
Publishing platforms emerged as a means to democratize writing by enabling writers to reach a wider audience. As the internet became increasingly crowded with personal blogs and articles of all kinds, content creators found themselves calling for attention in the vast online landscape.
Platforms like Medium, Substack or Hashnode arrived to fix this issue. Well-positioned writers migrated their content to these websites and leveraged their popularity, while others took the opportunity to be the first to write on them and became rising stars. Nowadays we can read content from everyone in the world on the same platforms without the need to dig for personal blogs.
Don’t get me wrong, personal blogs are still very important because they represent an extension of the writer itself. There’s much more about the content creator than the writing, a well-structured website with a pleasant design are features that make people connect with the creator. However, the internet has changed and SEO has taken the lead, making it hard for personal blogs to compete with publishing platforms.
Introducing web3 publishing platforms and writing NFTs
Web3 publishing platforms emerged not too long ago, I myself discovered Mirror at the dawn of 2023, and later Paragraph. But these are not the first ones to appear in this realm, I used to write on Steemit, then Hive and there is also Publish0x which I never tried.
Besides the different options available in web3 for writing, Mirror and Paragraph brought something different to the space, by announcing writing NFTs. We always thought of NFTs in the form of images, video or even audio, but it took longer to see them as text.
When I discovered writing NFTs, I was curious about the ownership of these articles and their longevity, which are two main drawbacks of web2 publishing platforms. I was glad to witness that all articles published on Mirror are permanently stored on Arweave, so I was able to check the permanency issue. The same doesn’t apply on Paragraph, where writers decide between publishing on the permaweb, or in a centralized database. I rather have my information stored forever, so I can easily fetch it, if these platforms vanish one day.
Concerning the ownership, when the content is uploaded to Arweave, it goes in a JSON format, organized by title, body, description, author’s address, timestamp and more. This structured piece of information has everything it needs to prove my ownership, so I can also check it. As for the collectors, it gets registered on the Ethereum blockchain that someone acquired my work.
Another cool feature that web3 publishing platforms have when compared to their counterpart, is the ease of gathering information. Web2 platforms have all their data allocated in centralized platforms, meaning that the only way to access the data is through web scraping. The same does not apply to web3 platforms, since the articles can easily be extracted from Arweave as JSON formats.
Let’s delve into the importance of web3 publishing data, and what can be built around it.
👉 Join Post3 Discord community here. Follow Post3 on Twitter (aka X) and Farcaster
Understanding web3 publishing data
At this point, we already know that when referring to web3 publishing data, we are talking about JSON files. This format is easy to manipulate and incorporate into software, which is key because front-end applications can fetch this data and display the articles in different manners.
Post3 decided to make something relevant for the web3 publishing community, by digging into these JSON files and creating structured datasets that contain the JSON information and extra features, harnessed from web scraping techniques.
By merging both GraphQL and web scraping, Post3 delivers ready-to-use datasets for various purposes. Ranging from textual, quantitative and qualitative analytics to more advanced use cases, such as building chatbots or search engines.
There’s a piece written by Mirror Development, that shows exactly how to retrieve the JSON information from Arweave, using Arweave’s GraphQL playground.
Later on, I decided to write another article that shows how you can do it with Python, among other relevant information.
While the scripts implemented in Post3 to extract information from web3 publishing platforms use the GraphQL steps mentioned in the previous articles, they also contain web scraping techniques to grab extra features that are not immediately available at the time the article is submitted, which are the number of collections, the price at which the article is sold, the revenue generated, the date the article was published, the network and others.
All these extracting steps are condensed in a robust pipeline prepared by Post3, to facilitate users to acquire the information in the form of datasets without the need for advanced data engineering skills.
At the moment these datasets are available in the Ocean Market, a web3 marketplace, and they can be acquired at an affordable price of 15 $mOCEAN. They are currently in CSV format, but depending on adoption, other formats such as JSON can be incorporated. If you have a specific requirement feel free to contact Post3 via Discord, Twitter and Farcaster.
The datasets contain the following features:
-
platform: web3 publishing platform
-
title
-
description
-
body
-
recipient_wallet
-
link: URL to the piece
-
arweave_link: the JSON link
-
author
-
date
-
collections: how many people have minted the entry at the moment the data was extracted
-
supply: how many people can mint the entry
-
price
-
currency
-
network: L2 solution to mint the entry
-
revenue
You can can get them here.
Discovering Post3 and its data-driven solutions
While data analysts, data scientists and data enthusiasts are familiar with data manipulation, and can easily explore the datasets and grab the core information, most individuals seek effortless visualization. Recognizing this, Post3 is dedicated to developing tools that pave the way for users to return outputs from the datasets without technical expertise.
Reports
Since the beginning, Post3 has delivered weekly reports based on the dataset uploaded on that same week. Until now, reports tend to answer the following questions:
-
Who are the authors from whom people have collected the most?
-
Which entries were the most collected?
-
Which authors generated the most revenue?
-
Which entries generated the most revenue?
-
What was the networks/chains usage?
-
Who caught our attention this week?
And users can find charts like this one:
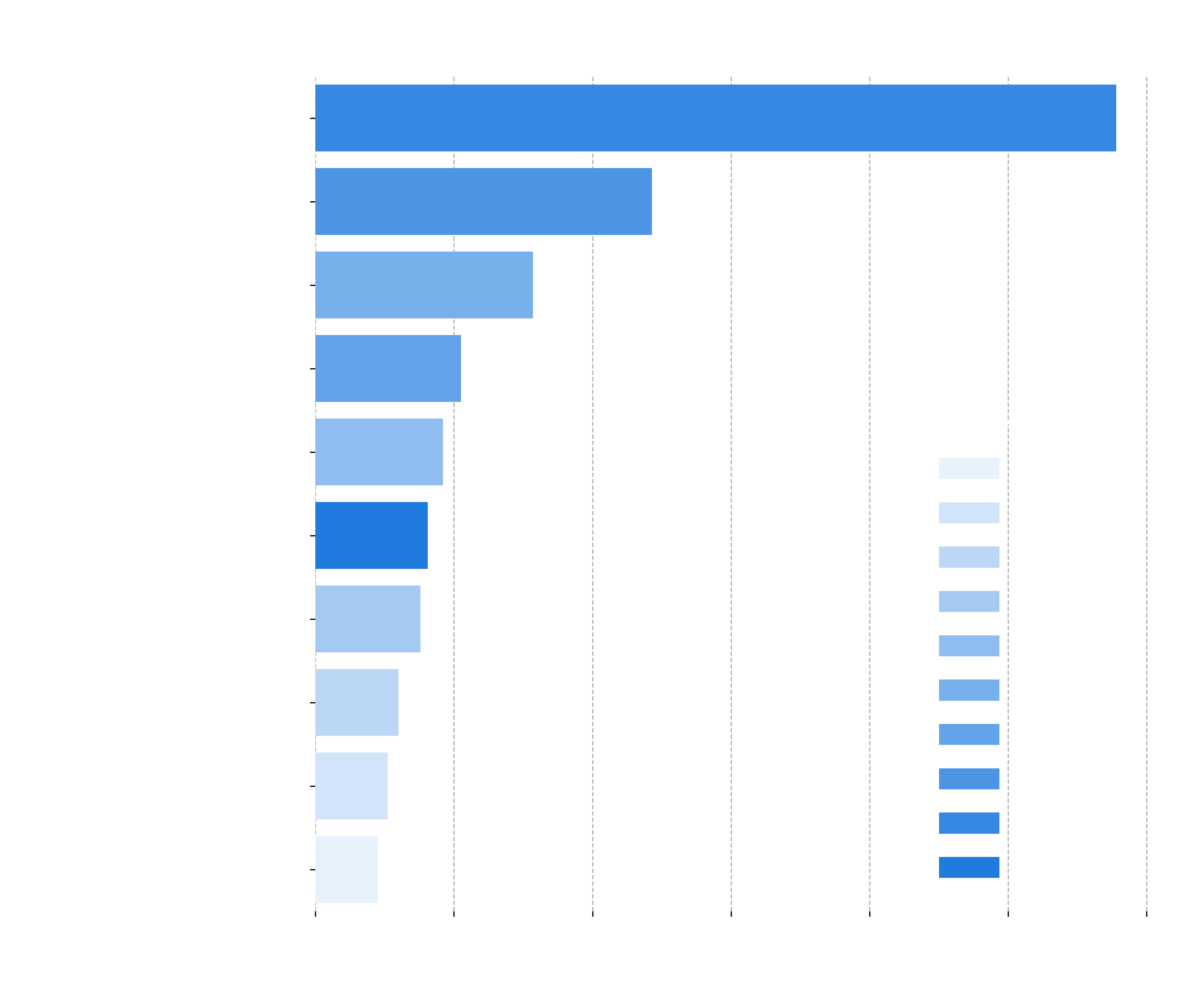
Post3 plans to make more templates, aimed at different goals, such as reports comparing Mirror with Paragraph, others focused on textual analysis, reports comparing the performance on different weeks, and much more. The options are endless with the information provided in the datasets. You can see an example of a weekly report below:
Applications
Post3 aims to empower users to explore the datasets without engaging in data analysis. For instance, one uses a key to start his/her car, without the need to know the materials and components that make part of that key. The same applies to the applications built on Post3. People can buy the datasets and use them on diverse platforms for different finalities, while still having the asset to make some data analysis if they intend to.
At the moment there is only one application built, Post3 Engine, which was crafted for intuitive operation. The user simply selects a dataset from the main page and uploads it along with a specific model. At the time I’m writing, there are two models, one that generates bar charts concerning the collections and revenue and a textual analysis model that prompts word clouds, comparison of language usage and more. You can see an explanation video below:
More models are on the roadmap to be integrated, as well as a better interface. Meanwhile, Post3 Engine serves as a landing page to show what is possible to build with web3 publishing data. Hopefully, it can open the doors to more applications and incentivize individuals and businesses to work with this kind of data and build their own products.
Dedicated Products
Post3 wants to be a gateway of data-driven solutions applied to web3 publishing platforms. Hence, every individual or business willing to work with this type of data can reach out to develop tailored products.
At the moment Post3 doesn’t have its own website, but if you have an idea, you can contact via Discord, Twitter and Farcaster.
The benefits
To summarize, see below some of the examples of what can be accomplished with the data-driven solutions presented before:
-
Discover Airdrops and Rewards: Some of the most popular and lucrative articles cover Airdrops. Submit a dataset to Post3 Engine or read the weekly reports to never miss an opportunity.
-
Discover New Projects: Almost every week, the top collections go to a new project writing on Mirror. This is important because being the first to take part in a new web3 protocol/project is usually rewarding.
-
Find Writers: If you know some data analysis, you can import the dataset to a Python script, find content that suits your taste, and subscribe to the publications. Another way is to follow the weekly reports since there are always some Post3 picks.
-
Optimize Writing: With Post3 Engine you can apply textual analysis to the datasets and observe important parameters, such as the top keywords and the average body length of the articles. With this information, writers can have a general idea of the trends and apply strategies to reach more people.
-
Build: the datasets contain all the information of that week, you can build tools like Post3 Engine to make the most of this data, like creating ChatBots, data exploration, dashboards and more.
👉 Join Post3 Discord community here. Follow Post3 on Twitter (aka X) and Farcaster
Meeting the builder
Indeed, Post3 is currently a one-man project, and that man is me, Marco, a former Microelectronics Engineer who found that the most effective and fastest way to build, is with a simple laptop.
After considerable changes in my professional life, I now see myself more towards Software Engineering, but highly focused on AI, Data Science and Web3. However, my passion lies in building, regardless of the technology employed.
I've been fortunate enough to work in some truly incredible places, like the European Spaceport in French Guiana. I also had the privilege to get in touch with top-notch microelectronics machines, that only a few have the chance to play with. And, on top of that, I've had the opportunity to collaborate with diverse multidisciplinary teams from all over the world.
Not too long ago, I decided to start a freelancing journey, which has been rewarding in several aspects, but time-consuming when compared to my previous jobs. I wrote a piece on Mirror about the freelancing life when I started, I may need to update it at some point.
Lately, I have been delving into writing NFTs, by building an extraction infrastructure through GraphQL and web scraping as well as using data visualization packages to make reports. A few weeks ago, I enrolled in a Hackathon, and I thought it could be the trigger to make the first web application of Post3, entitled Post3 Engine.
I’m currently mixing my paid jobs with Post3 development, which can be exhaustive sometimes. My goal at the moment would be to mainly focus my attention on building more reports, datasets and applications under this project, but for that, I would need some financial support which has been hard to find.
A curious fact about me is that I’m about to be a father, probably at the moment you’re reading this, I might already have my baby girl next to me. Get to know me better:
Calling for support
At this point, you may have noticed that the ambition is real but time is scarce, mainly because I need to prioritise paid work over Post3 most of the time.
The road is being paved, at a slower rhythm, but improvement is noticeable. With your help, I can mitigate the need for clients and accelerate the development of Post3.
Here's what your support will enable me to achieve:
-
Deliver more insights: Increase the number of weekly reports and diversify the thematics.
-
Enhance Post3 Engine: Develop and upload advanced models to Post3 Engine, to extract even more valuable insights from the datasets.
-
Develop dedicated products: Create tailored products for individuals and companies seeking specialized tools to explore Web3 publishing data.
Become an early adopter of the future of data analysis for Web3 publishing by supporting our crowdfunding campaign on Fabric:
Alternative ways to support Post3 include purchasing the weekly datasets from the Ocean Market or minting the reports delivered every week, like this one:
Let’s make Post3 the pillar of Web3 publishing data, and leverage innovative data-driven solutions together.
👉 Join Post3 Discord community here. Follow Post3 on Twitter (aka X) and Farcaster