. I use the same function to get the duration and cast it to integer so that I can compare it to 2000 (which is 2 seconds in milliseconds).
The CloudWatch group that I am querying is the play-production-play-server. This is the name of the CloudWatch group.
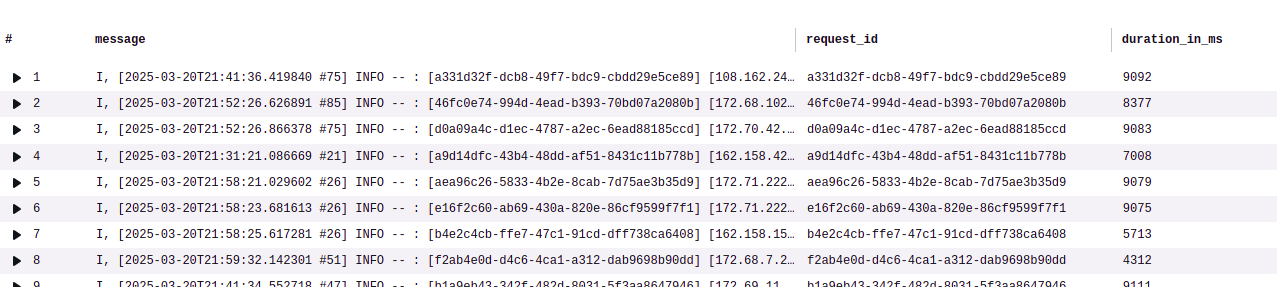
If I run this, I am getting results like this:
Get the Started lines
I will use another statement to get the lines that have the pattern Started. Here it is:
SELECT
s.`@message` as message,
REGEXP_EXTRACT(s.`@message`, 'Started GET .+\\?(.+)" for', 1) as query,
REGEXP_EXTRACT(s.`@message`, 'Started GET "([a-zA-Z0-9-/]+).+ for', 1) as path,
REGEXP_EXTRACT(s.`@message`, 'INFO -- : \\[([0-9a-f-]+)\\] .+ Started GET', 1) as request_id,
REGEXP_EXTRACT(s.`@message`, 'Started GET .+ for ([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) ', 1) as ip
FROM `play-production-play-server` as s
WHERE s.`@message` LIKE '%Started GET%'
Again, my tool is the REGEXP_EXTRACT. I can use it to extract the query, the path, the request_id and the ip of the request. Pretty useful information.
If I run this statement, I get results like this:

Join Two Statements
Now that I have the two statements, I can join them on the request_id. This will give me the duration of each request, along side other useful information like its path, its query and its ip.
Here is the statement:
SELECT
ss.path as path,
URL_DECODE(ss.query) as query,
ss.ip as client_ip,
ss.request_id as request_id,
cc.duration_in_ms as duration_in_ms
FROM (
SELECT
s.`@message` as message,
REGEXP_EXTRACT(s.`@message`, 'Started GET .+\\?(.+)" for', 1) as query,
REGEXP_EXTRACT(s.`@message`, 'Started GET "([a-zA-Z0-9-/]+).+ for', 1) as path,
REGEXP_EXTRACT(s.`@message`, 'INFO -- : \\[([0-9a-f-]+)\\] .+ Started GET', 1) as request_id,
REGEXP_EXTRACT(s.`@message`, 'Started GET .+ for ([0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}) ', 1) as ip
FROM `play-production-play-server` as s
WHERE s.`@message` like '%Started GET%'
) as ss
inner join (
SELECT c.`@message` as message,
REGEXP_EXTRACT(c.`@message`, 'INFO -- : \\[([0-9a-f-]+)\\] .+ Completed 200 OK', 1) as request_id,
CAST(REGEXP_EXTRACT(c.`@message`, 'in ([0-9]+)ms', 1) as INT) as duration_in_ms
FROM `play-production-play-server` as c
WHERE c.`@message` like '%Completed 200 OK%' and CAST(REGEXP_EXTRACT(c.`@message`, 'in ([0-9]+)ms', 1) as INT) >= 2000
) as cc on cc.request_id = ss.request_id
ORDER BY duration_in_ms desc
LIMIT 100
Two SQL sub-queries, inner-joined on the request_id.
Look how I also use the function URL_DECODE() to decode the query in order to make it easier to read.
I now get results like these:

Bingo! I now know which path, query and client_ip had these long running HTTP requests.
gm!
I am Panos M., humble, back-end software reader and writer at Talent Protocol.