这两天把在以太坊官网找的ETHWORKS写的这篇Zero-Knowledge Blockchain Scalability仔细看了两遍,让我对L2的运行逻辑有了更好的了解,但我对其中的一些技术术语还不太懂,姑且先写出来,后面再慢慢学习消化。
L2的目的
在L1的基础上添加L2的protocol以提高以太坊的最大吞吐量(处理交易的速度)并降低交易费用。L2将计算层放在L2上,大大降低了存储在L1上的数据,这使得交易处理速度更快更便宜,同时利用L1的安全性。
零知识证明
零知识证明的核心组成部分是,一个验证者verifier和一个证明者 prover。证明者P在不透漏知识的前提下,向验证者V证明,P拥有这个知识。
一个用于说明零知识证明的例子是,A和B玩一个包含两个球的游戏,一个球是红色,一个是绿色。A是色盲,这意味着这两个球在A眼中的颜色是一样的,而B视觉正常,B的任务是,向A证明这两个球的颜色不一样。游戏过程是这样的:A将两个球放在背后,每次只拿出其中一个球展示给B看,让B回答每次看到的球是否和上一个看到的球一样。如果A换球了,那么B从颜色上可以判断两次看到的球不一样;同理,如果A没换球,那么B从颜色上可以判断两次看到的球一样。在这个例子中,B是prover,A是verifier。尽管A不知道这两个球的颜色不一样,但A可以根据自己是否换球和B的回答来判断(验证),B是否知道(知识)这两个球的颜色不一样。
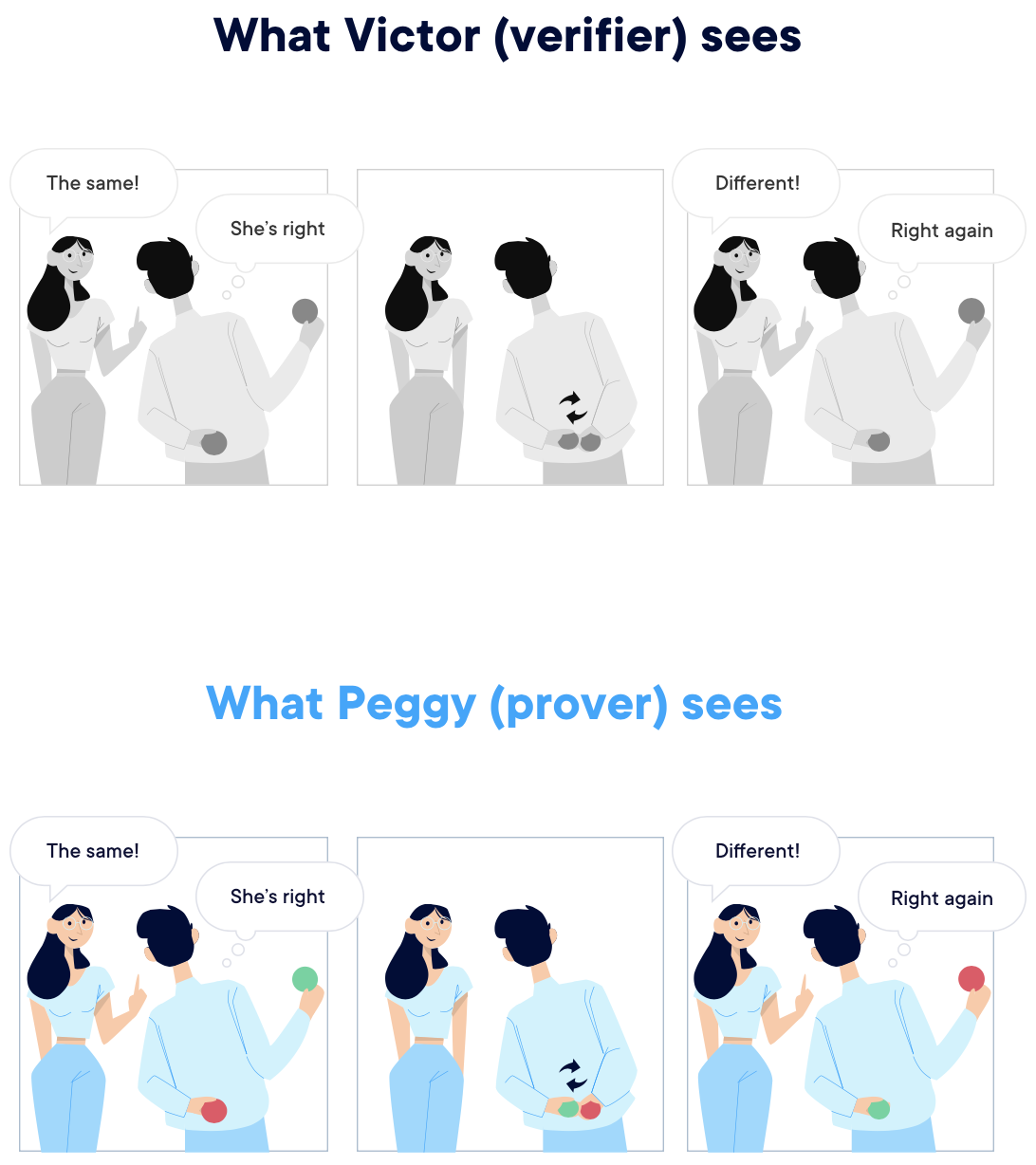
那零知识证明怎么用于L2扩容方案中呢?零知识加密可以能够被用于产生加密证明,表明某些计算确实是按照之前约定的规则执行过了。这些证明由程序生成,并能很容易被验证。生成的计算证明在数据上比计算数据本身小很多,除此之外,零知识证明可以做到让交易匿名。
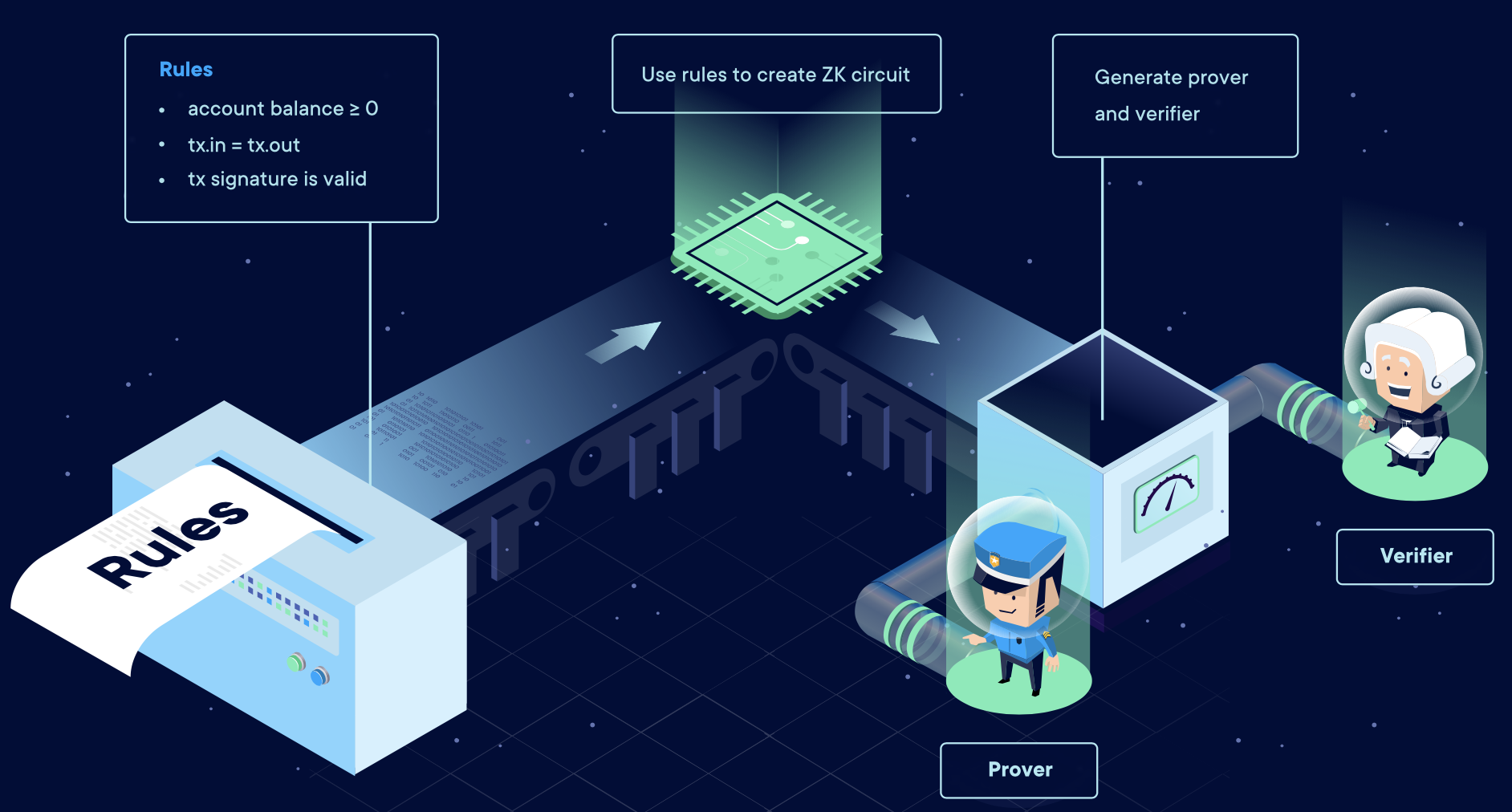
两种验证的情况:

SNARKs和STARKs的区别
SNARKs,succinct no-interactive argument of knowledge.
- succinct,简明,证明的数据量远小于它所代表的数据,可以快速验证
- no-interactive,只有一组信息由prover发送给verifier,不会有信息的互动传输
- argument of knowledge,知识论证/证明。证明被认为是在计算上可靠的。在没有用于支撑它的陈述的知识的情况下,一个带有恶意的证明者不太可能骗得过这个系统。
- SNARKs需要在prover和verifier之间存在一个信任设置trusted setup,这个设置是一些公开的参数,有点类似于一个游戏的规则。这些参数是由一群志愿参与者共同计算的。只要有一个参与者是诚实的,那么这个参数就是安全的。所以参与者越多,这个trusted setup就越安全。
STARKs中的T代表transparent,意思是STARKs不需要trusted setup,避免了可能造成整个系统失效的单点失败。对于STARKs来说,证明的数据量更大,但是对于大量交易打包的分摊计算成本更低。
数据可用性data availability
-
与用户余额相关的交易数据和信息可以放在链上或者链下,这意味着必须在可扩展性和安全性中间作出取舍。
-
将数据存储在链上,安全性可以得到保障,用户的资产直接放在L1上而不需要做什么,可以确保在L2解决方案提供者的服务器停止运作或者有恶意时,数据依然在L1上可用data availability,可以让用户产生证明,表明他们拥有的资产并随时取出,而不需要与系统互动。基于零知识证明的解决方案并将数据存储在链上的方案叫zkRollups.
-
将数据存储在链下,就会造成data availability的问题。当扩容方案的提供者不再协作时,普通用户很难提取他们的资产,除非他们能拿到代表他们资产的数据,这种解决方案叫validiums。为了减轻数据可用性问题,他们引入了多方委员会Data Availability Committee,用于存储和共享用户的数据信息,以防提供者有恶意或者不配合。尽管将数据存储在链下会带来数据可用性的问题,但有一个好处是更高的可扩展性,因为链上存储的数据更少了。
-
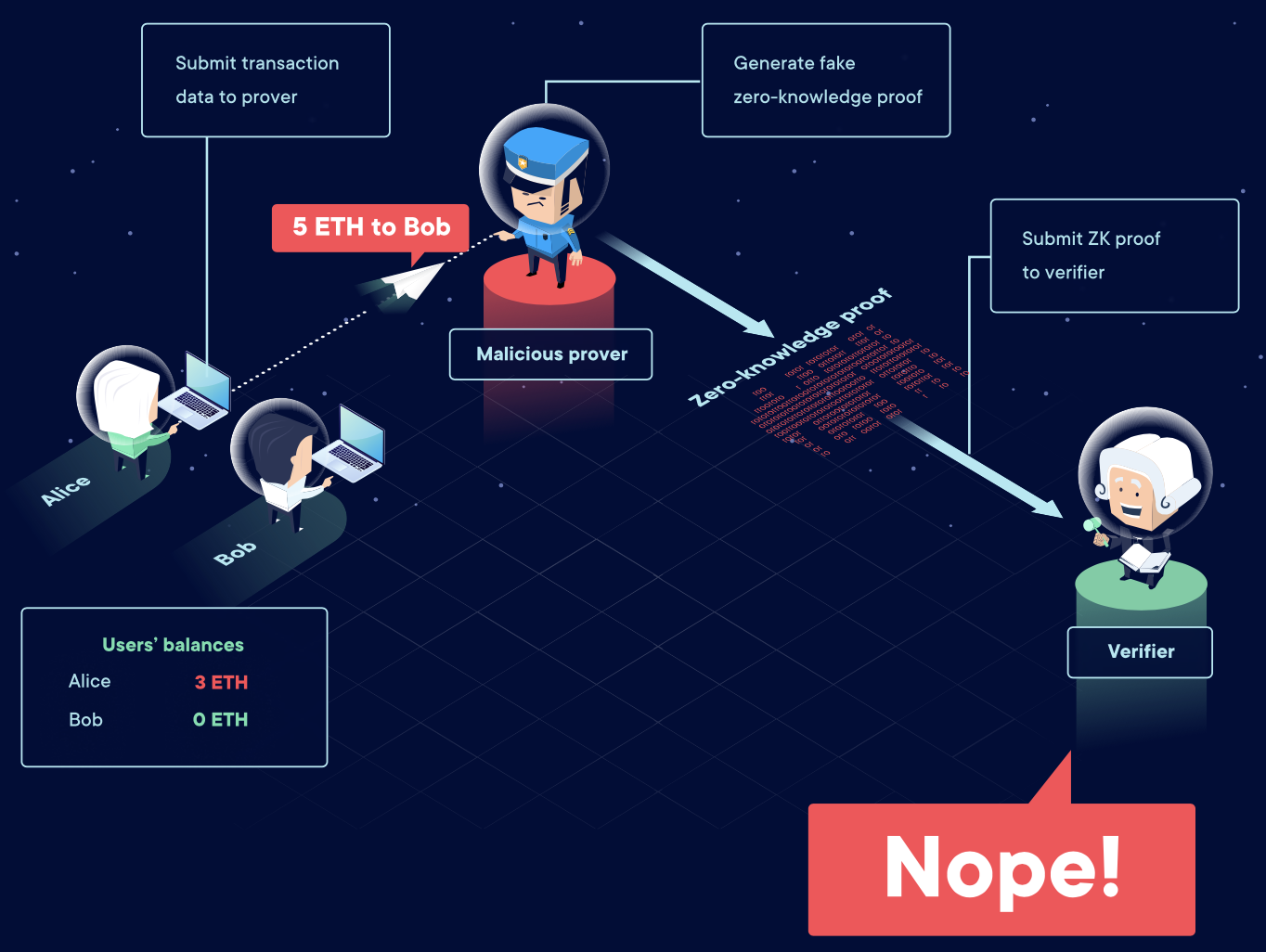
zkRollups中处理用户交易的服务器提供者叫做operator。他们扮演prover的角色,收集交易输入数据,然后将它们转化为更轻的零知识证明。计算过程在链下,因此交易本身不会被L1上的智能合约处理,智能合约只需要验证更轻的零知识加密证明,这也是导致手续费更低的原因,在L1上的智能合约扮演的是verifier的角色。
zkRollups的安全性来自于以下几个方面:
- operators无法以任何形式盗取用户的资金或者破坏这个系统。得益于零知识证明,这个系统只有在有效状态valid state才能运作。
- 用户不需要监督网络。因为所有用户数据都在链上。
- 用户可以随时将他们的资金从智能合约中提取到主网上。
zkRollups的流程
- L2上的operator内嵌了一个prover,同时L1的智能合约中包含一个verifier。
- 为了进入这个L2,用户需要先将资产转入这个zkRollup,资产会被放在L1上对应的智能合约中。
- 然后用户可以将资产发送给另一个人,签名交易并将交易信息提交给operator。
- 这个过程中,交易可以多次发生,比如A发送给B,B发送给C,C退出智能合约等等。
- 同时,operator会收集各种交易和退出的请求。
- 每隔一段时间,operator会将收集来的交易信息进行打包(形成一个新的区块),生成一个证明,并将交易和证明提交给verifier。
- verifier会验证这些交易和证明,一旦验证通过,交易即被最终确认。
为了充分理解zkRollups的扩容潜力,必须首先理解两个机制:
- operator需要支付将数据存储在链上并验证的成本,这个成本比它们自己存储并处理更便宜。
- 交易数据依然存储在链上,但不是以区块链状态,而是交易数据的状态(calldata),成本也更低。
calldata为什么更便宜?
- 调用数据并不是以blockchain state的一部分保存,这意味着可以在不需要存储所有历史数据的情况下,运行一个安全节点。
- 让zkRollup更加高效的关键就在于,节点不需要存储历史数据。
区块链状态需要能被搜查到,这个状态以Merkel tree的数据结构被存储,而且需要快速的存取。因此它总是被存放在快速的SSD驱动中。交易和历史数据可以存在慢一点的HDD驱动甚至便宜的云中。以太坊的扩容瓶颈是SSD驱动的速度和Merkel tree数据结构的存取。
