This isn’t a formal paper, although, an insight I got while I making an AITDD (AI Test Driven Development) framework for Solidity smart contract.
閱讀者請向下滾動/日本語で読む人はスクロール
Multidimensional Signifier Exploration Model (MSEM)
Model Overview
Purpose: The MSEM aims to model information as a high-dimensional hyperparameter space that includes time series and various attributes. It provides a general explanation for advanced LLM usage methods, assisting in the discussion of their extensibility and limitations.
Structure of MSEM
Time Axis:
- (x) axis: Time (left is past, right is future)
High-Dimensional Hyperparameter Space:
- (h_1, h_2, \ldots, h_n) axes: Specific attributes of information (example attributes: mainstreamness, category, credibility, source reliability, relevance, etc.)
Each hyperparameter (h_i) numerically represents a specific attribute.
Question (q) and Area Set:
Question (q) Area Set:
- A question (q) specifies multiple areas (enclaves) in the high-dimensional hyperparameter space. The transformation from question q to enclaves is internally handled by the LLM. The shape and number of enclaves vary sensitively based on the vocabulary and nuances that make up the question q.
It allows flexible searches of information across specific times and multiple attributes. Depending on the combination of obtained data, new nuances may be presented within the LLM (referred to as "signifiers").
Specific Examples
General Question (Multiple Time Areas and Attributes):
-
(x) axis: Range slightly to the right of the center (recent information)
-
(h_1): Mainstreamness (near the center, example attribute)
-
(h_2): Credibility (high, example attribute)
-
Enclaves: Include both specific past points and recent information
Example: "Reliable information on the 2012 and 2024 Olympic host cities?"
Specialized Question (Multiple Attribute Areas):
-
(x) axis: Right end (latest information)
-
(h_1): Mainstreamness (near center and upper end, example attribute)
-
(h_2): Category (medical technology and quantum computing, example attribute)
-
Enclaves: Include both mainstream latest information and niche latest information
Example: "Information on the latest medical technology and quantum computing research papers?"
Step-by-Step Explanation
Initial State: Diagram the initial state handling only two-dimensional hyperparameters.

Simple Prompt Behavior: Diagram the behavior of a simple prompt.

Complex Prompt Formation: Diagram how complex prompts form enclaves.
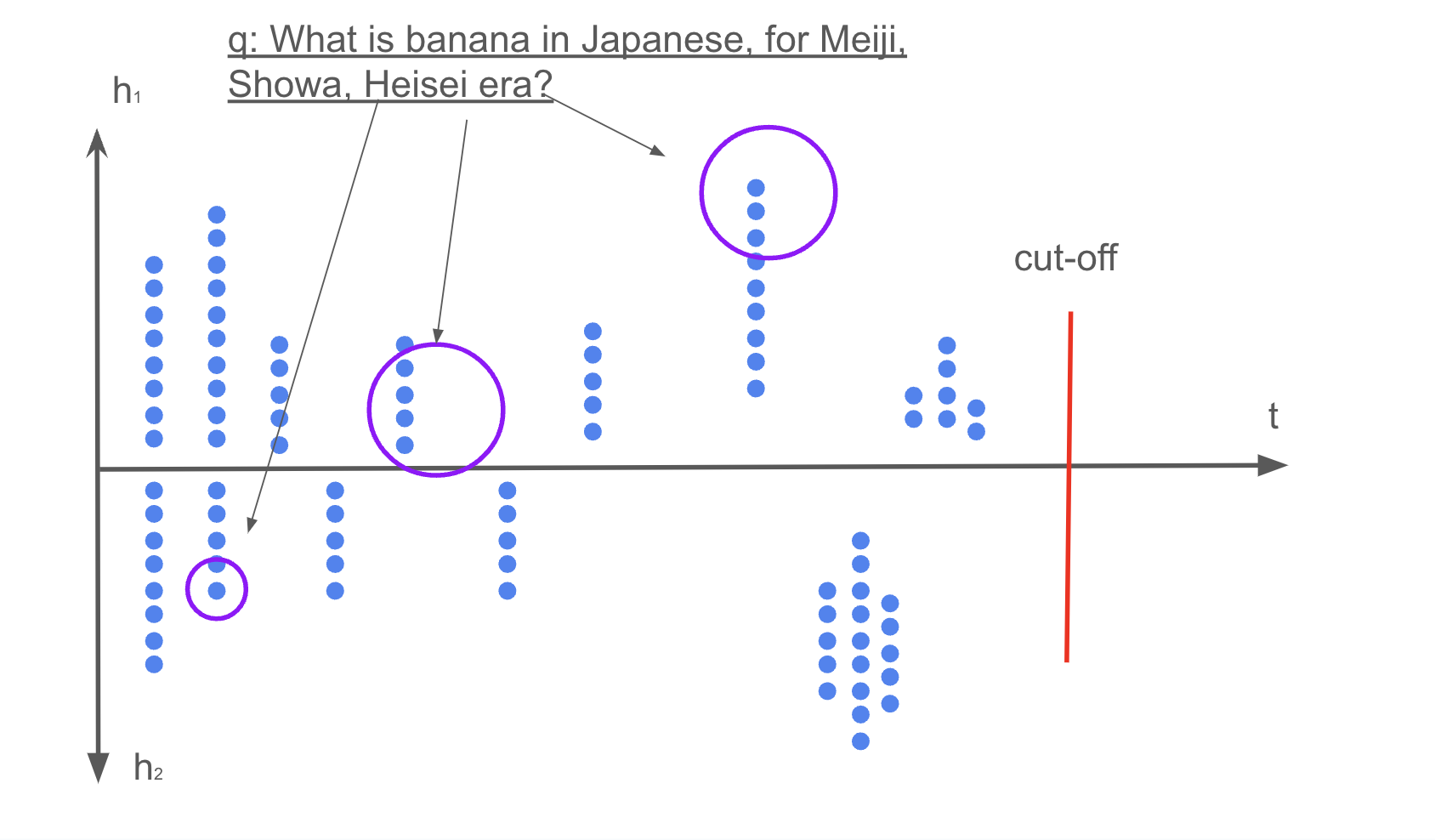
Knowledge Beyond Cutoff Date: Diagram knowledge beyond the LLM's cutoff date.

Addition of New Information: Illustrate how new information is uniquely added.

Constraints of Response Formats: Diagram response format constraints like UML or RAG (interpreted as linear mapping).

Implementation and unit tests are included in the same file, and errors that fail these tests are inputted into the LLM as linear mapping.

As errors are supplied while adding tests, the types of possible responses are strictly limited, leading towards a single implementation. This controlled use of LLM is difficult without support from automated tests, referred to as AITDD (AI-driven Test-Driven Development).

Advantages of MSEM
-
Intuitive Understanding: It enables intuitive and mathematically structured understanding of LLMs as time-series hyperparameter sets, prompts as hyperparameter coordinates sets, and the questioner's intuition (signifiers) as "imagination about hyperparameters."
-
Generalization: It generalizes updating the cutoff date of LLMs and custom LLMs like GPTs and LoRA as "LLM(t+1) with independently progressed sparse hyperparameters."
-
Linear Mapping Constraints: Techniques like RAG, UML-based prompts, and AITDD-supported code generation can be understood as "constraints of questionable hyperparameters by linear mapping of LLM(t)."
-
Future LLM Design and Usage: By expanding this model, it provides suggestions for the design and usage of unknown LLMs.
Summary
The "Multidimensional Signifier Exploration Model (MSEM)" suggests a general mathematical structure of LLMs. This model allows users and developers to apply a certain model to understand new LLMs and new usage methods, facilitating smooth discussions.
多維元意符探索模型 (MSEM)
模型概述
目的: MSEM旨在將信息建模為包含時間序列和各種屬性的高維超參數空間。它為先進的LLM使用方法提供了一般性說明,並輔助討論其可擴展性和局限性。
MSEM的結構
時間軸:
- (x) 軸: 時間(左側為過去,右側為未來)
高維超參數空間:
- (h_1, h_2, \ldots, h_n) 軸: 信息的特定屬性(示例屬性:主流性、類別、可信性、來源可靠性、相關性等)
每個超參數 (h_i) 數值化地表示特定屬性。
問題 (q) 和區域集合:
問題 (q) 區域集合:
- 問題 (q) 在高維超參數空間中指定多個區域(飛地)。從問題q到飛地的轉換由LLM內部處理。飛地的形狀和數量根據構成問題q的詞彙和細微差別而敏感地變化。
它允許靈活地搜索特定時間和多個屬性的信息。根據獲得數據的組合,LLM內可能會呈現出新的細微差別(稱為“意符”)。
具體示例
一般問題(多個時間區域和屬性):
-
(x) 軸: 略靠中間右側的範圍(最近的信息)
-
(h_1): 主流性(靠近中心,示例屬性)
-
(h_2): 可信性(高,示例屬性)
-
飛地: 包括特定的過去點和最近的信息
示例:“2012年和2024年奧運會舉辦地的可靠信息?”
專業問題(多個屬性區域):
-
(x) 軸: 右端(最新的信息)
-
(h_1): 主流性(靠近中心和上端,示例屬性)
-
(h_2): 類別(醫療技術和量子計算,示例屬性)
-
飛地: 包括主流最新信息和小眾最新信息
示例:“最新的醫療技術和量子計算研究論文的相關信息?”
階段性說明
初始狀態: 圖示處理僅二維超參數的初始狀態。

簡單提示行為: 圖示簡單提示的行為。

複雜提示形成: 圖示複雜提示形成飛地的情況。

超過截止日期的知識: 圖示超過LLM截止日期的知識。

新增信息: 描繪新增信息時的獨特情況。

響應格式的限制: 圖示如UML或RAG等響應格式的限制(解釋為線性映射)。

實施和單元測試包含在同一文件中,失敗的錯誤將作為線性映射輸入LLM。

在添加測試的同時提供錯誤信息,可能的響應類型被嚴格限制,朝向唯一的實施。這種精確控制的LLM使用方式在沒有自動測試支持的情況下是困難的,稱為AITDD(AI驅動的測試驅動開發)。

MSEM的優點
-
直觀理解: 它使LLM作為時間序列超參數集直觀且數理結構化地理解成為可能,提示作為超參數坐標集,以及提問者的直覺(意符)作為“對超參數的想像力”。
-
泛化: 它將LLM的截止日期更新和自定義LLM如GPTs和LoRA一般化為“具有獨立進展稀疏超參數的LLM(t+1)。”
-
線性映射限制: RAG、基於UML的提示、AITDD支持的代碼生成等技術可理解為“通過LLM(t)的線性映射對可提問超參數的限制。”
-
未來LLM設計和使用: 通過擴展此模型,為未知LLM的設計和使用提供建議。
總結
“多維元意符探索模型 (MSEM)” 建議了LLM的一般數學結構。該模型使用戶和開發者可以應用一定的模型來理解新LLM和新使用方法,促進討論的順利進行。
多次元シニフィエ探索モデル (MSEM)
モデルの概要
目的: 情報の時系列と多様な属性を高次元ハイパーパラメーター空間として模型化し、高度なLLM利用法群に一般的な説明を与え、その拡張性や限界について議論を補助することを目的とする。
MSEMの構造
-
時間軸:
- ( x ) 軸: 時間(左が過去、右が未来)
-
高次元ハイパーパラメーター空間:
-
( h_1, h_2, \ldots, h_n ) 軸: 情報の特定の属性(以下の例示的な属性: 主流性、カテゴリ、信憑性、出典の信頼度、関連性など)
-
各ハイパーパラメーター ( h_i ) は、特定の属性を数値的に表現します。
-
質問 ( q ) とエリアの集合
-
質問 ( q ) のエリア集合:
-
質問 ( q ) は、高次元ハイパーパラメーター空間で複数のエリア(飛び地)を指定します。この質問qから飛び地への変換はLLMが内部的に行いますが、質問qを構成する語彙やニュアンスに繊細に反応して飛び地の形状や個数は多岐にわたります。
-
特定の時間と複数の属性にわたる情報を柔軟に検索でき、得られたデータの組み合わせに応じてLLM内で新規なニュアンスが提示されることがあります(私はこれをシニフィエと呼んでいます)。
-
具体的な例
-
一般的な質問(複数の時間エリアと属性):
-
( x ) 軸の中央からやや右寄りの範囲(最近の情報)
-
( h_1 ): 主流性(中央付近、例示的属性)
-
( h_2 ): 信憑性(高い、例示的属性)
-
飛び地: 過去の特定の時点と最近の情報を両方含む
-
例: 「信頼できる2012年と2024年のオリンピック開催地に関する情報は?」
-
-
専門的な質問(複数の属性エリア):
-
( x ) 軸の右端(最新の情報)
-
( h_1 ): 主流性(中央と上端、例示的属性)
-
( h_2 ): カテゴリ(医療技術と量子コンピュータ、例示的属性)
-
飛び地: 主流の最新情報とニッチな最新情報を含む
-
例: 「最新の医療技術と量子コンピュータ研究論文に関する情報は?」
-
段階的な説明
まず初期状態を図示します。ここでは二次元的なハイパーパラメーターのみを扱います。

次に、シンプルなプロンプトの挙動を図示します。

複雑なプロンプトが飛び地を形成する様子です。

ベースとなるLLMのカットオフデートを超えた知識はこのように図示されます。

独自に新しい情報が追加されるときはこのように描写されます。

UMLやRAGなどの返答形式の制約はこのように図示されます。(線型写像と解釈します)

実装と単体テストを同じファイルに入れ込み、そのテストによってFailしているエラーを入力することもまたLLMへの線型写像的です。

テストを追加しながらエラーメッセージを供給していくと、可能な返答の種類は厳密に限定され、唯一の実装に向かっていきます。このような精度を制御したLLMの使い方は自動テストの支援なくしては難しく、これをAITDD(AIによるテスト駆動開発)と呼びます。

MSEMの利点
-
LLMを時系列的なハイパーパラメーター集合として、プロンプトもまたハイパーパラメーター座標の集合として、そして質問者の直感(シニフィエ)を「ハイパーパラメーターについての想像力」として直感的かつ数理構造を伴って理解することが可能になる。
-
LLMのカットオフデートの更新や、GPTsやLoRAなどのカスタムLLMを「時系列的に進歩した独自のスパースなハイパーパラメーターを持つLLM(t+1)」と一般化することが可能になった。
-
RAG, UMLに基づいたプロンプト, 単体テストで補助されたコード生成(AITDD)などのテクニックが「LLM(t)の線形写像による質問可能ハイパーパラメーターの制約」と理解することが可能になった。
-
このモデルを拡張することで未知のLLMの設計や利用法の示唆が得られる。
まとめ
「多次元シニフィエ探索モデル (MSEM)」は、LLMの一般的な数学的構造を示唆します。このモデルにより、ユーザーおよび開発者は新規なLLMや新規な利用法について一定の模型を適用して理解を試みることができ、議論の円滑化を期待できます。