
Originally published on Sep 30, 2021:
Arbitrum is Offchain Labs’ optimistic rollup implementation that aims to greatly increase the throughput of the Ethereum network. This guide is an introduction to how the Arbitrum design works and is meant for anyone looking to get a somewhat technical overview on this layer 2 solution. This article assumes that the reader has some knowledge of Ethereum and optimistic rollups. The following links may be helpful to those who would like more info on optimistic rollups:
- Optimistic Rollups
- An Incomplete Guide to Rollups
- A Rollup-Centric Ethereum Roadmap
- (Almost) Everything you need to know about the Optimistic Rollup
The Arbitrum network is run by two main types of nodes — batchers and validators. Together these nodes interact with Ethereum mainnet (layer 1, L1) in order to maintain a separate chain with its own state, known as layer 2 (L2). Batchers are responsible for taking user L2 transactions and submitting the transaction data onto L1. Validators on the other hand, are responsible for reading the transaction data on L1, processing the transaction and therefore updating the L2 state. Validators will then post the updated L2 state data to L1 so that anyone can verify the validity of this new state. The transaction and state data that is actually stored on L1 is described in more detail in the ‘Transaction and State Data Storage on L1’ section.
Basic Workflow
- The basic workflow begins with users sending L2 transactions to a batcher node, usually the sequencer.
- Once the sequencer receives enough transactions, it will post them into an L1 smart contract as a batch.
- A validator node will read these transactions from the L1 smart contract and process them on their local copy of the L2 state.
- Once processed, a new L2 state is generated locally and the validator will post this new state root into an L1 smart contract.
- Then, all other validators will process the same transactions on their local copies of the L2 state.
- They will compare their resultant L2 state root with the original one posted to the L1 smart contract.
- If one of the validators gets a different state root than the one posted to L1, they will begin a challenge on L1 (explained in more detail in the ‘Challenges’ section).
- The challenge will require the challenger and the validator that posted the original state root to take turns proving what the correct state root should be.
- Whichever user loses the challenge, gets their initial deposit (stake) slashed. If the original L2 state root posted was invalid, it will be destroyed by future validators and will not be included in the L2 chain.
The following diagram illustrates this basic workflow for steps 1–6.
Batcher Nodes and Submitting L2 Transaction Data
There are two different L1 smart contracts that batcher nodes will use to post the transaction data. One is known as the ‘delayed inbox’ while the other is known as the ‘sequencer inbox’. Anyone can send transactions to the delayed inbox, whereas only the sequencer can send transactions to the sequencer inbox. The sequencer inbox pulls in transaction data from the delayed inbox and interweaves it with the other L2 transactions submitted by the sequencer. Therefore, the sequencer inbox is the primary contract where every validator pulls in the latest L2 transaction data.
There are 3 types of batcher nodes — forwarders, aggregators, and sequencers. Users can send their L2 transactions to any of these 3 nodes. Forwarder nodes forward any L2 transactions to a designated address of another node. The designated node can be either a sequencer or an aggregator and is referred to as the aggregator address.
Aggregator nodes will take a group of incoming L2 transactions and batch them into a single message to the delayed inbox. The sequencer node will also take a group of incoming L2 transactions and batch them into a single message, but it will send the batch message to the sequencer inbox instead. If the sequencer node stops adding transactions to the sequencer inbox, anyone can force the sequencer inbox to include transactions from the delayed inbox via a smart contract function call. This allows the Arbitrum network to always be available and resistant to a malicious sequencer. Currently Arbitrum is running their own single sequencer for Arbitrum mainnet, but they have plans to decentralize the sequencer role in the future.
The different L2 transaction paths are shown below.
Essentially, batcher nodes are responsible for submitting any L2 transaction data onto L1. Once these transactions are processed on L2 and a new state is generated, a validator must submit that state data onto L1 as well. That process is covered in the next section.
Validator Nodes and Submitting L2 State Data
The set of smart contracts that enable validators to submit and store L2 state data is known as the rollup. The rollup is essentially a chain of blocks, so in other words, the rollup is the L2 chain. Note that the Arbitrum codebase refers to these blocks as ‘nodes’. However, to prevent confusion with the terms ‘validator nodes’ and ‘batcher nodes’, I will continue to refer to these rollup nodes as blocks throughout the article.
Each block contains a hash of the L2 state data. So, validators will read and process transactions from the sequencer inbox, and then submit the updated L2 state data hash to the rollup smart contract. The rollup, which stores a chain of blocks, will create a new block with this data and add it as the latest block to the chain. When the validator submits the L2 state data to the rollup smart contract, they also specify which block in the current chain is the parent block to this new block.
In order to penalize validators that submit invalid state data, a staking system has been implemented. In order to submit new L2 state data to the rollup, a validator must be a staker — they must have deposited a certain amount of Eth (or other tokens depending on the rollup). That way, if a malicious validator submits invalid state data, another validator can challenge that block and the malicious validator will lose their stake.
Once a validator becomes a staker, they can then stake on different blocks. Here are some of the important rules to staking:
- Stakers must stake on any block they create.
- Multiple stakers can stake on the same block.
- Stakers cannot stake on two separate block paths — when a staker stakes on a new block, it must be a descendant of the block they were previously staked on (unless this is the stakers first stake).
- Stakers do not have to add an additional deposit anytime they stake on a new block.
- If a block loses a challenge, all stakers staked on that block or any descendant of that block will lose their stake.
A block will be confirmed — permanently accepted in L1 and never reverted — if all of the following are true:
- The 7 day period has passed since the block’s creation
- There are no existing challenging blocks
- At least one staker is staked on it
A block can be rejected (destroyed) if all of the following are true:
- It’s parent block is older than the latest confirmed block (the latest confirmed block is on another branch)
- There is a staker staked on a sibling block
- There are no stakers staked on this block
- The 7 day period has passed since the block’s creation
Take the following diagram as an example:
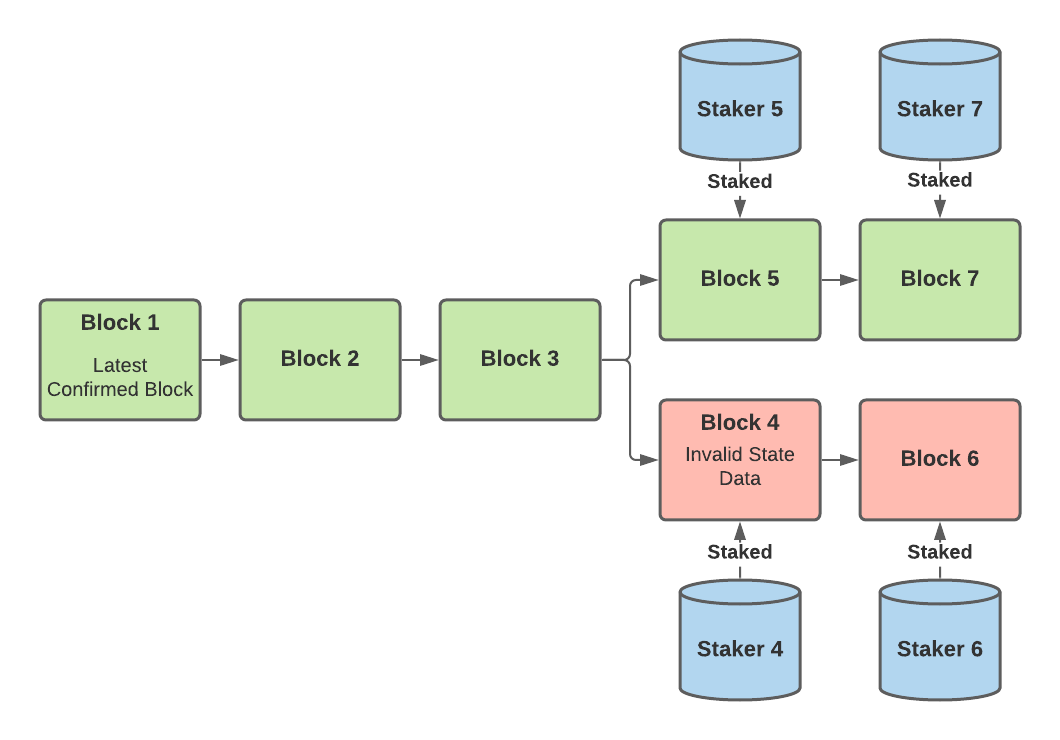
In this example, since blocks 4 and 5 share the same parent, staker 5 decides to challenge staker 4 and wins since block 4 contains invalid state data. Therefore, both staker 4 and staker 6 will lose their stakes. Stakers will continue adding new blocks to the chain that contains blocks 5 and 7. Blocks 4 and 6 will then be destroyed after the 7 day period has passed. Even though stakers are necessary for the system to work, not all validator nodes are stakers. The different types of validators are explained in the next section.
Validator Types
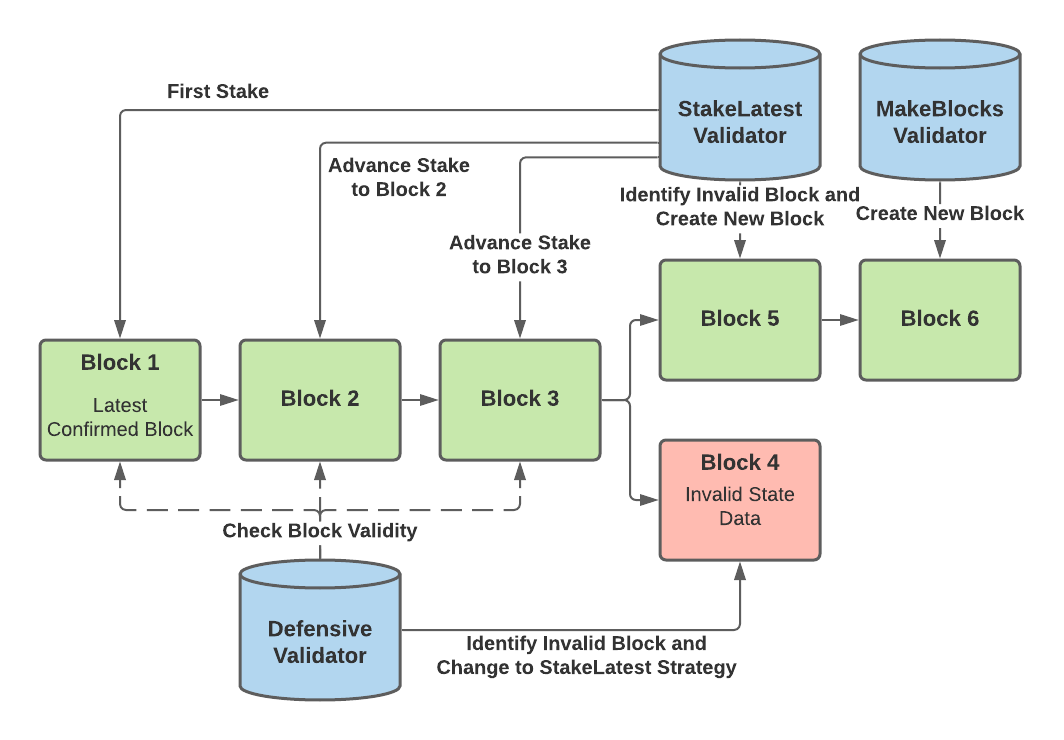
Each validator may use a different strategy to keep the network secure. Currently, there are three types of supported validating strategies — Defensive, StakeLatest, and MakeBlocks (known as MakeNodes in the codebase). Defensive validators will monitor the rollup chain of blocks and look out for any forks/conflicting blocks. If a fork is detected, that validator will switch to the StakeLatest strategy. Therefore, if there are no conflicting blocks, defensive validators will not have any stakes.
StakeLatest validators will stake on the existing blocks in the rollup if the blocks have valid L2 state data. They will advance their stake to the furthest correct block in the chain as possible. StakeLatest validators normally do not create new blocks unless they have identified a block with incorrect state data. In that case, the validators will create a new block with correct data and mandatorily stake on it.
MakeBlocks validators will stake on the furthest correct block in the rollup chain as well. However, even when there are no invalid blocks, MakeBlocks validators will create new blocks once they have advanced their stake to the end of the chain. These are the primary validators responsible for progressing the chain forward with new state data.
The following diagram illustrates the actions of the different validator strategies:
Transaction and State Data Storage on L1
Transaction Data Storage
As explained above, aggregator and sequencer nodes receive L2 transactions and submit them to the L1 delayed and sequencer inboxes. Posting this data to L1 is where most of the expenses of L2 come from. Therefore, it is important to understand how this data is stored on L1 and the methods used to reduce this storage requirement as much as possible.
Aggregator nodes receive user L2 transactions, compress the calldata into a byte array, and then combine multiple of these compressed transactions into an array of byte arrays known as a transaction batch. Finally, they will submit the transaction batch to the delayed inbox. The inbox will then hash the transaction batch and store the hash in contract storage. Sequencer nodes follow a very similar pattern, but the sequencer inbox must also include data about the number of messages to include from the delayed inbox. This data will be part of the final hash that the sequencer inbox stores in contract storage.
State Data Storage
After MakeBlocks validators read and process L2 transactions from the sequencer inbox, they will submit their updated L2 state data to the rollup smart contract. The rollup smart contract then hashes the state data and stores the hash in contract storage.
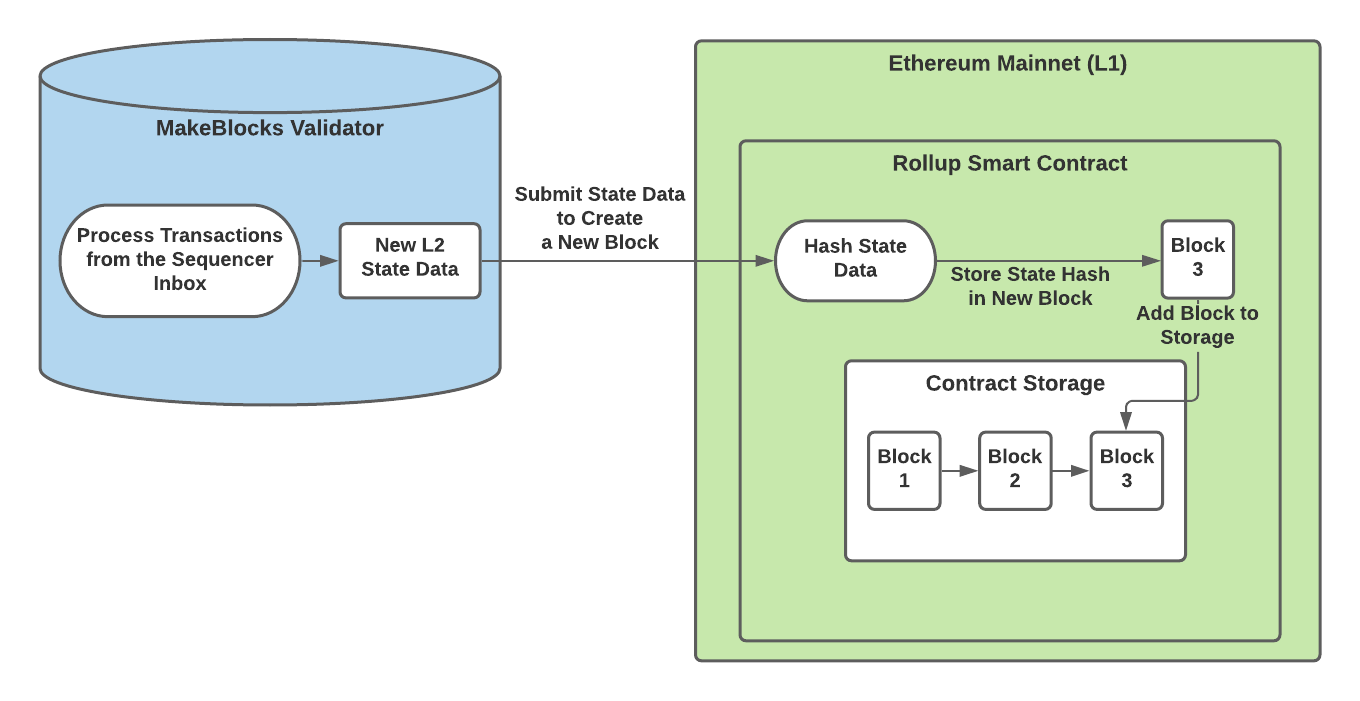
Retrieving Transaction and State Data
Even though only the hash of the transaction and state data is stored in contract storage, other nodes can see the original data by retrieving the calldata of the transaction that submitted the data to L1 from an Ethereum full node. The calldata of transactions to the delayed or sequencer inboxes contain the data for every L2 transaction that the aggregator or sequencer batched. The calldata of transactions to the rollup contract contain all of the relevant state data — enough for other validators to determine if it is valid or invalid — for L2 at that time. To make looking up the transaction easier, the smart contracts emit an event to the Ethereum logs that allows anyone to easily search for either the L2 transaction data or the L2 state data.
Since the smart contracts only have to store hashes in their storage rather than the full transaction or state data, a lot of gas is saved. The primary cost of rollups comes from storing this data on L1. Therefore, this storage mechanism is able to reduce gas expenses even further.
The AVM and ArbOS
The Arbitrum Virtual Machine
Since Arbitrum L2 transactions are not executed on L1, they don’t have to follow the same exact rules as the EVM for computation. Therefore, the Arbitrum team built their own virtual machine known as the Arbitrum Virtual Machine (AVM). The AVM is very similar to the EVM because a primary goal was to support compatibility with EVM compiled smart contracts. However, there are a few important differences.
A major difference between the AVM and EVM is that the AVM must support Arbitrum’s challenges. Challenges, covered in more detail in the next section, require that a step of transaction execution must be provable. Therefore, Arbitrum has introduced the use of CodePoints to their virtual machine. Normally, when code is executed, the instructions are stored in a linear array with a program counter (PC) pointing to the current instruction. Using the program counter to prove which instruction is being executed would take logarithmic time. In order to reduce this time complexity to constant time, the Arbitrum team implemented CodePoints — a pair of the current instruction and the hash of the next codepoint. Every instruction in the array has a codepoint and this allows the AVM to instantly prove which instruction was being executed at that program counter. CodePoints do add some complexity to the AVM, but the Arbitrum system only uses codepoints when it needs to make a proof about transaction execution. Normally, it will use the normal program counter architecture instead.
There are quite a few other important differences that are well documented on Arbitrum’s site — Why AVM Differs from EVM
ArbOS
ArbOS is Arbitrum’s own operating system. It is responsible for managing and tracking the resources of smart contracts used during execution. So, ArbOS keeps an account table that keeps track of the state for each account. Additionally, it operates the funding model for validators participating in the rollup protocol.
The AVM has built in instructions to aid the execution of ArbOS and its ability to track resources. This support for ArbOS in the AVM allows ArbOS to implement certain rules of execution at layer 2 instead of in the rollup smart contracts on layer 1. Any computation moved from layer 1 to layer 2 saves gas and lowers expenses.
Challenges
Optimistic rollup designs require there be a way to tell whether the L2 state data submitted to L1 is valid or invalid. Currently, there are two widely known methods — replayability and interactive proving. Arbitrum has implemented interactive proving as their choice for proving an invalid state.
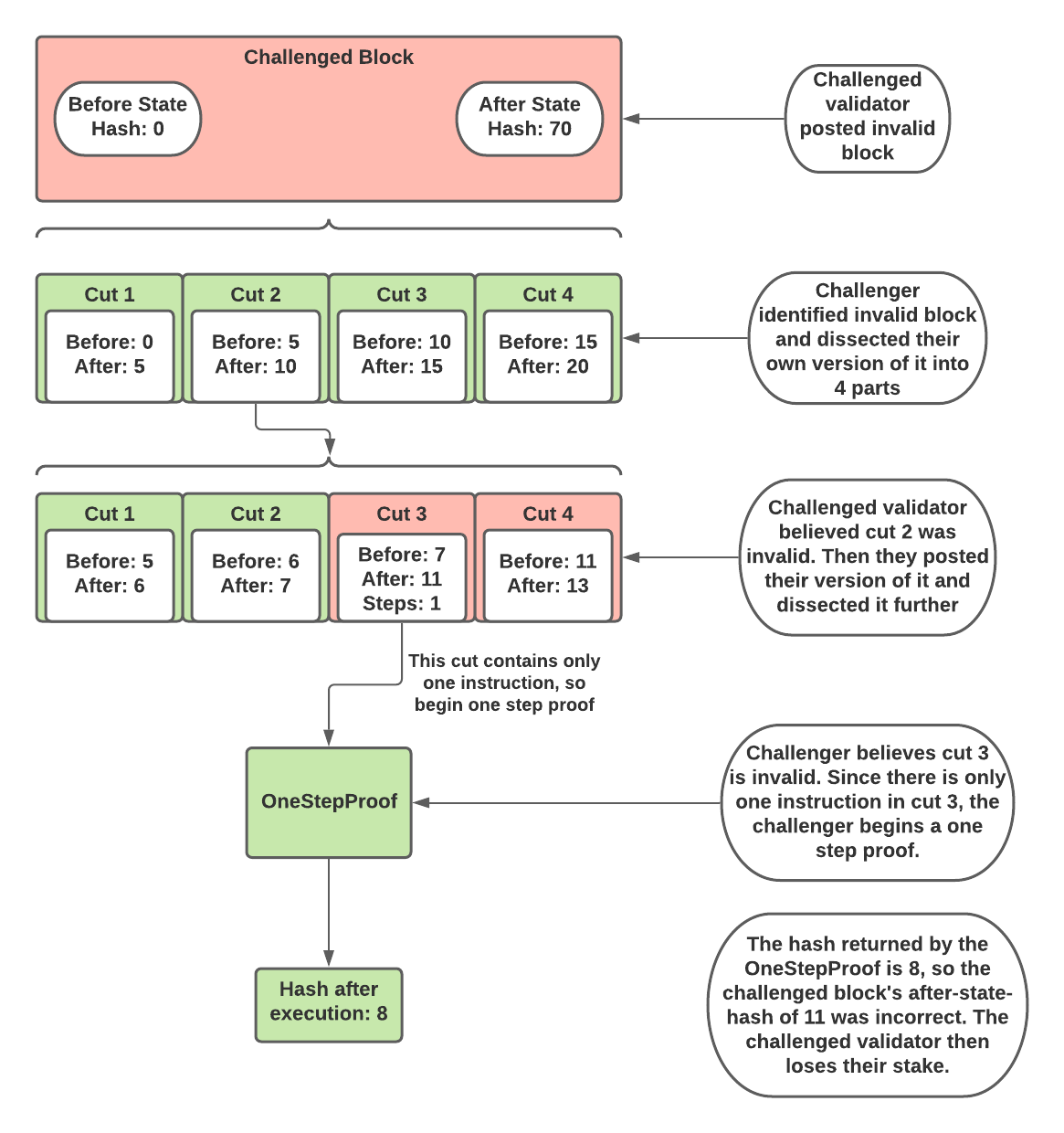
When a validator submits updated state data to the rollup, any staker can challenge that block and submit the correct version of it. When a challenge begins, the two stakers involved (challenger and challenged staker) must take turns dividing the execution into an equal number of parts and claim which of those parts is invalid. Then they must submit their version of that part. The other staker will then dissect that part into an equal number of parts as well, and select which part they believe is invalid. They will then submit their version of that part.
This process continues until the contested part of execution is only one instruction long. At this point, the smart contracts on L1 will perform a one step proof. Essentially, the one step proof executes that one instruction and returns an updated state. The block whose state matches that of the one step proof will win the challenge and the other block will lose their stake. The following diagram illustrates an example of a challenge.
Conclusion
How does this raise Ethereum’s transaction per second and lower transaction costs?
Arbitrum, along with all optimistic rollups, greatly improves the scalability of the Ethereum network and therefore lowers the gas costs (holding throughput constant). In L1 every Ethereum full node in the network will process the transaction, and since the network contains so many nodes, computation becomes very expensive. With Arbitrum, transactions will only be processed by a small set of nodes — the sequencer, aggregators, and validators. So, the computation of each transaction has been moved off of L1 while only the transaction calldata remains on L1. This clears a lot of space on L1 and allows many more transactions to be processed. The greater throughput reduces the gas costs since the competition for getting a transaction added to a block is lower.
Anything special about Abritrum’s implementation of optimistic rollups?
Arbitrum’s design gives many advantages that other rollup implementations don’t have because of its use of interactive proving. Interactive proving provides a great number of benefits, such as no limits on contract size, that are outlined in good detail on Arbitrum’s site — Why Interactive Proving is Better. With Arbitrum’s successful mainnet launch (though still early), it’s clear that the project has achieved an incredible feat.
If you’re interested in reading more on Arbitrum’s optimistic rollup, their documentation covers a lot more ground and is easy to read.